实验室非root权限配置服务器上自己版本的cuda
很多做ai和数据挖掘的组都需要用到比较新的pytorch;但是服务器上的默认版本并不那么先进,于是我们就需要自己配置cuda;后续可以在多个cuda 版本中进行切换。
我们实验室的配置ubuntu x86-64系统版本16.04 这个还是比较重要的,因为cuda 的一些版本如11.4要求服务器的系统版本要超过18.04,所以在选择cuda之前记得check系统的版本
可以使用lsb_release命令查看版本号
lsb_release -a
顺带一提 我使用的是MobaXterm SSh客户端,不过linux系统使用代码控制,就算你直接在shell里ssh所有的操作是一样的哈。苹果系统还没有使用过。
然后我们选择要安装的cuda 注意一定要按照复现文章需要的pytorch版本去安装对应的cuda;在安装之前 先看一下是不是支持。使用经典命令 nvidia-smi
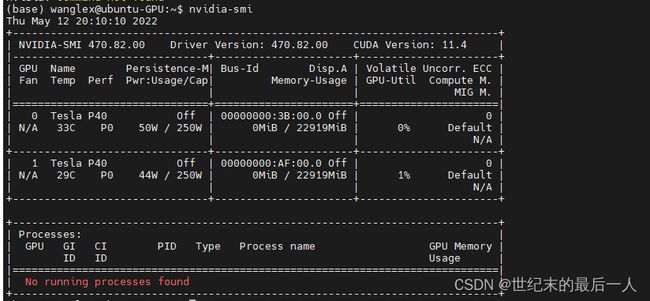
需要注意的是 这里的Driver Version是已经安装的gpu驱动版本。右边的CUDA Version是这个驱动最高支持的cuda 版本 但是需要注意的是,这个版本操作系统不一定对的上。而另一个查看cuda版本的命令 nvcc -V 看到的版本可能与smi显示的版本不一样,使用过程中的cuda版本以nvcc的为准哈,我们实验室默认安装的是10.2版本的cuda 如果没有特别的需要应该足够了,对ncvv显示的版本满意的同学们可以自行移步到安装pytorch进行阅读。
之后我们去英伟达的官网下载cuda toolkit;这里我们以cuda toolkit 11.3为例
cuda toolkit archive
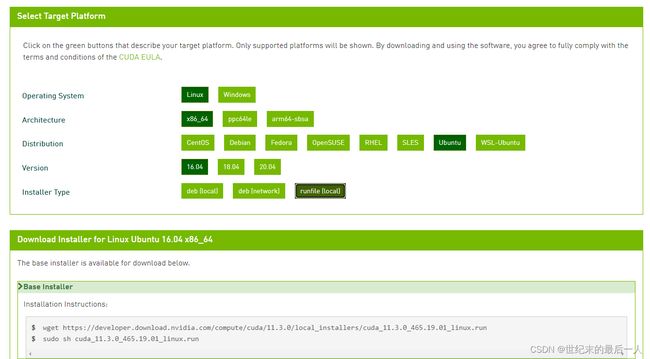
建议将文件下载到对应版本名称的文件文件夹中方便后续的操作
(base) wanglex@ubuntu-GPU:~$ mkdir cuda-11.3推荐使用runfile的形式,因为使用network要考虑到网络的连接问题,下到一半停住人麻了,可以在自己的电脑上先把.run文件下载下来;再传输到服务器上,从服务器上直接运行下面的两行代码也可以。
cd我们建立好的文件夹 .run文件应当也在这里 执行命令 不要加sudo 那是root的权限
sh cuda_11.3.0_465.19.01_linux.run
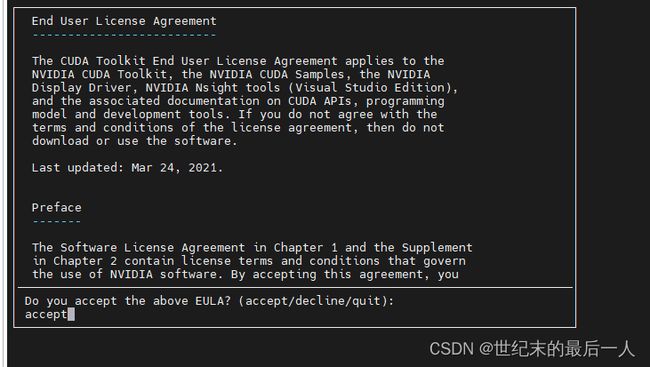
等待一会,输入accept 然后进入到选择界面 一般来说我们选择只安装cuda toolkit就可以
如果实验室没有装显卡驱动的话这里可以选择装驱动
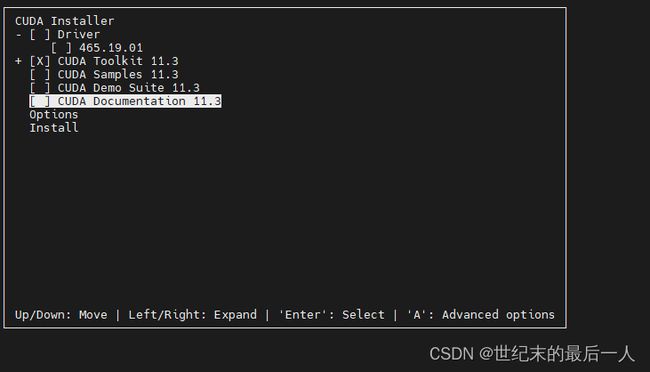
