win10环境下的 IDEA+sbt打包S程序
博客大致内容:
在win平台用scala语言并在IDEA中进行Spark编程,然后利用IDEA中的sbt插件进行打包,把打包好的jar包扔到Spark集群中运行。
安装前的准备:确保你有一个可以访问的Spark集群,一个安装好的IntelliJ IDEA。
1.安装本地sbt
1. 首先进入到sbt官网下载windows版的sbt。下载地址
2. 安装sbt。注意:安装路径一定不要有空格!!!
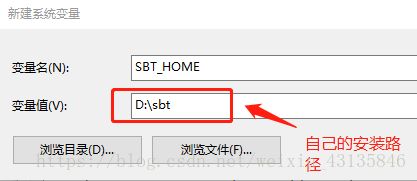
3. 配置sbt的环境变量。在系统变量中新建变量
SBT_HOME=D:\sbt
再在系统变量的PATH中添加
%SBT_HOME%\bin

4. 在sbt\conf\sbtconfig.txt中添加以下内容
-Dsbt.boot.directory=D:/sbt/.sbt/boot
-Dsbt.ivy.home=D:/sbt/.ivy2
-Dsbt.global.base=D:/sbt/.sbt
-Dsbt.repository.config=D:/sbt/conf/repo.properties
5. 在sbt\conf\目录下新建文件repo.repositories

6. 编辑步骤5新建的repo文件,加入以下内容,使用阿里云的源
[repositories]
local
ali:http://maven.aliyun.com/nexus/content/repositories/central/
7. win+R键,输入cmd进入控制台。在命令行中输入sbt。下载一些jar包

至此,windows平台的本地sbt配置完成。
2.配置IDEA
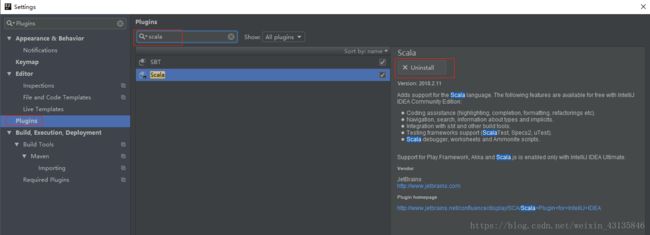
8. 安装scala和sbt插件
File->Settings->搜索Plugins,在插件中搜索scala和sbt进行安装
3.打开IDEA新建scala项目
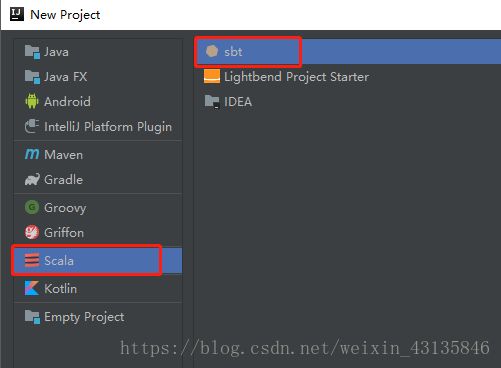
9. 新建项目

10. 使用sbt构建scala项目
11. 选择scala-SDK的版本,选择你安装Spark的那个版本所使用的scala版本,查看版本方法:使用命令:$>spark-shell 来查看。可以发现,这个spark版本是用2.11.8版本的scala编写的。
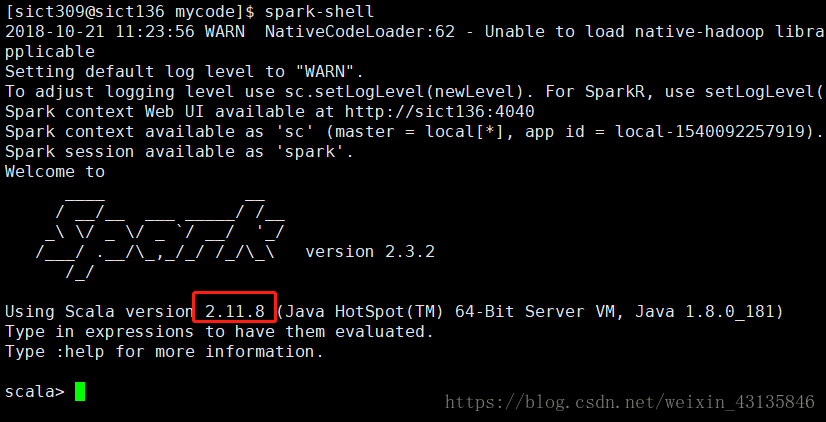
在这里选择2.11.8版本
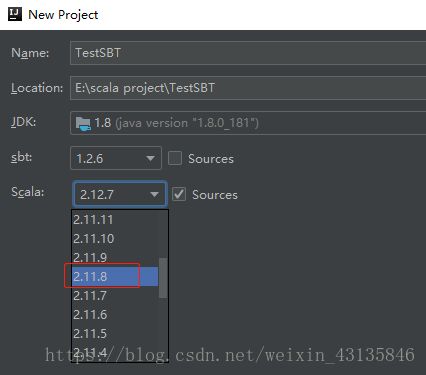
12. 修改项目的sbt设置,File->Settings->搜索 “sbt”,修改VM parameters的内容为/sbt/conf/sbtconfig.txt中的内容。ctrl+v粘贴。
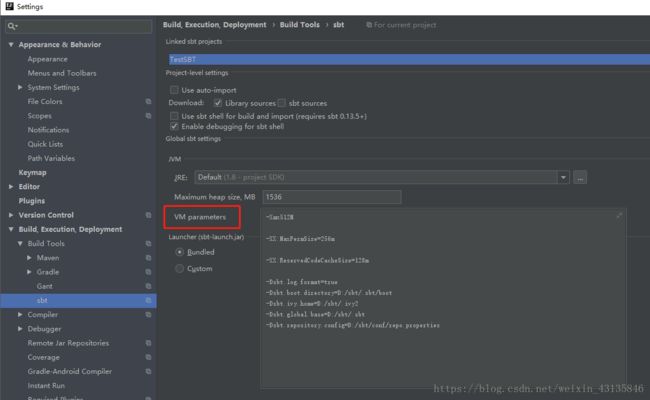
13. 新建一个测试类,在项目src/main/scala目录下新建一个scala 类。类型选择Object,不是class
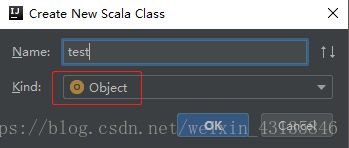
加入以下代码:
def main(args: Array[String]): Unit = {
println("打包成功!")
}
14. 新建sbt Task。点击右上角Add Configuration
点击左上角“+”号,选择sbt Task

