Kaggle项目之电信客户流失(Telco Customer Churn)
入门项目,记录自己思考过程,恐有不足,还望大家指点一二。
在和鲸社区上也有类似的,数据比这个要好一些,大家可以参考思路,去和鲸社区上经行分析。
----------------------------------------------------------废话分割线----------------------------------------------------------
一更:参考了别的作业,有了新的发现
----------------------------------------------------------一更分割线----------------------------------------------------------
准备工作:
导入库
import warnings
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import plotly.graph_objs as pltgo
import plotly.offline as pltoff
from sklearn import preprocessing
from sklearn.linear_model import ElasticNetCV
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error, explained_variance_score, \
median_absolute_error
from sklearn.linear_model import ElasticNetCV,RidgeCV,LassoCV
from sklearn.ensemble import RandomForestRegressor,RandomForestClassifier
from sklearn.feature_selection import SelectKBest
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.model_selection import cross_val_score,GridSearchCV
from sklearn import model_selection
导入数据
data_train = data_train = pd.read_csv("./Data.csv")
预先过滤warnings
# 过滤warings
warnings.filterwarnings('ignore')
第一步:观察数据的完整性与数据的类型
print("data_shape:",data_train.shape)
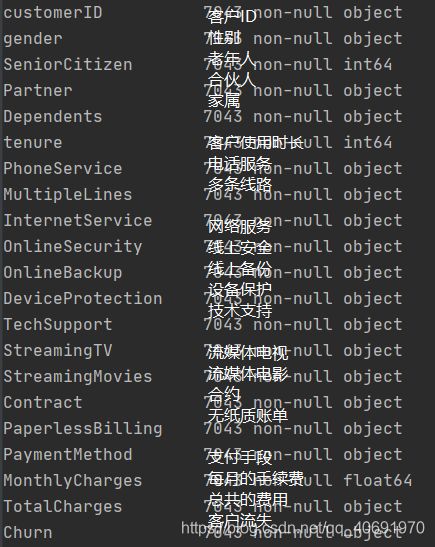
print("data_info:",data_train.info())

- 一共21个标签,7043条数据,没有缺失的数据,数据的类型也可以看的清清楚楚
了解每一个标签的含义,初步主观推测数据对于预测结果的影响的多少
通过绘图观察指标对于流失率的影响
柱形图观察分析指标的重要性
- 对于数据,只有数量不够直观,百分比更加直观的能看出数据的重要性
def Percentage(data_label,data_values_list,flag):
'''
计算各指标所占百分比
:param data_label:需要计算的Series
:param data_values_list: 各指标的数量
:return: 指标数量和占比的字符串 组成的列表
'''
total_value = len(data_label) if flag == 'part' else len(data_train)
percent_str = []
for data_value in data_values_list:
data_value_percent = data_value / total_value
percent = round(data_value_percent, 3)
str_total = str(data_value) + "(占比" + str(percent * 100) + "%" + ")"
percent_str.append(str_total)
return percent_str
# 局部分析
def Churn_yes_bar(data_label,title):
'''
观察 流失客户 中的主要因素
:param data_label:需要绘图的Series
:param title: 绘制图的名称
:return: 绘制的图
'''
# 对于流失率的影响,所以只需要分析流失用户的数据即可
data = data_label[data_train.Churn == "Yes"].value_counts()
plt.bar(data.index,data.values)
# 计算百分比
num_percent_list = Percentage(data_label[data_train.Churn == "Yes"],data.values,'part')
Indexlen = np.arange(len(data.index))
# 绘制百分比数据
for x,y in zip(data.index,Indexlen):
plt.text(x,data.values[y],s = num_percent_list[y],ha = 'center')
plt.title(title)
plt.ylabel("客户数量")
plt.show()
- 有些可以很容易的做初步判断是否为主要因素
- 例如:
# todo 电话服务的有无,可能是 客户流失 主要影响因素
# todo 有:1699 无:170 大多数的 流失客户 有 电话服务
Churn_yes_bar(data_train.PhoneService,"电话服务")

- 但有些需要稍作思考,决定怎样分析。
