2022.03.09:seaborn.scatterplot()——绘制一个可能有几个语义分组的散点图
原文链接:scatterplot绘制一个可能有几个语义分组的散点图
seaborn.scatterplot(
x=None, y=None, - vectors or keys in data 作用:指定 x 轴和 y 轴上位置的变量。
hue=None, - vector or key in data 作用:将生成不同颜色的点的变量分组。
可以是分类或数字,尽管颜色映射在后一种情况下会有不同的行为。
style=None, - vector or key in data 作用:将生成具有不同标记的点的变量分组。
可以具有数字 dtype,但始终被视为分类类型。
size=None, - vector or key in data 作用:将生成不同大小的点的变量分组。
可以是分类型的,也可以是数值型的,尽管大小映射在后一种情况下会有不同的行为
data=None, - pandas.DataFrame, numpy.ndarray, mapping, or sequence
作用:输入数据结构。要么是可以分配给命名变量的长形式向量集合,
要么是将在内部重新形成的宽形式数据集合。
palette=None, - string, list, dict, or matplotlib.colors.Colormap
作用:用于在映射语义时选择要使用的颜色。
字符串值传递给 color _ palette ()。List 或 dict 值意味着绝对映射,
而 colormap 对象意味着数字 mappinghue
hue_order=None, - vector of strings 作用:指定 semantic.hue 的范畴级别的处理和绘图顺序
hue_norm=None, - tuple or matplotlib.colors.Normalize
作用:设置数据单元标准化范围的一对值,
或者将从数据单元映射到[0,1]间隔的对象。用法意味着数字映射。
sizes=None, - list, dict, or tuple 作用:一个对象,它决定使用时如何选择大小。
它始终可以是大小值的列表,或者是变量到大小的 dict 映射级别。
当是 numeric 时,它也可以是一个元组,指定要使用的最小和最大大小,
以便在这个范围内对其他值进行规范化
size_order=None, - list 作用:为变量级别的外观指定顺序,否则根据数据确定它们。
如果变量是 numeric.sizeize,则不相关
size_norm=None, - tuple or Normalize object 作用:当变量是 numeric.size 时,
用于缩放绘图对象的数据单元的规范化
markers=True, - boolean, list, or dictionary
作用:对象,确定如何为变量的不同级别绘制标记。设置为将使用默认标记,
或者可以将变量的标记列表或字典映射级别传递给标记。
设置为将绘制无标记线。在 matplotlib.styleTruestyleFalse 中指定标记
style_order=None, - list 作用:为变量级别的外观指定顺序,否则它们是根据数据确定的。
如果变量是 numeric.stylestyle,则无关
x_bins=None, y_bins=None, - lists or arrays or functions 作用:目前无法使用。
units=None, - vector or key in data 作用:分组变量识别取样单位。
使用时,将为每个单元绘制具有适当语义的单独行,但不添加图例条目。
当不需要精确的身份时,显示实验复制的分布是有用的。目前无法使用。
estimator=None, - name of pandas method or callable or None
作用:在同一级别上对变量的多个观察值进行聚合的方法。
如果,所有的观察将被绘制。目前无法使用。y x None
ci=95, - int or “sd” or None 作用:与估计量相加时要绘制的置信区间的大小。
“ sd”是指抽取数据的标准差。设置为将跳过引导。目前无法使用。None
n_boot=1000, - int 作用:用于计算置信区间的引导程序数目,目前无法使用。
alpha=None, - float 作用:点的比例不透明度。
x_jitter=None, y_jitter=None, - booleans or floats 作用:目前无法使用。
legend="auto", - “auto”, “brief”, “full”, or False
作用:如何画出图例。如果是“ brief”,
则数值和变量将用均匀间隔的值示例表示。如果“满了”,
每个小组都会在图例中有一个条目。如果“自动”,
选择之间的简短或完整的表示基于数量的水平。
如果,则不添加图例数据,也不会显示图例
ax=None, - matplotlib.axes.Axes 作用:为绘图预先存在轴,
否则,在内部调用 matplotlib.pyplot.gca ()。
**kwargs - key, value mappings
作用:其他关键字参数被传递给 matplotlib.Axes.scatter ()。
):
variables = _ScatterPlotter.get_semantics(locals())
p = _ScatterPlotter(
data=data, variables=variables,
x_bins=x_bins, y_bins=y_bins,
estimator=estimator, ci=ci, n_boot=n_boot,
alpha=alpha, x_jitter=x_jitter, y_jitter=y_jitter, legend=legend,
)
p.map_hue(palette=palette, order=hue_order, norm=hue_norm)
p.map_size(sizes=sizes, order=size_order, norm=size_norm)
p.map_style(markers=markers, order=style_order)
if ax is None:
ax = plt.gca()
if not p.has_xy_data:
return ax
p._attach(ax)
p.plot(ax, kwargs)
return ax -> matplotlib.axes.Axes 包含图标的 matplotlib 轴
上面不是可以运行的代码哟
Draw a scatter plot with possibility of several semantic groupings.
绘制一个可能有几个语义分组的散点图。
The relationship between and can be shown for different subsets of the data using the , , and parameters. These parameters control what visual semantics are used to identify the different subsets. It is possible to show up to three dimensions independently by using all three semantic types, but this style of plot can be hard to interpret and is often ineffective. Using redundant semantics (i.e. both and for the same variable) can be helpful for making graphics more accessible.xyhuesizestylehuestyle
可以使用、和参数为数据的不同子集显示和之间的关系。这些参数控制使用哪些可视化语义来识别不同的子集。通过使用所有三种语义类型可以独立地显示三个维度,但是这种情节风格很难解释,而且往往是无效的。使用冗余语义(即对于同一个变量同时使用和使用冗余语义)有助于使图形更加可访问
