基于pytorch的dcgan网络的mnist手写体生成(附百度云整个工程文件夹)
文章目录
- 引言
- generator网络结构部分
- discriminator网络结构部分
- train代码
- 训练情况
- 遇到的问题
- 完整工程代码
引言
cgan全称是Conditional Generative Adversarial Nets,简单来说就是条件生成-对抗网络。
可以控制网络生成我们所需要的指定类型的图片,比如一般的GAN网络只能生成没有规律的手写数据体,但是CGAN可以生成我们想要的具体数字。由于DCGAN中加入了卷积层,所以性能也要比简单的线性层的CGAN强,体现在图片上就是噪点更少。
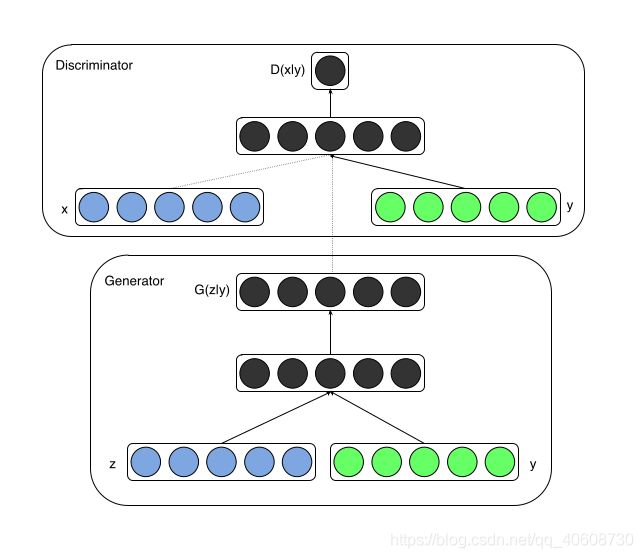
CGAN的网络结构如图所示,生成网络的输入的是高斯分布的噪声z和条件y,输出的就是图片,判别网络的输入是图片x和条件y,输出的是经过sigmoid激活函数处理后的值。
generator网络结构部分
class Generator(nn.Module):
"""docstring for Generator"""
def __init__(self):
super(Generator, self).__init__()
self.label_emb = nn.Embedding(10, 10)
self.fn1 = nn.Sequential(
nn.Linear(110, 32*7*7),
nn.ReLU())
self.conv1=nn.Sequential(
nn.Conv2d(32,64,3,1,1),
nn.BatchNorm2d(64,momentum=0.8),
nn.ReLU())
self.conv2=nn.Sequential(
nn.Conv2d(64,128,3,1,1),
nn.BatchNorm2d(128,momentum=0.8),
nn.ReLU())
self.conv3=nn.Sequential(
nn.Conv2d(128,64,3,1,1),
nn.BatchNorm2d(64,momentum=0.8),
nn.ReLU())
self.conv4=nn.Sequential(
nn.Conv2d(64,1,3,1,1),
nn.Tanh())
self.up2=nn.Sequential(
nn.Upsample(scale_factor=2,mode='nearest'))
def forward(self, noise, fake_label): # 64 100| 64|
gen_input = torch.cat((self.label_emb(fake_label), noise), dim=-1) # 64 110
x = self.fn1(gen_input) # 64 37*7*7
x = x.view([64,32,7,7]) # 64 32 7 7
x = self.conv1(x) # 64 64 7 7
x = self.up2(x) # 64 64 14 14
x = self.conv2(x) # 64 128 14 14
x = self.up2(x) # 64 128 28 28
x = self.conv3(x) # 64 64 28 28
x = self.conv4(x) # 64 1 28 28
return x
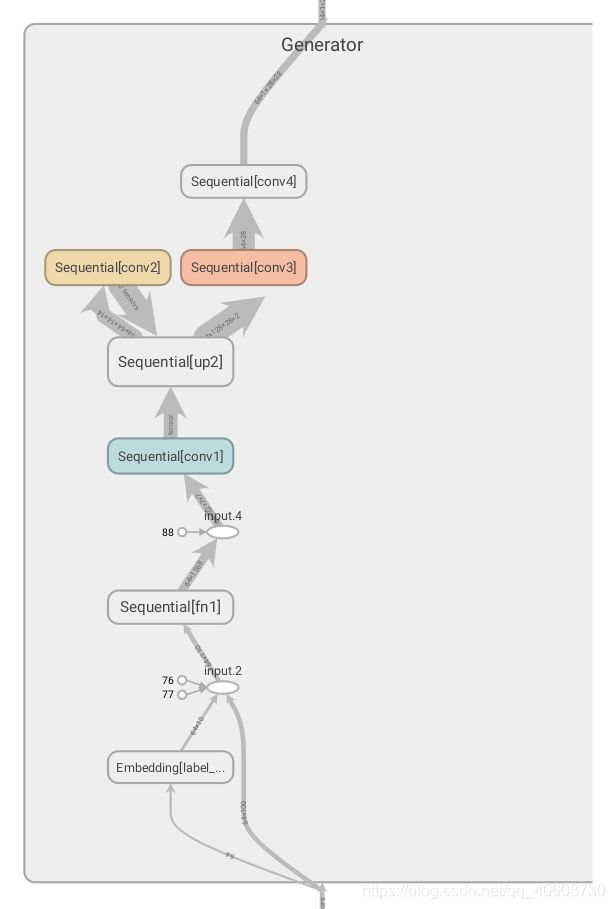
代码的右边有相应的tensor大小的注释,设置batchsize大小为64,noise大小为100维的正态分布,label维度是[1],大小为0-9的随机变量,把label经过Embedding层,变成维度是[10]的编码。最后的输出是[ 1 28 28 ]的单通道图片。
可视化结构如下:
discriminator网络结构部分
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.label_emb = nn.Embedding(10, 10)
self.conv1=nn.Sequential(
nn.Conv2d(1,32,3,2,1),
nn.BatchNorm2d(32, momentum=0.8),
nn.LeakyReLU(0.2, inplace=False))
self.conv2=nn.Sequential(
nn.Conv2d(32,64,3,2,1),
nn.BatchNorm2d(64, momentum=0.8),
nn.LeakyReLU(0.2))
self.pad=nn.Sequential(
nn.ZeroPad2d(padding=(1,0,1,0)))
self.conv3=nn.Sequential(
nn.Conv2d(64,128,3,2,1),
