大数据采集与预处理
大数据采集与预处理
@Time 2022 / 6 / 10
内部特供 版权所有 翻版必究

文章目录
- 大数据采集与预处理
-
- 第一章 大数据概述
-
- 1.1 技术支撑
- 1.2 大数据三阶段
- 1.3 大数据特点
- 1.4 大数据处理过程
- 1.5 大数据关键技术
- 1.6 大数据技术体系
- 1.7 传统数据采集与分布式大数据采集
- 1.8 分布式架构的大数据采集平台
- 第二章 数据采集基础
-
- 2.1 传统数据的采集
-
- 2.1.1 数据采集概述
-
- 2.1.1.1 概念
- 2.1.1.2 数据采集系统的任务
- 2.1.1.3 数据采集系统的好坏
- 2.1.1.4 传统数据采集的特点
- 2.1.2 数据采集系统架构
-
- 2.1.2.1 集散型数据采集系统
- 2.1.2.2 数据采集系统的软件
- 2.1.3 数据采集关键技术
-
- 2.1.3.1 采样技术
- 2.1.3.2 量化技术
- 2.1.3.3 编码技术
- 2.2 数据采集基础
-
- 2.2.1 数据的发展
- 2.2.2 大数据主要来源
-
- 2.2.2.1 大数据分类
- 2.2.3 大数据采集技术
-
- 2.2.3.1 数据采集面临的挑战和困难
- 2.2.3.2 大数据采集常用方法
- 2.2.4 采集框架对比
- 第三章 大数据采集架构
-
- 3.1 Flume
-
- 3.1.1 定义
- 3.1.2 架构图
- 3.1.3 组件定义及功能
- 3.1.4 运行机制
- 3.2 Kafka
-
- 3.2.1 定义
- 3.2.2架构图
- 3.2.3 组件定义及功能
- 3.2.4 push-and-pull消息机制
- 3.2.5 Zookeeper
- 3.2.6 架构核心特性
- 3.3 Scribe
-
- 3.3.1 组成
- 第四章 大数据迁移技术
-
- 4.1 数据迁移的原因
- 4.2 数据迁移定义
- 4.3 数据迁移的三个阶段:
- 4.4 数据迁移相关技术
-
- 4.4.1 基于主机的迁移方式
- 4.4.2 基于存储的数据迁移
- 4.4.3 备份恢复的方式
- 4.4.4 基于主机逻辑卷的迁移
- 4.4.5 基于数据库的迁移
- 4.4.6 服务器虚拟化数据迁移
-
- 其他数据迁移技术
- 4.5 数据迁移三种工具
-
- 4.5.1 Sqoop
- 4.5.2 ETL处理流程
- 4.5.3 Kettle
- 第五章 互联网数据抓取与处理技术
-
- 5.1 网络爬虫定义
- 5.2 网络爬虫功能
- 5.3 网络爬虫的抓取策略
- 5.4 网页更新策略
- 5.5 网络爬虫分类
-
- 5.5.1 按功能划分
- 5.5.2 按系统结构和实现技术划分
- 5.6 网络爬虫工具
- 第六章 数据预处理技术
-
- 6.1 数据对象与属性类型
-
- 6.1.1 标称属性
- 6.1.2 二元属性
- 6.1.3 序数属性
- 6.1.4 数值属性
- 离散属性与连续属性
- 6.2 数据的统计描述
-
- 6.2.1 数据预处理
- 6.2.2 数据质量
- 6.2.3 数据预处理的主要任务
-
- 数据清洗定义
- 数据集成定义
- 数据规约定义
- 数据变换定义
- 6.3 数据清洗
-
- 6.3.1 数据清洗原理
- 6.3.1 数据清洗常用方法
- 6.4 数据归约
-
- 6.4.1 经典数据归约策略
- 6.4.2 常用方法
-
- 6.4.2.1 小波变换
- 6.4.2.2 主成分分析
- 6.4.2.3 属性子集选择
- 6.4.2.4 回归和对数线性模型
- 6.4.2.7 抽样
- 6.4.2.8 数据立方体聚集
- 6.5 通过规范化变换数据
-
- 6.5.1 常用的数据规范化方法
- 6.6 通过离散化变换数据
- 6.7 标称数据的概念分层变换
-
- 6.7.1 常用的标称数据概念分层方法
- 习题整理
第一章 大数据概述
1.1 技术支撑
- 存储设备容量不断增加
- CPU处理能力大幅提升
- 网络带宽不断增加
1.2 大数据三阶段
传统数据库阶段
互动式互联网阶段
智慧社会阶段
1.3 大数据特点
-
大量化 数据大量化即大数据要处理的数据量巨大,从TB级上升到ZB级甚至更高的数据集
-
快速化 有的数据是爆发式产生,有的是由于用户众多,短时间内产生庞大的数据量
-
多样化
数据格式变得越来越多样,涵盖了文本、音频、图片、视频、模拟信号等不同的类型
数据来源也越来越多样,不仅产生于组织内部运作的各个环节,也来自于组织外部
-
价值化 传统数据的价值是显性的 大数据的价值是潜在的,需要针对某些价值主题进行挖掘
1.4 大数据处理过程

1.5 大数据关键技术
大数据采集
- 获取大数据是大数据分析处理的重要基础
- 数据采集,又称数据获取,是处于大数据生命周期的第一个环节,它是通过RFID射频数据、传感器数据、社交网络、移动互联网等方式获取各种类型的结构化、半结构化和非结构化的海量数据
大数据预处理
- 现实世界中,数据通常存在不完整、不一致的“脏”数据,无法直接进行数据挖掘,或挖掘结果差强人意,为了提高数据挖掘的质量产生的数据预处理技术
采集到的原始数据通常存在问题如下:杂乱性 重复性 不完整性
常见数据预处理技术
数据清理:异常数据清理,数据错误纠正,重复数据的清除等目标
数据集成:将多个数据源中的数据结合起来并统一存储,建立数据仓库
数据变换:通过平滑聚集,数据概化,规范化等方式,将数据转换成适用于数据挖掘的形式
数据规约:寻找依赖于发现目标的数据的应用特征,以缩减数据规模,从而在尽可能保持数据原貌的前提下,最大限度的精简数据量
大数据存储
- 大数据存储与管理要用存储器把采集到的大规模数据存储起来,建立相应的数据库,并进行管理和调用
- 大数据存储通常采用分布式文件系统、NoSQL数据库以及云存储等技术
- 分布式文件系统(DFS) :是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而通过计算机网络与节点相连。如HDFS
- 非关系型数据库NoSQL:区别于传统的关系数据库SQL,NoSQL保证系统能提供海量数据存储的同时具备优良的查询性能。如Hbase等
- 云存储:是指通过集群应用、网格技术或分布式文件系统等功能,将网络中大量各种不同类型的存储设备通过应用软件集合起来协同工作,共同对外提供数据存储和业务访问功能的一个系统。如阿里云
数据挖掘
- 数据挖掘是数据库知识发现(KDD)中的一个步骤。常用数据挖掘方法包括:
- 关联分析 聚类分析 分类分析 预测建模 机器学习 深度学习 集成学习
大数据可视化
- 大数据可视化是利用计算机图形学和图像处理技术,将数据转换为图形或图像在屏幕上显示出来,并进行交互处理的技术,这种技术可以更为直观地表达数据,从而发现数据隐含的规律。
- 标签云 历史流图 聚类图 空间信息流 热图
1.6 大数据技术体系
- 数据采集与预处理技术
- 分布式数据存储技术
- 分布式计算技术

1.7 传统数据采集与分布式大数据采集
- 传统数据采集:数据来源单一,数据结构简单,且存储、管理和分析数据量也相对较小,大多采用集中式的关系型数据库或并行数据仓库即可处理。
- 分布式大数据采集:更高的数据访问速度、更强的可扩展性、更高的并发访问量
1.8 分布式架构的大数据采集平台
Apache Chukwa Flume Scrible Apache kafka
第二章 数据采集基础
2.1 传统数据的采集
2.1.1 数据采集概述
2.1.1.1 概念
- 数据采集( Data Acquisition)是指将要获取的信息通过传感器转换为信号,并经过对信号的调整、采样、量化、编码和传输等步骤,最后送到计算机系统中进行处理、分析、存储和显示。
2.1.1.2 数据采集系统的任务
- 采集传感器输出的模拟信号,并转换为计算机能识别的数字信号,然后计算机进行相应的处理
2.1.1.3 数据采集系统的好坏
精度和速度
保证精度的条件下,应该尽可能提高采取速度,以满足实时采集,实时(处理、实时控制
2.1.1.4 传统数据采集的特点
- 数据采集系统一般都包含有计算机系统,这使得数据采集的质量和效率等大为提高,同时节省了硬件投资。
- 软件在数据采集系统中的作用越来越大,增加了系统设计的灵活性。
- 数据采集与数据处理相互结合得日益紧密,形成了数据采集与处理相互融合<的系统,可实现从数据采集、处理到控制的全部工作。
- 速度快,数据采集过程一般都具有“实时”特性。
- 随着微电子技术的发展,电路集成度的提高,数据采集系统的体积越来越小,可靠性越来越高。
- 出现了很多先进的采集技术,比如总线采集技术、分布式采集技术等。
2.1.2 数据采集系统架构
数据采集系统架构 由软件硬件两部分组成
从硬件的分类 微型计算机数据采集系统 集散型数据采集系统
微型计算机数据采集系统

