SDM原理解读与工程实践
SDM原理解读与工程实践
本文主要介绍的是阿里在召回阶段使用的深度召回模型SDM,paper名称为《SDM: Sequential Deep Matching Model for Online Large-scale Recommender System》
一. 概述
在推荐系统召回阶段,我们需要从海量的items当中选择出用户感兴趣的候选items, 然后放入到精排里面进行排序。因此,如何有效快速地选择出用户感兴趣的候选集非常重要。而在这篇paper当中,阿里将用户短期的行为序列和用户长期的行为序列融合起来,通过捕获用户变化的发展的和多样的兴趣喜好来候选出用户感兴趣的候选items
二. 需要了解的基础
(1)LSTM
(2)自注意力机制(Self-Attention Mechanism)
如果对这两个知识点没有基础,建议先阅读相关资料
三. 模型架构
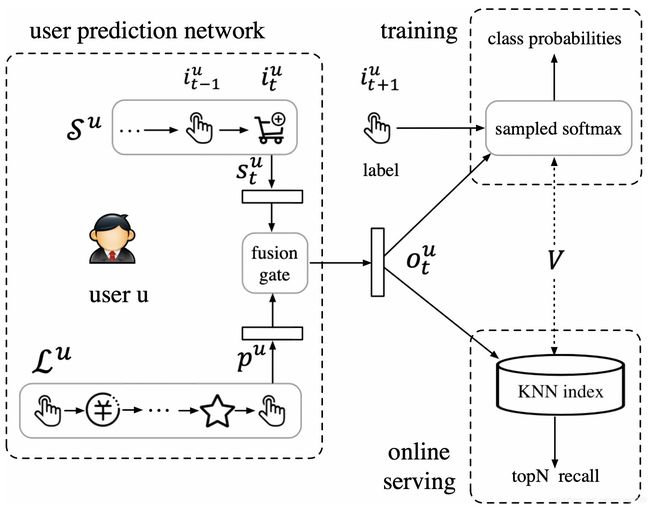
可以看到架构分成了三个部分
(1)User Prediction Network
在这个部分,Su表示用户最近一次的与item的交互序列,Su={i1, i2, i3, …, it}, it表示在t时刻用户交互的item。Lu则表示用户最近7天的所有行为序列。
然后,利用Su训练出表示短期兴趣的embedding(st),利用Lu训练出表示用户长期兴趣的embedding(pu)。
将sut和pu通过一个fusion gate(后面会讲解),生成最终表示用户长短期兴趣的embedding向量ot。
(2)Training
在training阶段,我们将ot做为输入,t时刻的下一个样本it+1做为要预测的正样本, 然后采样其他的items做为负样本,通过sampled-softmax的方法训练
(3)Serving
在training阶段我们得到了所有items对应的embedding,因此在serving的阶段我们可以通过取ot的距离最近的k个items,做为这个用户最终的候选集。
下面,我们将会对User Prediction Network的细节进行讲解。
四. User Prediction Network
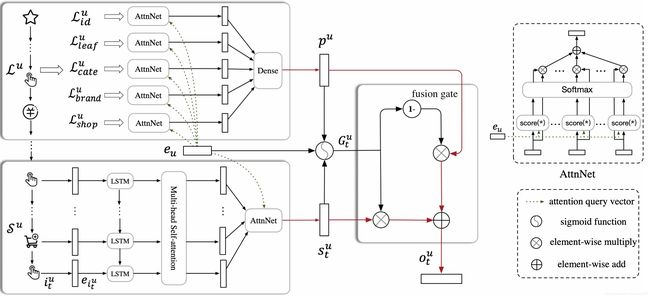
(1) 输入item序列转化成embedding
对于短期序列Su={i1,i2,i3, …,it}中的每个item,在转化成embedding输入的时候,不仅考虑到了item id,还需要考虑到其他side information,包括类型,品牌,商店等等。将这些id先分别转化成embedding,然后再将这些embedding全部拼接起来,做为这个item最终的embedding。表达式如下


对于用户也是一样的,除了use id以外,还可以加入年龄,性别等等这些特征,组成最终的用户embedding(eu)
(2) LSTM层
生成短期序列对应的embedding序列以后,将放入到LSTM当中,以捕获用户喜好的趋势,LSTM公式如下
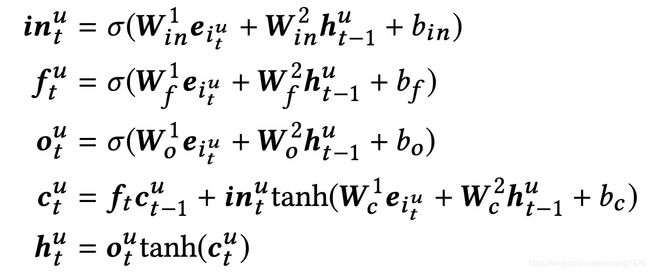
然后将得到的ht传递给更高层的attention网络
(3)Multi-head Self-Attention网络
用户每次在浏览电商网站的时候,商品都会较为相似,但同时也会浏览一些不相关的商品。为了减轻这种随机行为对结果的影响,作者加入了一层Self-Attention网络。为了捕获用户的多个兴趣点,因此使用了Multi-head Self-Attention。其中,Attendtion的Query,Key和Value均使用了LSTM层的输出作为输入。Multi-head Self-Attention公式摘抄自paper如下

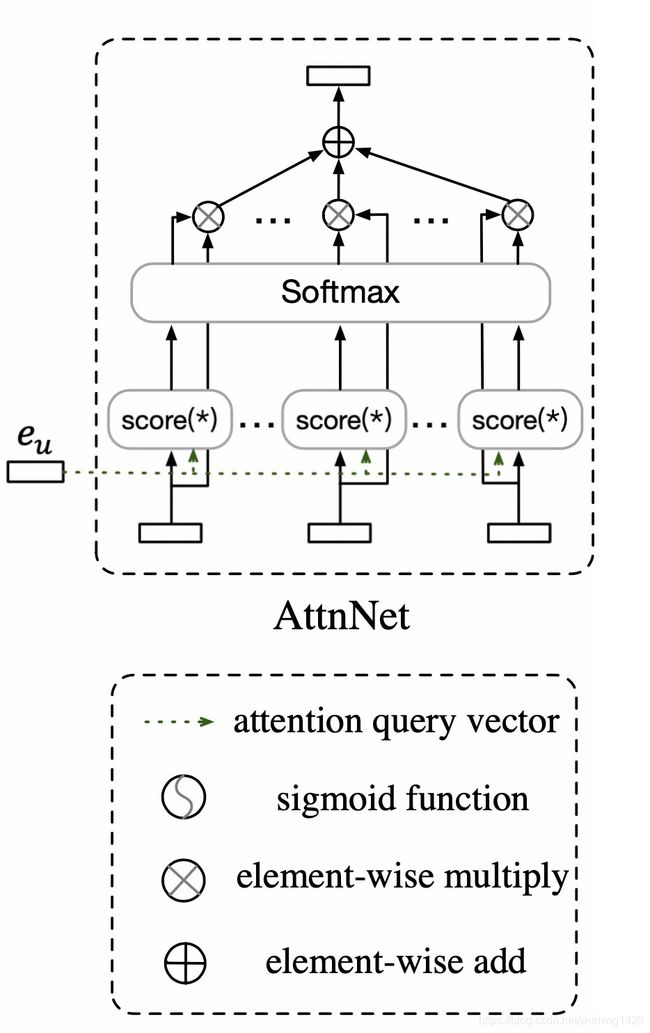
(4)User Attention层
对于不同的用户,即使是相似的商品集合,用户在偏好方面也可能有所不同。因此使用User Attention层去捕获更细粒度的用户偏好。使用用户的embedding(eu)作为attention的query。公式如下所示
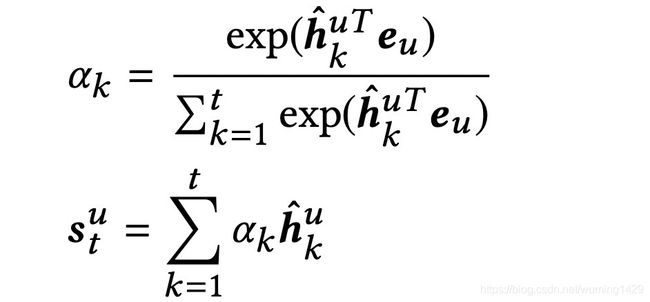
其中h是Multi-head Self-Attention网络的输出。User Attention层如下图所示
(5)短期行为和长期行为融合
