Multi-window back-projection residual networks for reconstructing COVID-19 CT super-resolution imag
Multi-window back-projection residual networks for reconstructing COVID-19 CT super-resolution images
用于重建COVID-19 CT超分辨率图像的多窗口反向投影残差网络
ABSTRACT
- Background and objective:With the increasing problem of coronavirus disease 2019 (COVID-19) in the world, improving the image resolution of COVID-19 computed tomography (CT) becomes a very important
task. At present, single-image super-resolution (SISR) models based on convolutional neural networks (CNN) generally have problems such as the loss of high-frequency information and the large size of the model due to the deep network structure.
随着2019冠状病毒病(COVID-19)在世界范围内的问题日益严重,提高COVID-19计算机断层扫描(CT)的图像分辨率成为一项非常重要的任务。目前,基于卷积神经网络(CNN)的单幅图像超分辨率(SISR)模型由于网络结构较深,普遍存在高频信息丢失、模型规模较大等问题。 - Methods:In this work, we propose an optimization model based on multi-window back-projection residual network (MWSR), which outperforms most of the state-of-the-art methods. Firstly, we use multi-window to refine the same feature map at the same time to obtain richer high/low frequency information, and fuse and filter out the features needed by the deep network. Then, we develop a back-projection network based on the dilated convolution, using up-projection and down-projection modules to extract
image features. Finally, we merge several repeated and continuous residual modules with global features, merge the information flow through the network, and input them to the reconstruction module.
在本研究中,我们提出了一种基于多窗口后向投影残差网络(MWSR)的优化模型,该模型的性能优于目前大多数最先进的方法。首先,我们利用多窗口同时对同一特征图进行细化,以获得更丰富的高频/低频信息,并对深度网络所需的特征进行融合和过滤。然后,我们开发了一个基于扩张卷积的反投影网络,利用向上投影和向下投影模块提取图像特征。最后,我们将几个具有全局特征的重复的、连续的残差模块进行合并,将通过网络的信息流进行合并,并输入到重构模块中。 - Results: The proposed method shows the superiority over the state-of-the-art methods on the benchmark dataset, and generates clear COVID-19 CT super-resolution images.
在基准数据集上,该方法优于目前最先进的方法,能够生成清晰的COVID-19 CT超分辨率图像 - Conclusion: Both subjective visual effects and objective evaluation indicators are improved, and the model specifications are optimized. Therefore, the MWSR method can improve the clarity of CT images
of COVID-19 and effectively assist the diagnosis and quantitative assessment of COVID-19.
改进了主观视觉效果和客观评价指标,优化了模型规范。因此,MWSR方法可以提高COVID-19 CT图像的清晰度,有效辅助COVID-19的诊断和定量评估。
1. Introduction
After the coronavirus invaded the lungs, it would diffuse along alveolar pores, which would lead to alveolar swelling, exudation of alveolar septum fluids, and thickening of alveolar septum, etc. All these will increase the CT number of the lungs, namely the lungs will become white. There is no exudation of granulocytes in viral infections, the alveoli are clean, and the air is still inside, so there is often a ground glass shadow without a substantial white mass change. Therefore, super-resolution (SR) reconstruction technology is urgently needed to improve the resolution of COVID-CT as an important basis for the diagnosis of COVID-19.
冠状病毒侵入肺部后,沿肺泡孔扩散,导致肺泡肿胀、肺泡间隔液渗出、肺泡间隔增厚等。所有这些都会增加肺部的CT数目,即肺部会变成白色。病毒感染时无粒细胞渗出,肺泡干净,空气仍在里面,故常有磨玻璃影,无实质白色肿块改变。因此迫切需要超分辨率(SR)重建技术来提高COVID-CT的分辨率,作为诊断COVID-19的重要依据。
The main contributions of this paper are described as follows:
- Expand the network structure horizontally to avoid the vertical depth of the network. The extended network uses the multi- window up-projection and down-projection residual module (MWUD) to extract the key information of the same feature map at the same time from the shallow network, to obtain more complete high/low frequency information in the original image as soon as possible.
横向扩展网络结构,避免垂直深度。扩展网络采用多窗口上投影和下投影残差模块(MWUD)从浅层网络中同时提取同一特征图的关键信息,以尽快获得原始图像中更完整的高低频信息。 - The residual network extracts features. The dilated convolution is used to expand the receptive field, and the image high/low frequency information is extracted layer by layer through 3 repetitive and continuous residual modules.