- 例如:这里我们对有电话服务的客户做了分析,发现其中有没有多条线路的电话服务对于客户是否流失这一点几乎没有影响,因为两者人数几乎是一样的,所以我们可以初步推断,有没有电话服务可能为主要的客户流失的影响因素,但电话服务线路的多少并无太大关系。(同时这里我们在下一步人工降维的时候就可以删掉这个维度)
# todo 有电话服务的人是否有多条线路:人数比列接近,并非主要因素,主要因素为有没有电话服务
# todo ('No', 849) ('Yes', 850)
Churn_yes_bar(data_train.MultipleLines[data_train.PhoneService == "Yes"],"是否有多条电话服务线路")

- 我们可以通过对整体的数据进行观察,进一步分析该因素是否对客户流失有影响。通过对比流失和非流失客户在某个因素上的数量,若流失客户远远大于非流失客户,则表明该因素仍然有可能为客户流失的主要因素。
# 整体分析
def Churn_doublebar(data_label,title):
'''
若某个因素并非 流失客户 中的因素
通过这个函数
对比观察 非流失客户 与 流失客户 的主要因素
:param data_label: 需要绘图的Series
:param title: 绘制图的名称
:return: 绘制的图
'''
x = np.arange(len(data_label.value_counts().index))
data_noChurn = data_label[data_train.Churn == "No"].value_counts()
data_yesChurn = data_label[data_train.Churn == "Yes"].value_counts()
y_No = list(data_noChurn.values)
y_Yes = list(data_yesChurn.values)
bar_width = 0.35
x_label = list(data_label.value_counts().index)
plt.bar(x,y_No,bar_width,align = 'center',label = "未流失客户")
# 计算百分比
NoNumPercentlist = Percentage(data_label[data_train.Churn == "No"],data_noChurn.values,'whole')
YesNumPercentlist = Percentage(data_label[data_train.Churn == "Yes"],data_yesChurn.values,'whole')
Nolen = np.arange(len(data_noChurn.index))
Yeslen = np.arange(len(data_noChurn.index))
# 绘制百分比数据
for i,j in zip(Nolen,Nolen):
plt.text(i,y_No[j],s = NoNumPercentlist[j],ha = 'center')
plt.bar(x + bar_width,y_Yes,bar_width,align = 'center',label = "流失客户")
for i,j in zip(Yeslen,Yeslen):
plt.text(i + bar_width,y_Yes[j],s = YesNumPercentlist[j],ha = 'center')
plt.xlabel(title)
plt.ylabel("客户数量")
plt.xticks(x + bar_width/2,x_label)
plt.legend(loc = 0)
plt.show()
散点图观察分析数据的重要性
- 对某些维度过多的指标,单独进行分析
# 单独处理tenure
# 将Tenure变量的值转变为分类值
def tenure_lab(data_train):
if data_train['tenure'] <= 12:
return 'Tenure_0_12'
elif (data_train['tenure'] > 12) & (data_train['tenure'] <= 24):
return 'Tenure_12_24'
elif (data_train['tenure'] > 24) & (data_train['tenure'] <= 48):
return 'Tenure_24_48'
elif (data_train['tenure'] > 48) & (data_train['tenure'] <= 60):
return 'Tenure_48_60'
elif data_train['tenure'] > 60:
return 'Tenure_gt_60'
data_train['tenure_group'] = data_train.apply(lambda data_train: tenure_lab(data_train), axis=1)
- 通过plotly第三方库进行绘制
# 利用散点图来研究按照tenure分组的每月开支和总开支情况
def plot_tenure_scatter(tenure_group, color):
tracer = pltgo.Scatter(x = data_train[data_train['tenure_group'] == tenure_group]['MonthlyCharges'],
y = data_train[data_train['tenure_group'] == tenure_group]['TotalCharges'],
mode = 'markers', marker = dict(line = dict(width = 0.2, color = 'black'),
size = 4, color = color, symbol = 'diamond-dot'),
name = tenure_group, # legend名称
opacity = 0.9
)
return tracer
# 利用散点图研究按照churn分组的每月开支和总开支
def plot_churn_scatter(churn, color):
