[论文笔记]Multixnet Multiclass multistage multimodal motion prediction
MultiXNet: Multiclass Multistage Multimodal Motion Prediction
MultiXNet 一种端到端的检测与运动预测模型。
如下图模型根据激光雷达和地图的输入数据,输出则是场景中其他参与者未来状态的多模态分布。
![[论文笔记]Multixnet Multiclass multistage multimodal motion prediction_第1张图片](http://img.e-com-net.com/image/info8/adb9a4f4fbb84a659877ce510a2ff04b.jpg)
本文的工作建立在IntentNet的基础上,对多种类型的交通参与者例如车辆、行人、自行车的联合检测和运动轨迹预测。
bird’s-eye view (BEV)和 Range view (RV)是对激光雷达点云数据的两种表示,具体的描述在上一篇论文笔记中提到。
BEV和RV融合方法虽然既保留了近距离目标的信息,也保留了远距离目标的信息,但代价是网络结构更加复杂和繁重。而本文的关注重点是BEV方法。
以前关于轨迹预测的研究大多集中在预测特定类型的道路行动者(如车辆或行人)的运动。然而,在公共道路上往往存在多种类型的道路参与者,为了安全驾驶,模型需要准确预测所有相关行为者的运动。此外,不同的行动者类型有不同的运动模式,例如,自行车手和行人的行为非常不同,因此对它们分别建模是很重要的。最近的一些论文使用递归方法解决了这一挑战,然而,与本文的端到端方法不同的是,那些方法没有使用原始传感器数据进行端到端的训练。
MultiXNet 结构
![[论文笔记]Multixnet Multiclass multistage multimodal motion prediction_第2张图片](http://img.e-com-net.com/image/info8/d278b0dfc28d4c56ba3f829b707a1b26.jpg)
MultiXNet 建立在IntentNet 的基础之上。
将点云转化到BEV视角中,每个时刻t的激光雷达扫描 S t S_t St的激光雷达点云表示为( x , y , z x, y, z x,y,z)。然后,在以SDV为中心的BEV图像中将扫描 S t S_t St立体像素化,体素大小分别为 △ L . △ W . △ V \triangle_L.\triangle_W.\triangle_V △L.△W.△V分别表示的x、y和z轴。并且将过去 T T T-1时刻的编码映射到同一个BEV框架中,并沿着通道维度堆叠特征映射。
接着将全局地图的信息编码在BEV视图中,地图编码说将行车路径、人行横道、车道和道路边界、十字路口、车道和停车场这些元素编码成二级制掩码,这样就产生了7个额外映射通道,
这些通道在与处理过的激光雷达通道堆叠之前,需要经过一些卷积层处理,作为网络其余部分的BEV输入,如IntentNet。
网络的输入:经过融合的BEV视角图像,该图像可以看作是SDV周围环境的自上而下的网格表示,每个网格单元包含沿通道尺寸编码的输入特征。
输入的图像经过多个2D卷积层,卷积层的术后出包含每个单元格位置的特征。
每个单元格共两组特征输出:目标检测以及运动预测。
用 c 0 = ( c ^ x 0 , c ^ y 0 ) c_0=(\hat{c}_{x0},\hat{c}_{y0}) c0=(c^x0,c^y0)表示目标 c 0 c_0 c0的中心位置, p ^ \hat{p} p^表示该点的概率,长宽分别用 l ^ , w ^ \hat{l},\hat{w} l^,w^表示, θ ^ 0 \hat{\theta}_0 θ^0表示目标相对于 x x x轴的朝向。
而 c h c_h ch即表示,在H个未来预测中的检测信息。而H个中心点集合即表示该目标在该时间段的轨迹。
损失:
损失包括所有BEV视角下的目标的检测损失和预测损失。
涉及到逐像素点的损失时,对于概率 p ^ \hat{p} p^的损失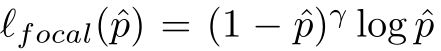
其中 λ = 2 \lambda=2 λ=2,对于存在ground-truth 的目标设置平滑- ℓ 1 \ell_1 ℓ1回归损失 ℓ 1 ( v ^ − v ) \ell_1(\hat{v}-v) ℓ1(v^−v)其中 v ^ \hat{v} v^为预测值, v v v为地面真值。
![[论文笔记]Multixnet Multiclass multistage multimodal motion prediction_第3张图片](http://img.e-com-net.com/image/info8/1fadfde8051b4a94b1df9057314bbbbf.jpg)
