B站:以SLO为核心的可用性观测与质量运营

UGeek大咖说是优维科技为技术爱好者研讨云原生技术演进趋势而创办的系列活动,邀请一线互联网大厂的核心骨干主讲,分享原厂实践。本年度主题为可观测,我们希望通过一场场有趣、有料、有深度的活动,让运维圈的小伙伴聚集在一起,深度交流与学习。
11月24日,UGeek大咖说第十一期在感恩节的祝福声中落幕。从2022年春节首期至今,观众已经陪伴了我们度过了11期直播活动,在此由衷向所有的新老观众与公众号读者们表示感谢。
本期活动,我们邀请到哔哩哔哩的在线SRE负责人——武安闯老师,为我们讲解以SLO为核心的可用性观测与质量运营。武老师从可用性对象多、可用性度量难、运营需求场景多这三个维度为我们分析了可用性困局的破解方法,告诉我们如何抽丝剥茧度量服务的可用性,如何开展报警治理,如何第一时间发现线上问题。此外还给大家分享了Google SRE中最核心的SLO工程方法论及SLO实施经验,在失败与持续不断解决不同问题的过程中,让我们学习了应该如何从SLO出发来做报警治理与质量运营。
以下为直播活动精华内容摘选,供大家阅读参考。
可用性困局

我们在工作中可能会遇到这些问题,比如在谈论一个可能性的时候,可能性的对象是很多的,我们并不知道可能性是在说谁。举个例子,线上运行的一个服务或者应用,这个应用的可能性有多少?你甚至也可以说这个应用的下面的某一个接口的可能性用多少才能真正触达到用户?所以可能性度量也是很难的,包括对这些可能性的数据标准和建模也很难。因为要算可能性,首先就要知道什么是不可用。
B站的实践过程
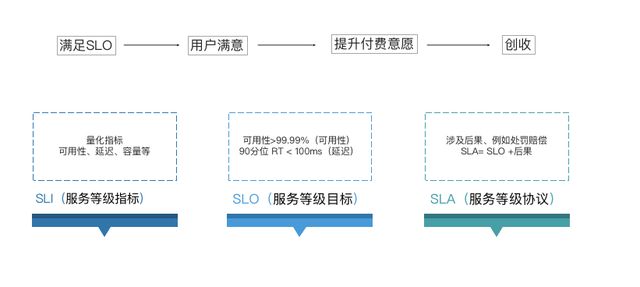
我们提到常见的两个概念:SLO和SLI。SLI是一个服务等级的指标,这是做SLO第一步要做的,去量化服务的一些指标。
服务水平目标(SLO)指定了服务可靠性的目标水平。SLO是做出以数据为依据的可靠性决策的关键,它们是SRE实践的核心。
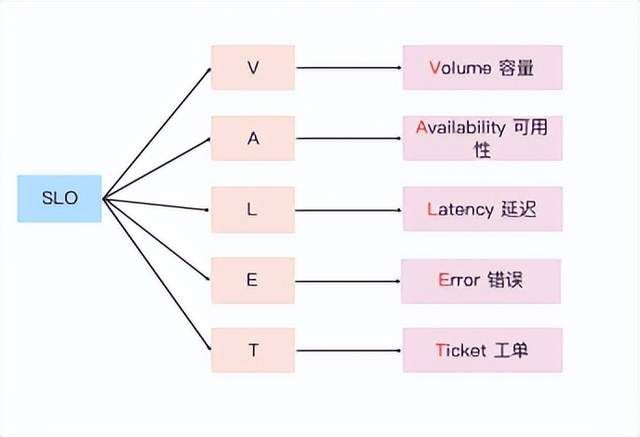
l 工程师稀缺,时间投入到重要服务的核心问题上
l SLO是做出工作优先级排序和可靠性相关工作的关键
l 工作按照SLO来开展,确保SLO是合理的
l 没有SLO,就没有SRE
Google实施SLO的理想流程

首先是要做SLI指标的选择,SLI的指标定义好了之后你就可以做SLO的定义了。比如前面算出的可能性,可以设一个目标,年可能性、季度可能性要达到多少。设定好之后就可以报警了。SLO里面可用性的报警是准确率最高的。有了SLI的度量和SLO之后就可以做错误预算了,比如全年可能性是9999,那么一年之内允许多少的不可用时间,这些错误预算你是可以拿到的,甚至说你在窗口再小一点,你一天可以允许多少的错误请求。
如果在一个实验窗户里面你的错误预算消耗殆尽,那我们可以制定一个错误预算的执行策略,比如说我们跟研发沟通,我们接下来的变更呢要专注于可靠性的问题,我们生产的变更尽量去冻结。同时需要一个仪表盘和报表来展示度量出的SLI的一些趋势,包括错误量,包括报表等等做一些可视化的运营,最终是要持续去改进SLO的。
SLO的第一次尝试
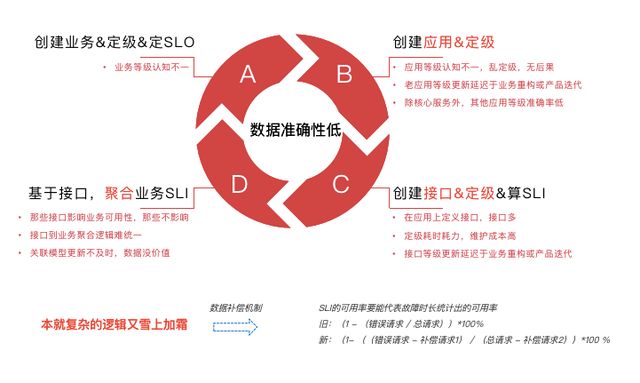
失败总结:
·业务分级模型过于理想,定级成本高
·业务SLI关联关系、API 元信息更新不及时,数据准确率低
