(pytorch)如何用yolov3训练自己的数据集(亲测有效)
鉴于网络上有很多用yolov3算法训练自己的数据集的教程都失效的情况下,我决定自己写一篇。在最新版的pytorch环境下训练。
首先要准备好我们自己的数据集(也就是图片),然后用我们的标注工具进行标注
1、标注工具(labelimg)
Labelimg是一款开源的数据标注工具,可以标注三种格式。
1 VOC标签格式,保存为xml文件。
2 yolo标签格式,保存为txt文件。
3 createML标签格式,保存为json格式。
下载就不多说了,用命令行或者官网下载都可以(我是用命令行安装的)
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple2、标注前的准备
首先这里需要准备我们需要打标注的数据集。这里我建议新建一个名为VOC2007的文件夹,里面创建一个名为JPEGImages的文件夹存放我们需要打标签的图片文件;再创建一个名为Annotations存放标注的标签文件;最后创建一个名为 predefined_classes.txt 的txt文件来存放所要标注的类别名称。
VOC2007的目录结构为:
├── VOC2007
│├── JPEGImages 存放需要打标签的图片文件
│├── Annotations 存放标注的标签文件
│├── predefined_classes.txt 定义自己要标注的所有类别(这个文件可有可无,但是在我们定义类别比较多的时候,最好有这个创建一个这样的txt文件来存放类别)
2、对数据集进行标注
首先在JPEGImages这个文件夹放置待标注的图片,这里是六类图片,这里我用的飞机蒙皮的缺陷图片。分别是fadongjihuahen、mengpiwuzi、biaomianyiwu、mengpikongdong、mengpiliewen、mengpidiaoqi。
然后再 predefined_classes.txt 这个txt文档里面输入定义的类别种类;如下图所示。

然后从终端进入到刚刚创建的这个VOC2007路径

输入如下的命令打开labelimg。这个命令的意思是打开labelimg工具;打开JPEGImage文件夹,初始化predefined_classes.txt里面定义的类。
labelimg JPEGImages predefined_classes.txt运行如上的命令就会打开这个工具;如下。
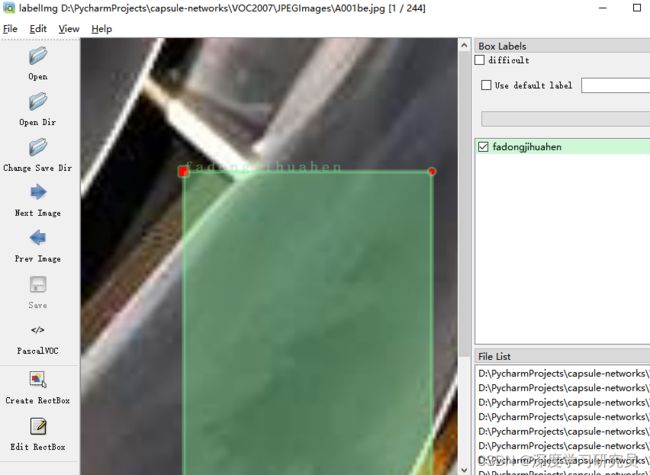
大家自行查找一下这个软件怎么用,不细讲了
标签打完以后可以去Annotations 文件下看到标签文件已经保存在这个目录下。
3、安装yolov3
下面就要下载编译yolov3了,yolov3的版本很多,我推荐大家下载我这个版本,其他版本会出现各种问题
git clone https://github.com/ultralytics/yolov3.git
cd yolov3
pip install -r requirements.txt这几行代码就把yolov3和相关依赖下载好了。
由github上的官方教程可以知道训练coco128数据用的下面这行代码
python train.py --img 640 --batch 16 --epochs 5 --data coco128.yaml --weights yolov3.pt那么这样我们只需要把data后面的 coco128.yaml换成我们自己的文件格式就行了。
coco128.yaml里的内容如下
# download command/URL (optional)
download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../coco128/images/train2017/
val: ../coco128/images/train2017/
# number of classes
nc: 80
# class names
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']大家看到train和val是两个路径,这两个路径就是我们的数据集相关文件,download不用管。
下面的class names就是我们的类别列表,所以我们只需要创建我们自己的train和val路径就行了
下面讲怎么创建
4、创建自定义数据集相关配置文件
在VOC2007下建一个ImageSet文件夹,再在里面建一个main文件夹
- VOC2007
- Annotations (标签XML文件,用对应的图片处理工具人工生成的)
- ImageSets (生成的方法是用sh或者MATLAB语言生成)
- Main
- test.txt
- train.txt
- trainval.txt
- val.txt
