springcloudAlibaba
1、系统架构演变
1.1 单体应用架构
容错率低:比如后台oom内存溢出,整个项目直接垮掉
1.2 垂直应用架构
比如:淘宝后台、天猫后台
1.3 分布式架构
比如:公共模块抽取出来,淘宝和天猫的用户服务、订单服务、商品服务,提高代码复用性
作为一个刚起步的互联网公司,建议使用分布式架构,使用单体或垂直使后续架构拆分的成本增高,
1.4 SOA架构
解决分布式架构中服务调用关系错综复杂,难以维护的问题
比如:加入某个分布式服务压力较大,需要水平拓展,部署在不同的服务器,在调用时,采用nginx轮训机制实现负载均衡,假如某个服务挂掉,治理中心解决了服务间调用关系的自动调节
不同服务使用不同的语言及协议开发,服务在调用时需要不同的处理,增加了处理的复杂度,SOA架构中的治理中心,可以针对不同的语言、不同的协议进行协调,他可以将一种协议转换到另一种协议,达到协议的统一,从而实现协调和调节服务
服务雪崩:比如在一个扇出调用(下单调用订单服务、商品服务、用户服务、库存服务、短信服务等),某一个节点列入短信服务,我们发短信需要调用第三方服务(短信运营平台)进行发送,比如调用时出现了网络波动造成整个线程卡死在这里,从而造成整个调用链路不可用,从而造成服务的雪崩、宕机
1.5 微服务架构
就是针对之前架构的服务进行更加彻底、更加细粒度的服务的拆分。
分布式架构和微服务架构区别:
1、 微服务架构首先也是一个分布式架构,同样是拆分成公共的服务出来,然后部署在不同的服务器,只是微服务架构拆分的更彻底有更多的微服务的协调和治理的组件;
SOA架构和微服务架构的区别
1、微服务架构其实就是SOA架构的升华,治理中心在微服务架构中也有所实现,并且在微服务架构中提供了更多治理协调的组件,并且微服务架构师去中心化的;
2、微服务架构介绍
2.1 常见的微服务架构
- dubbo: zookeeper +dubbo + SpringMVC/SpringBoot
配套 通信方式:rpc
注册中心:zookeeper / redis
配置中心:diamond
只能实现治理中心,有时候还是需要结合springCloud使用
2.SpringCloud:全家桶+轻松嵌入第三方组件(Netflix)(闭源了)
配套 通信方式:http restful
注册中心:eruka / consul
配置中心:config
断 路 器:hystrix
网关:zuul
分布式追踪系统:sleuth + zipkin
3.SpringCloud Alibaba
2.2 微服务架构图


2.3 版本依赖关系


3、实现分布式架构
父maven项目一般是用来聚合子maven项目,父maven项目一般不作为一个具体的项目去使用,也就是不会打成一个jar包去使用
4、nacos注册中心
4.1 核心功能

4.2 主流注册中心区别

4.3 nacos server部署
1、地址:https://github.com/alibaba/nacos/
2、由于我们使用的SpeingCloudAlibaba版本是2.2.5.RELEASE,其对应的nacos版本是1.4.1,在github页面点击release,找到1.4.1,尾部assets,下载nacosServer


3、默认是集群模式,入门改成单机模式,右击编辑

4、点击startup.cmd启动,访问http://localhost:8848/nacos/#/login,用户名和密码都是nacos
4.4 nacos client 搭建
雪崩保护:
阈值保护:设置为0-1之间,健康实例数/实例数<保护阈值
临时实例:spring.cloud.nacos.ephemeral=false;当服务宕机了也不会从服务列表剔除
![]()

