Kyuubi1.4.0集成spark3.2.0
目录
一、Kyuubi1.4.0集成spark3.2.0单机部署
二、Kyuubi1.4.0集群模式部署
三、Kyuubi问题
四、参数解释
五、Kyuubi Metrics
六、参考网址
一、Kyuubi1.4.0集成spark3.2.0单机部署
1、编译spark3.2.0基于hadoop3.0.0-cdh6.0.1、hive2.1.1
dev/make-distribution.sh --name 3.0.0-cdh6.0.1 --tgz -Phive-2.1 -Phive-thriftserver -Pyarn -Phadoop-3.0 -Dhadoop.version=3.0.0-cdh6.0.12、官网下载kyuubi1.4.0,已经编译完整
https://downloads.apache.org/incubator/kyuubi/kyuubi-1.4.0-incubating/
3、部署方式看《kyuubi1.2.0基于spark3.1.2单机模式部署》
二、Kyuubi1.4.0集群模式部署
1、Kyuubi、Spark集群设置成集群模式
kyuubi1.3.2之后的版本支持以下参数,可以使kyuubi服务在含有kerberos的ZK中创建目录
# 启动的spark引擎以yarn-cluster模式跑
spark.master=yarn
spark.submit.deployMode=cluster
spark.driver.memory=20g
spark.hadoop.fs.hdfs.impl.disable.cache=true
spark.executor.heartbeatInterval=30s
spark.yarn.jars=hdfs://nameservice3/user/spark3_2_0/*.jar
......
#spark.shuffle.useOldFetchProtocol=true
spark.shuffle.useOldFetchProtocol=true
spark.shuffle.service.enabled=true
spark.dynamicAllocation.enabled=true
#spark.dynamicAllocation.shuffleTracking.enabled=true
spark.dynamicAllocation.minExecutors=1
spark.dynamicAllocation.maxExecutors=1000
spark.dynamicAllocation.initialExecutors=1
spark.dynamicAllocation.schedulerBacklogTimeout=1s
spark.dynamicAllocation.executorIdleTimeout=60s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=5s
spark.driver.maxResultSize=5g
......
kyuubi.ha.enabled=true
kyuubi.ha.zookeeper.auth.type=KERBEROS
kyuubi.ha.zookeeper.auth.keytab=keytab文件
kyuubi.ha.zookeeper.auth.principal=keytab文件内容
kyuubi.ha.zookeeper.namespace=kyuubi
kyuubi.ha.zookeeper.quorum=zk集群地址
kyuubi.ha.zookeeper.client.port=21812、集群模式,连接Kyuubi
shell直接连接
beeline -u "jdbc:hive2://134.84.68.201:2181,134.84.68.202:2181,134.84.68.203:2181/aiops;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi;principal=hive/[email protected]"脚本连接
vim beelineKyuubi.sh
#!/bin/bash
# zookeeper连接
ZOOKEEPER_QUORUM=134.84.68.201:2181,134.84.68.202:2181,134.84.68.203:2181
# spark配置
SPARKI_CONFS="spark.executor.instances=10;spark.executor.memory=3g"
# kyuubi配置,USER|CONNECTION
KYUUBI_CONFS=""$SPARKI_CONFS;kyuubi.engine.share.level=CONNECTION"
# jdbc连接
JBDC_URL="jdbc:hive2://${ZOOKEEPER_QUORUM}/aiops;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi?$KYUUBI_CONFS;principal=hive/[email protected]"
# 使用beeline连接
beeline -u "$JBDC_URL"结论:kyuubi集群模式即实现了kyuubi的HA,又实现了负载均衡的效果。
三、Kyuubi问题
1、Spark 3 修改了 shuffle 通信协议,在与 CDH 2.4 版本的 ESS 交互时,需要设置 spark.shuffle.useOldFetchProtocol=true,否则可能报如下错误:
[SPARK-29435] Spark 3 doesn't work with older shuffle service,IllegalArgumentException: Unexpected message type: 。 2、kyuubi1.3.2之前,Kyuubi如果想部署为集群模式,ZK集群必须不含有Kerberos认证。
3、集群如果没有启用Kerberos认证,Kyuubi进程启动用户必须在HDFS设置为了proxyuser,否则连接时报如下异常:
22/05/31 14:47:30 ERROR SparkContext: Error initializing SparkContext.
org.apache.hadoop.security.authorize.AuthorizationException: User: root is not allowed to impersonate hive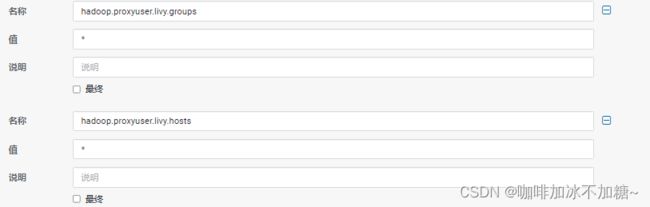
四、参数解释
kyuubi.engine.share.level=CONNECTION|USER|SERVER
#CONNECTION场景比较特殊,Driver是不会被复用的,所以对于CONNECTION模式,engine.idle.timeout是没有意义的,只要连接断开Driver就会立刻退出。
kyuubi.session.engine.idle.timeout=PT1H
#引擎TTL。约定Driver闲置了多长时间以后才释放五、Kyuubi Metrics
Kyuubi Server 中也定义了一些监控指标,用于监控 Kyuubi Server 的运行状况,支持了很多的 Reporter,包括 Prometheus,后续工作需要将指标投递到 Prometheus 中,对 Kyuubi 服务进行监控告警。具体参考:Kyuubi Server Metrics 官方文档。
六、参考网址
1、Introduction to the Kyuubi Configurations System — Kyuubi 1.3.0 documentation 2、Kyuubi 剖析 | Apache Kyuubi(Incubating) 核心功能调研-技术圈 3、Apache Kyuubi调研_静哥哥~的博客-CSDN博客_kyuubi