- JPEGImages(原始文件)
- labels (xml文件对应的txt文件)如上图
通过labelimg软件主要构造好JPEGImages和Annotations文件夹中内容,Main文件夹中的txt文件可以通过以下python脚本生成:
import os
import random
trainval_percent = 0.9
train_percent = 1
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()接下来生成labels文件夹中的txt文件,voc_label.py文件具体内容如下:
# -*- coding: utf-8 -*-
"""
Created on Tue Oct 2 11:42:13 2018
将本文件放到VOC2007的同级目录下,然后就可以直接运行
需要修改的地方:
1. sets中替换为自己的数据集
2. classes中替换为自己的类别
3. 将本文件放到VOC2007目录下
4. 直接开始运行
"""
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')] #替换为自己的数据集
classes = ["person"] #修改为自己的类别
#进行归一化
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOC%s/Annotations/%s.xml'%(year, image_id)) #将数据集放于当前目录下
out_file = open('VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOC%s/labels/'%(year)):
os.makedirs('VOC%s/labels/'%(year))
image_ids = open('VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('VOC%s/JPEGImages/%s.jpg\n'%(year, image_id))
convert_annotation(year, image_id)
list_file.close()voc_labels.py生成的txt文件需要重新组织一下,划分成训练集和验证集
后面我们来讲用什么代码划分
我们继续在VOC2007文件夹中新建文件夹
- VOC2007
- Annotations (标签XML文件,用对应的labelimg生成的)
- ImageSets (生成的方法是用python生成)
- Main
- test.txt
- train.txt
- trainval.txt
- val.txt
- JPEGImages(原始文件)
- labels (xml文件对应的txt文件)
- Allempty (用来存放不合要求的图片)
- images (用于pytorch版本的图片保存)
- train2014
- 001.jpg
- 002.jpg
- val2014
- 100.jpg
- 101.jpg
- label (用于pytorch版本的标签保存)
- train2014
- 001.txt
- 002.txt
- val2014
- 100.txt
- 101.txt之前我们生成的labels里的txt文件后面通过代码划分生成的文件就在label文件夹里
我们创建python脚本文件make_for_yolov3_torch.py放在VOC2007所在的同级文件夹下
import os, shutil
"""
需要满足以下条件:
1. 在JPEGImages中准备好图片
2. 在labels中准备好labels
3. 创建好如下所示的文件目录:
- images
- train2014
- val2014
- labels(由于voc格式中有labels文件夹,所以重命名为label)
- train2014
- val2014
"""
def make_for_torch_yolov3(dir_image,
dir_label,
dir1_train,
dir1_val,
dir2_train,
dir2_val,
main_trainval,
main_test):
if not os.path.exists(dir1_train):
os.mkdir(dir1_train)
if not os.path.exists(dir1_val):
os.mkdir(dir1_val)
if not os.path.exists(dir2_train):
os.mkdir(dir2_train)
if not os.path.exists(dir2_val):
os.mkdir(dir2_val)
with open(main_trainval, "r") as f1:
for line in f1:
print(line[:-1])
# print(os.path.join(dir_image, line[:-1]+".jpg"), os.path.join(dir1_train, line[:-1]+".jpg"))
shutil.copy(os.path.join(dir_image, line[:-1]+".jpg"),
os.path.join(dir1_train, line[:-1]+".jpg"))
shutil.copy(os.path.join(dir_label, line[:-1]+".txt"),
os.path.join(dir2_train, line[:-1]+".txt"))
with open(main_test, "r") as f2:
for line in f2:
print(line[:-1])
shutil.copy(os.path.join(dir_image, line[:-1]+".jpg"),
os.path.join(dir1_val, line[:-1]+".jpg"))
shutil.copy(os.path.join(dir_label, line[:-1]+".txt"),
os.path.join(dir2_val, line[:-1]+".txt"))
if __name__ == "__main__":
'''
https://github.com/ultralytics/yolov3
这个pytorch版本的数据集组织
- images
- train2014 # dir1_train
- val2014 # dir1_val
- labels
- train2014 # dir2_train
- val2014 # dir2_val
trainval.txt, test.txt 是由create_main.py构建的
'''
dir_image = r"C:\Users\pprp\Desktop\VOCdevkit\VOC2007\JPEGImages"
dir_label = r"C:\Users\pprp\Desktop\VOCdevkit\VOC2007\labels"
dir1_train = r"C:\Users\pprp\Desktop\VOCdevkit\VOC2007\images\train2014"
dir1_val = r"C:\Users\pprp\Desktop\VOCdevkit\VOC2007\images\val2014"
dir2_train = r"C:\Users\pprp\Desktop\VOCdevkit\VOC2007\label\train2014"
dir2_val = r"C:\Users\pprp\Desktop\VOCdevkit\VOC2007\label\val2014"
main_trainval = r"C:\Users\pprp\Desktop\VOCdevkit\VOC2007\ImageSets\Main\trainval.txt"
main_test = r"C:\Users\pprp\Desktop\VOCdevkit\VOC2007\ImageSets\Main\test.txt"
make_for_torch_yolov3(dir_image,
dir_label,
dir1_train,
dir1_val,
dir2_train,
dir2_val,
main_trainval,
main_test)代码中的文件路径需要自行修改,然后我们把images文件下的train2014文件夹和val2014文件夹复制到yolov3下的data-images下,把label下的train2014和val2014放到yolov3的data-labels下,如下图
然后在yolov3的cfg文件夹下创建自定义配置文件,暂且命名为yolov3.yaml,仿造coco128.yaml里的格式,把tran和val路径改成我们的路径就行了,把下载地址注释掉,类别改成我们自己的类别就行了。
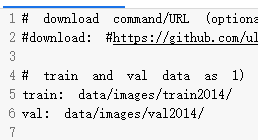
到底为止,符合yolov3格式数据集构造完毕,可以用官方代码进行训练了
python train.py --img 640 --batch 16 --epochs 50 --data cfg/yolov3.yaml --weights yolov3.pt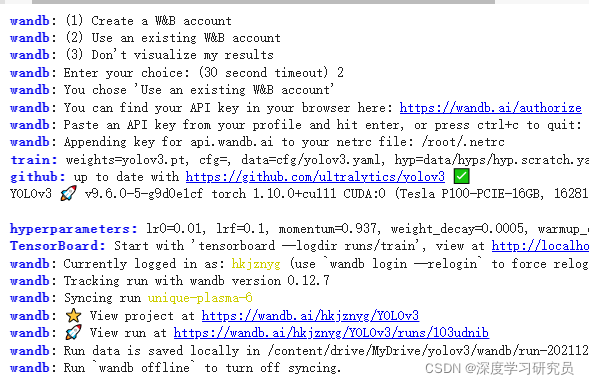
训练之前可能要安装个wandb
pip install wandb然后大家可以注册一个wandb账号,这是个可视化网站,可以很方便看到自己的训练效果。很好用
Weights & Biases – Developer tools for ML