nn.BatchNorm2d(128, momentum=0.8),
nn.LeakyReLU(0.2))
self.avpool=nn.Sequential(
nn.AvgPool2d(4))
self.fn1=nn.Sequential(
nn.Linear(138,32),
nn.Dropout(0.4),
nn.LeakyReLU(0.2))
self.fn2=nn.Sequential(
nn.Linear(32,1),
nn.Sigmoid()
)
def forward(self, image, label):
x_1 = image # 64 10 28 28
x_2 = self.conv1(x_1) # 64 32 14 14 *
x_3 = self.conv2(x_2) # 64 64 7 7
x_4 = self.pad(x_3) # 64 64 8 8 **
x_5 = self.conv3(x_4) # 64 128 4 4 *
x_6 = self.avpool(x_5) # 64 128 1 1 **
x_7 = x_6.view(64, -1) # 64 128
x_7 = torch.cat((x_7, self.label_emb(label)), dim=-1) # 64 138
x_8 = self.fn1(x_7) # 64 10 **
x_9 = self.fn2(x_8) # 64 10 **
return x_9
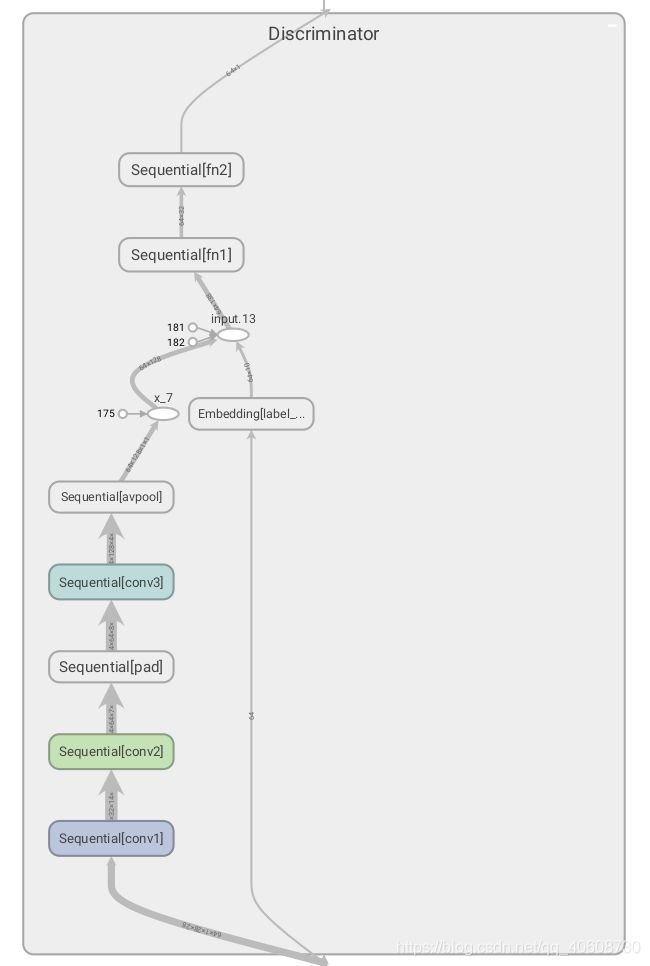
同理Discriminator的输入为图片和标签label,图片为[ 1 28 28]大小,label是[1]大小,在0-9之间,也将转化为[10]的tensor,在中间和image处理后的拼接,经过全连接层输出一个0-1之间的值,代表概率。
discriminator可视化:
train代码
import torch
from model import *
from data import *
import torchvision.utils as vutils
from torch.utils.data import DataLoader
import numpy as np
import os
import argparse
from torch.autograd import Variable
import time
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', default='mnist',help='cifar10 | lsun | mnist')
parser.add_argument('--dataroot', default='data/',help='path to data')
parser.add_argument('--batchSize', type=int, default=64, help='input batch size')
parser.add_argument('--imageSize', type=int, default=28, help='image size input')
parser.add_argument('--latentdim', type=int, default=100, help='size of latent vector')
parser.add_argument('--epoch', type=int, default=40, help='number of epoch')
parser.add_argument('--lrate', type=float, default=0.0002, help='learning rate')
parser.add_argument('--beta', type=float, default=0.5, help='beta for adam optimizer')
parser.add_argument('--beta1', type=float, default=0.999, help='beta1 for adam optimizer')
parser.add_argument('--output', default='bce_real_00015/', help='folder to output images')
parser.add_argument('--model_output', default='checkpoint/', help='folder to model checkpoints')
opt = parser.parse_args()
print(opt)
cuda = True if torch.cuda.is_available() else False
