Hugging Face 最新工作详解,研究负责人 Douwe Kiela 提出新型多模态任务评测基准...

导读:随着 DALLE、CLIP 等里程碑式工作的横空出世,「视觉-语言」多模态任务成为了目前人工智能领域最火热的话题之一。近日,Hugging Face 研究负责人、斯坦福大学兼职教 Douwe Kiela 针对当前「视觉-语言」预训练任务存在的评测任务瓶颈展开了讨论,介绍了其团队在 NeurIPS、CVPR 等顶级会议上提出的新型多模态评测任务「Hateful Memes」、「AdVQA」、「Minoground」,以及它们针对上述新任务提出的基础性「视觉-语言」对齐模型「FLAVA」。
讲者:Douwe Kiela
整理:熊宇轩
编辑:李梦佳
注:本文为「2022北京智源大会」报告,回放视频请看:
https://2022-live.baai.ac.cn/2022/live/?room_id=17479
在真实世界中理解语言背后的意图
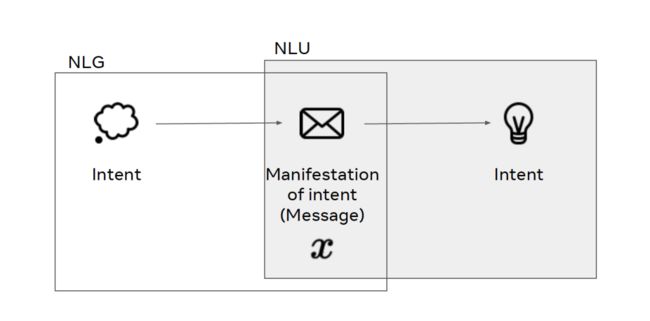
Kiela 在其研究生涯的大部分实践中专注于「让机器理解语言真正的意义」,这种语义是人类所理解的意义,而不仅仅是存在于计算机中的「虚假意义」。
从哲学的角度来说,对语言的定义还存在一定的争议。Kiela 认为,语言是思维的表现,它是一种消息,传递了一些真实的意图。人类精神世界的意图通过消息传递出来,沟通中的另一方也可以以此推断出正确的意图。
用自然语言处理(NLP)的术语来说,我们可以将上图中根据真实意图产生消息的过程看做自然语言生成(NLG),将根据消息推断意图的过程看做自然语言理解(NLU),而语言则是将从真实意图到推断意图的映射。
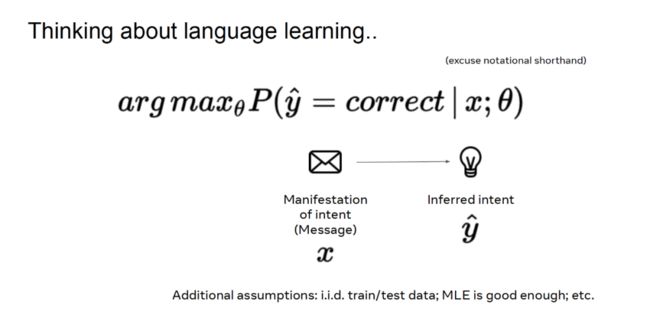
在机器学习领域中,我们根据给定的数据找到合适的映射模型的参数。具体到语言学习过程中,给定意图的表现(消息 x),我们要最大化预测意图正确的概率。对于大多数机器学习任务,我们往往假设训练数据和测试数据满足独立同分布,可以通过极大似然估计(MLE)来捕获底层流形。
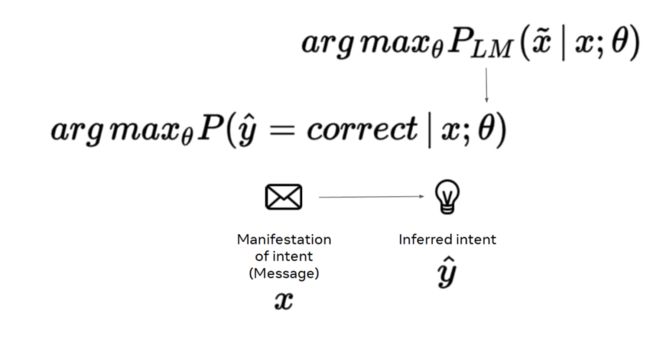
如今,我们往往通过预训练的语言模型初始化模型参数,而非随机初始化。在预训练过程中,我们通过在巨大的语料库上进行一些基础的语言建模任务(例如,掩码语言模型)得到模型的初始化参数,进而完成极大似然估计任务。
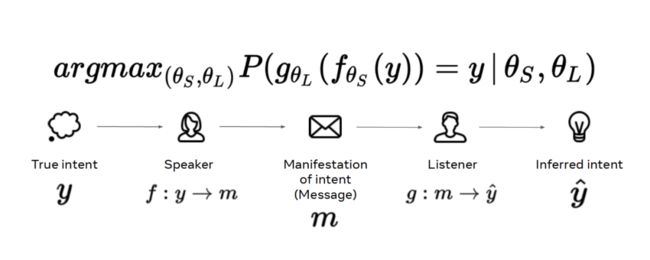
