spark sql Dataset&Dataframe算子大全
目录
Dataset&Dataframe
RDD,Dataset,Dataframe互相转换
Dataset&Dataframe算子
show()
na() 返回包含null值的行
stat()
sortWithinPartitions()
sort()&order by()
hint()
selectExpr()
filter&where
groupBy&rollup&cube
reduce
groupByKey()
agg()
limit(n:Int)
union
intersect()
except()
sample()
randomSplit()
flatMap&explode
withColumn
withColumnRenamed
drop
dropDuplicates()
describe(cols: String*): DataFrame
head(n: Int): Array[T]&head()&first()&take()&takeAsList
map&mapPartitions
collect()&collectAsList()&toLocalIterator()
count()
Dataset&Dataframe
type DataFrame = Dataset[Row]DataFrame每一行类型为Row,DataSet就没这限制了。
//查hive表
val df=spark.sql("select date,status,api from data.api")//df的类型为sql.Dataframe
val ds1=df.map(ele=>(ele.getString(0)))
val ds2=df.map(ele=>(ele.getString(0),ele.getLong(1),ele.getString(2)))
//元素ele的类型为Row,获取值必须调用get()或者get类型()方法,df.map将隐式转换为Dataset
ds1.map(ele=>(ele))//ele类型为String
ds2.map(ele=>(ele._1,ele._2,ele._3))//ele类型为tupleDataframe行类型为Row,如果想获取具体字段值,必须调用Row的get()或get类型()方法
Datset行类型可以为String,可以为tuple等等,获取值像RDD那样
RDD,Dataset,Dataframe互相转换
RDD转别的
val rdd=spark.sparkContext.textFile("C:\\zlq\\data\\people.txt")
val rdd1=rdd.map(ele=>(ele.split(",")(0),ele.split(",")(1).trim.toInt))
rdd1.toDF("name","age")//转df,指定字段名
rdd1.toDS()//转ds
case class Person(name:String,age:Int)
val rdd2=rdd.map(_.split(","))
.map(ele=>(Person(ele(0),ele(1).trim.toInt))).toDF()//将自定义类转df
val schemaString="name age"
val fields=schemaString.split(" ")
.map(ele=>StructField(ele,StringType,nullable = true))
val schema=StructType(fields)
val rdd3=rdd.map(_.split(",")).map(ele=>Row(ele(0),ele(1).trim))
val df=spark.createDataFrame(rdd3,schema)//将StructType作用到rdd上,转dfDataframe转别的
val df=spark.sql("select date,status,api from data.api")
df.rdd
//df转ds就太多了,先列举几个
df.as() map filter flatMap等等吧Dataset转别的
ds.rdd
//ds转df也不少,先列举
select join agg toDF()Dataset&Dataframe算子
show()
show()//默认显示20行,字段值超过20,默认截断
show(numRows: Int)//指定显示行数
show(truncate: Boolean)//指定是否截断超过20的字符
show(numRows: Int, truncate: Boolean)//指定行数,和是否截断
show(numRows: Int, truncate: Int)//指定行数,和截断的字符长度na() 返回包含null值的行
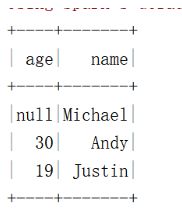
val df=spark.read.json("C:\\zlq\\data\\people.json")
df.show()
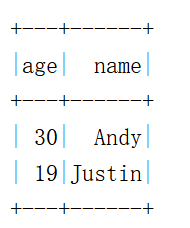
df.na.drop().show()
stat()
//{"name":"Michael"}
//{"name":"Andy", "age":30}
//{"name":"Justin", "age":19}
//{"name":"Tom", "age":19}
//{"name":"jerry", "age":19}
df.stat.freqItems(Seq("age")).show()结果如下,你把json的后两条去掉也是这结果,会自动去重

sortWithinPartitions()
类似hive的sort by,只在分区内排序,默认降序
spark.sql(
"""
|select distinct to_date(date) y
|from data.api_orc
""".stripMargin).repartition(20).sortWithinPartitions("y")
//为了查看每个分区的数据,转成rdd,调用mapPartitionsWithIndex()
.rdd.mapPartitionsWithIndex((x,iter)=>{
var result=List[String]()
for(i<-iter){
result ::=(x+"-"+i.getDate(0))
}
result.toIterator
}).foreach(println)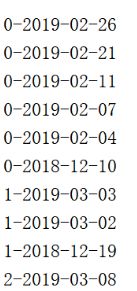
sort()&order by()
全局排序,按指定列
spark.sql(
"""
|select distinct to_date(date) y
|from data.api_orc
""".stripMargin).sort("y").show()hint()
df1.join(df2.hint("broadcast"))//将df2广播selectExpr()
spark.sql(
"""
|select distinct to_date(date) y
|from data.api_orc
""".stripMargin).sort("y").selectExpr("y as hahha").printSchema()
filter&where
where调用的是filter