残差网络提取特征。采用扩张卷积扩展接收野,通过3个重复连续的残差模块逐层提取图像的高低频信息。
2. Deep neural network for super-resolution reconstruction
In recent years, methods based on deep learning have become the most active research direction in the field of SR. Since the SR- CNN model proposed by Dong C et al. successfully used the convolutional neural network technology to reconstruct and generate higher-definition images, such methods have come to the fore. It uses many external HR images to construct a learning library, and generates a neural network model after training. In the process of LR image reconstruction, the prior knowledge obtained by the model is introduced to obtain the high-frequency detail infor-
mation of the image, to achieve the excellent image reconstruction effect.
近年来,基于深度学习的方法已经成为最活跃的研究方向领域的老自SRCNN盾C等人提出的模型成功应用卷积神经网络技术来重建和件吃更为清晰的图像,这种方法脱颖而出。利用大量外部HR图像构建学习库,训练后生成神经网络模型。在LR图像重建过程中,引入模型获得的先验知识,获取图像的高频细节信息,达到了良好的图像重建效果。
After that, FSRCNN [10] , ESPCN [1 1] and other models have made some improvements on each part of the network structure based on SRCNN.
之后,FSRCNN、ESPCN等模型在SRCNN的基础上对网络结构的各个部分进行了改进。
due to the increase of channel number, filter size, step size and other super parameters, it is very difficult to design a reasonable network structure. Then, He et al.proposed the ResNet to solve the above problems. Although it is suitable for image classification, its residual idea and strategy of repeated stack- ing modules can be applied to all computer vision tasks. In addition, the ResNet also proved that shortcut connection and recursive
convolution can effectively reduce the burden of neural network carrying a lot of key information.
由于信道数、滤波器尺寸、步长等超参数的增加,很难设计出合理的网络结构。然后,He等人提出了ResNet来解决上述问题。虽然它适用于图像分类,但其重复叠加模块的残差思想和策略可以应用于所有的计算机视觉任务。此外,ResNet还证明了快捷连接和递归卷积可以有效地减轻神经网络承载大量关键信息的负担。
3. Multi-window back-projection residual networks
To solve the problems of incomplete extraction of feature information in the original input image and large model scale due to the deep longitudinal structure of the network, we propose a multi-window back-projection residual networks for reconstructing COVID-19 CT super-resolution images. The model mainly includes multi-window up-projection and down-projection residual module (MWUD) and 3 Residual block modules (RB), MWUD is
up-projection and down-projection residual module, RB is residual block module. as shown in Fig. 2 .
为了解决由于网络纵向结构较深导致原始输入图像特征信息提取不完全和模型尺度较大的问题,我们提出了一种用于COVID-19 CT超分辨率图像重建的多窗口背投影残差网络。该模型主要包括多窗口上投影和下投影残差模块(MWUD)和3个残差块模块(RB),其中MWUD为上投影和下投影残差模块,RB为残差块模块。如图2所示。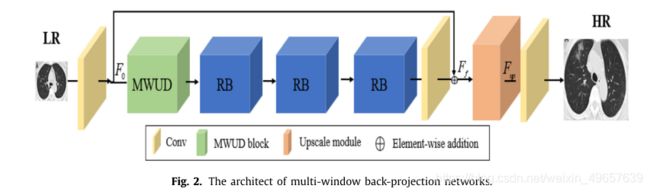
In the deep network, it is divided into three types. Fig. 3 is (a) Predefined upsampling, (b) Single upsampling, © Progressive upsampling. In this article, we proposed the multi-window up-projection and down-projection residual module, as shown in Fig. 3 (d).
在深层网络中,它分为三种类型。图3是(a)预先定义的上采样,(b)单个上采样,©渐进上采样。本文提出了多窗口上投影和下投影残差模块,如图3 (d)所示。
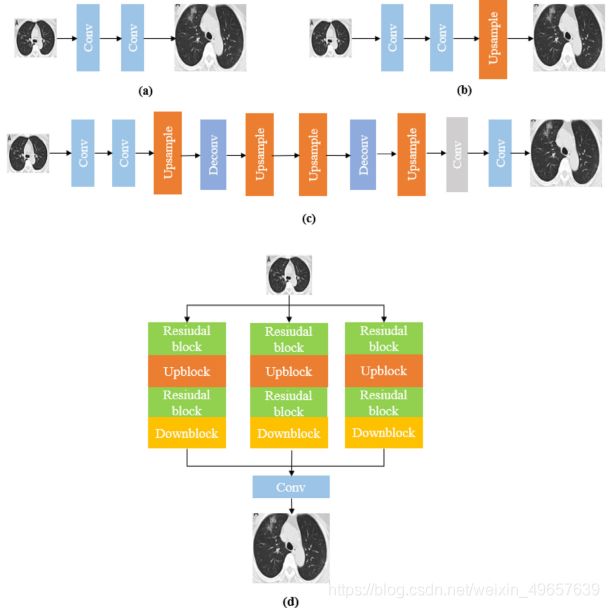
The main purpose of multi-window up-projection and down-projection residual module (MWUD) is to explore the interdependence between LR and HR as an efficient iterative process. In addition, the MWUD module can provide more information for each bottom-up or top-down mapping and increase the flow of information.