对于长期行为的序列Lu,我们首先按照特征将序列进行拆分成子集:Lid(item ID),Lshop(shop),Lbrand(brand)等等。例如Lshop包含用户过去7天所有交互过的商店。
然后这些L子集首先转化成embedding(注意这里的embedding空间是和短期行为的embedding空间是共享的,例如同一个item ID在长期行为和短期行为中转化成embedding是一样的),使用用户的embedding分别计算每个子集里面每个embedding的得分。公式如下所示
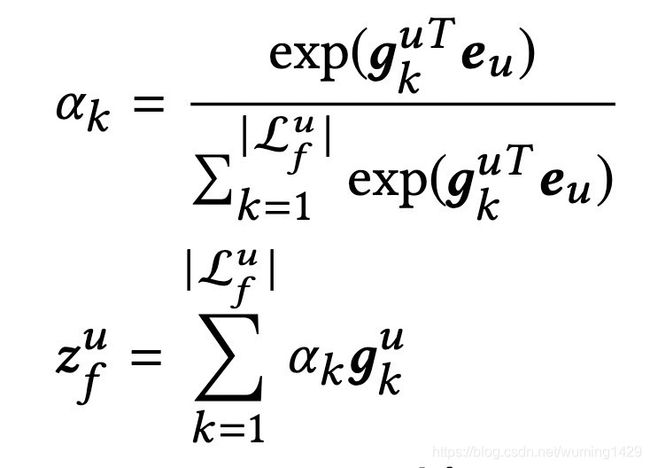
gk表示Lu子集里面第k个embedding。
然后将每个子集生成的embedding拼接起来,再经过一层全连接生成最终的pu。公式如下

最终,将生成的eu,st,pu做为输入加入到一个gate里面,然后生成最终的结果ot。公式如下所示
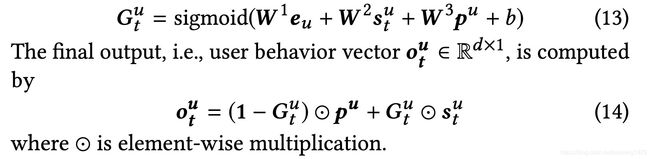
五. SDM召回实践
下面使用ml-1m数据集,实践一下SDM召回模型。该模型的实现主要参考:python软件的DeepCtr和DeepMatch模块。
- u2i召回
SDM模型训练完成可得到用户和物品的Embedding向量,再利用向量最近邻的方法(如局部敏感哈希LSH、kd树、annoy、milvus、faiss等)可计算出与每个用户最相似(向量相似度最高)的top-m个物品。线上召回时输入用户特征给模型,模型预测得到用户向量,利用向量检索工具召回M个相似物品作为候选物品作为该路召回的结果,进入后续的排序阶段。
- I2I召回
SDM模型训练完成后输入物品特征会生成每个物品的Embedding向量,再利用向量最近邻的方法(如局部敏感哈希LSH、kd树、annoy、milvus、faiss等)可计算出与每个物品最相似(向量相似度最高)的top-m个物品。线上召回时可根据用户最近操作(如点击)过的N个物品,分别召回k个相似物品,一共N*k个作为候选物品作为该路召回的结果,进入后续的排序阶段。
3)两种召回方式效果对比
u2i召回:
对用户行为预测为一个向量后再召回用户向量的topN个物品
i2i召回:
用户最近L个行为物品一一召回k个物品,总体再求topN个物品
用开源数据集ml-1m测试得到的结果如下(与DSSM、youtubeDNN、FM对比):
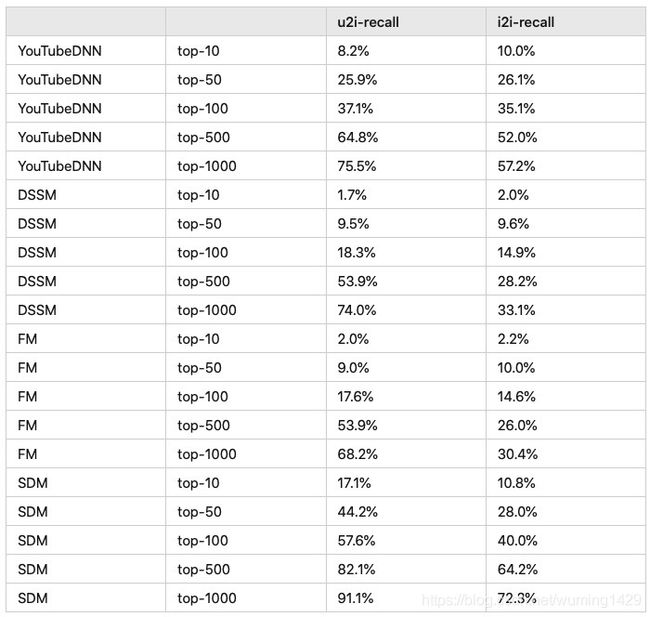
由上述结果可知,对ml-1m数据集u2i召回方式效果要好于i2i召回方式。并且SDM召回的效果要优于youtubeDNN、DSSM、FM。
完整代码如下:
import pandas as pd
from deepctr.feature_column import SparseFeat, VarLenSparseFeat
from preprocess import gen_data_set_sdm,gen_model_input_sdm
from sklearn.preprocessing import LabelEncoder
from tensorflow.python.keras import backend as K
from tensorflow.python.keras.models import Model
from tensorflow import keras
from deepmatch.models import *
from deepmatch.utils import sampledsoftmaxloss
import numpy as np
import faiss
from tqdm import tqdm
from deepmatch.utils import recall_N
import os
data_path = "../"
unames = ['user_id','gender','age','occupation','zip']
user = pd.read_csv(data_path+'ml-1m/users.dat',sep='::',header=None,names=unames,engine='python')
rnames = ['user_id','item_id','rating','timestamp']
ratings = pd.read_csv(data_path+'ml-1m/ratings.dat',sep='::',header=None,names=rnames,engine='python')