print('cuda:{}'.format(cuda))
os.makedirs(opt.output, exist_ok=True)
os.makedirs(opt.dataroot, exist_ok=True)
os.makedirs(opt.model_output, exist_ok=True)
data_sets = dataset(opt.dataset, opt.dataroot, opt.imageSize)
data_sets = DataLoader(data_sets, batch_size=opt.batchSize,shuffle=True)
generator = Generator()
gen_optimizer = torch.optim.Adam(generator.parameters(), lr=opt.lrate, betas=(opt.beta, opt.beta1))
discriminator = Discriminator()
dis_optimizer = torch.optim.Adam(discriminator.parameters(), lr=opt.lrate, betas=(opt.beta, opt.beta1))
loss = torch.nn.MSELoss()
label_tensor = torch.LongTensor
image_tensor = torch.FloatTensor
if cuda:
generator.cuda()
discriminator.cuda()
loss.cuda()
label_tensor = torch.cuda.LongTensor
image_tensor = torch.cuda.FloatTensor
print('model: gpu')
else:
print('model: cpu')
f = open('loss.txt', 'w')
a = np.arange(0,64,1)
a = a%10
imgs_label = torch.tensor(a).type(label_tensor)
for epoch in range(opt.epoch):
t0 = time.time()
for i,(imgs, labels) in enumerate(data_sets):
if imgs.shape[0] != 64:
continue
imgs = Variable(imgs.type(image_tensor))
labels = Variable(labels.type(label_tensor))
real_label = Variable(torch.full((64,1), 1.0).type(image_tensor))
fake_label = Variable(torch.full_like(real_label, 0.0).type(image_tensor))
noise = Variable(torch.randn([opt.batchSize, opt.latentdim]).type(image_tensor))
gen_labels = Variable(torch.randint(0,10,[opt.batchSize]).type(label_tensor))
gen_imgs = generator(noise, gen_labels)
real_validity = discriminator(imgs, labels)
dis_real_loss = loss(real_validity, real_label)
fake_validity = discriminator(gen_imgs.detach(), gen_labels)
dis_fake_loss = loss(fake_validity, fake_label)
dis_loss = 0.5*(dis_real_loss + dis_fake_loss)
# print(dis_loss)
dis_optimizer.zero_grad()
dis_loss.backward(retain_graph=True)
dis_optimizer.step()
for j in range(3):
noise = Variable(torch.randn([opt.batchSize, opt.latentdim]).type(image_tensor))
gen_labels = Variable(torch.randint(0,10,[opt.batchSize]).type(label_tensor))
gen_imgs = generator(noise, gen_labels)
