deeplearning.ai-卷积神经网络
参考:
http://mooc.study.163.com/learn/deeplearning_ai-2001281004?tid=2001392030#/learn/content?type=detail&id=2001729322&cid=2001724501
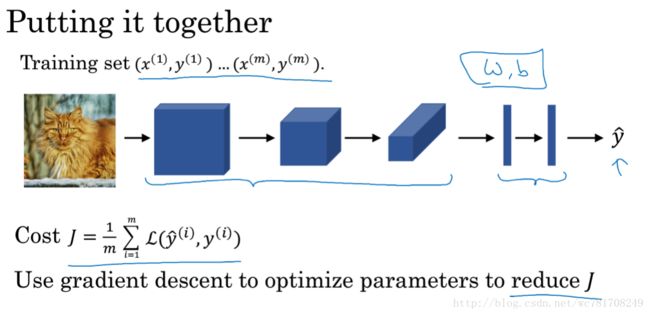
1、卷积神经网络
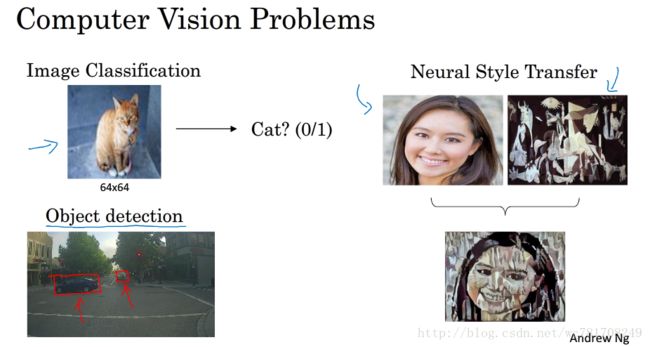
1.1 计算机视觉
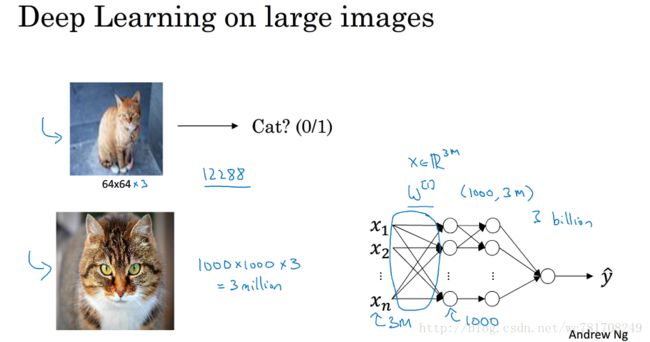
假如图像的大小1000x1000x3=3million
这意味着特征向量X的维度高达3million
第一个隐藏层也许有1000个隐藏单元,而所有的权值 W[1] W [ 1 ] ,如果你使用标准的全连接网络,该矩阵大小为[1000,3million],这意味着 W[1] W [ 1 ] 有 1000*3million个参数 即30亿个参数,如此巨大的参数情况下,难以获取足够的数据来防止神经网络发生过拟合和竞争需求,要处理含30亿参数的神经网络,巨大的内存需求让人不太能接受,而对于视觉处理,肯定不想它只能处理小图片,你希望它同时也能处理大图,为此我们需要进行卷积运算,它是卷积神经网络非常重要的一块
下节课介绍如何进行这种运算,用年龄检测的例子来说明卷积的含义