mnames = ['item_id','title','genres']
movies = pd.read_csv(data_path+'ml-1m/movies.dat',sep='::',header=None,names=mnames,engine='python')
data = pd.merge(pd.merge(ratings,movies),user)
sparse_features = ["item_id", "user_id", "gender", "age", "occupation", "zip", ]
SEQ_LEN_short = 5
SEQ_LEN_prefer = 50
# 1.稀疏特征编码,生成训练和测试集
features = ['user_id', 'item_id', 'gender', 'age', 'occupation', 'zip', 'genres']
feature_max_idx = {}
for feature in features:
lbe = LabelEncoder()
data[feature] = lbe.fit_transform(data[feature]) + 1
feature_max_idx[feature] = data[feature].max() + 1
user_profile = data[["user_id", "gender", "age", "occupation", "zip", "genres"]].drop_duplicates('user_id')
item_profile = data[["item_id"]].drop_duplicates('item_id')
user_profile.set_index("user_id", inplace=True)
train_set, test_set = gen_data_set_sdm(data, seq_short_len=SEQ_LEN_short, seq_prefer_len=SEQ_LEN_prefer)
train_model_input, train_label = gen_model_input_sdm(train_set, user_profile, SEQ_LEN_short, SEQ_LEN_prefer)
test_model_input, test_label = gen_model_input_sdm(test_set, user_profile, SEQ_LEN_short, SEQ_LEN_prefer)
# 2.count #unique features for each sparse field and generate feature config for sequence feature
embedding_dim = 32
# for sdm,we must provide `VarLenSparseFeat` with name "prefer_xxx" and "short_xxx" and their length
user_feature_columns = [SparseFeat('user_id', feature_max_idx['user_id'], 16),
SparseFeat("gender", feature_max_idx['gender'], 16),
SparseFeat("age", feature_max_idx['age'], 16),
SparseFeat("occupation", feature_max_idx['occupation'], 16),
SparseFeat("zip", feature_max_idx['zip'], 16),
VarLenSparseFeat(SparseFeat('short_item_id', feature_max_idx['item_id'], embedding_dim,
embedding_name="item_id"), SEQ_LEN_short, 'mean',
'short_sess_length'),
VarLenSparseFeat(SparseFeat('prefer_item_id', feature_max_idx['item_id'], embedding_dim,