上图中权重越大,负载均衡时分到的流量越大。
通常不会设置保护阈值,后面会在sentinel服务熔断降级去完成雪崩保护,所以nacos通常还是作为注册中心使用。
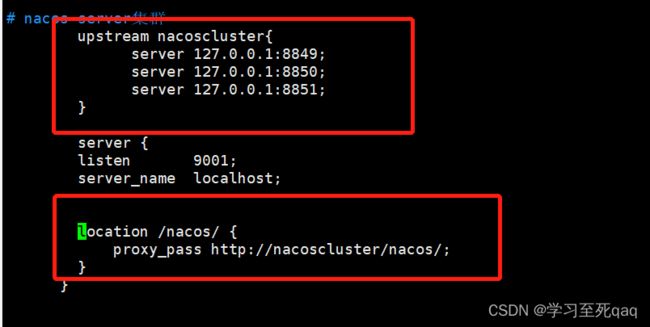
4.5 nacos server linux集群部署

1、下载nacos server :https://github.com/alibaba/nacos/releases
2、上传至服务器,分别解压成三个nacos server

3、修改conf/application.properties配置文件中的port和mysql

4、拷贝cluster.conf.example到当前目录cluster.conf,修改cluster.conf(本地ip:端口)

5、进入bin目录下修改startup.sh,修改内存

6、分别启动3个startup.sh,通过9001端口转发到各个nacos server

7、配置nginx负载均衡
5、Ribbon负载均衡
负载均衡硬件实现:交换机,其效率更高;
nginx最普遍的软件的负载均衡
5.1 客户端的负载均衡

5.2 服务端的负载均衡

5.3 常见的负载均衡算法

5.4 修改默认负载均衡策略
不能写在@SpringbootApplication注解的@CompentScan扫描得到的地方,否则自定义的配置类就会被所有的
RibbonClients共享。 不建议这么使用,推荐yml方式
1、配置config类,在启动类上加@RibbonClients注解,指定该配置类
2、在yml文件中直接指定负载均衡策略,stock-service.
ribbon.NFLoadBalancerRuleClassName=com.alibaba.cloud.nacos.ribbon.NacosRule
3、自定义负载均衡策略,创建策略类继承AbstractLoadBalancerRule,重写choos方法,在yml文件中指定该类,stock-service.ribbon.NFLoadBalancerRuleClassName.NFLoadBalancerRuleClassName=com.jl.ribbon.rule.CustomRule
5.5 饥饿加载
在进行服务调用的时候,如果网络情况不好,第一次调用会超时。
Ribbon默认懒加载,意味着只有在发起调用的时候才会创建客户端

开启饥饿加载,解决第一次调用慢的问题


6、feign
6.1 feign使用
Spring Cloud openfeign对Feign进行了增强,使其支持Spring MVC注解,另外还整合了Ribbon和Nacos,从而使得Feign的使用更加方便
6.2 Spring Cloud Feign的自定义配置及使用
6.2.1 日志配置

1、全局配置:在配置类上加@Configuration,yml文件中修改springboot的日志级别为debug
2、局部配置:注释掉@Configuration注解,在ProductFeignService上添加configuration参数为该配置类的.class文件,如此
3、配置文件设置局部配置:

6.2.2 契约配置
理解:springMVC的注解还原成feign的原生注解
一般是版本升级时使用
使用配置文件或者yml文件配置的方式实现
6.2.3 超时时间配置
6.2.4 自定义拦截器实现认证逻辑
场景:在网关中使用,日志、授权认证等的场景
1、创建拦截器
2、配置类或者yml配置文件使其生效
7、nacos config
7.1 权限管理

7.2 搭建nacos-config服务
1、创建config-nacos服务,启动类中获取environment数据
2、必须使用bootstrap.yml配置文件配置nacos server地址
3、默认配置文件是properties类型,如果是yaml文件类型需要在本地配置文件文件中指定
config.file-extension: yaml
4、动态获取@Value的数据,就需要在controller上加@RefreshScope
8、sentinel
承接了阿里巴巴近十年的双11大促流量的核心场景,主要关注服务高可用的场景
8.1 容错机制
1、超时机制
在不做任何处理的情况下,服务提供者不可用会导致消费者请求线程强制等待,而造成系统资源耗尽。加入超时机制,
一旦超时,就释放资源。由于释放资源速度较快,一定程度上可以抑制资源耗尽的问题。
2、服务限流