这种做法实际上将实际的语言问题极大简化了。人类真实的语言行为并不是直接将真实意图 y 通过信息 x 映射为预测![]() 。对于人类来说,语言问题还涉及两个独立的函数:说话者 f 和倾听者 g。f 将真实意图映射为消息,g 将消息映射为预测的意图。我们要单独地对说话者和倾听者函数进行参数化,再将这些函数组合起来。
。对于人类来说,语言问题还涉及两个独立的函数:说话者 f 和倾听者 g。f 将真实意图映射为消息,g 将消息映射为预测的意图。我们要单独地对说话者和倾听者函数进行参数化,再将这些函数组合起来。
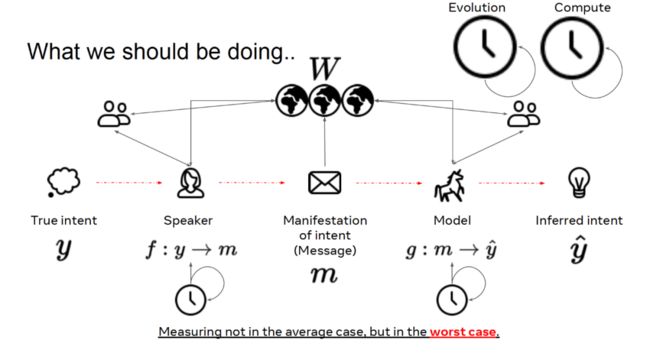
在现实世界中,情况往往更加复杂,对话的参与者不仅仅限于说话者和倾听者两方,可能周围还有其它参与对话的人。这种对话环境充满各种可能性,谈论的话题甚至可能是并不存在的事务(例如,独角兽)。我们确保所说的话与其它相同语言社会中的说话者和倾听者者兼容一致。这涉及到对宏观演进过程的先验、对文化的先验,以及我们个人的经验。因此,我们也要考虑时序信息,这与我们随时间学习、掌握语言、将语言用于沟通是有关的。
如前文所述,我们在现有的机器学习任务中,将真实意图转化为体现意图的消息文本,将其输入给通过分布式统计量初始化的模型,进而使用该模型推断标签。然而,这种做法忽略了语言中的大量其它因素,将问题过于简化了。
多模态任务的评估
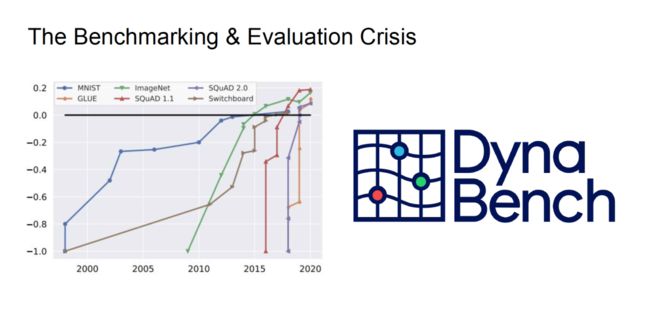
近十年来,人工智能技术突飞猛进,以令人难以置信的速度发展着。如上图所示,黑色的直线代表人类水平。著名的 MNIST 数据集发布于 2000 年前后,机器学习研究者们花费了近 20 年才在该数据集上取得「饱和」的性能。但是,橙色折现代表的 GLUE 任务几乎一经发布就被解决了。从评测任务和评价指标上看,我们似乎解决了所有的问题,但实际的问题要比这些评测任务复杂得多,这意味着我们在该领域遭遇了评测基准或评价指标的「危机」。
因此,研究者们需要与复杂场景更相近的评测方式。Kiela 在报告中提到,他们的团队目前使用了动态基准测试平台「Dyna Bench」,试图找到更好的评测任务和指标。
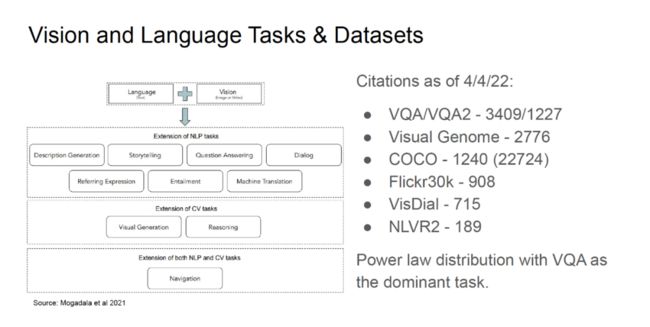
如上图所示,视觉、语言任务所使用的数据集的引用量存在一定的「幂律分布」现象。其中,VQA/VQA2 数据集(视觉问答)的引用量最高,其次是 Visual Genome(场景理解)、COCO(图片描述)等数据集。其中,VQA 是「视觉-语言」领域中目前最流行的任务。目前,深度学习模型在 VQA 任务上的性能也趋近于饱和,然而我们并没有真正解决所有的问题。

