1——爬虫学习笔记:【音频数据】
音频数据爬取学习
- 0、需要具备的基础与环境
- 1、代码分块介绍
-
- 1_1、首先导入相应的包
- 1_2、找到研究想要爬取的网页,并用浏览器分析一下
-
- 1_2_1、确定研究对象
- 1_2_3、使用浏览器F12进行分析
- 1_2_4、向我们的对象发起友好的资源请求
- 1_3、发送请求,并研究返回的response中的text
- 1_4、找到特点后,直接将东西都给提炼出来
- 2、整个项目
参考链接【Python实战】听书就用它了:海量资源随便听,内含几w书源,绝对精品哦~
本文是在这篇文章上的基础进行改进的,提供了更多的解释与步骤,保证能够顺利执行代码
本文的主要目的是为了掌握爬虫的基本知识,而不是局限于对某个网页的爬取,因为网页千变万化,但是百变不离其中~
0、需要具备的基础与环境
- 知道python脚本,并知道如何运行
1、代码分块介绍
1_1、首先导入相应的包
import requests
# 正则表达式模块 --> 内置模块 不需要安装
import re
import os
1_2、找到研究想要爬取的网页,并用浏览器分析一下
1_2_1、确定研究对象
我们这里的研究对象为:http://www.ximalaya.com/album/9723091
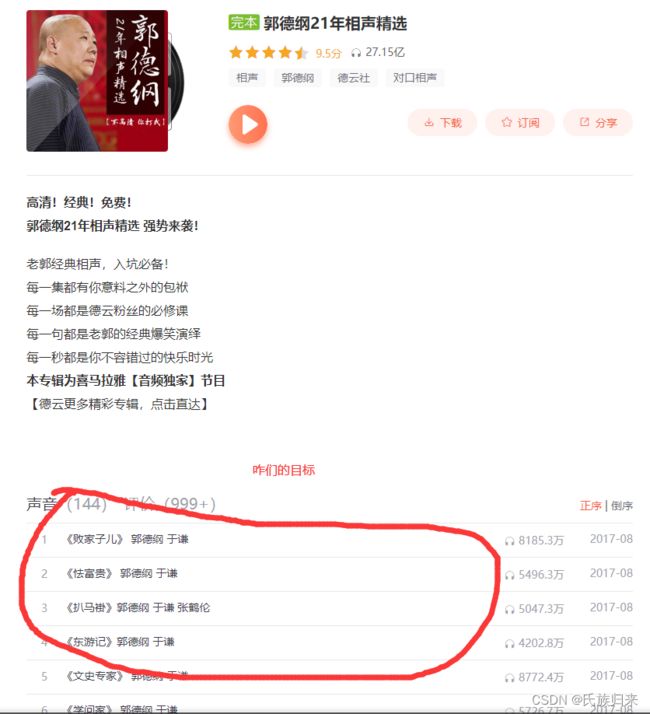
1_2_3、使用浏览器F12进行分析
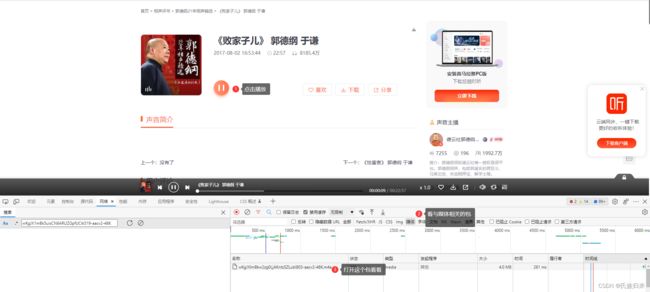
先按下F12,然后点击,再用浏览器抓包分析:

分析三部曲:
找到关键字符
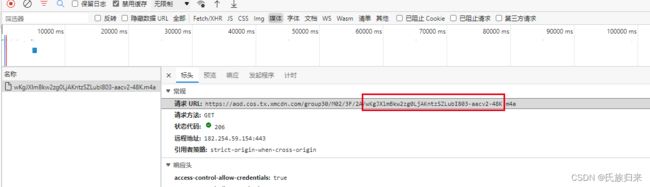
按ctrl+F在包中搜索:wKgJXlmBkw2zg0LjAKntzSZLubI803-aacv2-48K
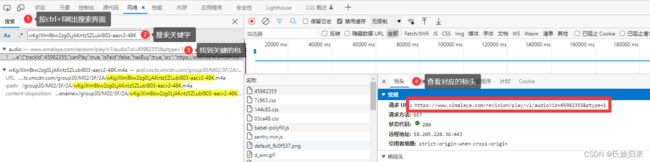
注意这个请求里面有个id=45982355这个玩意,所以我们可以大胆猜测,这个id就是控制到底获取什么音频数据~~~~~
不信的话,可以通过两个音频数据包请求url地址对比(选择另外一个进行播放,重复上述步骤) —> 最终会发现主要改变 id
只要获取所有音频ID, 就可以获取所有音频播放链接
通过搜索 ID 找到ID所在的地方 —> 在什么地方可以获取到所有音频ID
目的: 获取音频播放链接 --> 音频数据包 —> 需要传入音频ID —> 音频列表页面
1_2_4、向我们的对象发起友好的资源请求
"""
1. 发送请求, 模拟浏览器对于 音频列表页面 发送请求
爬虫代码, 需要伪装一下
不伪装, 可能会被反爬 --> 得不到数据, 或者得到数据不是你想要的内容
"""
# 音频列表页面
url = 'http://www.ximalaya.com/album/9723091'
# 伪装模拟 headers 请求头<字典数据类型>
headers = {
# user-agent 用户代理, 表示浏览器基本身份信息
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
1_3、发送请求,并研究返回的response中的text
# 发送请求:
# 调用requests模块里面get请求方法, 对于url地址发送请求, 并且携带上headers请求头伪装, 最后用自定义变量response接受返回数据
response = requests.get(url=url, headers=headers)
# response响应<>对象 200 状态码 表示请求成功
print(response)
# 输出:查找我们的研究对象:观察这些东西的前后文特点
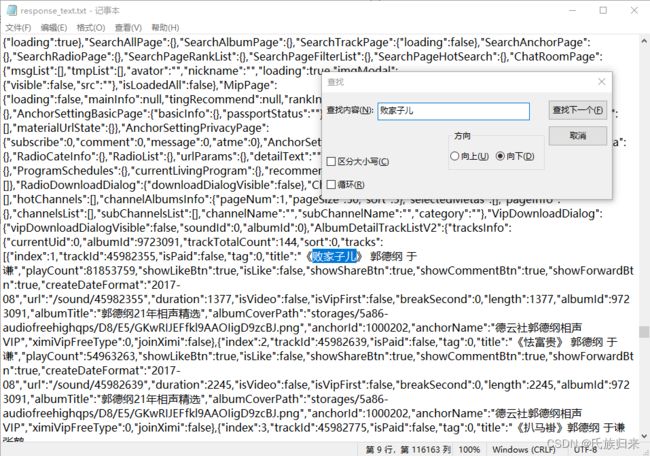
1_4、找到特点后,直接将东西都给提炼出来
"""
"""
2. 获取数据, 获取服务器返回响应数据
