机器学习笔记-AdaBoost理论及实现
AdaBoost简介
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
理论参考:https://blog.csdn.net/qq_38890412/article/details/120360354
AdaBoost实现
导包
import numpy as np
import matplotlib.pyplot as plt
from sklearn import tree
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
from sklearn.metrics import classification_report
plt.style.use('ggplot')
随机生成数据并画图
#生成2维正太分布,生成的数据按分位数分成两类,500个样本,2个样本特征
x1,y1=make_gaussian_quantiles(n_samples=500,n_features=2,n_classes=2)
#生成2维正太分布,生成的数据按分位数分成两类,400个样本,2个样本特征,均值都为3
x2,y2=make_gaussian_quantiles(mean=(3,3),n_samples=500,n_features=2,n_classes=2)
#将两组数据合成一组数据
x_data=np.concatenate((x1,x2))
y_data=np.concatenate((y1,-y2+1))
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()
数据散点图如下所示:

建立决策树模型并训练模型画出散点图和计算精度
#决策树模型
model=tree.DecisionTreeClassifier(max_depth=3)
#输入数据建立模型
model.fit(x_data,y_data)
#获取数据所在的范围
x_min,x_max=x_data[:,0].min()-1,x_data[:,0].max()+1
y_min,y_max=x_data[:,1].min()-1,x_data[:,1].max()+1
#生成网络矩阵
xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02),np.arange(y_min,y_max,0.02))
z=model.predict(np.c_[xx.ravel(),yy.ravel()])
z=z.reshape(xx.shape)
#等高线图
cs=plt.contourf(xx,yy,z)
#样本散点图
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()
#模型准确率
model.score(x_data,y_data)
决策树模型训练结果如下所示:

训练精度为:0.788
建立AdaBoost模型,并计算训练精度
#Adaboost模型,重点放在分类错误的样本上边,使分类错误的样本的准确率得到提升
model=AdaBoostClassifier(DecisionTreeClassifier(max_depth=3),n_estimators=10)
#训练模型
model.fit(x_data,y_data)
#获取数据所在的范围
x_min,x_max=x_data[:,0].min()-1,x_data[:,0].max()+1
y_min,y_max=x_data[:,1].min()-1,x_data[:,1].max()+1
#生成网络矩阵
xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02),np.arange(y_min,y_max,0.02))
z=model.predict(np.c_[xx.ravel(),yy.ravel()])
z=z.reshape(xx.shape)
#等高线图
cs=plt.contourf(xx,yy,z)
#样本散点图
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()
#模型准确率
model.score(x_data,y_data)
Adaboost训练结果如下图所示:
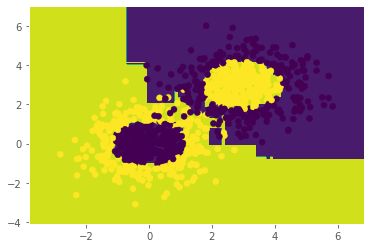
训练精度为0.981