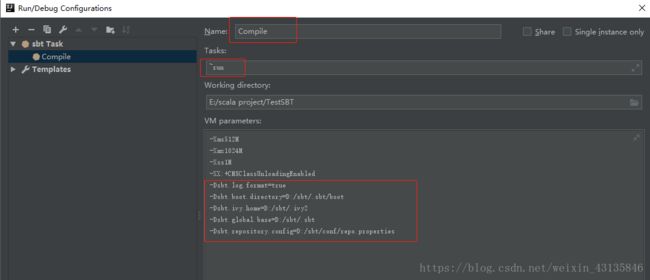
修改Name,这个自己设置即可
Tasks项输入:~run
修改VM parameters的内容:把/sbt/conf/sbtconfig.txt中的以-Dsbt开头的内容加进去
4. 运行程序
15. 点击右上角绿色小三角
运行输出结果如下:

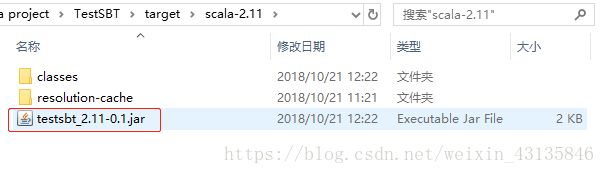
可以看出,程序运行成功。打包好的jar包在\target\scala-2.11\testsbt_2.11-0.1.jar
16. 上传jar包至spark集群运行
把这个jar上传至spark集群的机器上,如果你的windows能够访问spark集群,利用xshell工具,连接上spark集群,利用命令$>rz 上传jar包。上传至的目录就是输入rz命令的当前目录。

17. 输入下面命令。
/soft/spark/bin/spark-submit --class test /soft/spark/mycode/testsbt_2.11-0.1.jar
它的意思是先进入到spark/bin目录下找到spark-submit命令,然后设置–class为我们jar包中的test类,然后指定jar包的位置