开发者工具当中所看到 response
- response.text 获取响应文本数据
这个数据需要肉眼去分析,可以将这个text内容保存下来,然后自己分析一下
3. 解析数据, 提取我们想要的数据内容
- 音频名字
- 音频ID
正则表达式 --> re
调用re模块里面findall方法 --> 找到所有, 找到所有我们想要的数据内容
re.findall('匹配什么数据', '什么地方'): 从什么地方, 去匹配什么数据
- .*? 表示匹配任意字符<除了\n换行符 回车>
- \d+ 表示匹配0个或者多个数字
"""
# 音频名字
titles = re.findall('"tag":0,"title":"(.*?)","playCount"', response.text)
# 音频ID
audio_id_list = re.findall('"url":"/sound/(\d+)","duration"', response.text)
print(titles)
print("-"*80)
print(audio_id_list)
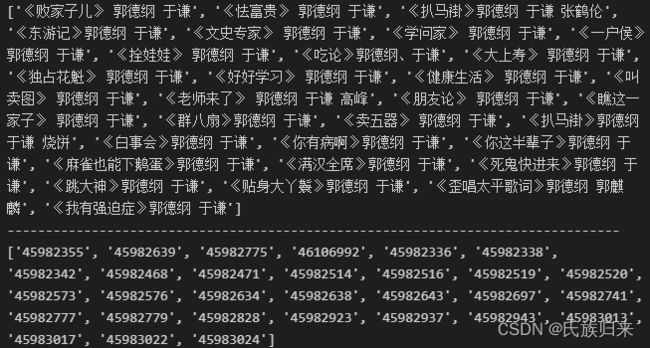
通过相对位置,我们可以看到《败家子儿》和45982355这个id号对应起来了,恰好就是我们在用浏览器分析时候得到的id号~
# for循环遍历, 把列表里面元素一个一个提取出来
for title, audio_id in zip(titles, audio_id_list):
"""
4. 发送请求, 模拟浏览器对于 音频数据包 发送请求
https://www.ximalaya.com/revision/play/v1/audio?id=45982639&ptype=1
5. 获取数据, 获取服务器返回响应数据
开发者工具当中所看到 response
根据开发者工具当中的response的数据显示, 可以选择不同数据获取方式
"""
# 字符串格式化方法 format 把 audio_id 传到 这个链接里面
link = f'https://www.ximalaya.com/revision/play/v1/audio?id={audio_id}&ptype=1'
# 发送请求
response_1 = requests.get(url=link, headers=headers)
# 获取数据 response.json() 获取响应json字典数据
print(response_1.json())
"""
6. 解析数据, 提取我们想要的数据内容
- 音频url
根据字典取值: 键值对取值, 根据冒号左边的内容[键], 提取冒号右边的内容[值]
7. 保存数据
"""
audio_url = response_1.json()['data']['src']
# 对于 音频链接 发送请求, 获取数据
audio_content = requests.get(url=audio_url, headers=headers).content
#保存数据
path = '1_喜马拉雅听书_data/音乐文件'
if not os.path.exists(path):
os.makedirs(path)
with open(path + title + '.mp3', mode='wb') as f:
f.write(audio_content)
print(title, audio_url)
最终效果:


2、整个项目
import requests
# 正则表达式模块 --> 内置模块 不需要安装
import re
import os
"""
1. 发送请求, 模拟浏览器对于 音频列表页面 发送请求
爬虫代码, 需要伪装一下
不伪装, 可能会被反爬 --> 得不到数据, 或者得到数据不是你想要的内容
"""
# 音频列表页面
url = 'http://www.ximalaya.com/album/9723091'