3、隔离
原理:用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,则会进行降级
处理,用户的请求不会被阻塞,至少可以看到一个执行结果(例如返回友好的提示信息),而不是无休止的等待或者看
到系统崩溃。
4、服务熔断
远程服务不稳定或网络抖动时暂时关闭,就叫服务熔断。
现实世界的断路器大家肯定都很了解,断路器实时监控电路的情况,如果发现电路电流异常,就会跳闸,从而防止电路
被烧毁。
软件世界的断路器可以这样理解:实时监测应用,如果发现在一定时间内失败次数/失败率达到一定阈值,就“跳闸”,断路
器打开——此时,请求直接返回,而不去调用原本调用的逻辑。跳闸一段时间后(例如10秒),断路器会进入半开状
态,这是一个瞬间态,此时允许一次请求调用该调的逻辑,如果成功,则断路器关闭,应用正常调用;如果调用依然不
成功,断路器继续回到打开状态,过段时间再进入半开状态尝试——通过”跳闸“,应用可以保护自己,而且避免浪费资
源;而通过半开的设计,可实现应用的“自我修复“。
所以,==同样的道理,当依赖的服务有大量超时时,在让新的请求去访问根本没有意义,只会无畏的消耗现有资源。==比如
我们设置了超时时间为1s,如果短时间内有大量请求在1s内都得不到响应,就意味着这个服务出现了异常,此时就没有必
要再让其他的请求去访问这个依赖了,这个时候就应该使用断路器避免资源浪费
5、服务降级
有服务熔断,必然要有服务降级。
所谓降级,就是当某个服务熔断之后,服务将不再被调用,此时客户端可以自己准备一个本地的fallback(回退)回调,
返回一个缺省值。 例如:(备用接口/缓存/mock数据) 。这样做,虽然服务水平下降,但好歹可用,比直接挂掉要强,当
然这也要看适合的业务场景。
8.2 sentinel是什么
![]()

8.3 sentinel控制台
下载sentinel控制台的jar包
https://github.com/alibaba/Sentinel/releases
启动:
java -Dserver.port=8858 -Dsentinel.dashboard.auth.username=hjl -Dsentinel.dashboard.auth.password=hjl -jar sentinel-dashboard-1.8.0.jar
在pom中加入依赖(这里是原生的sentinel,后面只使用sentinel-starter就可以)
com.alibaba.csp
sentinel-transport-simple-http
1.8.0
在idea配置jvm参数
-Dcsp.sentinel.dashboard.server=127.0.0.1:8858
随便访问一个接口将服务注册进去,再刷新页面,请求http://localhost:8858/ U:hjl;P:hjl
8.4 springcloudAlibaba整合Sentinel
1、导入依赖
com.alibaba.cloud
spring-cloud-starter-alibaba-sentinel
流控:通常设置在服务提供方;降级:通常设置在服务消费方
服务重启后在控制台设置的规则都会消失,因为设置的规则没有持久化,都是存储在内存当中的。
2、QPS(每秒访问的请求)流控

3、线程流控

使用两个浏览器分别请求
4、BlockException异常统一处理

关联流控
当访问/order/add的qps为2,访问/order/get被流控



链路流控
对getUser业务方法进行流控,使test2接口访问受限,test1不受限

对getUser的业务方法进行流控,但是只让test2接口受影响(不只是可以对接口进行)
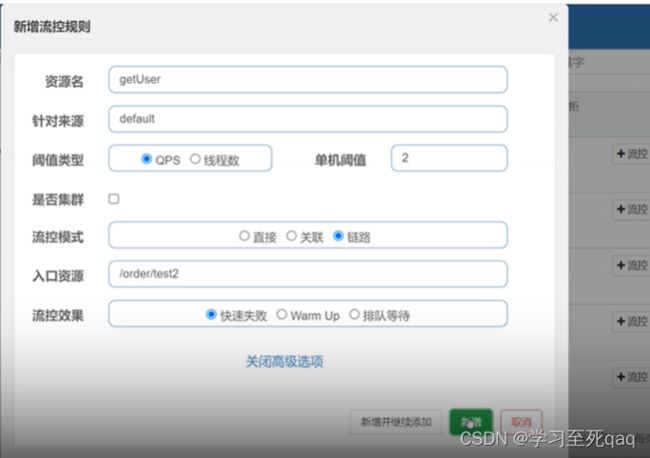
测试无效,需要在yml文件进行配置