因此,「视觉-语言」等多模态任务需要新的评估设置。通常而言,好的评估设置应该具有以下特性:
(1)数据质量高,几乎没有标注误差
(2)构建成本可接受
(3)任务具有足够难度
(4)足以区分模型的性能
(5)与真实场景接近,对现实用例具有代表性
(6)有简单直接的评测方法
除此之外,针对多模态任务的评估设置还应该做到:
(1)不被某一种特定的模态所主导,各模态的数据较为均衡
(2)能真正评测模型在多模态数据上的性能,而非仅利用单一模态
在本文中,Kiela 重点讨论了信息、模型、世界环境之间的关系,而世界环境主要通过视觉表征,模型根据消息和对世界环境的观测学习。
Hateful Memes 数据集
人们在 VQA 任务上开展了丰富的研究,但是该任务与现实世界中的用例需求还有很大的区别。研究人员希望新的评测任务需要真正进行多模态的推理和理解。

在 Facebook 工作期间 Kiela 发现「厌恶言论分类器」在单模态情况下的性能良好,而在多模态场景下的性能则大打折扣。为此,Kiela 等人提出了「Hateful Memes」(令人厌恶的表情包)任务。如上面的示意图(并非真正来自于数据集)所示,如果在臭鼬的图片上附上「喜欢你今天的味道」,或者在一片沙漠的图片上附上「看看有多少人爱你」,这会令人感到不悦。但是如果我们在玫瑰的图片上附上「喜欢你今天的味道」或一群人的图片上附上「看看有多少人爱你」,那就会令人感到开心。
可见,通过替换图像可能会改变分类标签。如果分类器可以区分上述图片,对其进行正确的分类(令人厌恶/不令人厌恶),就可以真正具备多模态推理和理解的能力,而非仅仅利用单一模态的表层特征。
数据集构建过程
为构建 Hateful Meme 数据集,Kiela 等人首先选择了经过训练的标注者,从而确保标注的质量,但是这些标注者的数量较少且费用较高。
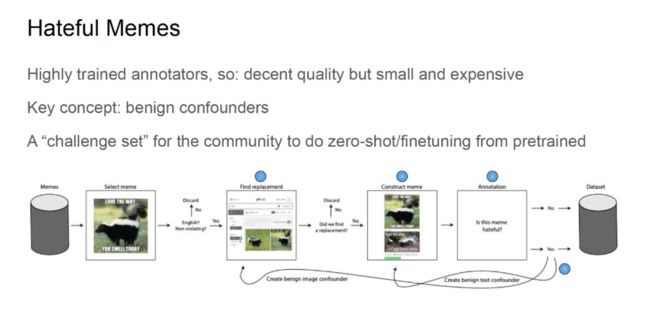
在构建数据集的过程中,「良性混杂因素」十分关键。Kiela 等人在互联网上收集了大量的表情包,他们首先检查表情包是否使用英语且符合法律、技术、版权等要求,丢弃不符要求的表情。