See the tutorial for more information.
更多信息请参见教程。
The default treatment of the (and to a lesser extent, ) semantic, if present, depends on whether the variable is inferred to represent “numeric” or “categorical” data. In particular, numeric variables are represented with a sequential colormap by default, and the legend entries show regular “ticks” with values that may or may not exist in the data. This behavior can be controlled through various parameters, as described and illustrated below.huesize
如果存在语义(在较小程度上也是)的默认处理方式,则取决于变量是否被推断为表示“数字”或“范畴”数据。特别是,默认情况下,数值变量使用顺序的彩色图表来表示,图例条目显示常规的“刻度”,其值可能存在于数据中,也可能不存在于数据中。这种行为可以通过各种参数来控制,如下面所描述和说明的那样
-
Parameters 参数
-
- x, y: vectors or keys in
-
Variables that specify positions on the x and y axes.
指定 x 轴和 y 轴上位置的变量。
hue : vector or key in -
Grouping variable that will produce points with different colors. Can be either categorical or numeric, although color mapping will behave differently in latter case.
将生成不同颜色的点的变量分组。可以是范畴或数字,尽管颜色映射在后一种情况下会有不同的行为。
size: vector or key in -
Grouping variable that will produce points with different sizes. Can be either categorical or numeric, although size mapping will behave differently in latter case.
将生成不同大小的点的变量分组。可以是范畴型的,也可以是数值型的,尽管大小映射在后一种情况下会有不同的行为。
style : vector or key in -
Grouping variable that will produce points with different markers. Can have a numeric dtype but will always be treated as categorical.
将生成具有不同标记的点的变量分组。可以具有数字 dtype,但始终被视为范畴类型。
data : -
Input data structure. Either a long-form collection of vectors that can be assigned to named variables or a wide-form dataset that will be internally reshaped.
输入数据结构。要么是可以分配给命名变量的长形式向量集合,要么是将在内部重新形成的宽形式数据集合。
palette: string, list, dict, or -
Method for choosing the colors to use when mapping the semantic. String values are passed to
color_palette(). List or dict values imply categorical mapping, while a colormap object implies numeric mapping.hue方法,用于在映射语义时选择要使用的颜色。字符串值传递给 color _ palette ()。List 或 dict 值意味着绝对映射,而 colormap 对象意味着数字 mappinghue
hue_order: vector of strings
-
Specify the order of processing and plotting for categorical levels of the semantic.
hue指定 semantic.hue 的范畴级别的处理和绘图顺序
hue_norm: tuple or -
Either a pair of values that set the normalization range in data units or an object that will map from data units into a [0, 1] interval. Usage implies numeric mapping.
设置数据单元标准化范围的一对值,或者将从数据单元映射到[0,1]间隔的对象。用法意味着数字映射。
sizes : list, dict, or tuple
-
An object that determines how sizes are chosen when is used. It can always be a list of size values or a dict mapping levels of the variable to sizes. When is numeric, it can also be a tuple specifying the minimum and maximum size to use such that other values are normalized within this range.
sizesizesize一个对象,它决定使用时如何选择大小。它始终可以是大小值的列表,或者是变量到大小的 dict 映射级别。当是 numeric 时,它也可以是一个元组,指定要使用的最小和最大大小,以便在这个范围内对其他值进行规范化
size_order : list
-
Specified order for appearance of the variable levels, otherwise they are determined from the data. Not relevant when the variable is numeric.
sizesize为变量级别的外观指定顺序,否则根据数据确定它们。如果变量是 numeric.sizeize,则不相关
size_norm : tuple or Normalize object
-
Normalization in data units for scaling plot objects when the variable is numeric.
size当变量是 numeric.size 时,用于缩放绘图对象的数据单元的规范化
markers : boolean, list, or dictionary
-
Object determining how to draw the markers for different levels of the variable. Setting to will use default markers, or you can pass a list of markers or a dictionary mapping levels of the variable to markers. Setting to will draw marker-less lines. Markers are specified as in matplotlib.