f g fg fg表示 foreground 前景单元格, b g bg bg表示background 背景单元格。 1 c 1_c 1c表示若条件c成立则等于1,否则为0。背景单元格的损失为:![]()
所有定义的最终的损失为![[论文笔记]Multixnet Multiclass multistage multimodal motion prediction_第4张图片](http://img.e-com-net.com/image/info8/d18b1974856e4195ac08fa66c638aa38.jpg)
λ \lambda λ为随时间的常数衰减因子,本文的实验中设置为0.97。
不确定性估计:本文将不确定性分解成横向不确定性along-track(AT)、纵向不确定性cross-track(CT)。将预测路径点 c ^ h \hat{c}_h c^h沿AT和CT方向投影,并假定这些方向的误差服从 Laplace(µ, b)分布,且横向和纵向的参数相互独立。接着使用KL散度来最小化损失。其中ground-truth服从
![]()
而预测服从![]()
![[论文笔记]Multixnet Multiclass multistage multimodal motion prediction_第5张图片](http://img.e-com-net.com/image/info8/e50cae860dc34d18801c14b52c6e922e.jpg)
类似地,可以计算 K L C T KL_{CT} KLCT
轨迹优化:采用第一步得到的中心点 c ^ 0 \hat{c}_0 c^0和航向 θ ^ 0 \hat{\theta}_0 θ^0
然后通过一个轻量级的CNN网络输入Rotated 特征图,接着对未来轨迹和不确定性进行最终预测,
第一阶段和第二阶段网络共同训练,第一阶段使用完全损失L,第二阶段只使用未来预测损失,其中第二阶段预测作为最终输出轨迹。第二阶段是完全可微分的,因此梯度从第二阶段流向第一阶段。
第一阶段和第二阶段的预测都可以在最终系统中使用。由于第二阶段的预测会导致额外的延迟成本,系统可以对一些参与者使用第一阶段的预测,而只对认为很重要的参与者运行第二阶段的轨迹预测。
而第二阶段的输出是 M条预测轨迹,并且对应输出每条轨迹的概率 p ^ m \hat{p}_m p^m。
实验:
数据集:nuScenes和TG4D
TG4D是一个专有的数据集,使用64线激光雷达以10Hz的采集频率捕获数据,前置摄像头捕捉图像在1920 × 1200分辨率与90°水平视野(FOV)。数据包含来自5500个不同场景的超过100万帧,3D边界**框标签最大范围为100米。
nuScenes是一个公开可用的数据集,使用32束激光雷达以20Hz的采集频率捕获数据,前置摄像头1600 × 900分辨率和水平FOV 70◦。这些数据包含1000个场景和39万个激光雷达扫描帧。
![[论文笔记]Multixnet Multiclass multistage multimodal motion prediction_第6张图片](http://img.e-com-net.com/image/info8/cb19fc5cc0734ce98c5a79f287492387.jpg)
MultiXNet与最先进的方法SpAGNN和IntentNet进行了比较,对比average precision (AP)平均精度,displacement error (DE)位移误差,以及3秒内的cross-track (CT)预测误差。
通过数据可以看出MultiXNet在三种道路参与者上都有很不错的表现。
![[论文笔记]Multixnet Multiclass multistage multimodal motion prediction_第7张图片](http://img.e-com-net.com/image/info8/ac1ecb5d40c1494eb59f5c830c4e6cfa.jpg)
上面行为IntentNet,下面行为MultiXNet;地面真实值用红色表示,预测值用蓝色表示,而彩色的椭圆表示对未来预测推断的不确定性的一个标准偏差 。
这两个模型都正确地检测和预测了大多数交通参与者的运动。如上图中间一辆大卡车在SDV右侧右转车道上的运动预测。IntentNet预测的是一条直线轨迹,而实际上在做一个转弯。而MultiXNet生成了多种模式,并为转弯和直线轨迹提供了合理的不确定性估计。
预测了大多数交通参与者的运动。如上图中间一辆大卡车在SDV右侧右转车道上的运动预测。IntentNet预测的是一条直线轨迹,而实际上在做一个转弯。而MultiXNet生成了多种模式,并为转弯和直线轨迹提供了合理的不确定性估计。
MultiXNet 是一个多级模型,首先推断目标检测和预测,然后使用第二级模型对这些预测进行优化,输出多个潜在的未来轨迹。