peopleDs.where("age > 15")
peopleDs.filter($"age" > 15)groupBy&rollup&cube
返回Dataset
ds.groupBy($"department").avg()//按部门计算平均值
ds.groupBy($"department", $"gender").agg(Map(
"salary" -> "avg",
"age" -> "max"
))//计算平均工资,和最大年龄reduce
调的就是rdd的reduce方法,传的方法返回什么类型,reduce就返回什么类型
val df=spark.read.json("C:\\zlq\\data\\people.json")
println(df.select("age").na.drop().reduce((row1, row2) => {
Row(row1.getLong(0) + row2.getLong(0))
}).get(0))
//计算年龄总和groupByKey()
接收一个将Row转为别的类型的函数
val df=spark.sql(
"""
|select size,status
|from data.api_orc
|where to_date(date)="2019-03-18"
""".stripMargin).groupByKey(row=>(row.getLong(1)))//取第二个字段agg()
是ds.groupBy().agg的缩写,返回 DataFrame
spark.sql(
"""
|select size,status
|from data.api
|where to_date(date)="2019-03-15"
""".stripMargin).agg(Map("size"->"max","status"->"avg")).show()limit(n:Int)
返回新的Dataset
union
并集,字段数必须必须相同
val df1=spark.read.json("C:\\zlq\\data\\people.json")
val df2=spark.read.json("C:\\zlq\\data\\people.json")
df1.union(df2).show()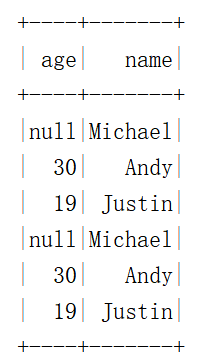
intersect()
交集
except()
差集
df1.except(df2)//df1里有的而df2里没有的sample()
返回Dataset,参数依次为,是否放回,抽取比例,随机种子
sample(withReplacement: Boolean, fraction: Double, seed: Long)
sample(withReplacement: Boolean, fraction: Double)randomSplit()
将Dataset按比例大致分为结果Dataset,返回Array[Dataset]or list
randomSplit(weights: Array[Double], seed: Long)
randomSplitAsList(weights: Array[Double], seed: Long)
randomSplit(weights: Array[Double])
println(df1.collect().length)
df1.randomSplit(Array(0.3,0.4,0.3)).foreach(ele=>{
println(ele.collect().length)
})
//结果为 29 8 13 8flatMap&explode
返回DataFrame
println(df2.collect().length)
println(df2.flatMap(ele=>(ele.getString(1).split(","))).collect().length)
//第二个数比第一个数大,一行拆多行,行转列withColumn
添加列或者替换列
val df=spark.createDataset(Seq(("tom",21,17),("jerry",31,19)))
.toDF("name","age","salary")
df.show()
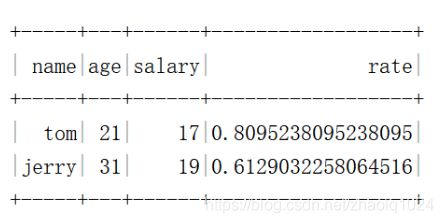
df.withColumn("rate",df("salary")/df("age")).show()
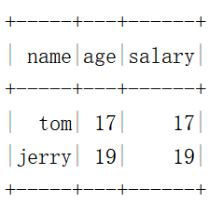
df.withColumn("age",df("salary")).show()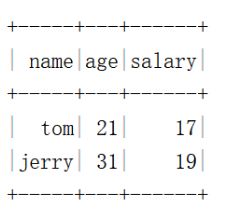
withColumnRenamed
给字段重命名
val df=spark.createDataset(Seq(("tom",21,17),("jerry",31,19)))
.toDF("name","age","salary")
df.withColumnRenamed("name","hah").printSchema()
drop
删除一列或者多列
val df=spark.createDataset(Seq(("tom",21,17),("jerry",31,19)))
.toDF("name","age","salary")
df.drop("name","age").printSchema()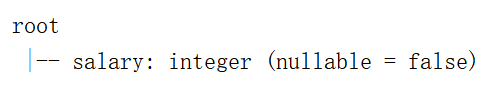
dropDuplicates()
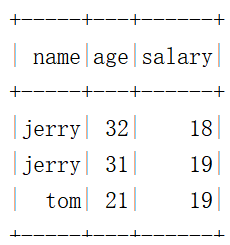
val df=spark.createDataset(Seq(("tom",21,19),("jerry",31,19),("jerry",32,18)))
.toDF("name","age","salary")
df.dropDuplicates("name").show()
df.dropDuplicates("salary").show()
df.dropDuplicates("salary","name").show() 

describe(cols: String*): DataFrame
计算数量,均值等
val df=spark.createDataset(Seq(("tom",21,19),("jerry",31,19),("jerry",32,18)))
.toDF("name","age","salary")
df.describe("age","salary").show() 
head(n: Int): Array[T]&head()&first()&take()&takeAsList
head(),first返回第一个元素,head(n)返回数组
val df=spark.createDataset(Seq(("tom",21,19),("jerry",31,19),("jerry",32,18)))
.toDF("name","age","salary")
for(i<-df.head(2)){
println(i)
}
println(df.head())
println(df.first())map&mapPartitions
fun(ele) fun(partition)
collect()&collectAsList()&toLocalIterator()
一个返回Array,一个返回List
count()
返回行数