测试,此场景拦截不到BlockException,对应@SentinelResource指定的资源必须在@SentinelResource注解中指定
blockHandler处理BlockException
预热和排队等待流控效果
预热流控效果(激增流量)




等待排队流控效果(脉冲流量)
每秒10个线程访问,重复4次,每次间隔5秒,结果应该是每次5个成功5个失败
等待排队效果:利用间隔等待的5秒时间分担流量

快速失败:


熔断降级
与流控的区别:流控在服务提供端,服务降级在服务消费端
慢调用比例

熔断时长:10S内请求直接熔断,10s后进入半开状态,即有1次慢调用直接熔断
异常比例

规则持久化

推荐使用Push模式
1、导入依赖
com.alibaba.csp
sentinel-datasource-nacos
2、配置dataId和内容
seata
事务介绍

本地事务

分布式事务
分布式事务典型场景
当下互联网发展如火如荼,绝大部分公司都进行了数据库拆分和服务化(SOA)。在这种情况下,完
成某一个业务功能可能需要横跨多个服务,操作多个数据库。这就涉及到到了分布式事务,用需要操
作的资源位于多个资源服务器上,而应用需要保证对于多个资源服务器的数据的操作,要么全部成
功,要么全部失败。本质上来说,分布式事务就是为了保证不同资源服务器的数据一致性。


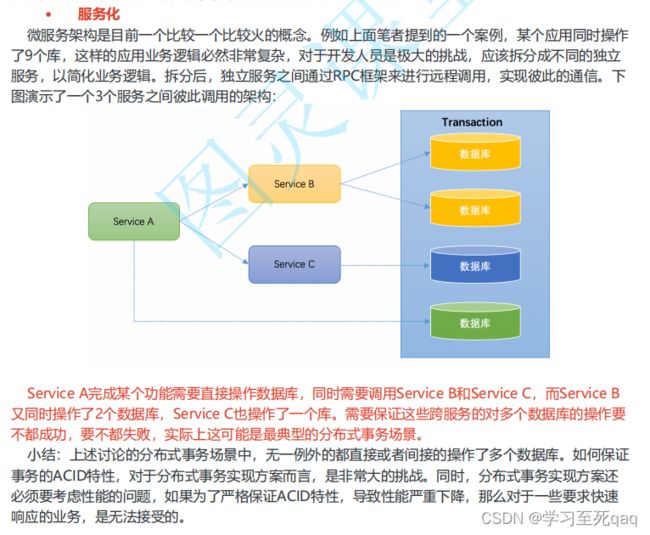
常见分布式事务解决方案

分布式事务理论基础
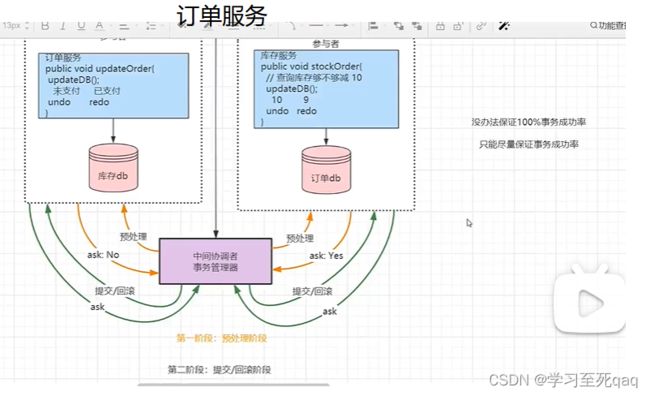
2PC两阶段提交协议
Prepare:提交事务请求
基本流程如下图:

- 询问 协调者向所有参与者发送事务请求,询问是否可执行事务操作,然后等待各个参与者的响应。
- 执行 各个参与者接收到协调者事务请求后,执行事务操作(例如更新一个关系型数据库表中的记录),并将
Undo 和 Redo 信息记录事务日志中。 - 响应 如果参与者成功执行了事务并写入 Undo 和 Redo 信息,则向协调者返回 YES 响应,否则返回 NO
响应。当然,参与者也可能宕机,从而不会返回响应
Commit:执行事务提交
执行事务提交分为两种情况,正常提交和回退。
正常提交事务
流程如下图:


中断事务
在执行 Prepare 步骤过程中,如果某些参与者执行事务失败、宕机或与协调者之间的网络中断,那么协调者就无法
收到所有参与者的 YES 响应,或者某个参与者返回了 No 响应,此时,协调者就会进入回退流程,对事务进行回
退。流程如下图红色部分(将 Commit 请求替换为红色的 Rollback 请求)



AT模式(auto transcation)
AT 模式是一种无侵入的分布式事务解决方案。
阿里seata框架,实现了该模式。
在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架
会自动生成事务的二阶段提交和回滚操作。

AT 模式如何做到对业务的无侵入:





TCC 模式
- 侵入性比较强, 并且得自己实现相关事务控制逻辑
2.在整个过程基本没有锁,性能更强
TCC 模式需要用户根据自己的业务场景实现 Try、Confirm 和 Cancel 三个操作;事务发起方在一阶
段执行 Try 方式,在二阶段提交执行 Confirm 方法,二阶段回滚执行 Cancel 方法。



异步调用

seata部署
地址:https://seata.io/zh-cn/docs/ops/deploy-guide-beginner.html



官网
https://seata.io/zh-cn/docs/ops/deploy-guide-beginner.html
1、下载启动包
步骤一:下载安装包
https://github.com/seata/seata/releases(.gz是适配linux环境;.zip是适配windows环境)
2、Server端存储模式(store.mode)支持三种:
- file:(默认)单机模式,全局事务会话信息内存中读写并持久化本地文件root.data,性能较高(默认)
- db:(5.7+)高可用模式,全局事务会话信息通过db共享,相应性能差些(适用于集群部署)
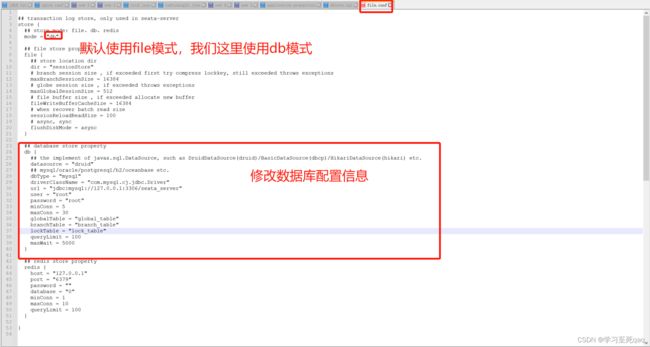
https://github.com/seata/seata/tree/1.4.0/script
中下载mysql的数据表,将script目录拷进seata目录
- redis:Seata-Server 1.3及以上版本支持,性能较高,存在事务信息丢失风险,请提前配置适合当前场景的redis持久化配置
修改/conf/registry.conf文件配置,使其注册进入nacos注册中心
步骤五:配置Nacos注册中心 负责事务参与者(微服务) 和TC通信

获取/seata/script/config-center/config.txt,修改配置信息
修改mode为db,修改数据库配置信息
启动sh脚本文件,将配置信息注册进nacos注册中心
sh ${SEATAPATH}/script/config-center/nacos/nacos-config.sh -h localhost -p 8848 -g SEATA_GROUP -t 5a3c7d6c-f497-4d68-a71a-2e5e3340b3ca -u username -w password
分布式事务client业务搭建
第一步:添加pom依赖
com.alibaba.cloud
spring-cloud-starter-alibaba-seata
第二步: 各微服务对应数据库中添加undo_log表
配置yml文件
gateway

gateway整合sentinel流控降级
1、导入依赖
com.alibaba.cloud
spring-cloud-alibaba-sentinel-gateway
com.alibaba.cloud
spring-cloud-starter-alibaba-sentinel
2、添加配置
sentinel:
transport:
dashboard: 127.0.0.1:8858