可以看出,我们刚才打包好的jar包 已经可以在spark集群中运行了。
5.进阶之路一
- 编写Spark程序,打jar包并在集群中运行。
修改项目根目录下的build.sbt文件,添加Spark的核心依赖。添加如下一行代码:
libraryDependencies +="org.apache.spark" % "spark-core_2.11" % "2.3.2" % "provided"
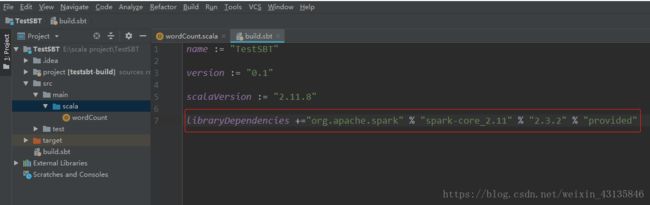
修改完后点击右下角的“Import Changes”,等待加载依赖包。
- 新建一个wordCount类,添加以下代码:
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
object wordCount {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
val inputFile = "/user/wordcount/words.txt" //hdfs文件访问
val conf = new SparkConf().setAppName("wordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}
代码是统计hadoop中的hdfs文件系统中的一个words.txt中的词频。
- 运行,生成jar包。
上传至Spark集群环境中,运行jar包
/soft/spark/bin/spark-submit --class wordCount /soft/spark/mycode/testsbt_2.11-0.1.jar
可以看到运行结果。
- 另附三种从HDFS中加载数据的方法,下面三行代码等价。
val lines = sc.textFile("hdfs://localhost:8020/user/hadoop/words.txt") //这个端口号是自己设定的
val lines = sc.textFile("/user/hadoop/words.txt")
val lines = sc.textFile("words.txt") //默认加载/user/hadoop/下的文件
6.进阶之路二
使用Spark操作HBase。前提是集群中配置好了HBase,并且里面有一个名为“student”的表,属性有name、gender、age这三个。
- 先在项目根目录下的project文件下创建assembly.sbt文件,配置sbt的插件。
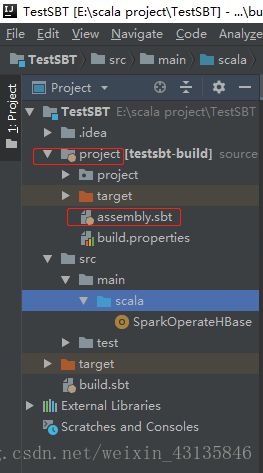
-在assembly.sbt中添加以下内容:
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.8") //这个0.14.8版本号根据自己的sbt版本修改
- 接下来在build.sbt中添加有关HBsae的依赖,和解决添加打包jar包后和scala类库冲突的问题。
libraryDependencies += "org.apache.hbase" % "hbase-client" % "1.1.5"
libraryDependencies += "org.apache.hbase" % "hbase-common" % "1.1.5"
libraryDependencies += "org.apache.hbase" % "hbase-server" % "1.1.5"
assemblyJarName in assembly := "BigData.jar" //指定打包的名称
test in assembly := {}
assemblyOption in assembly := (assemblyOption in assembly).value.copy(includeScala = false)
assemblyMergeStrategy in assembly := {
case PathList("javax", "servlet", xs@_*) => MergeStrategy.first
case PathList(ps@_*) if ps.last endsWith ".class" => MergeStrategy.first
case PathList(ps@_*) if ps.last endsWith ".xml" => MergeStrategy.first
case PathList(ps@_*) if ps.last endsWith ".html" => MergeStrategy.first
case PathList(ps@_*) if ps.last endsWith ".properties" => MergeStrategy.first
case "application.conf" => MergeStrategy.concat
case "unwanted.txt" => MergeStrategy.discard
case x =>
val oldStrategy = (assemblyMergeStrategy in assembly).value
oldStrategy(x)
}
修改完后,Import Changes以下,如果有错误,回去修改assembly.sbt中的版本号。
- 新建一个scala类,名为SparkOperateHBase,代码作用是读取HBase中的名为“student”表的内容。
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.log4j.{Level, Logger}
object SparkOperateHBase {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.apache.hadoop.hbase").setLevel(Level.ERROR)
val conf = HBaseConfiguration.create()
val sc = new SparkContext(new SparkConf())
//设置查询的表名
conf.set(TableInputFormat.INPUT_TABLE, "student")
val stuRDD = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
val count = stuRDD.count()
println("Students RDD Count: " + count)
stuRDD.cache()
//遍历输出
stuRDD.foreach({ case (_, result) =>
val key = Bytes.toString(result.getRow)
val name = Bytes.toString(result.getValue("info".getBytes, "name".getBytes))
val gender = Bytes.toString(result.getValue("info".getBytes, "gender".getBytes))
val age = Bytes.toString(result.getValue("info".getBytes, "age".getBytes))
println("Row key:" + key + " Name:" + name + " Gender:" + gender + " Age:" + age)
})
}
}
- 本地打包
在IDEA左下角打开Terminal,这个Terminal和win的Dos窗口没什么区别,IDEA的就是直接在项目根目录下敲命令。
sbt assembly
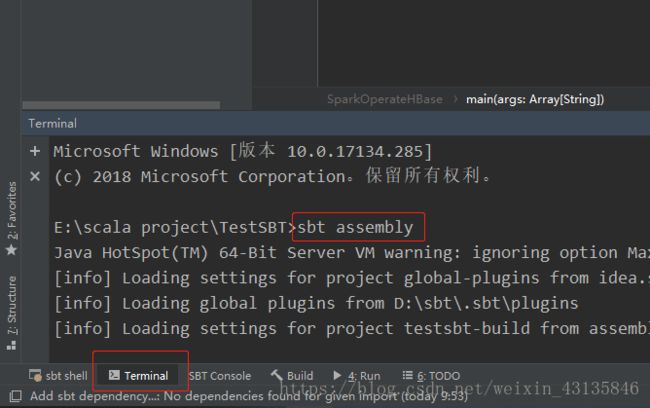
带有依赖的jar包打包已经完成!此时去文件夹中找到BigData.jar,会发现大小变大了不少,30+M,不带jar包的才几K。