标注者们将符合要求的表情中的背景图像替换,将替换背景后的表情及标注者赋予的标签(是否令人厌恶)存储到数据中。对于令人厌恶的图像,他们还分别创建了良性文本混杂因素和良性图像混杂因素,进一步创建了更多不令人讨厌的表情。

Kiela 等人在这项工作中发现,现有的最优模型与人类在 Hateful Memes
上的表现仍然存在巨大差距,其准确率分别为 69% 和 84%。此外,研究者们发现了一些有趣的现象:
(1)使用局部区域的特征可以获得远超使用全局网格特征的性能,图像预处理的作用很大
(2)进行模态间早融合的性能优于中期融合和晚融合
(3)目前的多模态预训练在该任务上并未取得显著作用
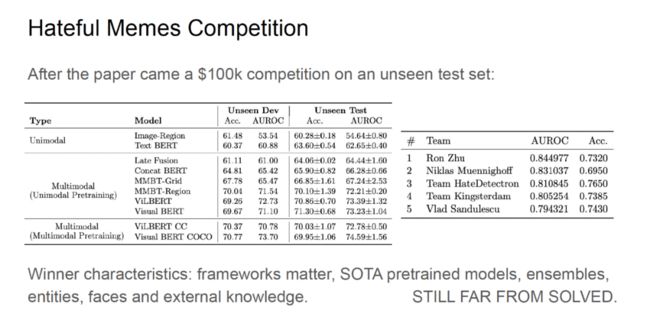
「Hateful Memes」数据集发布后,Kiela 等人组织了同名竞赛,要求模型未见过的测试数据集上做出预测,该赛事的奖金高达 10 万美元。对比基线在新的未见过的数据集上的性能与在原始测试数据集上展现出了相似的性能。尽管参赛者在该赛事中取得了很高的 AUROC 得分,但是模型性能距离人类水平还相差甚远。
获得一名的团队基于「PaddlePaddle」框架实现了很多当前最优的预训练模型,从而获得了很高的准确率得分。此外,外部知识的引入也对性能提升有很大帮助。
对抗性VQA
由于 VQA 广受研究社区的欢迎,Kiela 等人也尝试对 VQA 评测任务进行改进,从而提出了「对抗性 VQA」任务。该任务首席在构建数据集的回路中同时引入人类和模型,在「Dyna Bench」平台上实现了动态的对抗性数据收集。
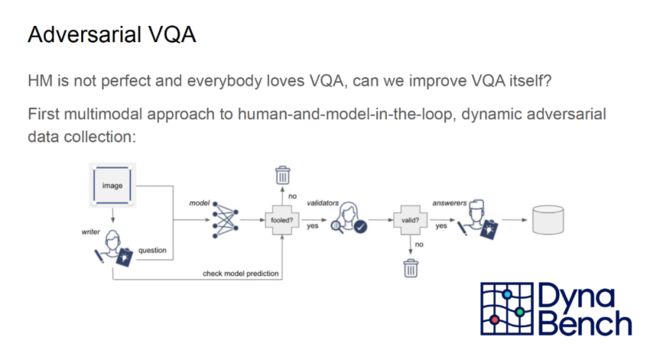
首先,标注者针对图像提出一个问题,并将该问题输入给图像。接着,标注者查看模型的答案是否合理。如果模型的答案合理,则不使用该图像和问题;反之,验证人员将再次确认图像和问题是否有意义。若通过验证,则由人类回答者给出问题的合理答案。最终,图像、问题、答案会被存储到数据集中。在整个过程中,模型并不知道正确的答案。