微型计算机数据采集系统是传感器、模拟多路开关、程控放大器、采样/ 保持器、A/D转换器、计算机及外设等设备。
传感器
- 把各种非电的物理量,比如温度、压力、位移、流量等转换成电信号的 器件称为传感器。
模拟多路开关
- 数据采集系统往往要对多路模拟量进行采集。可以用模拟多路开关来轮流切换各路模拟量与A/D转换器间的通道,使得在一个特定的时间内,只 允许一路模拟信号输入到A/D转换器,从而实现分时转换的目的。
程控放大器
- 在数据采集时,来自传感器的模拟信号一般都是比较弱的低电平信号。 程控放大器的作用是将微弱输人信号进行放大,以便充分利用A/D转换器 的满量程分辨率。
采样保持器
- AD转换器完成一次转换需要一定的时间,在这段时间内希望AD转换器输入端的模拟信号电压保持不変,以保证有较高的转换精度。这可以用采样/保持器来实现,采样/保持器的加入,大大提高了数据采集系统的采样频率。
A/D转换器
- 模拟信号转换为数字信号
接口
- 用来将传感器输出得数字信号进行整形或电平调整,然后再传送到计算机的总线
微机及外部设备
- 对数据采集系统的工作进行管理和控制,并对采集到的数据做必要的处 理,然后根据需要进行存储、显示或打印
2.1.2.1 集散型数据采集系统

是计算机网络技术的产物。由若干个数据采集站和一台上位机及通信接口组成
数据采集站
- 一般是由单片机数据采集装置组成,位于生产设备附近,独立完成数据采集和处理任务,并将数据以数字信号的形式传送给上位机。
上位机
- 一般为PC计算机,配置有打印机和绘图机。上位机用来将各个数据采集站传送来的数据,集中显示在显示器上或用打印机打印成各种报表,或 以文件形式存储在磁盘上。此外,还可以将系统的控制参数发送给各个 数据采集站,以调整数据采集站的工作状态。
通信接口
- 数据采集站与上位机之间通常采用异步串行传送数据。数据通信通常采 用主从方式,由上位机确实与哪一个数据采集站进行数据传送。
集散型数据采集系统的主要优点:
系统适应能力强
- 无论大规模的系统还是中小规模的系统,集散型系统都能够适应,因为可以通过选用适当数量的数据采集站来构成数据采集系统。
系统的可靠性高
- 由于采用了多个以单片机为核心的数据采集站,若某个数据采集站发生了故障,只会影响到某项数据的采集,而不会对系统的其他部分造成影响。
系统可以实时响应
- 由于系统中各个数据采集站之间是真正并行工作的,所以系统的实时响应较好。
对系统硬件的要求不高
- 由于集散型数据采集系统采用了多机并行处理方式,所以每一个单片机仅完成数量 十分有限的数据采集和处理任务,因此它对硬件的要求不高,用低档的硬件组成高 性能的系统。
用数字信号传输代替模拟信号传输,克服常模干扰和共模干扰
2.1.2.2 数据采集系统的软件
模拟信号采集与处理程序
- 对模拟信号采集、标度变换、滤波处理及次数据计算,并将数据存储到硬盘
数字信号采集与处理程序
-
对数字输入信号进行采集及码制之间的转换,如BCD码转换为ASCII码 脉冲信号处理程序
-
对输入的脉冲信号进行电平高低判断和计数,开关信号处理程序
开关信号处理程序
-
系统设定的扫描周期定时查询运行 中断性开关信号处理 随中断的产生随时运行
运行参数设置程序
- 对数据采集系统的运行参数进行设置,运行参数有:采样通道号、采样 点数等
系统管理(主控)程序
-
将各个工程模块程序组织成一个程序系统,并管理和调用各个功能模块的程序,还可用来管理系统数据文件的存储和输出。一般以文字菜单和 图形菜单的人机界面技术来组织、管理和运行系统程序
通信程序
-
完成上位机与各个数据采集站之间的数据传送工作(只有集散型数据采 集系统才具有通信功能)
2.1.3 数据采集关键技术
- 数据采集系统中采用计算机作为处理机。计算机处理的信号是二进制的离散数字信号,而被采集的各种物理量一般都是连续模拟信号,因此,在数据采集系统中,首先遇到的问题是传感器所测量到的连续模拟信号怎样转换成离散的数字信号。
2.1.3.1 采样技术
x,y离散转化为x离散y连续
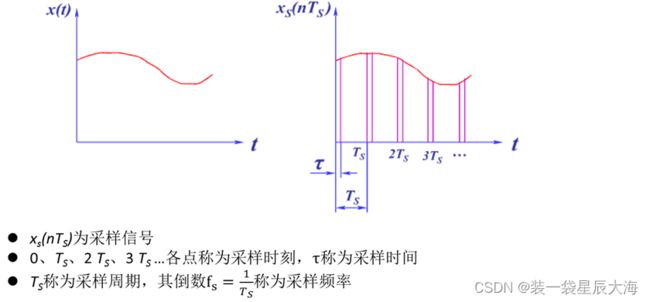

常用的采样技术
常规采样技术(占内存大)

间歇采样技术(时间段采样)

变频采样技术(模拟信号频率变化)
- 变频采样是指在采样过程中采样频率可以变化。
- 例如,如果模拟信号的频率是随时间增大而减小的,那么就可以采用变频采样技术,从而减少采样的数据量。因此,实现变频采样的先决条件是清楚目标信号的频率随时间变化的关系。
2.1.3.2 量化技术
x离散y连续转为x,y均成离散信号
- 量化就是把采样信号的幅值与某个最小数量单位的一系列整倍数比较,以最接近于采样信号幅值的最小数量单位倍数来代替该幅值。
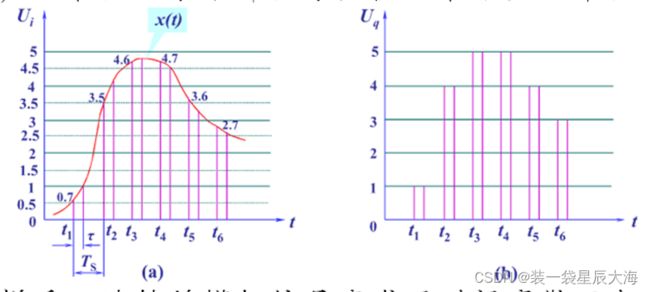
经采样后,连续的模拟信号变成了时间离散而电压幅值在各自范围内连续的采样信号,经过量化处理,得到了n个离散值的量化信号。
2.1.3.3 编码技术
将离散信号转化为数字信号
- 把量化信号的数值用二进制代码来表示,称为编码。
- 量化信号经编码后转换为数字信号。
- 完成量化和编码的器件是模/数(A/D)转换器。
- 编码有多种形式,最常用的是二进制编码。
常用编码方法
- 单极性二进制编码
- 双极性二进制编码
2.2 数据采集基础
2.2.1 数据的发展
- 数据是可以获取和存储的信息
- 对数据的记录能力是人类社会进步的重要标志
- 数据的记录方式揭示了的数据的发展方向
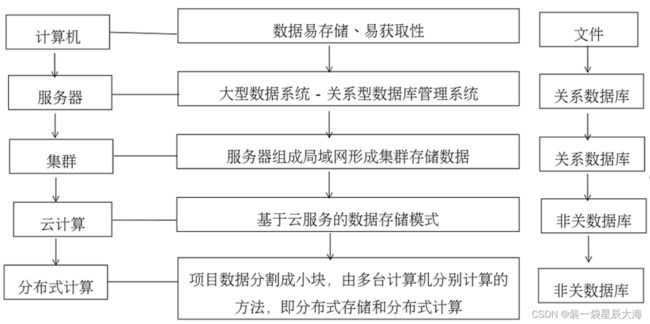
大数据产生
- 分布式计算
- 互联网技术发展:物联网、移动互联网、社交网络等
大数据区别于传统数据之处
- 大数据关注数据流,而不是数据库中的“库表”
- 大数据分析依赖于数据科学家,而不是传统的数据分析师
- 大数据正在改变传统数据采集、存储和分析的处理流程
- 大数据正在引领新的数据思维
2.2.2 大数据主要来源
- 政府数据,税收数据/社保数据/交通数据等
- 企事业单位的数据,生产数据/监控数据等
- 物联网数据,传感器数据/条形码数据/RFID数据等
- 互联网数据,门户网站数据/社交网站数据/电子商务数据等
2.2.2.1 大数据分类
按产生数据的主体划分
- 少量企业应用产生的数据
- 大量人产生的数据
- 大型服务器产生的数据
按数据来源的行业划分
- 大型互联网公司产生的数据
- 电信、金融、保险、电力、石化等大型国有企业数据
- 公共安全、医疗、交通领域等政府机构产生的数据
- 气象、地理、政务等国家公共领域产生的数据
- 制造业和其他传统行业产生的生产数据
按数据来源的形式
- 海量交易数据
- 海量交互数据
- 海量传感器数据
按数据存储类型划分
- 结构化数据就是数据库系统存储的数据
- 非结构化数据
2.2.3 大数据采集技术
2.2.3.1 数据采集面临的挑战和困难
- 数据的分布性:文档数据分布在数以百万计的不同服务器上,没有预先定义的拓扑结构相连
- 数据的不稳定性:系统会定期或不定期地添加和删除数据。
- 数据的无结构和冗余性:很多网络数据没有统一的结构,并存在大量重复信息
- 数据的错误性:数据可能是错误的或无效的。错误来源有录入错误、语法错误、OCR错误等。
- 数据结构复杂:既有存储在关系数据库中的结构化数据,也有文档、系统日志、图形图像、语音、视频等非结构化数据。
2.2.3.2 大数据采集常用方法
- 系统日志采集、利用ETL工具采集以及网络爬虫
系统日志文件采集
- 日志文件是由数据源系统自动生成的记录文件
- Web服务器日志文件记录了Web服务器接受处理请求以及运行时错误等各种原始信息,以及Web网站的外来访问信息,包括各页面的点击数、点击率、网站用户的访问量和Web用户的财产记录等。
- Web服务器主要包括以下三种日志文件格式:公用日志文件格式、扩展日志格式和IIS日志格式。
- 对于系统日志文件采集,可以使用海量数据采集工具,如Hadoop的Chukwa、Cloudera的Flume、Facebook的Scrible以及Apache kafka等大数据采集框架。
利用ETL工具采集
- ETL即数据抽取( Extract)、转换( Transform)、加载(Load)的过程