打×代表选择 下一步要选择Options>>Toolkit Options>>change Toolkit Install Path>>将这里的默认改为your_path否则我们是没有权限安装在它默认的位置的
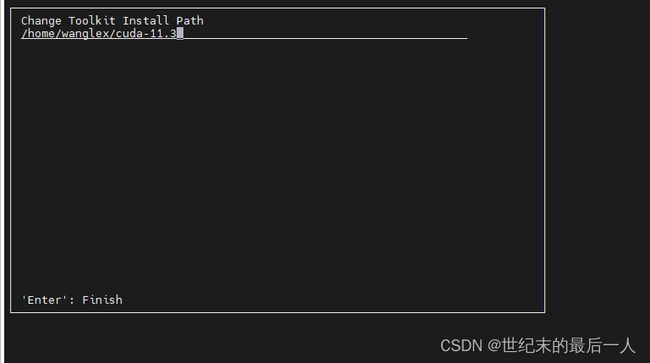
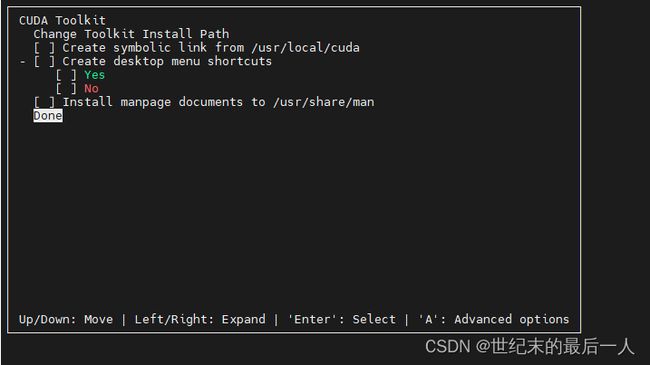
回到上一步 全部取消 选择Done 然后Install就可以了

安装完成 提示警告是因为没装驱动 不过本来实验室服务器的显卡就有驱动 这个无伤大雅
之后安装cudnn 从cudnn官网进行下载,11.3的话直接下载for CUDA 11.x 2021年六月的那个版本就好了,不知道是不是11.3别名11.x。

下载红色圆圈中的版本,下载完后把.tar文件也放到之前建立的文件夹中。使用linux命令解压缩
tar -xvf cudnn-11.3-linux-x64-v8.2.1.32.tgz #得到cudnn文件夹
然后需要将cudnn的一些文件复制到 cuda的路径当中 在终端中可以直接看到这两个文件,居然是隐藏的文件夹 是一个link的状态,就很有趣
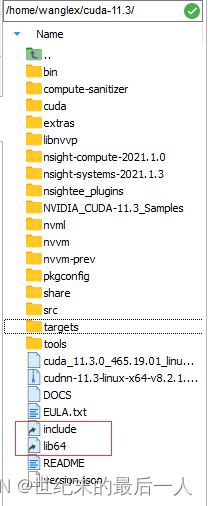
cp cuda/include/cudnn.h your_path/include/ #这里的your_path是安装cuda的绝对路径;默认为在这个文件夹下操作
cp cuda/lib64/libcudnn* your_path/lib64/
chmod a+r your_path/include/cudnn.h
chmod a+r your_path/lib64/libcudnn*
然后需要修改环境变量
vim ~/.bashrc打开环境变量设置文件,相信之前安装anaconda3的时候大家已经了解这个文件了,直接在文件最后添加三行代码
export PATH=your_path/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=your_path/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export CUDA_HOME=your_path #记得把所有的your_path换成你的安装绝对路径 例:/home/wanglex/cuda-11.3
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:your_path/lib64
export LD_LIBRARY_PATH=your_path/extras/CUPTI/lib64:$LD_LIBRARY_PATH然后:wq退出 偷偷说一句 使用ssh终端的话可以直接在你的用户文件夹下找到这个.bashrc文件然后直接在windows中修改,会自动和服务器上同步,很适合不咋玩linux的朋友。