1.2 边缘检测示例
卷积运算是卷积神经网络最基本的组成部分
使用边缘检测作为入门样例
卷积是如何进行运算得
让电脑看清照片中有什么物体,你可能做的第一件事,检测图片中的垂直边缘,检测水平边缘
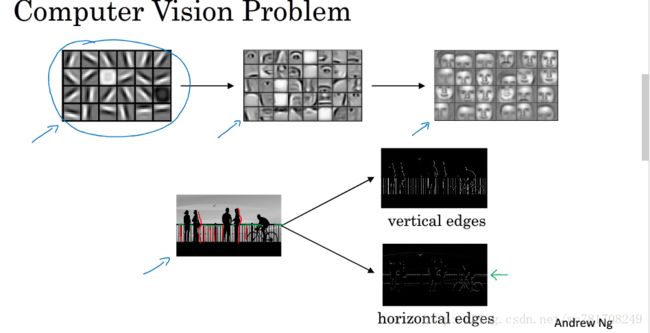
如何在图像中检测这些边缘
注:在数学中星号(*)是卷积的标准标志,但是在python中,这个标识常常用来表示乘法 或者元素乘法
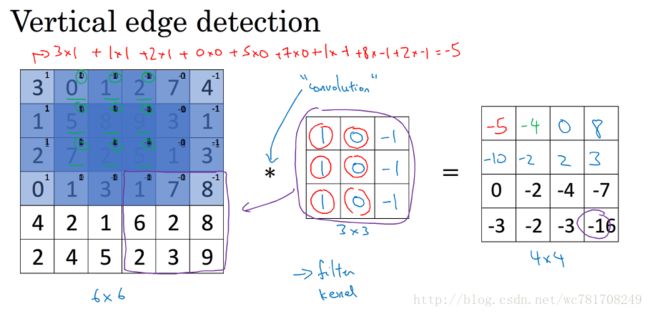
实现卷积操作:
Python:使用np.convolve()
from scipy.signal import convolve2d
tensorflow :使用tf.nn.conv2d
keras:conv2D
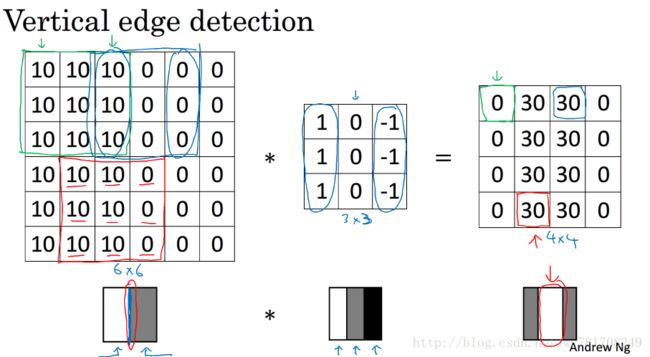
1.3 更多边缘检测内容
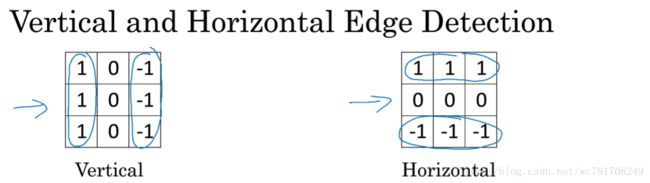
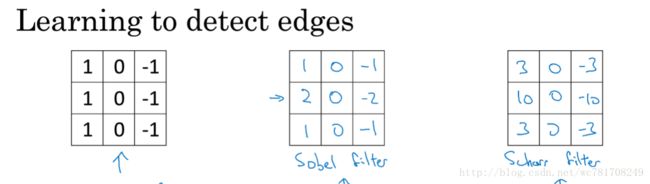
1.4 Padding
假设图像大小 n x n 卷积核大小 f x f 卷积后的图像大小 (n-f+1)x(n-f+1)
p表示padding
卷积后的图像大小 (n+2p-f+1)x(n+2p-f+1)
f通常为奇数

1.5 卷积步长
p表示padding s表示stride