embedding_name="item_id"), SEQ_LEN_prefer, 'mean',
'prefer_sess_length'),
VarLenSparseFeat(SparseFeat('short_genres', feature_max_idx['genres'], embedding_dim,
embedding_name="genres"), SEQ_LEN_short, 'mean',
'short_sess_length'),
VarLenSparseFeat(SparseFeat('prefer_genres', feature_max_idx['genres'], embedding_dim,
embedding_name="genres"), SEQ_LEN_prefer, 'mean',
'prefer_sess_length'),
]
item_feature_columns = [SparseFeat('item_id', feature_max_idx['item_id'], embedding_dim)]
K.set_learning_phase(True)
import tensorflow as tf
if tf.__version__ >= '2.0.0':
tf.compat.v1.disable_eager_execution()
# units must be equal to item embedding dim!
model = SDM(user_feature_columns, item_feature_columns, history_feature_list=['item_id', 'genres'],
units=embedding_dim, num_sampled=100, )
model.compile(optimizer='adam', loss=sampledsoftmaxloss) # "binary_crossentropy")
history = model.fit(train_model_input, train_label, # train_label,
batch_size=512, epochs=20, verbose=1, validation_split=0.0, )
K.set_learning_phase(False)
# 4. 生成用户emb和物品emb,用于召回
test_user_model_input = test_model_input
all_item_model_input = {"item_id": item_profile['item_id'].values,}
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
user_embs = user_embedding_model.predict(test_user_model_input, batch_size=2 ** 12)
item_embs = item_embedding_model.predict(all_item_model_input, batch_size=2 ** 12)
test_user_np = test_user_model_input['user_id']
all_item_np = all_item_model_input['item_id']
test_user_emb_all = np.hstack((test_user_np.reshape(-1, 1),user_embs))
all_item_all = np.hstack((all_item_np.reshape(-1, 1),item_embs))
np.savetxt('user_embs.csv', test_user_emb_all, delimiter = ',')
np.savetxt('item_embs.csv', all_item_all, delimiter = ',')
print(test_user_emb_all.shape)
print(all_item_all.shape)
test_true_label = {line[0]:[line[3]] for line in test_set}
# 5、faiss 创建索引 插入item_embs
index = faiss.IndexFlatIP(embedding_dim)