tracer = pltgo.Scatter(x = data_train[data_train['Churn'] == churn]['MonthlyCharges'], # 进提取已流失客户数据
y = data_train[data_train['Churn'] == churn]['TotalCharges'], # 进提取已流失客户数据
mode = 'markers', marker = dict(line = dict(width = 0.2, color = 'black'),
size = 4, color = color, symbol = 'diamond-dot'),
name = 'Churn'+churn, # legend名称
opacity = 0.9)
return tracer
trace1 = plot_tenure_scatter('Tenure_0_12', '#FF3300')
trace2 = plot_tenure_scatter('Tenure_12_24', '#6666FF')
trace3 = plot_tenure_scatter('Tenure_24_48', '#99FF00')
trace4 = plot_tenure_scatter('Tenure_48_60', '#996600')
trace5 = plot_tenure_scatter('Tenure_gt_60', 'grey')
trace6 = plot_churn_scatter('Yes', 'red')
trace7 = plot_churn_scatter('No', 'blue')
data1 = [trace1, trace2, trace3, trace4, trace5]
data2 = [trace7, trace6]
# 绘制画布
def layout_title(title):
layout = pltgo.Layout(dict(
title = title, plot_bgcolor = 'rgb(243, 243, 243)', paper_bgcolor = 'rgb(243, 243, 243)',
xaxis = dict(gridcolor = 'rgb(255, 255, 255)', title = 'Monthly charges',zerolinewidth = 1, ticklen = 5, gridwidth = 2),
yaxis = dict(gridcolor = 'rgb(255, 255, 255)', title = 'Total charges',zerolinewidth = 1, ticklen = 5, gridwidth = 2),
height = 600
))
return layout
layout1 = layout_title('Monthly Charges & Total Charges by Tenure group')
layout2 = layout_title('Monthly Charges & Total Charges by Churn group')
fig1 = pltgo.Figure(data = data1, layout = layout1)
fig2 = pltgo.Figure(data = data2, layout = layout2)
# pltoff.plot(fig1)
# pltoff.plot(fig2)
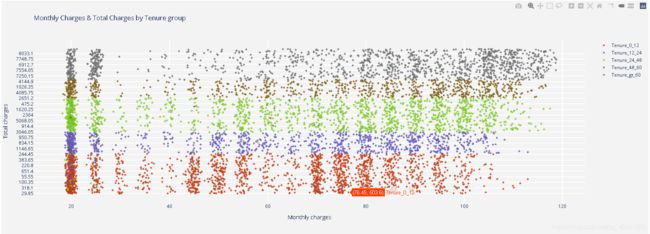
- fig1:绝大多数用户使用时长集中在0-12这个区域
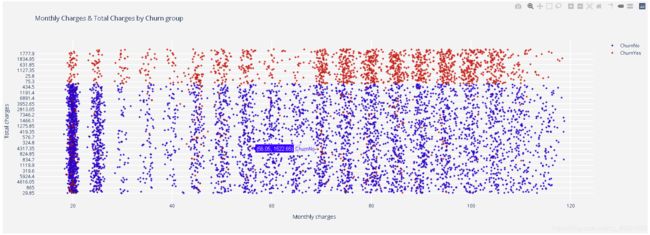
- fig2:费用越低,客户流失数量越少
第二步:对数据进行分析,分析可降维的因素
- 讨论什么样的指标是可以删除的,也就是什么类型的指标对于客户流失是不重要的,什么样的是重要的
- 不可删除的:从局部向整体分析
-
局部分析:
-
从已经流失的客户方面来看,某个维度的各项数据不平衡,差距过大,说明该维度有可能对客户流失造成影响,比如:
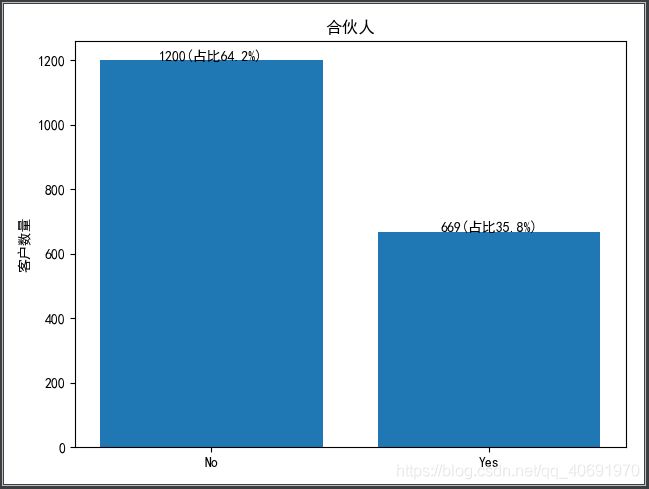
-
如果数据数量平均,再从整体来分析。
-
整体分析:
- 如果非流失客户的数量在一个指标下远大于流失客户的数量,说明对客户流失的影响不大。
- 如果非流失客户的数量在一个指标下与流失客户的数量几乎持平,说明对客户流失的影响很小。
- 如果非流失客户的数量在一个指标下远小于流失客户的数量,说明对客户流失的影响很大。
-
联合分析:
- 有些数据指标不能单独分析:比如:
PhoneService和MultipleLines、InternetService和OnlineSecurity- 因为有后者的前提条件是要有前者,拆开看可能会出现错误的分析
- 有些数据指标不能单独分析:比如:
-
- 不可删除的:从局部向整体分析
'''
结论:
可能为主要因素的指标:SeniorCitizen、PhoneService(Y/N)、Partner(Y/N)、Dependents(Y/N)、tenure(标准化处理)、InternetService(需要one-hot编码)、
OnlineSecurity(Y/N/NIS)、OnlineBackup(Y/N/NIS)、DeviceProtection(Y/N/NIS)、TechSupport(Y/N/NIS)、
Contract(需要one-hot编码)、PaperlessBilling(Y/N)、PaymentMethod(需要one-hot编码)、MonthlyCharges(标准化处理)
可以去掉的指标:gender(去掉)、MultipleLines(去掉)、StreamingTV(不一定可以去掉)、StreamingMovies(不一定可以去掉)、TotalCharges(去掉)
'''
第三步:对数据进行处理
数据预处理
- 因为数据本身比较完整,没有缺失值或噪点之类的需要处理,所以就要考虑数据的可处理性。
- 对于像
InternetService、Contract、PaymentMethod这种只有几个维度的指标,可以考虑用one-hot编码进行处理。 - 其他字符串类型的Series也需要one-hot编码