·无法通过负载均衡一条Metrics计算到的可用性来覆盖业务全部故障场景
·部分部门的业务只提供内网服务,不过负载均衡,导致没有SLI数据
·SLI数据好像除了当报表外,也没什么价值
·SLO是可靠性决策的关键因素,但不是非有不可
·SLO的价值绝对不是报表,而是及时报警,发现影响·SLI指标的异常
·错误预算策略是诗与远方
·SLI度量的核心是业务功能和应用,而不是聚合业务SLI
……
再次出发
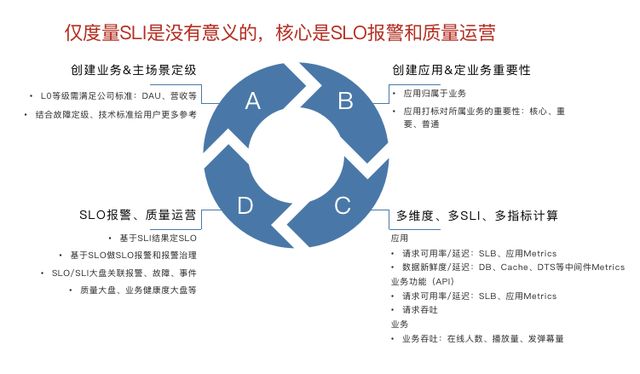
可能是业务的分级模型太过于理想了,经济成本非常高,业务下哪些接口的信息是对业务人员有影响的,哪些是没有影响的。原先性更新的,我们也更新得不及时,最终就导致我们整个数据准确率比较低。SLO是通过负载均衡来度量的,但是我们实践时发现无法通过负载均衡层面的metrics来覆盖全部的故障场景。而且有些部门的业务只提供了内网服务,没有过负载均衡,它通过服务直接发现了。那这种服务就没有SLI指标和数据了,这种服务就度量不出来。而且我们当时的数据呢除了当代表之外,也没有什么价值,对。我们后来在思考中,我发现SLO是可靠性角色的关键因素,但它并不是非有不可,因为在没有SLO工程之前,我们线上的一些五年型治理专项改进也是可以做的。比如说我们基于故障来做。所以SLO它一定有自己存在的价值,但并不是可以解决所有的问题,我们必须合理去认识它。
现场答疑互动·问答
怎么管理Slo,和哪些功能联动?
需要建设一个SLO的平台,去做一些原数据的管理。怎么联动,要做质量运营。正常运营的情况下,我们要扩展SLO的场景,我们不能把数据只放在平台。那么压测的时候我们什么情况下来熔断一个压测任务呢?就是SLO的指标产生影响的时候,同时可以把SLO数据去运营到常见的研发平台,研发最常用的平台,或者SLI的平台也可以把数据放过去,让用户每时每刻都能看到自己的。服务的可用率的情况,同时在他变更的时候也能通过这种可用率的实施的指标,让他知道这种指标对自己的服务产生价值。
SLO指标如何选取,如何度量?
那么对于可用率来讲,我们核心是要前提识别错误,我们内部也有这种需求,有一个业务不标准,线上多次出现问题。可能第一时间提到一个,就是说。呃,把这个业务部门的SLO给定一下,或者把SLO报警给覆盖一下。那么其实大家都忽略一个前提是说你要做SLO报警,首先要知道错误,所以你首先应该是做错误的标准化和错误的识别。有了错误的识别之后,你才能去度量服务的可用率。可用率出来之后,有多个维度去度量,因为很难通过一个指标去发现现行服务所有的故障,最后可能你是通过多维度的指标去发现,线上的所有故障来提升SLO的准确率和对故障召回率,除了可用率之外,B站的实践的时候还做了数据延迟的一个数据指标,度量,因为我们的场景对存储依赖特别重。你们的业务相关里面我们并没有用到很多消息对列啊,包括说我们的双环中也是从看到这边同步DB,服务如果有一个请求,Severs直接就写缓存,然后直接写DB,在这种材料里面,可能延迟关注的就是DB的主从同步延迟就行了,里面没有下一对列,也没有看到任务。所以你这种时候数据延迟举报就不是很关注。最后实际的去多量指标的时候,我们还加了业务维度的吞吐指标。因为业务冲突,指标一旦产生,比如下跌20%或者下跌30%。那一定是线上一个重大问题,然种业务冲突指标在很多公司,他们核心盯的一个业务大屏,可能就是盯业务,打盘指标。他们可能并不会很关心技术层面的指标。
如何以用户体验纬度看待服务可用性?