# faiss.normalize_L2(item_embs)
index.add(item_embs)
# 6、根据user_emb 检索物品列表
# faiss.normalize_L2(user_embs)
D, I = index.search(np.ascontiguousarray(user_embs), 1000)
s1000 = []
s500 = []
s100 = []
s50 = []
s10 = []
hit = 0
filename = 'user_emb_rec_list.txt'
if os.path.exists(filename):
os.remove(filename)
with open(filename, 'a') as f:
for i, uid in tqdm(enumerate(test_user_model_input['user_id'])):
pred = [item_profile['item_id'].values[x] for x in I[i]]
item_list = ",".join('%s' %x for x in pred)
filter_item = None
recall_score_1000 = recall_N(test_true_label[uid], pred, N=1000)
recall_score_500 = recall_N(test_true_label[uid], pred, N=500)
recall_score_100 = recall_N(test_true_label[uid], pred, N=100)
recall_score_50 = recall_N(test_true_label[uid], pred, N=50)
recall_score_10 = recall_N(test_true_label[uid], pred, N=10)
s1000.append(recall_score_1000)
s500.append(recall_score_500)
s100.append(recall_score_100)
s50.append(recall_score_50)
s10.append(recall_score_10)
# if test_true_label[uid] in pred:
# hit += 1
f.write("{} {}\n".format(uid, item_list))
print("recall1000", np.mean(s1000))
print("recall500", np.mean(s500))
print("recall100", np.mean(s100))
print("recall50", np.mean(s50))
print("recall10", np.mean(s10))
# print("hit rate", hit / len(test_user_model_input['user_id']))
# 7、根据item_emb 检索物品列表生成I2I倒排索引
# faiss.normalize_L2(item_embs)
D, I = index.search(np.ascontiguousarray(item_embs), 50)
s1000 = []
s500 = []
s100 = []
s50 = []
s10 = []
hit = 0
i2i_dict = {}
filename = 'item_item_list.txt'
if os.path.exists(filename):
os.remove(filename)
with open(filename, 'a') as f:
for i, item_id in tqdm(enumerate(all_item_model_input['item_id'])):
pred = [item_profile['item_id'].values[x] for x in I[i] ]
pred2 = [x for x in pred if x != item_id]
item_list = ",".join('%s' % x for x in pred2)
# i2i倒排索引
i2i_dict[item_id] = [x for x in pred2]
f.write("{} {}\n".format(item_id, item_list))