VQA 问题目前并未被真正完全解决。如上图右侧所示,当我们提出「电视机的品牌是什么」、「猫的领带上有几个卡通图案」等问题时,模型给出的答案大多是错误的。在对抗性 VQA 任务上,目前最优的模型甚至比使用「多数」答案构建的基线更低。
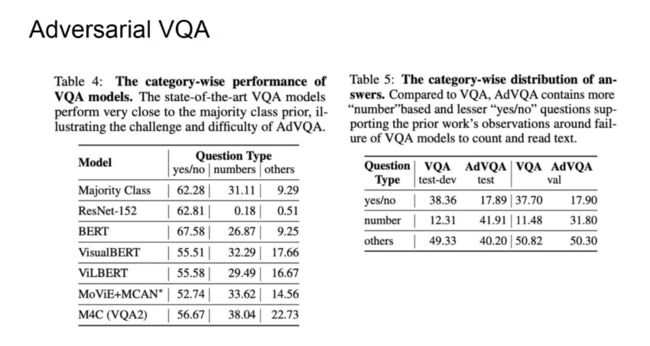
在工作中,Kiela 等人发现,除 Bert 之外的大多数现有的最好的模型在「Yes/No」问题上甚至弱于用「多数」类作为答案的对比基线。在计数任务和其它任务上,也存在类似的现象,模型的性能很低。

微软的研究团队几乎与 Kiela 等人同一时间提出了对抗性 VQA 的另一版本,该数据集可以在「adversarialvqa.org」上下载。研究者们分别利用 COCO 的中的图像和 Conceptual Captions 中的图像构建了「In-Domain」版的数据集和「Out-of-Domain」版的数据集。
Winoground
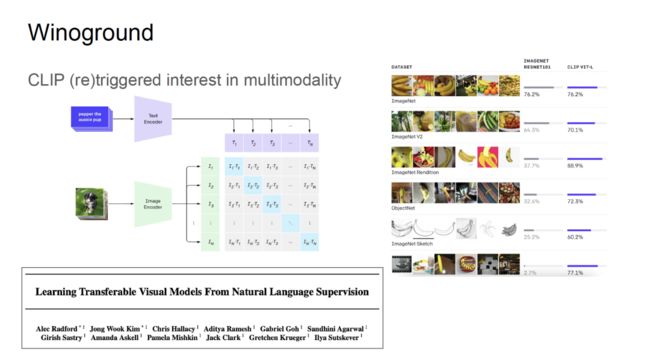
OpenAI 的 CLIP 是一项革命性的工作,让多模态研究焕发了新生,成为了人工智能领域的下一个研究前沿。与在 ImageNet 上预训练的 ResNet 类模型相比,CLIP 不仅可以在 ImageNet 上取得很好的准确率,CLIP 在鲁棒性测试任务中也有很好的表现。而 ResNet 类的模型在这些鲁棒性测试中性能极差。