多窗口上投影和下投影残差模块(MWUD)的主要目的是作为一种有效的迭代过程来探索LR和HR之间的相互依赖性。此外,MWUD模块可以为每个自底向上或自顶向下的映射提供更多的信息,增加信息流。
As shown in Fig. 3 (d), multi-window back-projection network consists of three up-projection and down-projection residual modules, each MWUD module consists of an up-projection (upblock), a down-projection (downblock), and two residual block modules.
如图3 (d)所示,多窗口背投影网络由三个上投影和下投影残差模组组成,每个MWUD模组由一个上投影(upblock)、一个下投影(downblock)和两个残差块模组组成。
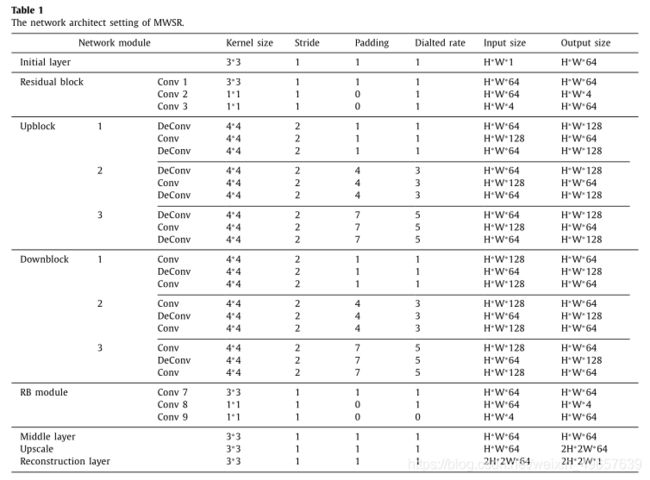
In this paper, we introduce dilated convolution into the up projection and down-projection of MWUD module without losing the resolution and expanding the receptive field. Furthermore, 128 feature fusing layer and 64 Feature Fusing Layers (FFL) are introduced in up-projection model and down-projection model to reduce the MWSR network parameters, the parameters are shown in Table 1 . In the MWUD module, different division rates lead to different re-ceptive fields, which can capture multi-scale context information of COVID-19 CT images.
本文在不丧失分辨率和扩大接收野的前提下,将扩张卷积引入MWUD模的上投影和下投影。在上投影模型和下投影模型中分别引入128个特征融合层和64个特征融合层,以减少多wsr网络参数,参数如表1所示。在MWUD模块中,不同的分割率导致不同的感知域,能够获取COVID-19 CT图像的多尺度上下文信息。
The up-projection model maps each other step by step between the LR feature map and the HR feature map, and the down-projection model maps each other step by step between the HR feature map and the LR feature map, as shown in Fig. 4 . Accordingly, back-projection extracts image features by up-projection and down-projection. It can be understood that the network is a process of continuous self-correction. Its purpose is to avoid the single-step nonlinear mapping error when only up-sampling at the end of the network, and to improve the super-resolution performance.
向上投影模型在LR特征图和HR特征图之间逐步映射,向下投影模型在HR特征图和LR特征图之间逐步映射,如图4所示。反过来,反投影通过向上投影和向下投影来提取图像特征。可以理解,网络是一个不断自我修正的过程。其目的是为了避免仅在网络端进行上采样时产生的单步非线性映射误差,提高超分辨率性能.
4. Experiments and analysis
The public datasets BSD500 and T91were used in the experiment, and the two training sets have a total of 591 images. Due to the depth model usually benefits from large amounts of data, 591 images are not sufficient to push the model to its best performance . Thus, to make full use of the dataset, we use the MATLAB to expand the data of the BSD500 and T91 training set images by two methods, namely scaling and rotation. Each image was scaled by the ratios of 0.7, 0.8, and 0.9. Additionally, each image w as respectively rotated by 90 °, 180 °, and 270 °, and 9456 images were finally obtained. In addition, a lot of tests and comparisons have been made on the public benchmark datasets Set5 , Set14, and Urban100.