styleTruestyleFalse对象,确定如何为变量的不同级别绘制标记。设置为将使用默认标记,或者可以将变量的标记列表或字典映射级别传递给标记。设置为将绘制无标记线。在 matplotlib.styleTruestyleFalse 中指定标记
style_order : list
-
Specified order for appearance of the variable levels otherwise they are determined from the data. Not relevant when the variable is numeric.
stylestyle为变量级别的外观指定顺序,否则它们是根据数据确定的。如果变量是 numeric.stylestyle,则无关
{x,y}_bins : lists or arrays or functions
-
Currently non-functional.
目前无法使用。
units : vector or key in -
Grouping variable identifying sampling units. When used, a separate line will be drawn for each unit with appropriate semantics, but no legend entry will be added. Useful for showing distribution of experimental replicates when exact identities are not needed. Currently non-functional.
分组变量识别取样单位。使用时,将为每个单元绘制具有适当语义的单独行,但不添加图例条目。当不需要精确的身份时,显示实验复制的分布是有用的。目前无法使用。
estimator : name of pandas method or callable or None
-
Method for aggregating across multiple observations of the variable at the same level. If , all observations will be drawn. Currently non-functional.
yxNone在同一级别上对变量的多个观察值进行聚合的方法。如果,所有的观察将被绘制。目前无法使用。yxNone
ci: int or “sd” or None
-
Size of the confidence interval to draw when aggregating with an estimator. “sd” means to draw the standard deviation of the data. Setting to will skip bootstrapping. Currently non-functional.
None与估计量相加时要绘制的置信区间的大小。“ sd”是指抽取数据的标准差。设置为将跳过引导。目前无法使用。没有
n_boot: int
-
Number of bootstraps to use for computing the confidence interval. Currently non-functional.
用于计算置信区间的引导程序数目,目前无法使用。
alpha : float
-
Proportional opacity of the points.
点的比例不透明度。
{x,y}_jitter : booleans or floats
-
Currently non-functional.
目前无法使用。
legend : “auto”, “brief”, “full”, or False
-
How to draw the legend. If “brief”, numeric and variables will be represented with a sample of evenly spaced values. If “full”, every group will get an entry in the legend. If “auto”, choose between brief or full representation based on number of levels. If , no legend data is added and no legend is drawn.
huesizeFalse如何画出传奇。如果是“ brief”,则数值和变量将用均匀间隔的值示例表示。如果“满了”,每个小组都会在图例中有一个条目。如果“自动”,选择之间的简短或完整的表示基于数量的水平。如果,则不添加图例数据,也不会显示图例
ax : -
Pre-existing axes for the plot. Otherwise, call
matplotlib.pyplot.gca()internally.为绘图预先存在轴,否则,在内部调用 matplotlib.pyplot.gca ()。
**kwargs : key, value mappings
-
Other keyword arguments are passed down to
matplotlib.axes.Axes.scatter().其他关键字参数被传递给 matplotlib.Axes.scatter ()。
datadatadatadatapandas.DataFrame,numpy.ndarray, mapping, or sequencematplotlib.colors.Colormapmatplotlib.colors.Normalizedatamatplotlib.axes.Axes Returns 返回
-
-
-
The matplotlib axes containing the plot.
包含阴谋的 matplotlib 轴。
matplotlib.axes.Axes -
See also
参见
-
Plot data using lines.
使用线条绘制数据。
-
Plot a categorical scatter with jitter.
用抖动绘制分类散布图。
-
Plot a categorical scatter with non-overlapping points.
用不重叠的点绘制范畴散点图。
lineplot
stripplot
swarmplot
Examples
例子
These examples will use the “tips” dataset, which has a mixture of numeric and categorical variables:
这些例子将使用“ tips”数据集,该数据集包括数值变量和分类变量:
tips = sns.load_dataset("tips")
tips.head()
| total_bill 总账单 | tip 尖端 | sex 性 | smoker 吸烟者 | day 日 | time 时间 | size 大小 | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female 女性 | No 没有 | Sun 太阳 | Dinner 晚餐 | 2 |
| 1 | 10.34 | 1.66 | Male 男性 | No 没有 | Sun 太阳 | Dinner 晚餐 | 3 |
| 2 | 21.01 | 3.50 | Male 男性 | No 没有 | Sun 太阳 | Dinner 晚餐 | 3 |
| 3 | 23.68 | 3.31 | Male 男性 | No 没有 | Sun 太阳 | Dinner 晚餐 | 2 |
| 4 | 24.59 | 3.61 | Female 女性 | No 没有 | Sun 太阳 | Dinner 晚餐 | 4 |
Passing long-form data and assigning and will draw a scatter plot between two variables:xy
传递长形式的数据并赋值,然后在两个变量之间绘制散点图: xy
sns.scatterplot(data=tips, x="total_bill", y="tip")