为了探寻 CLIP 成功的原因,Kiela 等人借鉴 NLP 领域中的思路,利用 Winograd 方法测试了 CLIP 的性能。例如,在句子「The [trophy] doesn't fit in the [suitcase] because it is too [large/small]」中,若选用词「large」,则「it」指代的是「trophy」;若选用词「small」,则「it」指代的是「suitcase」,而现有的人工智能算法很难完成这种识别任务。
此外,如上图右上角所示,Kiela 等人在论文「Masked Language Modeling and the Distributional Hypothesis」中,通过不同的语序组织相同的词语构成两句不同的句子,将其输入给模型,通过模型生成的图像检测模型是否能够真正进行「视觉-语言」组合推理。
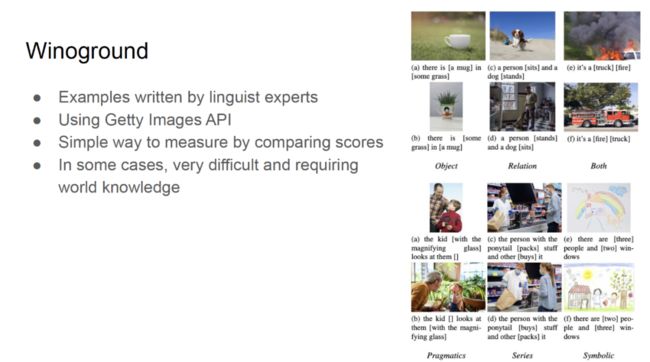
为了构建 Winoground 数据集,Kiela 等人首先邀请了语言学专家编写文本示例。接着,他们通过 Getty 图像 API 确保了将该数据集发布到研究社区中的合法性。在大多数情况下,人类可以很直观、轻易地理解 Winoground 中不同语序的图文对,研究人员希望人工智能系统也能够做到这一点,而评测比较分数是一种很简单的评测方法。

现有的最优模型在 Winoground 数据集上表现欠佳。其中,VinVL/UNITER/ViLLA 模型的得分相对最高,获得了 37-38 分。然而,这与人类的水平——89 分还有很大的差距。Kiela 等人对各种类别、各种数据的组合方式进行了测试,发现模型会退化到较弱的单一模态先验上,只利用文本或图像。
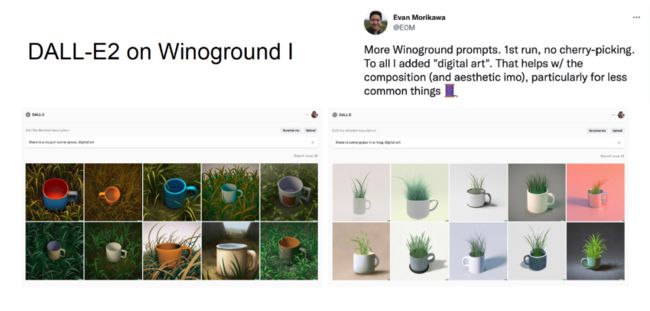
Winoground 发布后,OpenAI 发布了 DALLE-E2,它们在 Winoground 上测试了 DALLE-E2 的性能。DALLE-E2 是一种生成式模型,这与 Winoground 对图文对进行对比的设定并不完全一致。但是,如上图所示,DALLE-E2 有时在 Winoground 上的效果非常好。
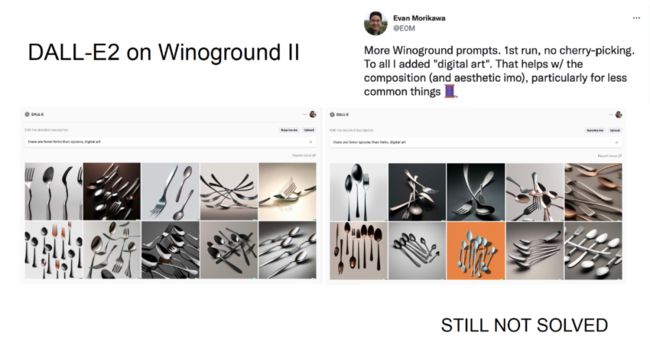
然而,在上图所示的更深入的实验中,DALLE-E2 有时无法严格地根据指令文本生成比叉子更少的勺子,模型仍然未完全「理解」数量关系。
FLAVA:基础性的语言和视觉对齐
除了构建多模态任务的评测任务,Kiela 团队在「FLAVA:基础性的语言和视觉对齐」一文中也提出了对这些评测任务的解决方案。在该工作中,他们从头开始训练了一个多模态预训练模型。这是因为,在现实世界和互联网环境下,许多任务需要同时利用文本、视频、音频等模态的数据。这与人脑理解世界的方式是一致的,各种模态之间可以互补,提供不同的视角。此外,通过共享参数,可以迁移模型的知识,提升样本效率。通过上述方法,Kiela 等人构建了一种模态无关的大型语言模型,将其作为基础性的模型。