抽取
- 全量抽取
- 增量抽取:日志比对、时间戳、触发器、全表比对
数据转换和加工
- 字段映射、数据过滤、数据清洗、数据替换、数据计算、数据验证、数据加解密、数据合并、数据拆分等
数据加载
- 将转换和加工后的数据加载到目的库中
互联网数据采集
- 互联网大数据通常是指“人、机、物”三元世界在网络空间中彼此之间相互交互与融合所产生的大数据,其特点如下:
- 多源异构性 互联网大数据通常由不同的用户产、不同的网站产生、数据呈现复杂多样的非结构化形式
- 交互性 微博微信的兴起导致大量的互联网数据有很强的交互性时效性
- 时效性 在互联网平台上,每时每刻都有大量新的数据发布、使得信息传播具有时效性
- 社会性 用户可以转发回复,互联网大数据直接反应了社会的状态突发性
- 突发性 有些信息在短时间内应发大量的新的网络数据产生
- 高噪声 互联网大数据来自于众多不同的网络用户,具有很高的噪声和不确定性
对互联网大数据的采集,通常是通过网络爬虫技术进行的。
网络爬虫:也叫网页蜘蛛,是一种“自动化浏览网络”的程序,或者说是一种网络机器人。通俗来说,网络爬虫从指定的链接入口,按照某种策略从互联网中自动获取有用信息。
2.2.4 采集框架对比

第三章 大数据采集架构
3.1 Flume
3.1.1 定义
-
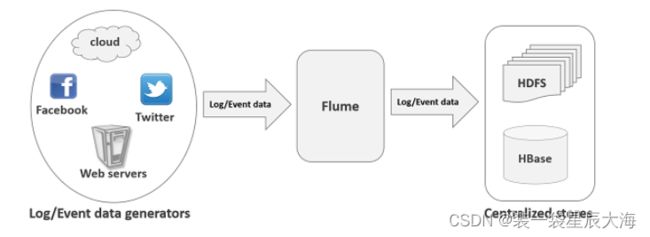
Apache Flume 是一个可以收集日志、事件等数据资源的数据采集系统,它将这些数量庞大的数据从各项数据资源中集中或者存储。
-
Apache Flume具有高可用性分布式的特性,作为配置工具,其设计的原理是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。
-
数据传输的是流动的是事件(Event)
-
事件是Flume内部数据传输的最基本单元
-
它是由一个可选头部和一个负载数据的字节数组(该数据组是从数据源接入点传入,并传输给传输器,也就是HDFS/HBase)构成
Flume系统首先将Event封装,然后利用Agent进行其解析,并依据规则传输给HBase或者HDFS。
3.1.2 架构图

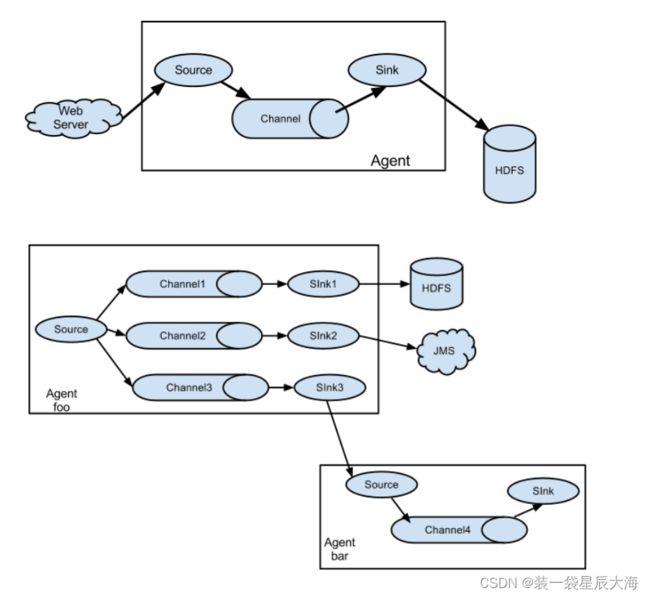
3.1.3 组件定义及功能
Channel
- Channel(管道)是一种暂时的存储容器,它将从Source处接收到的event格式的数据缓存起来,它在Source和Sink间起着一个桥梁的作用。
- Channel是一个完整的事务,这一点保证了数据在收发时的一致性,并且它可以和任意数量的Source和Sink链接。支持的类型包括JDBC channel、FileSystem channel、Memort channel等。
Sink
- Sink负责从管道中读出数据并发给下一个Agent或者最终的目的地。
- Sink支持的不同目的地种类包括HDFS、HBASE、 Solr、ElasticSearch、File、Logger或者其它的Flume Agent。
Source
- Source负责接收数据,并将接收的数据以Flume的event格式进行封装,然后将其传递给一个或者多个通道Channal。
- Flume的Source支持HTTP,JMS,RPC,NetCat,Exec,Spooling Directory等协议
- Source端可以利用Spooling监视一个目录或者文件,解析新生成的事件
HDFS
- 暂时的存储容器,它将从source处接收到的event格式数据缓存起来,在source与sink之间起着缓冲作用,并且channel是一个完整的事务,保证了数据收发时的一致性,可以与任意数量的source与sink连接
3.1.4 运行机制
多Agent级联

3.2 Kafka
3.2.1 定义
- Kafka是最初由Linkedin公司开发,是一个分布式﹑支持分区的 (partition)多副本的( replica) ,基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统﹑低延迟的实时系统storm)Spark流式处理引擎, web/nginx日志﹑访问日志,消息服务等等,用scala语言编写, Linkedin于 2010年贡献给了Apache基金会并成为顶级开源项目。
3.2.2架构图
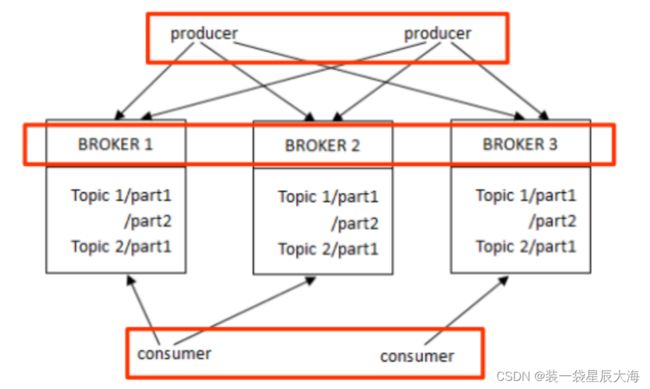
3.2.3 组件定义及功能
1 . Broker
-
缓存代理,Kafka集群中的一台或多台服务器统称broker.
-
在Kafka中,Broker一般有多个,它们组成一个分布式高容错的集群。Broker的主要职责是接受Producer和Consumer的请求,并把消息持久化到本地磁盘。Broker以topic为单位将消息分成不同的分区(partition),每个分区可以有多个副本,通过数据冗余的方式实现容错。
-
Broker中保存的数据是有有效期的,比如7天,一旦超过了有效期,对应的数据将被移除以释放磁盘空间。只要数据在有效期内,Consumer可以重复读取而不受限制。
2. Producers----消息的生产者(消息的入口)
- Producers是向它们选择的主题发布数据·生产者可以选择分配某个主题到哪个分区上。
- Producers直接发送消息到Broker上的 leader partition ,不需要经过任何中介一系列的路由转发。
- Producer客户端自己控制着消息被推送到哪些Partition。实现的方式可以是随机分配﹑实现一类随机负载均衡算法或者指定一些分区算法·
- Kafka Producer 可以将消息在内存中累计到一定数量后作为一个batch发送请求·Batch的数量大小可以通过Producer的参数控制,参数值可以设置为累计的消息的数量(如500条)·累计的时间间隔(如100ms)或者累计的数据大小
- (64KB)
- Producers可以异步·并行的向Kafka发送消息,但是通常producer在发送完消息之后会得到一个 future 响应,返回的是offset 值或者发送过程中遇到的错误
3. Consumers—消息的消费者(消息的出口)
- Kafka提供一种单独的消费者抽象,此抽象具有两种模式的特征消费组:Queuing和 Publish-SubScribe -
- 消费者使用相同的消费组名字来标识,每个主题的每条消息都会发送到某个consumers 实例,这些实例所在的消费者需要提出订阅,才能获得消息。
- Kafka支持以组的形式消费Topic ,如果Consumers有同一个组名,那么 Kafka就相当于一个队列消息服务,而各个
- Consumer均衡的消费相应 Partition中的数据。
- 若Consumers有不同的组名,那么Kafka就相当与一个广播服务,它会把 Topic中的所有消息广播到每个Consumer。
3.2.4 push-and-pull消息机制
- Kafka的发布和订阅消息过程中,Producer到 Broker 的过程是 push,也就是有数据就推送到 Broker;而 Consumer到 Broker的过程是 pull它是通过consumer 主动取数据的,而不是 Broker 把数据主动发送到consumer端的.
- 从图可以看出, Kafka采用了push-and-pull消息传输机制·这种机制中, Broker决定了消息推送的速率,而Consumer可以自主决定是否批量的从 Broker接受数据。
3.2.5 Zookeeper

Apache Zookeeper是Apache Hadoop的一个子项目,作为一种分布式服务框架,提供协调和同步分布式系统各节点的资源配置等服务,是分布式系统一致性服务的软件。Apache Kafka主要是利用Zookeeper解决分布式应用中遇到的数据管理问题,比如,名称服务状态同步服务﹑集群管理﹑分布式应用配置项的管理等。
3.2.6 架构核心特性
- 压缩功能:Kafka支持对消息进行压缩,压缩的好处就是减少传输的数据量,减轻对网络传输的压力。
- 消息可靠性:为保证信息传输成功,当一个消息被发送后,Producer会等待Broker成功接收到消息的反馈,如果消息在途中丢失或是其中一个Broker挂掉,Producer会重新发送。
- 备份机制:备份机制是Kafka 0.8版本的新特性。一个备份数量为n的集群允许n-1个节点失败。在所有备份节点中,有一个节点作为lead节点,这个节点保存了其它备份节点列表,并维持各个备份间的状体同步。
Kafka的核心特征保证Kafka能确保其高可靠性、容错性、可扩展性以及并发性的处理消息。
3.3 Scribe
Scribe能够从各种日志源上收集日志,存储到一个中央存储系统 (NFS或分布式文件系统等),以便于进行集中统计分析处理。
Scribe为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。