# 不改变顺序去重
def dupe(items):
seen = set()
for item in items:
if item not in seen:
yield item
seen.add(item)
# 8、根据用户最近操作的50个物品检索物品列表
data.sort_values("timestamp", inplace=True, ascending=False)
filename = 'user_action_rec_list.txt'
if os.path.exists(filename):
os.remove(filename)
filename2 = 'user_action_rec_list2.txt'
if os.path.exists(filename2):
os.remove(filename2)
filename3 = 'user_action_list.txt'
if os.path.exists(filename3):
os.remove(filename3)
with open(filename, 'a') as f, open(filename2,'a') as f2, open(filename3,'a') as f3:
for uid, hist in tqdm(data.groupby('user_id')):
pred = []
result = []
# 截取最近50个物品
pos_list = hist['item_id'].tolist()[1:51]
act_list = ",".join('%s' % x for x in pos_list)
# 根据这50个物品检索物品列表
for item_id in pos_list:
pred = pred + i2i_dict[item_id]
result.append(str(item_id) + ":[" + ",".join('%s' % x for x in i2i_dict[item_id]) + "]")
pred = list(dupe(pred))
pred = pred[:1000]
item_list = ",".join('%s' % x for x in result)
item_list2 = ",".join('%s' % x for x in pred)
filter_item = None
recall_score_1000 = recall_N(test_true_label[uid], pred, N=1000)
recall_score_500 = recall_N(test_true_label[uid], pred, N=500)
recall_score_100 = recall_N(test_true_label[uid], pred, N=100)
recall_score_50 = recall_N(test_true_label[uid], pred, N=50)
recall_score_10 = recall_N(test_true_label[uid], pred, N=10)
s1000.append(recall_score_1000)
s500.append(recall_score_500)
s100.append(recall_score_100)
s50.append(recall_score_50)
s10.append(recall_score_10)
# if test_true_label[uid] in pred:
# hit += 1
f.write("{} {}\n".format(uid, item_list))
f2.write("{} {}\n".format(uid, item_list2))
f3.write("{} {}\n".format(uid, act_list))
print("recall1000", np.mean(s1000))
print("recall500", np.mean(s500))
print("recall100", np.mean(s100))
print("recall50", np.mean(s50))
print("recall10", np.mean(s10))
五、相关思考
1)SDM为什么召回效果明显优于youtubeDNN和DSSM?
2)是否可以优化youtubeDNN和DSSM使其召回效果达到跟SDM差不多?