- 先把字符串类型的Series变为更好处理,数据更简化的Series
# todo 处理含有 三个维度 得指标,例如:OnlineBackup:Yes、No、No internet service,把No internet service变成No
def NIS_to_No(data):
'''
将 No internet service 变成 No 便于后续处理
:param data: 需要处理的Series
:return: 处理完成的Series
'''
return data.str.replace('No internet service','No')
- 对所有字符串类型的Series进行one-hot编码
# todo 将有 少量维度 的指标进行one-hot编码
def Get_dummies(data,title):
'''
对所有字符串类的数据进行one-hot编码处理
:param data: 需要处理的Series
:param title: 编码后用来分类的列名称
:return: 编码完成的Series
'''
return pd.get_dummies(data,prefix = title)
- 将编码后的数据并入原来的集合,形成训练集
# 处理完成把编码后的Series并入原来的数据
df_test = pd.concat([data_test,dummies_PhoneService,dummies_Partner,dummies_Dependents,dummies_InternetService,dummies_OnlineSecurity,
dummies_OnlineBackup,dummies_DeviceProtection,dummies_TechSupport,dummies_Contract,dummies_PaperlessBilling,
dummies_PaymentMethod,dummies_StreamingTV,dummies_StreamingMovies],axis = 1)
- 但对于像
tenure这样的具有大量维度的指标,one-hot编码是不可取的,可以考虑使用归一化进行处理。
# todo 将有 大量维度 的指标尝试进行标准化处理,降低标准差
# 在新的sklearn库中,处理的数据要是二维数据,当输入的是一维数据的时候,需要用 reshape(-1,1) 将数据二维化
scaler = preprocessing.StandardScaler()
df_test['tenure_scaled'] = scaler.fit_transform(df_test.tenure.values.reshape(-1,1))
df_test['MonthlyCharges_scaled'] = scaler.fit_transform(df_test.MonthlyCharges.values.reshape(-1,1))
- 在所有数据处理完成之后,将数据精简,未处理的数据删除,合成训练集
# 删除未处理的数据
df_test.drop(['gender','customerID','PhoneService','Partner','Dependents','InternetService','OnlineSecurity','OnlineBackup','DeviceProtection',
'TechSupport','Contract','PaperlessBilling','PaymentMethod','StreamingTV','StreamingMovies',
'TotalCharges','MultipleLines','tenure_group'],axis = 1,inplace = True)
- 将预测用的
Churn单独提取出来,并将数据处理成非字符串的形式
y_train = data_train.Churn
df_test.drop(['Churn'],axis = 1,inplace = True)
# 将 y_train 变成 0,1 形式表达,进行模型训练
def transfrom_y_train(y_train):
'''
对y_train经行处理
:param y_train:y_train
:return: 处理后的y_train
'''
y0 = y_train.str.replace('Yes', '1')
y1 = y0.str.replace('No', '0')
for i in range(len(y1)):
y1[i] = 1 if y1[i] == '1' else 0
return y1
y_train = transfrom_y_train(y_train)
对数据进一步降维
- 观察数据之间的相关性
# 利用热力图观察数据之间的相关性
corr_matrix = df_test.corr().abs()
sns.heatmap(corr_matrix,cmap='spectral')
plt.show()
- 把相关性较高的指标提出来,相关性高,说明相似,对用户流失得影响也可能相似,提高数据对于训练模型的契合度
# triu将矩阵里面的某几个主对角线的数据清零,在这里是用来取消对称部分的重复数据
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape),k = 1).astype(np.bool))
to_drop = [i for i in upper.columns if any(upper[i] > 0.75)]
# 删掉相似度高的
df_test.drop(to_drop,axis = 1,inplace = True)
第四步:建立训练模型,经行预测
划分数据集
- 因为这个数据集官方没有给测试集,所以我们需要自行划分训练集和测试集,这里只是划分的一种简单方法,并不唯一,大家可以自行思考更为合理有效的划分方式。
# 这里处理y_train是为了便于后续的训练集,保证和新训练集的数据量一致
def Train_split(data_all,ratio_num,y_train):
'''