3.3.1 组成
- Scribe由Scribe Agent、Scribe和存储系统三部分组成。
- Scribe Agent实际上是一个thrift client。各个数据源需通过thrift向Scribe传输数据,每条数据记录包含一个category和一个message,可以在Scribe配置中指定thrift线程数,默认是3。
- Scribe接收到thrift client发送过来的数据,放到一个共享队列message queue,然后根据配置文件,Scribe可以将不同category的数据存放到不同目录中并push给后端不同的存储对象。
- 后端的存储系统提供各种各样的Store方式
第四章 大数据迁移技术
4.1 数据迁移的原因
- 数据的快速增长
- 多种业务数据
- 不同软硬件平台的数据如何采集并获取 整合&使用
4.2 数据迁移定义
- 数据迁移(HSM,Hierarchical Storage Management)又称分级存储管理,是一种将离线存储与在线存储融合的技术。它将高速、高容量的非在线存储设备作为磁盘的下一级设备,然后将磁盘中常用的数据按指定的策略自动迁移到磁带库(简称带库)等二级大容量存储设备上
4.3 数据迁移的三个阶段:
- 数据迁移前的准备
- 要进行待迁移数据源的详细说明(包括数据的存储方式、数据量、数据的时间跨度)
- 建立新旧系统数据库的数据字典
- 对旧系统的历史数据进行质量分析,新旧系统数据结构的差异分析新旧系统代码数据的差异分析
- 建立新老系统数据库表的映射关系,对无法映射字段的处理方法
- 开发、部属ETL工具,编写数据转换的测试计划和校验程序;制定数据转换的应急措施
- 数据迁移的实施
- 要求制定数据转换的详细实施步骤流程
- 包括数据迁移环境、业务准备、数据迁移技术测试等
- 数据迁移后的校验
- 对迁移工作的检查,结果将会判定新系统能否使用
- 质量检查工具或使用程序进行校验
4.4 数据迁移相关技术
4.4.1 基于主机的迁移方式
- 直接拷贝方法
- 利用操作系统命令直接拷贝
- UNIX系统一般可以使用cp、dd、tar、savevg等命令。在Windows系统,一般使用图形界面工具或copy命令
- 特点:此方法简单灵活,可以方便的决定哪些数据需要迁移,但其缺点也很明显,由于从主机端发起,对主机的负载压力和应用的冲击较大
- 逻辑卷数据镜像技术
- 逻辑卷:逻辑磁盘形成的虚拟盘,也可称为磁盘分区(LV)
- 镜像:一个磁盘上的数据在另一个磁盘上存在一个完全相同的副本
- 对于服务器操作系统(Linux)已经采用逻辑卷管理器(LVM)的系统,可以直接利用LVM的管理功能完成原有数据到新存储的迁移
- 特点:此方法支持任意存储系统之间的迁移,且成功率较高,支持联机迁移。但在镜像同步的时候,仍会对主机有一定影响,适合于主机存储的非经常性迁移
- 利用操作系统命令直接拷贝
4.4.2 基于存储的数据迁移
- 基于存储的数据迁移,主要分为同构存储和异构存储的数据迁移
- 同构存储的数据迁移是利用其自身复制技术,实现磁盘或卷LUN的复制
- LUN:逻辑单元号,是在硬件层分出各个逻辑盘后指定的号码
- 卷:当连接存储设备时,就可以识别到存储设备上逻辑设备LUN,此时LUN相对于主机来讲就是一个“物理硬盘”,在该“物理硬盘”上创建一个或多个分区,就可以得到一个或多个卷。此时卷相对于主机是一个逻辑设备
- 从容量大小方面比较卷,分区、LUN的关系如下:
- 卷=分区≤主机设备管理器中的磁盘=LUN≤存储设备中硬盘的总容量
- 同构存储的复制技术又分为同步复制和异步复制
- 同步复制是主机I/O需写入主存储和从存储后才可继续下一个I/O写入
- 异步复制为主机的I/O写入主存储后便可继续写入操作而无需等待I/O写入从存储
- 基于同构存储的数据迁移
- 需要在新机房环境中为目标主机建立必须的用户以及配置系统参数
- 在源存储与目标存储上实现卷LUN的对应关系,进行数据复制同步
- 数据同步完成后,停止旧机房主机的数据库及业务应用,确保数据完全一致
- 断开两机房存储之间的Truecopy复制
- 基于异构存储的数据迁移
- 使用目标存储B的虚拟化二理软件识别存储A的LUN1,建立映射关系
- 断开既有主机与存储A之间的I/О链路
- 在主机上识别目标存储B虚拟化管理的LUN2以间接使用存储A,启动业务检测
- 存储内部复制技术实现虚拟化管理的映射卷LUN2(主卷)至存储B(从卷)LUN3复制
- 存储内部复制完成后,断开主机与存储B虚拟化管理LUN2的I/O链路,连接主机至存储B的LUN3,改变主卷属性并删除复制关系
4.4.3 备份恢复的方式
- 利用备份管理软件将数据备份到磁带(或其他虚拟设备),然后恢复到新的存储设备中
- 对于联机要求高的设备,可以在线备份
- 特点:可以有效缩短停机时间窗口,一旦备份完成,其数据的迁移过程完全不会影响生产系统。但备份时间点至切换时间点,源数据因联机操作所造成的数据变化,需要通过手工方式进行同步
4.4.4 基于主机逻辑卷的迁移
- Unix、Linux操作系统具有稳定性好、不易感染病毒等优点,通常作为数据库服务器操作系统使用,且一般均使用逻辑卷管理磁盘
- 实现过程:
- 主机的逻辑卷管理使卷组(VG)的信息保存于磁盘,只要操作系统平台一致,其卷组信息在新主机上能够识别,即可对卷组直接挂载使用,实现更换主机
- 实现过程:
- 基于主机的逻辑卷镜像数据迁移主要是为既有逻辑卷添加物理卷(PV)映射,通过数据的初始化同步使新加入的PV与既有PV数据完全一致,再删除位于原存储上的PV,实现数据在不同存储之间数据的迁移
- 适用场景:逻辑卷的数据迁移一般适用于存储、主机更换等情景
- 使用逻辑卷更换主机:
- 如果新主机操作系统与旧主机一致,且采用了逻辑卷管理存储,仅须主机识别存储和导入卷组就可以实现数据迁移
- 使用主机逻辑卷镜像更换存储:
- 仅须将新存储添加至当前系统卷组,同时逻辑卷镜像写入两份数据,然后对旧存储删除就可以实现数据迁移
4.4.5 基于数据库的迁移
- 同构数据库数据迁移
- 同构数据库的数据迁移技术,通常是利用数据库自身的备份和恢复功能来实现数据的迁移,可以是整个库或是单表
- 大型数据库都有专门的数据复制技术,可以用于数据迁移,如Sybase的Replication Server、Oracle的DataGuard
- 数据量不大时,一般为原数据库主机导出数据再通过网络通道将数据传输至目标数据库主机并导入,例如Oracle的export/import、Sybase的dump/load
- 同构数据库的数据迁移较为简单、不限操作系统平台,但是这种方法的缺点在对业务影响时间较长,数据迁移的速度取决于主机的读写速度以及网络传输速度
- 异构数据库数据迁移
- 异构数据库的数据迁移一般使用第三方软件实现数据库的数据迁移,这种方法适用于纯数据迁移,并且不需要关注存储过程
数据迁移时存在问题: - 字段类型的长度发生了变化,如字符型的长度均变为了255
- 自增序列不一致等问题,数据转换后需要重新定义
- 程序不完全兼容,如在分页时需要设置记录集为客户端游标
- 主键、索引丢失,需要重新建立
- 异构数据库的迁移不限操作系统、数据库平台,但是需要花费—一定的时间及费用,特别是专门的定制开发,时间可能很长且代价较高,在数据迁移后应用需一定时间才能趋于稳定
- 异构数据库的数据迁移一般使用第三方软件实现数据库的数据迁移,这种方法适用于纯数据迁移,并且不需要关注存储过程
4.4.6 服务器虚拟化数据迁移
-
服务器虚拟化可以提高设备资源的利用率,尤其是可以使CPU、内存、存储空间得到充分的使用,可实现服务器整合,也符合目前的云计算需求
-
目前较为成熟、应用广泛的产品有VMware vSphere、MicrosoftHyper-V、RedHat KVM等
-
物理机向虚拟机迁移
- 是指将包含应用配置的物理服务器迁移到虚拟机,而不需要重新安装操作系统和应用软件,也称之为P2V (Physical to Virtual)
-
虚拟机的迁移︰是将虚拟机从运行的主机或存放数据的存储迁移至另外的主机或存储,其可用于处理主机或存储故障,同时也方便更换主机或存储。
-
虚拟机的迁移通常分为冷迁移和热迁移
- 冷迁移是将已经关停的虚拟机在不同的主机上启动或将相关虚拟机文件静态拷贝至目标存储
- 热迁移指的是在不影响虚拟机可用性的情况下将虚拟机迁移至目的地
- VMware中主要有vmotion和storagevmotion的两种热迁移方法
-
步骤
- 在迁移开始,先将源存储的VM目录拷贝至目标存储;
- 在目标存储上使用新拷贝的VM目录生成一个新的VM,其处于静止状态;
- 通过镜像驱动程序(mirror diver)向源存储和目标存储同时写入数据I/O;
- 通过系统Vmkernel或VAAl将源VM数据拷贝至目标存储上
- 源VM数据拷贝完成后,将mirror diver新写入的数据与目标存储上的VM数据合并,并暂停VM;
- 新VM使用合并后的数据启动,并删除源VM及其目录数据
-
其他数据迁移技术
- 备份恢复方法
- 数据库工具方法
- 存储虚级化方法
- 历史数据迁移方法
- 网络数据传输
4.5 数据迁移三种工具
4.5.1 Sqoop
- Apache Sqoop是一种用于Apache Hadoop 与关系型数据库之间结构化、非结构化数据转换的工具,它是Java语言编写的数据迁移开源工具
- Sqoop可以通过Sqoop这个工具实现传统的关系型数据库(RDBMS)与Hadoop云环境平台的数据迁移
数据导入流程
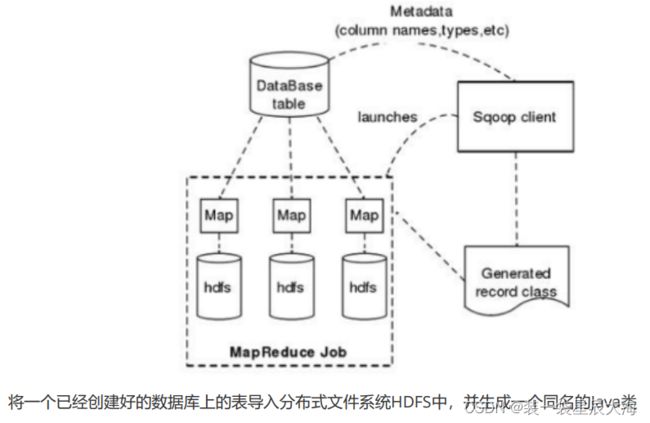
将一个已经创建好的数据库上的表导入分布式文件系统HDFS中,并生成一个同名的Java类
步骤
- 首先读取要进行数据迁移的表结构,生成运行类并打成对应的jar包,再提交给Hadoop
- 设置好Job,主要参数的设置
- Hadoop通过执行MapReduce作业执行import命令,包括对数据进行数据划分、数据划分后写入各Split的数据上下边界范围并读取该范围、创建RecordReader并从数据库中读取数据、创建Map并根据RecordReader从传统关系型数据库中读取的数据,设置好Map的键值对,最后运行Map任务
数据导出流程