# 伪装模拟 headers 请求头<字典数据类型>
headers = {
# user-agent 用户代理, 表示浏览器基本身份信息
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求:
# 调用requests模块里面get请求方法, 对于url地址发送请求, 并且携带上headers请求头伪装, 最后用自定义变量response接受返回数据
response = requests.get(url=url, headers=headers)
# response响应<>对象 200 状态码 表示请求成功
print(response)
"""
2. 获取数据, 获取服务器返回响应数据
开发者工具当中所看到 response
- response.text 获取响应文本数据
这个数据需要肉眼去分析,可以将这个text内容保存下来,然后自己分析一下
3. 解析数据, 提取我们想要的数据内容
- 音频名字
- 音频ID
正则表达式 --> re
调用re模块里面findall方法 --> 找到所有, 找到所有我们想要的数据内容
re.findall('匹配什么数据', '什么地方'): 从什么地方, 去匹配什么数据
- .*? 表示匹配任意字符<除了\n换行符 回车>
- \d+ 表示匹配0个或者多个数字
"""
# 音频名字
titles = re.findall('"tag":0,"title":"(.*?)","playCount"', response.text)
# 音频ID
audio_id_list = re.findall('"url":"/sound/(\d+)","duration"', response.text)
# for循环遍历, 把列表里面元素一个一个提取出来
for title, audio_id in zip(titles, audio_id_list):
"""
4. 发送请求, 模拟浏览器对于 音频数据包 发送请求
https://www.ximalaya.com/revision/play/v1/audio?id=45982639&ptype=1
5. 获取数据, 获取服务器返回响应数据
开发者工具当中所看到 response
根据开发者工具当中的response的数据显示, 可以选择不同数据获取方式
"""
# 字符串格式化方法 format 把 audio_id 传到 这个链接里面
link = f'https://www.ximalaya.com/revision/play/v1/audio?id={audio_id}&ptype=1'
# 发送请求
response_1 = requests.get(url=link, headers=headers)
# 获取数据 response.json() 获取响应json字典数据
print(response_1.json())
"""
6. 解析数据, 提取我们想要的数据内容
- 音频url
根据字典取值: 键值对取值, 根据冒号左边的内容[键], 提取冒号右边的内容[值]
7. 保存数据
"""
audio_url = response_1.json()['data']['src']
# 对于 音频链接 发送请求, 获取数据
audio_content = requests.get(url=audio_url, headers=headers).content
#保存数据
path = '1_喜马拉雅听书_data/音乐文件'
if not os.path.exists(path):
os.makedirs(path)
with open(path + title + '.mp3', mode='wb') as f:
f.write(audio_content)
print(title, audio_url)