实验使用公共数据集BSD500和T91,两个训练集共有591幅图像。由于深度模型通常受益于大量的数据,591张图像不足以推动模型的最佳性能。因此,为了充分利用数据集,我们利用MATLAB对BSD500和T91训练集图像的数据进行了缩放和旋转两种方法的扩展。每个图像年龄按0.7、0.8和0.9的比例缩放。将每幅图像分别旋转90°、180°、270°,最终得到9456幅图像。此外,对公共基准数据集Set5、Set14和Urban100进行了大量的测试和比较。
We compare our model with the 9 state-of-the-art SR methods, including Bicubic, A +, SCN, SRCNN, FSRCNN , VDSR , DRCN, LapSRN, and DRRN. The specific implementation of these models has been officially published on the Internet; thus, these algorithms can be executed on the same test dataset for fair comparison. In addition, the quality of the generated super-resolution image is evaluated by two common objective evaluation indexes: peak signal to noise ratio (PSNR) and structural similarity (SSIM) .
我们将我们的模型与包括双立方、A +、SCN、SRCNN、FSRCNN、VDSR、DRCN、LapSRN和DRRN在内的9种最先进的SR - meth- ods进行了比较。这些模型的具体实施已经在互联网上正式发布;因此,这些算法可以在相同的测试数据集上执行,以便进行公平比较。另外,用峰值信噪比(PSNR)和结构相似度(SSIM)这两个常用的客观评价指标来评价生成的超分辨率图像的质量。
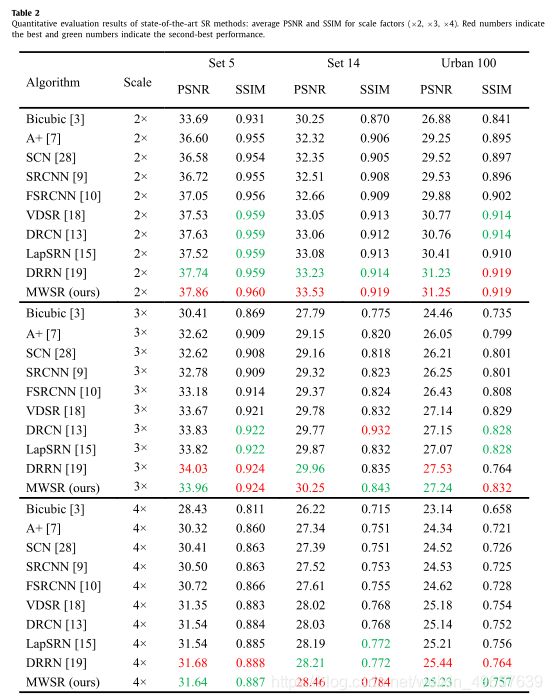
We show the quantitative results in the Table 2 , it shows the evaluation results of 10 kinds of super-resolution algorithms, which are magnified by 2 ×, 3 × and 4 × respectively on three public test datasets. As can see that the performance of the MWSR method outperforms other state-of-the art methods in different multiples and different test datasets, further, the MWSR method successfully reconstruct the detailed textures and improves the image perception quality, and realizes the model lightweight and operation efficiency optimization.
我们在表2中展示了定量结果,它展示了10种超分辨率算法的评价结果,在三个公开测试数据集上分别放大了2 ×、3 ×和4 ×。可以看出,该方法在不同的倍数和不同的测试数据集上的性能优于其他最先进的方法,并且成功地重建了细节纹理,提高了图像感知质量,实现了模型轻量化和操作效率的优化。
5. Conclusion
In order to solve the problems of incomplete extraction of feature information and large scale of COVID-19 CT original input image due to the deep vertical structure of the network, we propose a super-resolution model based on multi-window back-projection residual networks (MWSR).
为了解决因网络纵向结构较深而导致的COVID-19 CT原始输入图像特征信息提取不完全和图像规模大的问题,提出了一种基于多窗口背投影残差网络(MWSR)的超分辨率模型。
The experimental results show that MWSR can reconstruct COVID-19 texture features more effectively than other popular models. For future implementation, we will focus on optimizing the up-sampling operation of the high-resolution reconstruction part, and calculate the more realistic and effective mapping relationship between the low-resolution feature space
and the high-resolution feature space.
实验结果表明,与其他流行的纹理模型相比,MWSR能够更有效地重构COVID-19纹理特征。在未来的实现中,我们将重点优化高分辨率重建部分的上采样操作,计算出更真实有效的低分辨率特征空间与高分辨率特征空间的映射关系。