根据目标表的定义生成一个java类,然后通过创建MapReduce作业把从分布式系统中读取的需要导出的数据文件所使用生成的类解析为数据记录,执行选定的导出方法,一般选定JDBC的导出方法
4.5.2 ETL处理流程
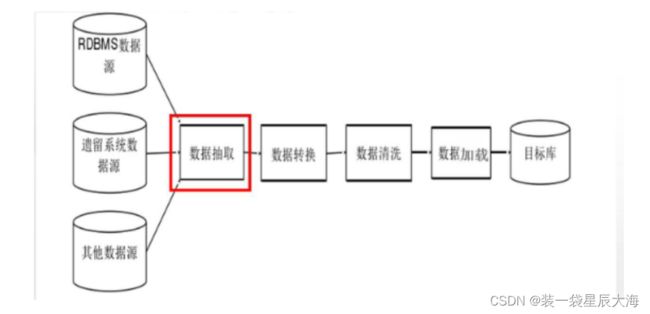
- 数据抽取是从不同的数据源(不同物理环境和背景以及多样化的数据)中通过采用不同的方法抽取数据的一个过程。此外,可以通过使用机器学习方法对网页内容中半结构化的数据进行抽取。而对于非结构化数据,可通过一种模拟线性模型的模糊匹配方法进行处理;在实际的应用中,数据源通常为传统关系型数据库,数据抽取的方法大概包括全量抽取(数据迁移)、增量抽取(只抽取自上次抽取后传统关系型数据库的数据表中有变化的数据)
- 数据转换是从数据源中抽取获得的数据格式与目标数据格式可能存在不一致的情况。所以需要对抽取后的数据进行数据转换以及加工处理,包括数据的合并、汇总、过滤和转换,重新对数据进行格式化等过程。
- 数据清洗是指数据在加载到数据仓库之前,可能会存在一些问题数据,即“脏数据”,如不完整数据、错误数据和重复数据等,须进行数据清洗,这是一个不断反复的过程。对于数据清洗的研究,以及有比较丰富的数据清洗算法可供参考使用,相似重复数据监测与消除算法、DBMS的集成数据清理算法和增量数据清洗算法等层出不穷。
- 数据加载是将经过数据转换和数据清洗后的数据依照实际数据模型定义的表结构装载到目标库中。通常包含两种方式装载,一种是通过SQL语句进行直接的插入(insert)、删除(delete)和更新(Update)操作,另一种是采用批量装在方法,如bcp,bulk
4.5.3 Kettle
核心组件
- 勺子(Spoon.bat/spoon.sh):是一个图形化的界面,可以让我们用图形化的方式开发转换和作业。windows选择Spoon.bat; Linux选择Spoon.sh
- 煎锅(Pan.bat/pan.sh):利用Pan可以用命令行的形式执行由Spoon编辑的转换和作业厨房(Kitchen.bat/kitchen.sh}:利用Kitchen可以使用命令行调用由Spoon编辑好的Job
- 菜单(Carte.bat/Carte.sh): Carte是一个轻量级的Web容器,用于建立专用、远程的ETLServer。
两种设计
- Transformation(转换)︰完成针对数据的基础转换。
- Job(作业):完成整个工作流的控制。
- 作业是步骤流,转换是数据流。这是作业和转换最大的区别。
- 作业的每一个步骤,必须等到前面的步骤都跑完了,后面的步骤才会执行;而转换会一次性把所有空间全部先启动(一个控件对应启动一个线程),然后数据流会从第一个控件开始,一条记录、一条记录地流向最后的控件。
核心概念
1、可视化编程
Kettle可以被归类为可视化编程语言(Visula ProgrammingLanguages,VPL),因为Kettle可以使用图形化的方式定义复杂的ETL程序和工作流。
可视化编程一直是Kettle里的核心概念,它可以让你快速构建复杂的ETL作业和减低维护工作量。它通过隐藏很多技术细节,使IT领域更贴近于商务领域。
Kettle里的代码就是转换和作业。
2、转换
转换(transaformation)负责数据的输入、转换、校验和输出等工作。Kettle 中使用转换完成数据ETL全部工作。转换由多个步骤(Step)组成,如文本文件输入,过滤输出行,执行SQL 脚本等。各个步骤使用跳 (Hop)来链接。跳定义了一个数据流通道,即数据由一个步骤流(跳)向下一个步骤。在Kettle 中数据的最小单位是数据行(row),数据流中流动的其实是缓存的行集(RowSet)。
3、步骤
步骤(控件)是转换里的基本的组成部分,快速入门的案例中就存在两个步骤,“CSV文件输入”和“Excel输出”。
一个步骤有如下几个关键特性:
①步骤需要有一个名字,这个名字在同一个转换范围内唯一。
②每个步骤都会读、写数据行(唯一例外是“生成记录”步骤,该步骤只写数据)。
③步骤可将数据写到与之相连的一个或多个输出跳(hop),再传送到跳的另一端。
④大多数的步骤都可以有多个输出跳。一个步骤的数据发送可以被设置为分发和复制,
4、跳
跳就是步骤之间带箭头的连线,跳定义了步骤之间的数据通路。
跳实际上是两个步骤之间的被称之为行集的数据行缓存,行集的大小可以在转换的设置里定义。当行集满了,向行集写数据的步骤将停止写入,直到行集里又有了空间。当行集空了,从行集读取数据的步骤停止读取,直到行集里又有可读的数据行。
5、元数据
⑦小数点符号:十进制数据的小数点格式。不同文化背景下小数点符号是不同的,一般是点(.)或逗号(,)。
⑧分组符号:数值类型数据的分组符号,不同文化背景下数字里的分组符号也是不同的,一般是点(.)或逗号(,)或单引号(′)
6、数据类型
数据以数据行的形式沿着步骤移动。一个数据行是零到多个字段的集合,字段包含下面几种数据类型。
String:字符类型数据
②Number:双精度浮点数。
③Integer:带符号长整型(64位)。④BigNumber:任意精度数据。⑤Date:带毫秒精度的日期时间值。⑥Boolean:取值为true和false的布尔值。
Binary:二进制字段可以包含图像、声音、视频及其他类型的二进制数据。
7、并行
跳的这种基于行集缓存的规则允许每个步骤都是由一个独立的线程运行,这样并发程度最高。这一规则也允许数据以最小消耗内存的数据流的方式来处理。在数据仓库里,我们经常要处理大量数据,所以这种高并发低消耗的方式也是ETL工具的核心需求。
对于kettle的转换,不能定义一个执行顺序,因为所有步骤都以并发方式执行:当转换启动后,所有步骤都同时启动,从它们的输入跳中读取数据,并把处理过的数据写到输出跳,直到输入跳里不再有数据,就中止步骤的运行。当所有的步骤都中止了,整个转换就中止了。
8、作业
作业(Job),负责定义一个完成整个工作流的控制,比如将转换的结果发送邮件给相关人员。因为转换(transformation)以并行方式执行,所以必须存在一个串行的调度工具来执行转换,这就是Kettle中的作业。
特点
-
免费开源 基于java的免费开源的软件,对商业用户也没有限制
-
易配置 可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定
-
不同数据库 ETL工具集,它允许你管理来自不同数据库的数据
-
两种脚本文件 transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制
-
图形界面设计 通过图形界面设计实现做什么业务,无需写代码去实现
-
定时功能 在Job下的start模块。有一个定时功能,可以每日,每周等方式进行定时
第五章 互联网数据抓取与处理技术
5.1 网络爬虫定义
网络爬虫,也称网络蜘蛛,或网络机器人。它是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本,被广泛用于互联网搜索引擎、资讯采集、舆情监测等
5.2 网络爬虫功能
网络爬虫一般分为数据采集,处理,储存三个部分
- 网络爬虫一般从一个或者多个初始URL开始,下载网页内容
- 通过搜索或是内容匹配手段获取网页中感兴趣的内容,同时不断从当前页面提取新的URL
- 根据网络爬虫策略,按一定的顺序放入待抓取URL队列中,整个过程循环执行,一直到满足系统相应的停止条件
- 对这些被抓取的数据进行清洗,整理,并建立索引,存入数据库或文件中
- 最后根据查询需要,从数据库或文件中提取相应的数据,以文本或图表的方式显示出来
5.3 网络爬虫的抓取策略
网络爬虫的抓取策略是指在网络爬虫系统中决定URL在待抓取URL队列中排列顺序的方法
常见的网络爬虫抓取策略包括:
深度优先策略
深度优先策略是按照深度由低到高的顺序,依次访问下一级网页链接,直到不能再深入为止