分割训练集为 新训练集 和 测试集
:param data_all: df_test
:param ratio_num: 新训练集占原本数据集合的比例:小数形式
:param y_train: y_train
:return: 新训练集、测试集、新y_train
'''
data_all_len = data_train.shape[0]
min_len = data_all_len * ratio_num
while True:
train_len = int(np.random.uniform(0,data_all_len))
if train_len > min_len:
break
train = data_all[:train_len]
test = data_all[train_len+1:]
y_train = y_train[:train_len]
return train,test,y_train
x_train,x_test,Y_train = Train_split(df_test,0.8,y_train)
建立模型
- 可以找出预测用的数据对比源数据检验预测的效果。
封装分析模型好坏的函数
def _ApplyLinerAlgo(model,x_train,x_test,y_train):
model.fit(x_train,y_train)
y_predict = model.predict(x_train)
# r2数值越大,模型训练效果越好
print("r2评价模型好坏:",r2_score(y_train,y_predict))
print("MSE评价模型好坏:",mean_squared_error(y_train,y_predict))
print("MAE评价模型好坏:",mean_absolute_error(y_train,y_predict))
print("EAS评价模型好坏:",explained_variance_score(y_train,y_predict))
print("MAE评价模型好坏:",median_absolute_error(y_train,y_predict))
print('\n')
y_train_pre = np.exp(model.predict(x_test))
return y_train_pre
建立简单模型
回归模型
- 这里只给出一种回归模型的训练,可以使用弹性回归、岭回归、Lasso回归建立模型经行尝试,但对于该数据集,建议使用随机森岭,模型效果较好。
# 使用随机森岭回归模型训练和预测
RFR = RandomForestRegressor()
print("RandomForestRegressor:\n")
y_pre_RFR = _ApplyLinerAlgo(RFR,x_train,x_test,Y_train)
分类模型
- 个人认为,分类模型对于这个问题可能是更好的选择。
# 建立 分类模型进行预测,使用网格搜索
# 融合两种模型
pipe = Pipeline([('select',SelectKBest(k = 'all')),('classify',RandomForestClassifier(random_state = 10, max_features = 'auto'))])
# 利用 网格搜索 对融合模型得参数进行最优解搜索
param_test = {'classify__n_estimators':list(range(10,50,2)),'classify__max_depth':list(range(20,80,2))}
gsearch = GridSearchCV(estimator=pipe,param_grid=param_test,scoring='roc_auc',cv=10)
# 分割数据集
split_train,split_test = model_selection.train_test_split(df_test,test_size=0.3,random_state=0)
split_y_train = y_train[:len(split_train)]
# 寻找参数最优解
test = split_test.as_matrix()[:,1:]
X = split_train.as_matrix()[:,1:]
y = split_train.as_matrix()[:,0]
# gsearch.fit(X,y)
# print(gsearch.best_params_, gsearch.best_score_)
# {'classify__max_depth': 20, 'classify__n_estimators': 48} 0.7234027336077584
# # 将选出的 n_estimators = 48、max_depth = 20 带入模型中
select = SelectKBest(k = 20)
clf = RandomForestClassifier(random_state = 10, warm_start = True,
n_estimators = 48,
max_depth = 20,
max_features = 'sqrt')
pipeline = make_pipeline(select, clf)
pipeline.fit(X, y)
# 用 交叉验证 对数据进行预测分析
cv_score = cross_val_score(pipeline, X, y, cv= 10)
# 利用 Mean 和 std 对数据预测情况经行判断
print("CV Score : Mean - %.7g | Std - %.7g " % (np.mean(cv_score), np.std(cv_score)))
Prediction = pipeline.predict(test)
--------------------------------------------------------完结分割线------------------------------------------------------------
基本流程就是这样了,希望对看过的你有所帮助,感谢阅读。