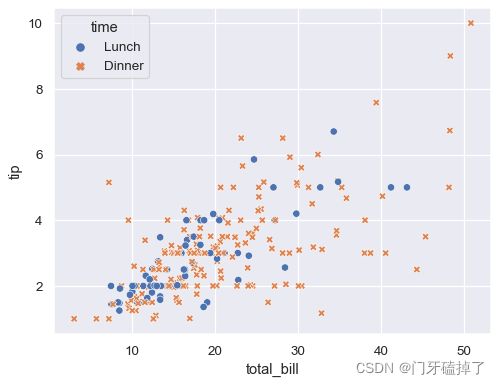
Assigning a variable to will map its levels to the color of the points:hue
分配一个变量将映射其水平的颜色点: 色调
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time")

Assigning the same variable to will also vary the markers and create a more accessible plot:style
分配相同的变量也会改变标记,并创建一个更容易理解的情节: 样式
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time", style="time")
Assigning and to different variables will vary colors and markers independently:huestyle
分配和不同的变量将独立地改变颜色和标记: huestyle
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="day", style="time")

If the variable assigned to is numeric, the semantic mapping will be quantitative and use a different default palette:hue
如果分配给的变量是 numeric,语义映射将是定量的,并使用不同的默认面板: hue
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="size")

Pass the name of a categorical palette or explicit colors (as a Python list of dictionary) to force categorical mapping of the variable:hue
传递范畴调色板或显式颜色的名称(作为 Python 字典列表)以强制对变量进行范畴映射: hue
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="size", palette="deep")

If there are a large number of unique numeric values, the legend will show a representative, evenly-spaced set:
如果存在大量唯一的数值,图例将显示一个具有代表性的均匀间距集:
tip_rate = tips.eval("tip / total_bill").rename("tip_rate")
sns.scatterplot(data=tips, x="total_bill", y="tip", hue=tip_rate)