广度优先策略
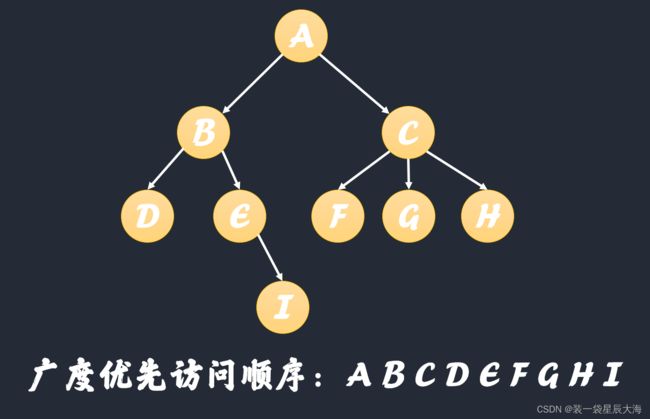
广度优先策略是按照广度优先的搜索思想,逐层抓取URL池中的每一个URL的内容并将每一层的扇出URL纳入URL池中
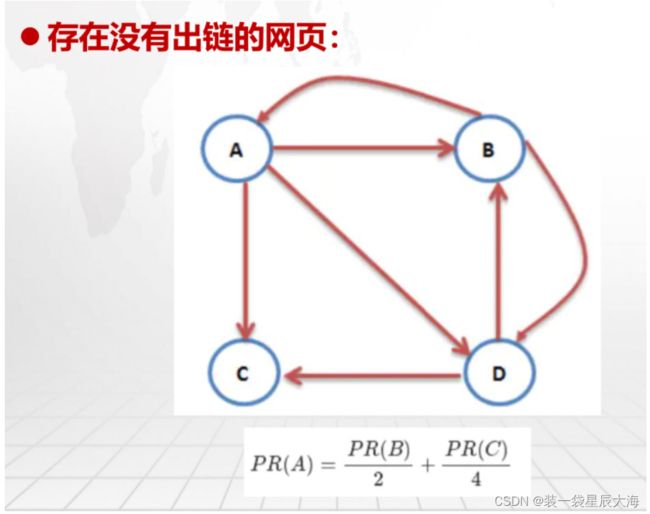
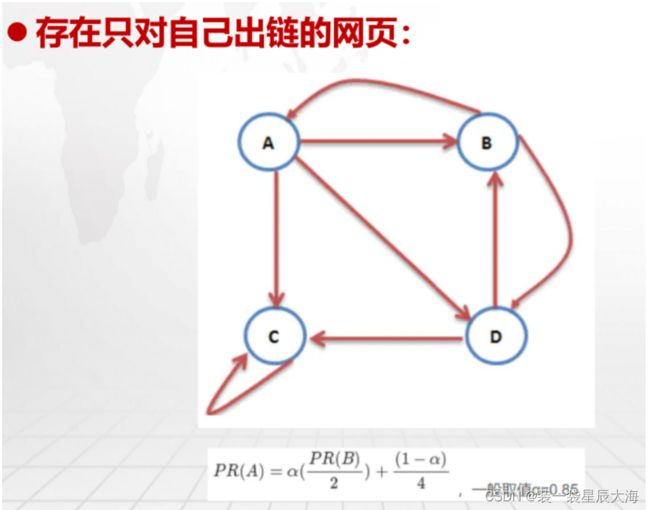
局部策略
-
给每个网页一个PageRank值
-
通过(投票)算法不断迭代,直至每个网页的值达到平稳为止
(1)出链:如果在网页A中附加了网页B的超链接B-Link,用户浏览
网页A时可以点击B-Link然后进入网页B。上面这种A附有B-Link这种
情况表示A出链B。可知,网页A也可以出链C,如果A中也附加了网
页C的超链接C-Link(2)入链:上面通过点击网页A中B-Link进入B,表示由A入链B。如
果用户自己在浏览器输入栏输入网页B的URL,然后进入B,表示用户
通过输入URL入链B
(3)无出链:如果网页A中没有附加其他网页的超链接,则表示A无
出链
(4)只对自己出链:如果网页A中没有附加其他网页的超链接,而只
有他自己的超链接A-Link,则表示A只对自己出链
(5)PR值:一个网页的PR值,概率上理解就是此网页被访问的概率,
PR值越高其排名越高。
OPIC策略
- (OnlinePageImportanceComputation)策略实际上也是对页面进行一个重要性打分。初始时,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序
- 与PageRank相比,PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程。因此,OPIC计算速度明显快于局部PageRank策略,是一种较好的重要性衡量策略,适合实时计算场景
-
大站优先策略
大站优先策略是指对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载 -
反向链接数策略
反向链接数策略是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序 -
最佳优先策略
最佳优先搜索策略是通过计算URL描述文本与目标网页的相似度,或者与主题的相关性,根据所设定的阈值选出有效URL进行抓取
5.4 网页更新策略
用户体验策略
- 在搜索引擎查询某个关键词的时候,通常会搜索大量的网页,并且这些网页会按照一定的规则进行排名,但是,大部分用户都只会关注排名靠前的网页,所以,在爬虫服务器资源有限的情况下,爬虫会优先更新排名结果靠前的网页。这种更新策略称之为用户体验策略。
历史数据策略
- 历史数据策略是依据某一个网页的历史更新数据,通过泊松分布进行建模等手段,预测该网页下一次更新的时间,从而确定下一次对该网页的爬取时间,也就是更新周期
聚类分析策略
- 聚类分析策略的基本原理是首先将海量网页进行聚类分析(即按照相似性进行分类),因为一般来说,相似的网页的更新频率类似。聚类之后,这些海量会被分为多个类,每个类中的网页具有类似的属性,即一般具有类似的更新频率。然后,对聚类结果中的每个类中的网页进行抽样,并计算出抽样网页的平均更新频率,从而确定每个聚类的网页爬行频率
5.5 网络爬虫分类
5.5.1 按功能划分
批量型爬虫
- 批量型爬虫是根据用户配置进行网络数据的抓取,用户通常需要配置的信息包括URL或URL池、爬虫累计工作时间和爬虫累计获取的数据量等信息
- 这种方法适用于互联网数据获取的任何场景,通常用于评估算法的可行性以及审计目标URL数据的可用性。批量式爬虫实际上是增量型爬虫和垂直型爬虫的基础
增量型爬虫
- 增量型爬虫是根据用户配置持续进行网络数据的抓取,用户通常需要配置的信息包括URL或URL池、单个URL数据抓取频度和数据更新策略等信息。因此,增量型爬虫是持续不断的抓取,对于抓取到的网页,要定期更新,并且增量型爬虫需要及时反映这种变化。
- 这种方法可以实时获取互联网数据,通用的商业搜索引擎基本采用
这种爬虫技术。
垂直型爬虫
- 垂直型爬虫是根据用户配置持续进行指定网络数据的抓取,用户通常需要配置的信息包括URL或URL池、敏感热词和数据更新策略等信息。
- 垂直型爬虫的关键是如何识别网页内容是否属于指定行业或者主题。
- 这种方法可以实时获取互联网中与指定内容相关的数据,垂直搜索网站或者垂直行业网站通常采用这种爬虫技术
5.5.2 按系统结构和实现技术划分
通用网络爬虫
- 通用网络爬虫又称全网爬虫,它是根据预先设定的一个或若干初始种子URL开始,以此获得初始网页上的URL列表
- 在爬行过程中不断从URL队列中获取一个的URL,进而访问并下载该页面
- 页面下载后,页面解析器去掉页面上的HTML标记后得到页面内容,将摘要、URL等信息保存到Web数据库中
- 同时抽取当前页面上新的URL,保存到URL队列,直到满足系统停止条件