为了构建这种基础模型,研究人员面临以下困难:
(1)为了实现「视觉-语言」对齐,我们需要大量的图文对数据,然而成对的多模态数据往往数量有限;
(2)CLIP 的成功在很大程度上归功于他们在构建图文对语料库上的努力,然而这些数据并未无偿公开,研究人员无法在相同的数据集上复现 CLIP;
(3)设计跨模态联合学习架构十分困难;
(4)现有的预训练往往针对特定的领域设计,例如:针对视觉任务设计的 Moco、SimCLR 和针对语言任务设计的 Bert、RoBERTa;
(5)在缺乏图文对数据时,如何利用单一模态的数据;
(6)对巨大算力的需求;

FLAVA 是一种全面的多模态模型,这种基础性模型在 35 项「视觉-语言」、计算机视觉、自然语言处理任务上都拥有很好的表现。Kiela 等人在单一模态文本数据、单一模态视觉数据、公开的图文对数据上联合训练了 FLAVA 模型,推动了上述领域的发展。
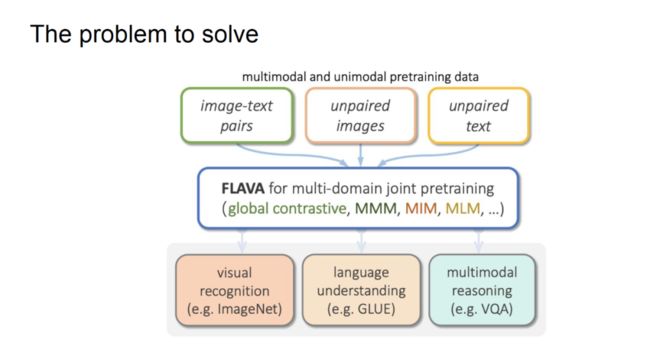
Kiela 等人将图文对多模态数据和图像、文本单一模态数据输入给 FLAVA 模型,针对不同的任务(全局对比损失、MMM、MIM、MLM)设计了各种损失,希望模型能够完成多模态推理、语言理解、视觉识别等任务。
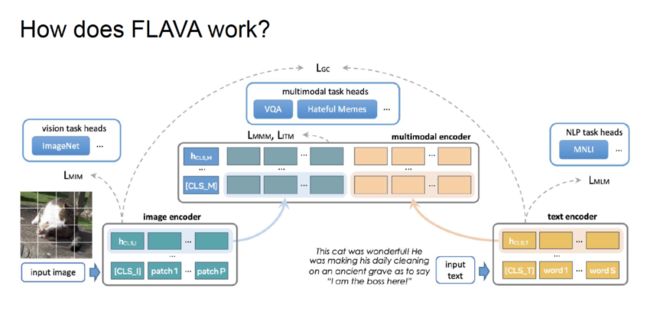
在视觉方面,图像被划分为若干个图块(patch),这些图块会被输入给 ViT 等视觉 Transformer 模型,并通过顶层的分类头完成图像识别任务。在该过程中,研究人员将图块作为词例(Token),通过掩码图像建模(MIM)训练模型。
在语言方面,文本被划分为若干个词例(Token),这些词例被输入给 Transformer 模型,通过标准的掩码语言建模(MLM)训练,顶层的 NLP 任务头会被用于完成 MNLI(多类型自然语言推理)等任务。
基于上述单一模态的表征,Kiela 等人构建了一个 Transformer 多模态编码器,将单一模态进行早融合,通过掩码多模态建模完成 VQA、Hateful Memes 等任务。此外,Kiela 等人还采用了与 CLIP 类似的全局对比损失,从而确保各模态的表征被对齐。