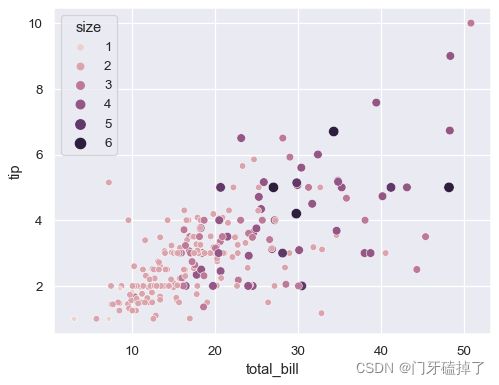
A numeric variable can also be assigned to to apply a semantic mapping to the areas of the points:size
还可以指定一个数值变量来对点的区域应用语义映射: size
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="size", size="size")
Control the range of marker areas with , and set to force every unique value to appear in the legend:sizeslengend="full"
控制标记区域的范围,并设置为强制每个唯一值出现在图例中: sizeslengend = “ full”
sns.scatterplot(
data=tips, x="total_bill", y="tip", hue="size", size="size",
sizes=(20, 200), legend="full"
)

Pass a tuple of values or a matplotlib.colors.Normalize object to to control the quantitative hue mapping:hue_norm
传递一组值或 matplotlib.color.Normalize 对象来控制定量色调映射: hue _ norm
sns.scatterplot(
data=tips, x="total_bill", y="tip", hue="size", size="size",
sizes=(20, 200), hue_norm=(0, 7), legend="full"
)

Control the specific markers used to map the variable by passing a Python list or dictionary of marker codes:style
通过传递 Python 列表或标记代码字典: style 来控制用于映射变量的特定标记
markers = {"Lunch": "s", "Dinner": "X"}
sns.scatterplot(data=tips, x="total_bill", y="tip", style="time", markers=markers)

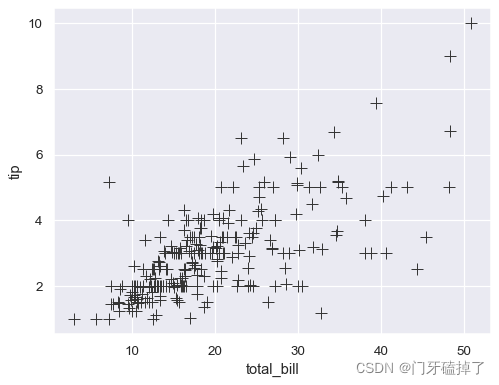
Additional keyword arguments are passed to matplotlib.axes.Axes.scatter(), allowing you to directly set the attributes of the plot that are not semantically mapped:
将其他关键字参数传递给 matplotlib.axes。5. Axes.scatter () ,允许你直接设置不是语义映射的图的属性:
sns.scatterplot(data=tips, x="total_bill", y="tip", s=100, color=".2", marker="+")
The previous examples used a long-form dataset. When working with wide-form data, each column will be plotted against its index using both and mapping:huestyle
前面的示例使用了长形式的数据集。在处理广泛形式的数据时,将使用 huestyle 和 mapping: 将每一列与其索引绘制在一起
index = pd.date_range("1 1 2000", periods=100, freq="m", name="date")
data = np.random.randn(100, 4).cumsum(axis=0)
wide_df = pd.DataFrame(data, index, ["a", "b", "c", "d"])
sns.scatterplot(data=wide_df)

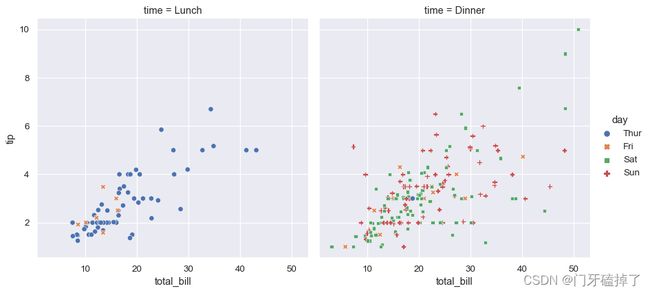
Use relplot() to combine scatterplot() and FacetGrid. This allows grouping within additional categorical variables, and plotting them across multiple subplots.
使用 relplot ()结合 scatterplot ()和 FacetGrid。这允许在附加的范畴变量中进行分组,并在多个次要图中绘制它们。
Using relplot() is safer than using FacetGrid directly, as it ensures synchronization of the semantic mappings across facets.
使用 relplot ()比直接使用 FacetGrid 更安全,因为它确保了跨 facet 的语义映射的同步。
sns.relplot(
data=tips, x="total_bill", y="tip",
col="time", hue="day", style="day",
kind="scatter"
)