聚焦网络爬虫
聚焦网络爬虫也叫主题网络爬虫,顾名思义,聚焦网络爬虫是按照预先定义好的主题有选择地进行网页爬虫的一种爬虫技术,聚焦网络爬虫不像通用网络爬虫一样将目标资源定位在全互联网中,而是将爬取的目标网页定位在与主题相关的页面中,可以大大节省爬虫时所需的带宽资源和服务器资源
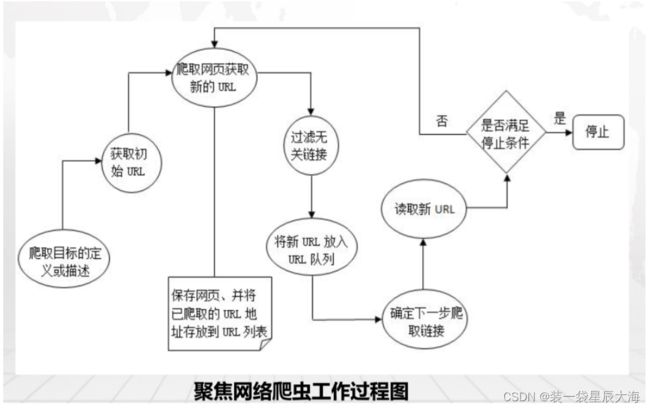
聚焦网络爬虫的功能模块
- 页面采集模块:主要是根据待访问URL队列进行页面下载,再将下载的页面交给页面分析模块处理
- 页面分析模块:对采集到的页面进行分析,主要用于连接超链接排序模块和页面相关计算模块
- 页面相关度计算模块:系统核心模块,主要用于评估页面与主题的相关度,并提供爬行策略指导爬行过程
- 页面过滤模块:过滤掉与主题无关的链接,同时将该URL及其所有隐含的子链接一并去除,保证爬虫效率
- 链接排序模块:将过滤后页面按照优先级加入待访问URL队列
- 内容评价模块:评价内容重要性,根据内容重要性,可以确定哪些页面优先访问
深层网络爬虫
-
DeepWeb(深层页面)是指普通搜索引擎难以发现的信息内容Web页面
-
深层网络爬虫比只爬取表层网页的网络爬虫更复杂些,它在访问并解析出URL后,还需要继续分析该页面是否包含有深层网页入口的表单。若包含,则还要模拟人的行为对该表单进行分析、填充、并提交,最后从返回页面中提取所需要的内容,将其加入到搜索引擎中参与索引,以提供用户查找

分布式网络爬虫
分布式网络爬虫包含多个爬虫,每个爬虫需要完成的任务和单个的爬行器类似,它们从互联网上下载网页,并把网页保存在本地的磁盘,从中抽取URL并沿着这些URL的指向继续爬行

主从式

对等式

5.6 网络爬虫工具
- Googlebot是Google公司的网页抓取器,也称为Google机器人或Google探测器
- 百度蜘蛛是百度搜索引擎的一个自动程序。它的作用是访问收集整理互联网上的网页、图片、视频等内容,然后分门别类建立索引数据库,使用户能在百度搜索引擎中搜索到各网站的网页、图片、视频等内容
- ApacheNutch是一个包含Web爬虫和全文搜索功能的开源搜索引擎,使用Java语言实现。相对于商用的搜索引擎,它的工作流程更加公开透明,拥有很强的可定制性,并且支持分布式爬虫,Nutch最新版本的底层实现使用Hadoop
- 八爪鱼数据采集系统以完全自主研发的分布式云计算平台为核心的,可以非常容易的从任何网页精确采集需要的数据,生成自定义的、规整的数据格式
- 火车采集器是合肥乐维信息技术有限公司开发的一款专业网络数据采集软件。它是一个供各大主流文章系统、论坛系统等使用的多线程内容采集发布程序
- 集搜客是一款功能强大的网页数据抓取软件,它既可以实现数据采集,也可以进行数据挖掘等分析处理
第六章 数据预处理技术
6.1 数据对象与属性类型
- 数据集由数据对象组成,一个数据对象代表一个实体。
- 数据对象又称样本、实例、数据点或对象。
- 数据对象用属性描述。
- 属性是一个数据字段,表示数据对象的一个特征。(在很多文献中,属性、维、特征、变量可以互相转换。)
- 一个属性的类型由该属性可能具有的值的集合决定。属性可以是标称的、二元的、序数的或数值的。
6.1.1 标称属性
- 标称属性(nominal attribute)的值是一些符号或事物的名称。每个值代表某种类别、编码或状态。这些值不必具有有意义的序。在计算机科学中,这些值也被看做是枚举的。
- eg 描述人的时候,发色、婚姻状况
6.1.2 二元属性
- 二元属性属于一种标称属性,只有两个类别或状态:0或1,其中0通常表示该属性不出现,而1表示出现。如果两种状态对应于true和false的话,二元属性又称布尔属性。
- 如果二元属性的两种状态具有同等价值并且携带相同的权重,即关于哪个结果应该用0或1编码并无偏好,称二元属性是对称的。
- 如果二元属性的状态结果不是同样重要的,称二元属性是非对称的。
- eg 艾滋病化验结果 阳性 阴性
6.1.3 序数属性
- 序数属性是一种属性,其可能的值之间具有有意义的序或秩评定,但是相继值之间的差是未知的。
- eg 成绩的ABCD等级 教师职称
6.1.4 数值属性
-
数值属性是定量的,即它是可度量的量,用整数或实数值表示。数值属性可以是区间标度的或比率标度的。
-
区间标度属性用相等的单位尺度度量,值之间的差是有意义的。
-
比率标度属性是具有固有零点的数值属性,差和比率都是有意义的。
-
离散属性与连续属性
-
机器学习领域开发的分类算法通常把属性分成离散的或连续的。离散属性具有有限或无限可数个值,可以用或不用整数表示。例如头发颜色属性有7种取值情况;二元属性取0和1;年龄属性取0到110等。
-
如果属性不是离散的,则它是连续的。在经典意义下,连续值是实数,而数值可以是整数或实数;在实践中,实数值用有限位数字表示,连续属性一般用浮点变量表示。
6.2 数据的统计描述
-
中心趋势度量:均值、中位数和众数





- 数据散布度量:极差、分位数、方差和标准差

- 数据的图形描述:分位数图、直方图和散点图
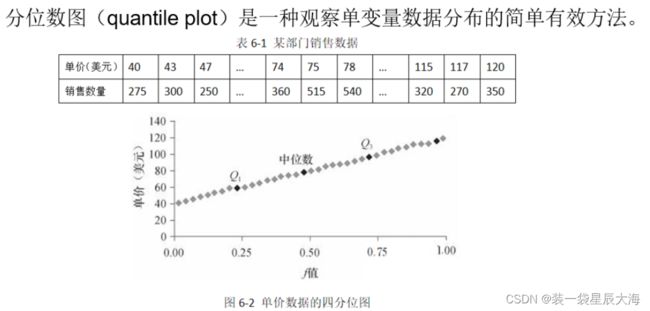
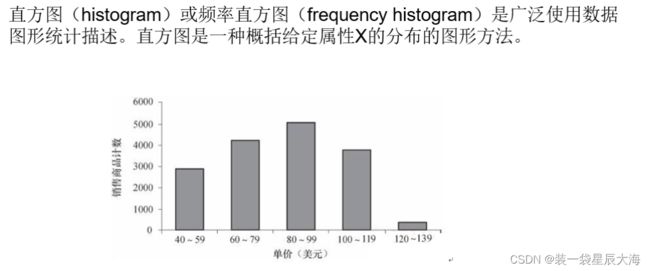
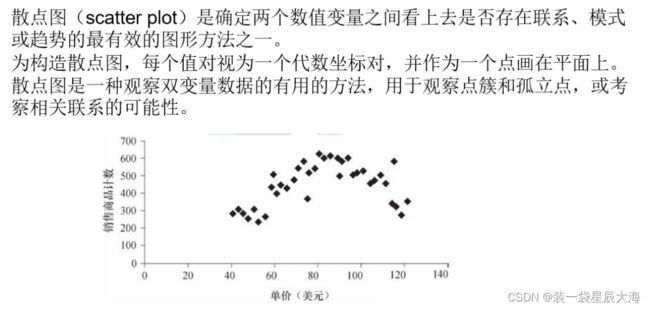




6.2.1 数据预处理
数据预处理(Data Preprocess)是指在对数据进行挖掘以前,需要先对原始数据进行清理、集成、变换以及归约等一系列处理工作,以达到数据挖掘算法进行知识获取所要求的最低规范和标准。
6.2.2 数据质量
- 数据为满足其规范和标准,必须提高数据质量。
- 评估数据质量的参数指标包括
- 准确性
- 完整性
- 一致性
- 时效性
- 可信选
- 可解释性
6.2.3 数据预处理的主要任务
数据清洗定义
数据清洗(Data Cleaning)的过程一般包括填补存在遗漏的数据值、平滑有噪音的数据、识别和除去异常值,并且解决数据不一致等问题。
数据集成定义
数据集成(Data Integration)是指将多个不同数据源的数据合并在一起,形成一致的数据存储,例如,将不同数据库中的数据的集成到一个数据库中进行存储。
数据规约定义
数据归约(Data Reducing)是指在尽可能保持数据原貌的前提下,最大限度地精简数据量,并保证数据归约前后的数据挖掘结果相同或几乎相同。数据归约策略包括维归约和数值归约。
数据变换定义
数据变换(Data Transformation)是指将数据库转换成适合于挖掘的形式,通常包括平滑处理、聚集处理、数据泛化处理、规范化、属性构造等方式。
6.3 数据清洗
6.3.1 数据清洗原理
- 数据清洗原理指的是利用相关技术将脏数据转化为满足数据质量要求的数据。