validity = discriminator(gen_imgs, gen_labels)
gen_optimizer.zero_grad()
gen_loss = loss(validity, real_label)
# print(gen_loss)
gen_loss.backward(retain_graph=True)
gen_optimizer.step()
if i%500 == 0:
gen_img = generator(noise, imgs_label)
vutils.save_image(gen_img, '{}/gen_samples_epoch_{}_{}.png'.format(opt.output, epoch, i), normalize=True)
print("[Epoch: {}/{}] [D loss: {}] [G loss: {}] [time: {}]".format(epoch+1, opt.epoch, dis_loss.item(), gen_loss.item(), time.time()-t0))
f.write("[Epoch: {}/{}] [D loss: {}] [G loss: {}] [time: {}]\n".format(epoch+1, opt.epoch, dis_loss.item(), gen_loss.item(), time.time()-t0))
torch.save(generator.state_dict(), '{}/generator_epoch_{}.pth'.format(opt.model_output, epoch))
torch.save(discriminator.state_dict(), '{}/discriminator_epoch_{}.pth'.format(opt.model_output, epoch))
训练情况
训练的loss值基本不会变化,但是效果确实越来越好。
部分生成的手写体图片:


可以看出大部分生成的大部分手写体图片还是挺清晰的,而且样式也很多,但是生成的数字1就不太好,大部分的1都有一个或者两个点,可能是训练次数不够导致的,大概只需要训练40epoch就行,多训练一些可能效果更好。
遇到的问题
说一下遇到的问题,在刚开始训练的时候报错:
RuntimeError:one of the variables needed for gradient computation has been modified by an inplace operation
根据百度上的很多方法都不能解决,所以就找师兄帮忙,后面师兄发现问题是因为在训练模型的时候,我先训练的是generator,后面训练的discriminator,在训练generator和discriminator产生的loss应该分别计算不能放在一起,cgan的网络比较特殊,在训练generator的时候,也需要用到discriminator,在训练discriminator的时候也要用到generator,但是只调用一次generator,调用了三次discriminator,分别计算三个loss,应该先进行discriminator的更新,也比较符合一般流程和直觉。
在解决了这个问题之后,训练的时候我发现cgan退化成了gan,没法控制生成的数字体,然后就对模型的loss函数以及网络结构进行了重新设计,不再采用one-hot编码,在网络中加入Embedding层,改变cat位置,防止标签数据淹没在图片数据中。后面的网络在更新一次discriminator参数后,会更新三次generator,加快模型的训练,防止discriminator过强导致genera效果不好tor。后面也使用了tensorboardX实现了网络结构的可视化。
完整工程代码
代码链接: https://pan.baidu.com/s/1K2pfXYgLQPdSpc2MeOUFNw 密码: klga
工程说明:
checkpoint里面存放着三个训练好的gen模型,可以供test调用
data存放着mnist数据集
images存放训练过程中生成的图片,每个epoch保存两张,可在train中调整
log、test-output、runs是tensorboardX可视化生成的,在model_vis.py中,好像尝试了好几种方法
result是test生成的图片
data加载训练数据的,比较简单
model是模型的结构定义
model_vis是模型的可视化代码 最后在编译器下面的命令行运行 tensorboard --logdir runs 打开其中的本地网址即可
test是加载生成模型,通过对话框输入0-9之间的数字就可生成8*8的图片矩阵 存放到result中
train训练模型的代码
由于基础不好,所以代码可能会存在问题,还望在评论区指出或私信。