Kiela 等人构建了多模态图文对数据集 PMD,该数据集可以公开访问,包含约 7 千万个图文对数据,具有较高的标注质量。
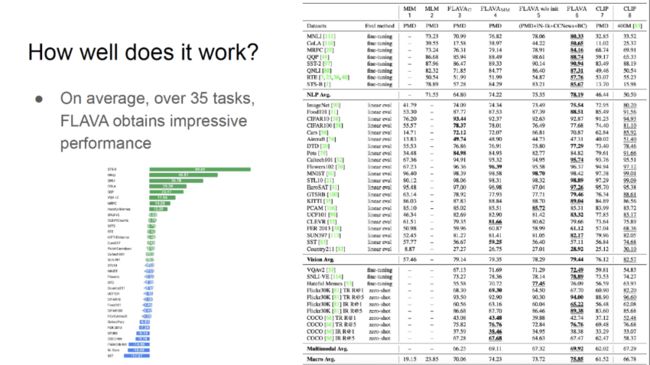
在 35 项下游任务上,FLAVA 都取得了优异的性能,在多项任务上优于 CLIP。FLAVA 模型在大多数消融实验设定下的性能也都优于 CLIP。
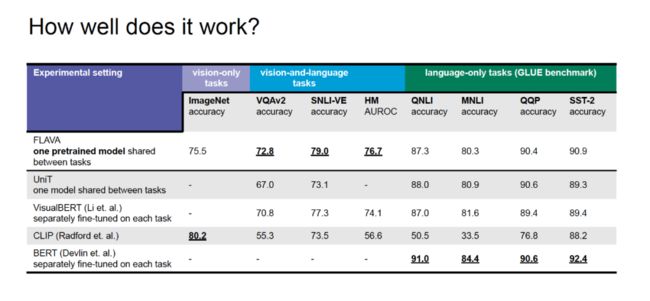
如上图所示,在视觉任务中,FLAVA 的最佳性能弱于 CLIP;在「视觉-语言」任务上,FLAVA 的性能显著优于 CLIP;在自然语言处理任务上,FLAVA 的性能优于 CLIP,但弱于专门针对语言任务设计的 BERT。
结语
目前,如何整合各种数据,设计出在各模态任务上均具有最佳性能的模型是学界研究的前沿课题。为此,研究人员面临着许多难题:
(1)数据方面,Kiela 等人发布了 PMD 公开数据集
(2)模型架构方面,Kiela 等人基于 Transformer 模型设计不同模态下的掩码建模任务
(3)联合训练方面,Kiela 等人提出了 FLAVA 模型
(4)需要强大的算力。
未来,研究人员还需要探索如何在不同的 Transformer 之间共享参数,将各种知识融合在一起,让模型更加全面地理解概念。更多更大的模型将被提出,研究人员将利用更多的数据和更多的模态训练这些模型。

目前,Hugging Face 已经发布了 FLAVA 和 Winoground,PMD 数据集也即将公开,从而形成闭环。在图像、对抗性 VQA 任务上,FLAVA 的性能明显优于先前最佳的模型。
推荐阅读

清华大学车辆学院李升波|强化学习,让自动驾驶汽车自我进化,越开越好

梅宏院士:如何构造人工群体智能?| 智源大会特邀报告回顾

图灵奖得主Adi Shamir最新理论,揭秘对抗性样本奥秘 | 智源大会特邀报告回顾