6.3.1 数据清洗常用方法
-
填充缺失的数据值
- 忽略元组
- 人工填写缺失值
- 使用一个全局常量填充缺失值
- 使用属性的中心度量(如均值或中位数)填充缺失值
- 使用同类样本的属性均值或者中位数填充缺失值
- 使用最可能的值填充缺失值。
-
光滑噪音数据
-
分箱:分箱方法是通过考察数据的 “近邻”值,即周围的值来光滑有序数据的值。
-
等频分箱法
等频分箱法是将数据集按元组个数分箱,每箱具有相同的元组数,每箱元组数称为箱子的深度。
-
等宽法
等宽法是使数据集在整个属性值的区间上平均分布,即每个箱的区间范围是一个常量,称为箱子的宽度。
-
用户自定义区间法等分箱方法
用户自定义区间是指用户可以根据需要自定义区间,当用户明确希望观察某些区间范围内的数据分布时,使用这种方法可以方便地帮助用户达到目的。
-
-
回归:光滑数据可以利用数学中的拟合函数来实现,数学中称为回归。
- 线性回归就是通过找出拟合两个属性的“最佳”直线,使得其中一个属性可以用于预测出另一个属性
- 多元线性回归是线性回归的扩展,其涉及的属性多于两个,并且将数据拟合到一个多维曲面。
-
孤立点分析:孤立点可通过聚类进行检测。
- 聚类是将相似的值组织成群或“簇”,那么落在簇集合外的值被称为孤立点(或离群点)
-
-
识别和删除离群点
-
纠正数据不一致
检测偏差。这是数据清洗的第一步。通常,可以根据已知的数据性质的知识(如,数据类型和定义域等)发现噪声、孤立点和需要考察的不寻常的值。
纠正偏差。一旦发现数据偏差,通常需要使用一系列变换来纠正。例如,利用数据迁移工具实现字符串的替换。但是,这些工具通常只能实现有限的变换。因此常常可能需要为纠正偏差编写定制的程序。
6.4 数据归约
- 数据归约技术可以用来得到数据集的归约表示,使得数据集变小,但同时仍然近于保持原数据的完整性。也就是说,在归约后的数据集上进行挖掘,依然能够得到与使用原数据集近乎相同(或几乎相同)的分析结果。
6.4.1 经典数据归约策略
- 维归约
- 数量归约
- 数据压缩
6.4.2 常用方法
6.4.2.1 小波变换

6.4.2.2 主成分分析

6.4.2.3 属性子集选择

6.4.2.4 回归和对数线性模型



6.4.2.7 抽样


6.4.2.8 数据立方体聚集
- 在对现实世界数据进行采集时,采集到的往往并不是你感兴趣数据,而是需要对数据进行聚集。
- 数据立方体是一种多维数据模型,允许用户从多维对数据建模和观察。数据立方体是二维表格的多维扩展,但是数据立方体不局限于三个维度。
6.5 通过规范化变换数据
- 规范化数据试图赋予所有属性相等的权重。
- 规范化对于涉及神经网络的分类算法、基于距离度量的分类(如最近邻分类)和聚类特别有用。
6.5.1 常用的数据规范化方法
最小-最大规范化

z分数规范化

按小数定标规范化

6.6 通过离散化变换数据
- 利用分箱方法可以实现数据离散化。
- 直方图分析也是一种非监督离散化技术。
- 聚类也是一种流行的离散化方法。
- 分类决策树算法是一种自顶向下划分方法,也可以用于离散化。
- 相关性度量也可以用于实现数据离散化。
6.7 标称数据的概念分层变换
对于标称数据,人工定义概念分层是一项耗时的任务。实际上,很多标称数据的分层结构信息都隐藏在数据库的模式中,并且可以在模式定义中自动地定义。
6.7.1 常用的标称数据概念分层方法
- 在模式级显式地说明属性的部分序:通常标称属性的概念分层涉及一组属性,因此,用户或专家可以在模式级通过说明属性的偏序或全序定义概念分层。
- 通过显式数据分组说明分层结构的一部分:这实际上是一种人工定义概念分层结构方法。在大型数据库中,通过显式的值枚举定义整个概念分层是不现实的。然而,对于一小部分中间层数据,可以很容易地显式说明分组。
- 说明属性集但不说明它们的偏序:用户可以说明一个属性集形成概念分层,但并不显式说明它们的偏序。然后,系统试图自动地产生属性的序,构造有意义的概念分层。
- 嵌入数据语义:在定义分层时,由于对分层结构概念模糊,可能在分层结构的说明中只包含了相关属性的一小部分。
习题整理
1.采用哪些方式可以获取大数据?
(1)通过业务系统或者互联网端的服务器自动汇聚(系统日志采集,网络数据采集(通过网络爬虫实现)),如业务数据、用户行为数据等。
(2)通过卫星、摄像机和传感器等硬件设备自动汇聚,如遥感数据、交通数据等。
(3)通过整理汇聚,如商业景气数据、人口普查数据等。
2.常用大数据采集工具有哪些?
(1)Apache Chukwa,一个针对大型分布式系统的数据采集系统,其构建在Hadoop之上,使用HDFS作为存储。
(2)Flume,一个功能完备的分布式日志采集、聚合和传输系统。在Flume中,外部输入称为Source(源),系统输出称为Sink(接收端),Channel(通道)将源和接收端链接在一起。
(3)Scrible,facebook开源的日志收集系统。
(4)Kafka,当下流行的分布式发布、订阅消息系统,也可用于日志聚合。不仅具有高可拓展性和容错性,而且具有很高的吞吐量。特点是快速的、可拓展的、分布式的、分区的和可复制的。
3.简述什么是Apache Kafka数据采集。
Apache Kafka 是当下流行的分布式发布、订阅消息系统,被设计成能够高效地处理大量实时数据,其特点是快速的、可拓展的、分布式的、分区的和可复制的。Kafka是用Scala语言编写的,虽然置身于Java阵营,但其并不遵循JMS规范。
4.Topic可以有多少个分区,这些分区有什么用?
一个Topic可以有多个分区,这些分区可以作为并行处理的单元,从而使Kafka有能力高效地处理大量数据。
5.Kafka抽象具有哪种模式的特征消费组?
Kafka提供一种单独的消费者抽象,此抽象具有两种模式的特征消费组:Queuing和Publish-Subscribe。
6.简述数据预处理的原理。
数据预处理(Data Preprocessing)是指在对数据进行挖掘以前,需要对原始数据进行清理、集合和变换等一系列处理工作,以达到挖掘算法进行知识获取研究所要求的最低规范和标准。通过数据预处理工作,可以使残缺的数据完整,并将错误的数据纠正、多余的数据去除,进而将所需的数据进行数据集成。数据预处理的常见方法有数据清洗、数据集成和数据变换。
7.数据清洗有哪些方法?
(1)填充缺失值。常用处理方法:忽略元组、人工填写缺失值、使用一个全局变量填充缺失值、用属性的均值填充缺失值、用同类样本的属性均值填充缺失值、使用最可能的值填充缺失值。
(2)光滑噪声数据。方法:分箱、回归、聚类。
(3)数据清洗过程,包括检测偏差和纠正偏差。
8.数据集成需要重点考虑的问题有哪些?
(1)模式集成和对象匹配问题。
(2)冗余问题。
(3)元组重复。
(4)数据值冲突的检测与处理问题。
9.数据变换主要涉及哪些内容?
(1)光滑。去除数据中的噪声。
(2)聚集。对数据进行汇总或聚集。
(3)数据泛化。使用概念分层,用高层概念代替底层或“原始”数据。
(4)规范化。将属性数据按比例缩放,使之落入一个小的特定区间。
(5)属性构造。可以构造新的属性并添加到属性集中,以帮助挖掘过程。
10.分别简述常用ETL工具。
ETL是用来描述将数据从源端经过提取、转换、装入到目的端的过程。
常用工具有:
(1)PowerCenter。Informatica的PowerCenter是一个可拓展、高性能企业数据集成平台,应用于各种数据集成流程,通过该平台可实现自动化、重复使用及灵活性。
(2)IBM Datastage。IBM InfoSphere Datastage是一款功能强大的ETL工具,是IBM数据集成平台IBM Information Server的一部分,是专门的数据提取、数据转换、数据发布工具。
(3)Kettle。Kattle是Pentaho的ETL工具,Pentaho是一套开源的解决方案。Kattle是一款国外优秀的开源ETL工具,由纯Java编写,可以在Windows、Linux、UNIX上运行,无需安装,数据抽取高效稳定。
?**
一个Topic可以有多个分区,这些分区可以作为并行处理的单元,从而使Kafka有能力高效地处理大量数据。
5.Kafka抽象具有哪种模式的特征消费组?
Kafka提供一种单独的消费者抽象,此抽象具有两种模式的特征消费组:Queuing和Publish-Subscribe。
6.简述数据预处理的原理。
数据预处理(Data Preprocessing)是指在对数据进行挖掘以前,需要对原始数据进行清理、集合和变换等一系列处理工作,以达到挖掘算法进行知识获取研究所要求的最低规范和标准。通过数据预处理工作,可以使残缺的数据完整,并将错误的数据纠正、多余的数据去除,进而将所需的数据进行数据集成。数据预处理的常见方法有数据清洗、数据集成和数据变换。
7.数据清洗有哪些方法?
(1)填充缺失值。常用处理方法:忽略元组、人工填写缺失值、使用一个全局变量填充缺失值、用属性的均值填充缺失值、用同类样本的属性均值填充缺失值、使用最可能的值填充缺失值。
(2)光滑噪声数据。方法:分箱、回归、聚类。
(3)数据清洗过程,包括检测偏差和纠正偏差。
8.数据集成需要重点考虑的问题有哪些?
(1)模式集成和对象匹配问题。
(2)冗余问题。
(3)元组重复。
(4)数据值冲突的检测与处理问题。
9.数据变换主要涉及哪些内容?
(1)光滑。去除数据中的噪声。
(2)聚集。对数据进行汇总或聚集。
(3)数据泛化。使用概念分层,用高层概念代替底层或“原始”数据。
(4)规范化。将属性数据按比例缩放,使之落入一个小的特定区间。
(5)属性构造。可以构造新的属性并添加到属性集中,以帮助挖掘过程。
10.分别简述常用ETL工具。
ETL是用来描述将数据从源端经过提取、转换、装入到目的端的过程。
常用工具有:
(1)PowerCenter。Informatica的PowerCenter是一个可拓展、高性能企业数据集成平台,应用于各种数据集成流程,通过该平台可实现自动化、重复使用及灵活性。
(2)IBM Datastage。IBM InfoSphere Datastage是一款功能强大的ETL工具,是IBM数据集成平台IBM Information Server的一部分,是专门的数据提取、数据转换、数据发布工具。
(3)Kettle。Kattle是Pentaho的ETL工具,Pentaho是一套开源的解决方案。Kattle是一款国外优秀的开源ETL工具,由纯Java编写,可以在Windows、Linux、UNIX上运行,无需安装,数据抽取高效稳定。