其实我们定SLO也就是为了体现出用户的可能性的一个受损的情况,那但实际上SLO报警出来的时候不代表用户一定受损了。因为我们前面有提到我们很多服务,它是由内网的一些调用,它并不会直接触达用户,那在上游比方说网关或者slb我可能有一些降级的策略,那么最终用户层面是无损的。但是呢SLO报警依然可以发现你的服务在线上产生了异常,你的服务产生异常之后呢?不一定对用户产生异常了,这个两个不影响,但最好你肯定在线上来讲,你有一个要跟进的case,或者要有一个跟进的一个事项,那么在用户维度,可以通过用户反馈这个指标来去衡量这个事故的严重程度,像我们内部在做一些报警的时候。我们也很关注用户反馈,那么对于一个业务模块,如果用户反馈数量超过几个,我们就认为就是线上目前可能产生一些紧急事故了,那么对用户反馈数量呢?如果只有一两个,那可能是线上某一个bug或者一个比较特殊产品才会出发的。我们都会去跟进。所以最终情况下,就是SLO的指标,让你发现所有的问题,让你可以去做一些复盘跟进,包括一些五年性的治理,但不代表是影响用户了。影响用户这个维度呢,除了SLO之外,我们可以加上用户反馈的指标,那对于b站场景我们肯定有客服团队,我们就可以很适时的拿到用户反馈的指标。那么在其他公司或者团队可能也是类似的,如果你的产品是有很多的c端用户,一般都会有客户团队,我们可以考虑去拿一个实时的用户反馈指标。
怎么从指标到定义完全不可用?
(实际的情况总是有些好用,有些不好用)
指标到定义完全不可用,实际对实际我们服务出现故障的时候很少说是百分百不可用了,一般就是说错误率10%或者20%,30%,那么这种你通过SLO的度量是可以发现的。比如说你对SLI的数据做一个一分钟的聚合,一分钟里面基于错误总请求去算一下这一分钟的一个可用率情况怎么样?那你的SLI的指标是可以清晰体现出服务这种有没有完全不可用的场景的。服务的可用不可用,给最终用户有没有受损,其实也是不是强相关的,但是你服务SLI指标产生异常一定代表你服务出问题了一定是需要SRE和研发去跟进的。
SLO指标设计时候依赖哪些采集工具?除了Prometheus或者网关accesslog,还有什么别的最佳实践?
基本上都是各个公司在用的,一个监控工具啊。
我们大量的数据也是普罗米修斯里面过来的,数据一般就是技术指标。那么网关层面,我们其实不是去解析access log的,access log成本太高了,网关层面我们是也是用的网关层面,也可以暴露一些出来。然后到朋友里面我们统一取过来。那么前面有提到我们也收集了一些业务层面的一些吞吐指标,那么这些指标因为是业务买点上报的,所以这种指标我们是没办法存破,我们的渠道,我们是存我们的数的平台,然后跟他们之间去做一些数据的订阅和采集。所以我们现在数指标采集两部分,一部分是业务指标,存我们内部其他的平台,另一种就是技术指标,我们目前统一从普罗米修斯来取。我们不会把指标分的特别散,比如说网关也从用日志来取,然后那网关如果从用日志来取,那应用理论上也可以取日志,对吧?因为应用也有日志,我们一般就通过match就好了。
中小型公司如何开展,重点先从哪些开始?
SLO的开展跟公司规模没关系,而是跟你现在的基础设施或者微服务的基础能力有关,具备这个能力了,只要你这些指标是可度量的,那么你就都可以去做SLO的实践,这个时间的核心侧重点就是把错误度量出来,然后去做报警,来发现现象问题,以及你把这些指标度量出来之后,做一些可视化的报表。把这种东西运营到上层平台里面去,这套模型其实不管你公司规模怎么样,主要是看你现在整个微服务的体系,或者你计价的体系有没有这些指标可以让你采集的,我举个例子,你现在内部覆盖均衡,都没有暴露任何指标,你想做这个事情就很难,比如说我们应用侧也没有任何指标报出来,根本拿不到错误,做这个东西也就很难,这个时候你可能只能基于日志来做,如果你服务的日志打的很非标,乱打,没有任何标准,也没有错误出来,那你也做不了这个东西的度量,所以它的核心前提是。你的基础设施或者你的微服务体系欺诈体系具备这个能力了,具备这个基础就可以做。