source ~/.bashrc
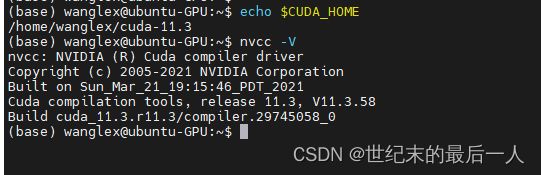
echo $CUDA_HOME
激活path 如果这个时候打印出我们安装的path就说明更改成功了 赶快ncvv -V看一下
然后安装pytorch
首先pytorch必须安装在环境当中,而我们默认大家是安装了anaconda3来管理环境的,于是我们使用conda新建一个虚拟环境,-n后面可以自己随便命名
conda create -n pytorch python=3.10
安装完成后激活该虚拟环境,conda activate pytorch
进入pytorch官网pytorch
选择自己要安装的版本 记得与操作系统、cuda版本对应
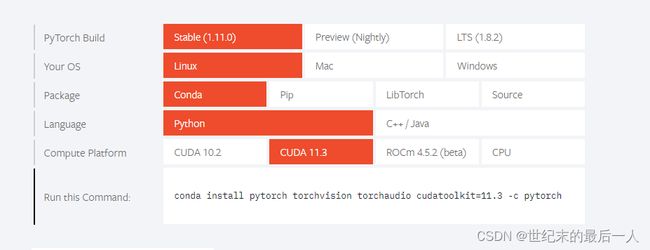
试了很多方法 感觉还是官网这个代码直接复制下来最靠谱,可能慢点,但是比较稳定。如果用清华的镜像的话,我推荐自己先下载下来放到服务器上解压缩。安装完成后,进入python环境,检查CUDA是否可用,调用
torch.cuda.is_available()返回True说明CUDA环境可用。

到这一步就配置完成了,之后运行代码的话我推荐在anaconda 的base环境中安装和配置jupyter notebook的借口 当然使用jupyter lab也行 jupyter的好处在于你在base里面配置好之后,所有的虚拟环境中只需要安装ipykernel就可以了
conda install ipykernel
python -m ipykernel install --user --name your_env --display-name "Python [conda env:your_env]"
#查看已有的kernel
jupyter kernelspec list
删除已有的kernel
jupyter kernelspec remove kernelname本文主要是我自己安装过程中的一些操作,其中参考了很多朋友的文章,也看了很多debug.log stackoverfollow上的问题等等,希望大家在安装环境的时候能够保持耐心,耐心的对待错误,积极运用谷歌 相信自己能解决问题,最后 实在不行咱可以摆烂使用默认环境嘛,要不把师兄配置好的conda env copy一下或者直接连接到自己的 jupyter上也是可以滴
参考:
实验室服务器(非root用户)深度学习环境配置 Miniconda3 + Cuda + Cudnn + pytorch-gpu_wgx96的博客-CSDN博客_miniconda安装cudnn
不用sudo权限安装cuda10.1_cxxx17的博客-CSDN博客_无sudo安装cuda