pytorch实现DCGAN生成动漫人物头像
pytorch实现DCGAN生成动漫人物头像
DCGAN原理
参考这一系列文章
数据集
21551张64*64动漫人物头像
生成效果
训练1个epoch(emm…)

训练10个epoch(起码有颜色了)
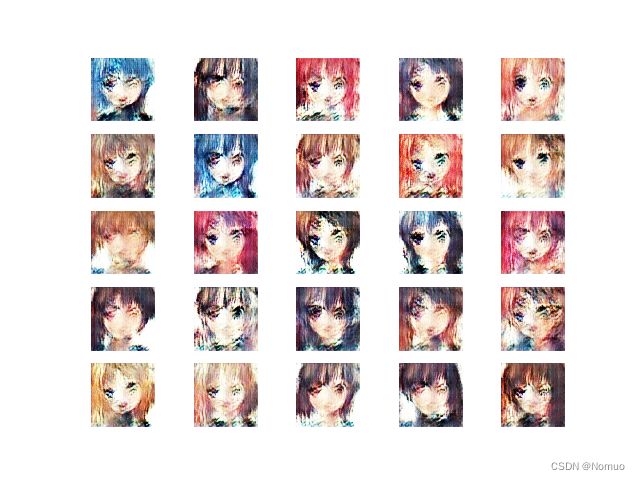
训练20个epoch(有点吓人)

训练50个epoch(有一两张能看的)

继续跑效果应该更好
loss(GAN的loss会来回波动):

pytorch实现
数据加载
文件名:data_loader.py
DATA_PATH为存放上述动漫头像的路径,读入的时候进行了预处理耗时较久
DATA_PATH = './data/'
import cv2
import os
import numpy as np
def load_data():
"""
:rtype: np.ndarray
"""
images = []
for img_name in os.listdir(DATA_PATH):
img = cv2.cvtColor(
cv2.resize(
cv2.imread(DATA_PATH + img_name, cv2.IMREAD_COLOR), (64, 64)
),
cv2.COLOR_BGR2RGB
)
images.append(img)
images = np.array(images)
# 将0到255转换为-1到1,以适应tanh函数输出
images = images / 127.5 - 1
np.random.shuffle(images)
# 将通道放到索引后面
images = images.transpose(0, 3, 1, 2)
return images
data = load_data() # 索引、通道、高、宽的四维ndarray
模型
文件名:model.py
import torch.nn as nn
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
# 使用反卷积+batch normalization+relu
def generator_builder(in_channels, out_channels, kernel_size, stride, padding):
return [
nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, padding),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
]
self.net = nn.Sequential(
*generator_builder(100, 64 * 8, 4, 1, 0),
*generator_builder(64 * 8, 64 * 4, 4, 2, 1),
*generator_builder(64 * 4, 64 * 2, 4, 2, 1),
*generator_builder(64 * 2, 64, 4, 2, 1),
nn.ConvTranspose2d(64, 3, 4, 2, 1),
nn.Tanh() # 生成器使用tanh
)
def forward(self, x):
return self.net(x)
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
# 使用卷积+batch normalization+leakyRelu
def discriminator_builder(in_channels, out_channels, kernel_size, stride, padding):
return [
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.2, inplace=True)
]
self.net = nn.Sequential(
*discriminator_builder(3, 64, 4, 2, 1),
*discriminator_builder(64, 64 * 2, 4, 2, 1),
*discriminator_builder(64 * 2, 64 * 4, 4, 2, 1),
*discriminator_builder(64 * 4, 64 * 8, 4, 2, 1),
nn.Conv2d(64 * 8, 1, 4, 1, 0),
nn.Sigmoid() # 判别器使用sigmoid
)
def forward(self, x):
return self.net(x)
图片展示工具
文件名:utils.py
SAVE_PATH为图片保存路径
import matplotlib.pyplot as plt
SAVE_PATH = './results/'
def show_images(images, index):
plt.clf()
for i, img in enumerate(images[:25]):
plt.subplot(5, 5, i + 1)
plt.axis('off')
plt.imshow(img)
plt.gcf().savefig(f'{SAVE_PATH}gen_img_epoch_{index}.png')
def show_losses(loss_d, loss_g):
plt.clf()
plt.plot(loss_d, color='r')
plt.plot(loss_g, color='b')
plt.legend(('D loss', 'G loss'), loc='upper right')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.gcf().savefig(f'{SAVE_PATH}losses.png')
训练
文件名:trainer.py
MODEL_SAVE_PATH为模型保存路径
import torch
import torch.optim as opt
import numpy as np
import model
import data_loader
import utils
MODEL_SAVE_PATH = './model/'
REAL_LABEL = 1.0
FAKE_LABEL = 0.0
class trainer:
def __init__(self, batch_size, epochs):
self.device = torch.device('cuda')
self.generator = model.generator().to(self.device)
self.discriminator = model.discriminator().to(self.device)
self.loss_func = torch.nn.BCELoss()
# 学习率和beta的修改来自DCGAN原论文
self.opt_gen = opt.Adam(self.generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
self.opt_dis = opt.Adam(self.discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
self.batch_size = batch_size
self.epochs = epochs
def train(self):
data = torch.asarray(data_loader.data).type(torch.FloatTensor)
label = torch.FloatTensor(self.batch_size).to(self.device)
losses_d = []
losses_g = []
batch_num = int(data.shape[0] / self.batch_size)
for epoch in range(1, self.epochs + 1):
for batch in range(0, batch_num):
batch_data = data[batch * self.batch_size:(batch + 1) * self.batch_size].to(self.device)
is_last_batch = batch == batch_num - 1
# 训练判别器
self.opt_dis.zero_grad()
out = self.discriminator(batch_data).squeeze()
label.data.fill_(REAL_LABEL)
loss_d_true = self.loss_func(out, label) # type: torch.Tensor
loss_d_true.backward()
noise = torch.randn(self.batch_size, 100, 1, 1).to(self.device)
fake = self.generator(noise)
out = self.discriminator(fake.detach()).squeeze()
label.data.fill_(FAKE_LABEL)
loss_d_fake = self.loss_func(out, label) # type: torch.Tensor
loss_d_fake.backward()
self.opt_dis.step()
# 仅在每一epoch的最后一个batch记录损失
if is_last_batch:
loss_d = loss_d_fake + loss_d_true
losses_d.append(loss_d.item())
# 训练生成器
self.opt_gen.zero_grad()
label.data.fill_(REAL_LABEL)
out = self.discriminator(fake).squeeze()
loss_g = self.loss_func(out, label) # type: torch.Tensor
loss_g.backward()
self.opt_gen.step()
# 仅在每一epoch的最后一个batch记录损失
if is_last_batch:
losses_g.append(loss_g.item())
noise = torch.randn(25, 100, 1, 1).to(self.device)
gen_images = self.generator(noise)
gen_images = gen_images.detach().cpu().numpy()
gen_images = (gen_images.transpose(0, 2, 3, 1) + 1) * 127.5
gen_images = gen_images.astype(np.uint8)
utils.show_images(gen_images, epoch)
print(f'epoch {epoch} finished')
utils.show_losses(losses_d, losses_g)
torch.save(self.generator.state_dict(), MODEL_SAVE_PATH + f'generator.pth')
torch.save(self.discriminator.state_dict(), MODEL_SAVE_PATH + f'discriminator.pth')
开始训练和生成图像
文件名:main.py
128为batch size(DCGAN原文使用较小的batch size),50为epoch
import trainer
if __name__ == '__main__':
trainer.trainer(128, 50).train()