假设图像大小 n x n 卷积核大小 f x f
卷积后的图像大小 (n+2p−f)÷s+1 ( n + 2 p − f ) ÷ s + 1 x (n+2p−f)÷s+1 ( n + 2 p − f ) ÷ s + 1
如果 (n+2p−f)÷s ( n + 2 p − f ) ÷ s 不是整数 ,向下取整


1.6 卷积中“卷”的体现之处
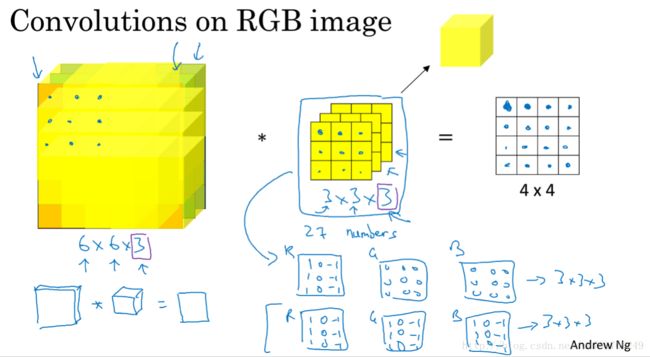
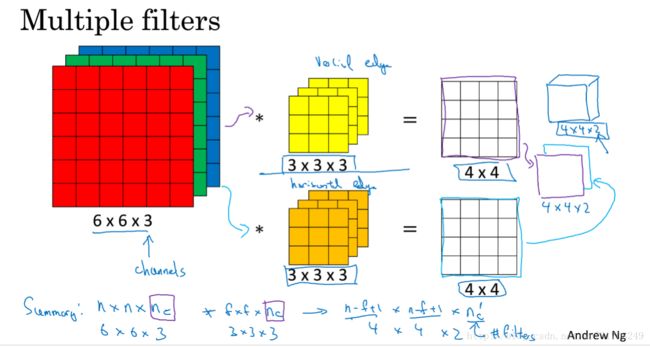
1.7 单层卷积网络

1.8 简单卷积网络示例
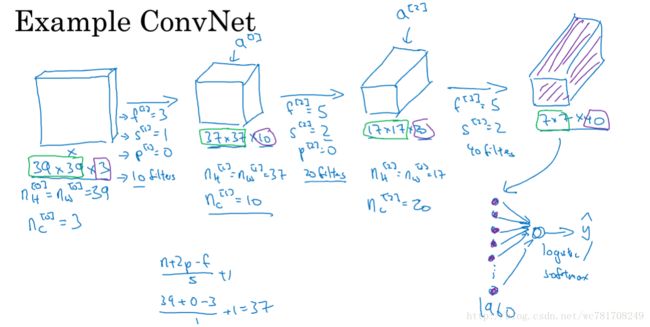

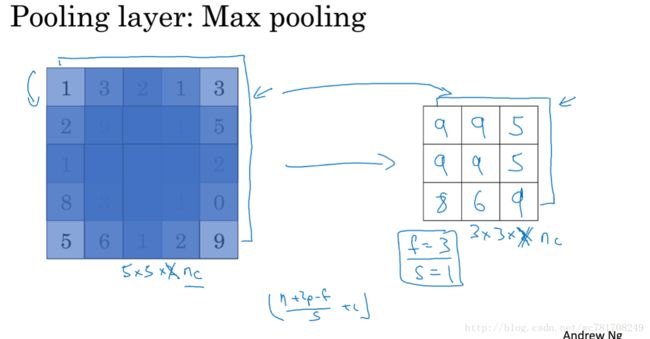
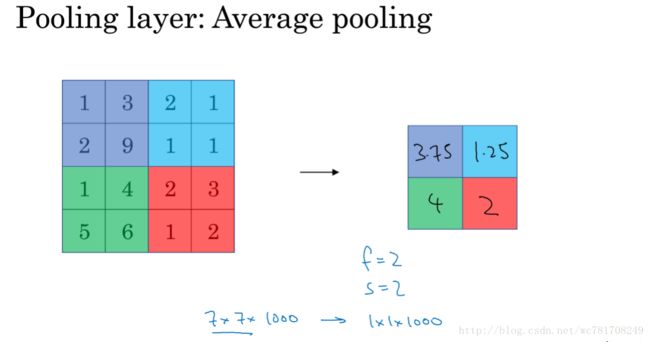
1.9 池化层
一般使用最大池化层,平均池化层使用少
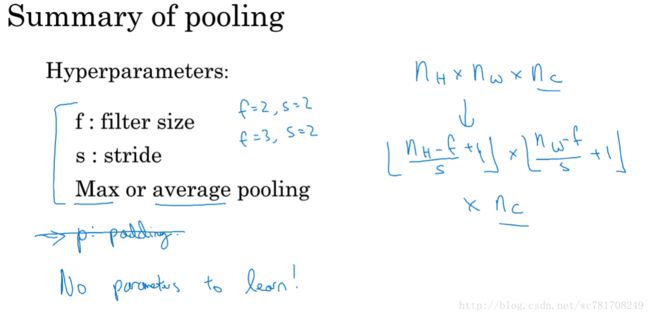
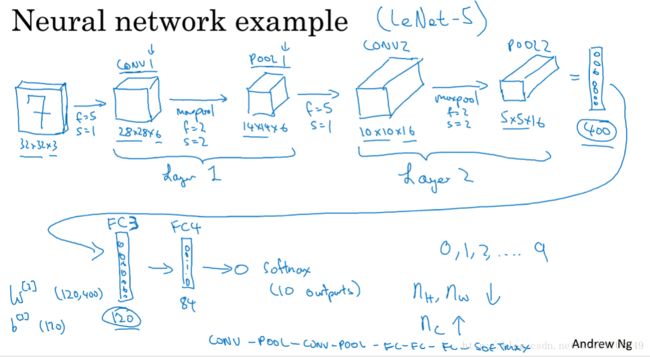
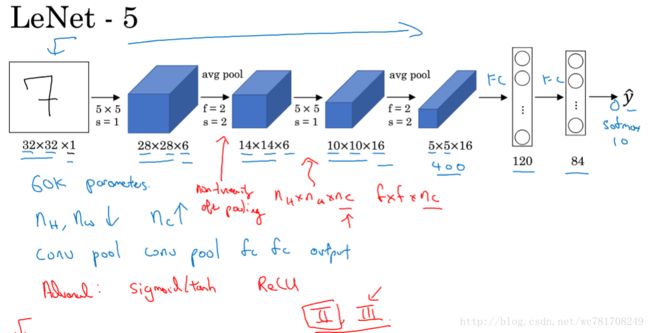
1.10 卷积神经网络示例
关于如何选择参数
常规的做法尽量不要自己设置超参数,而是查看文献中别人采用了哪些超参数,选一个在别人任务中效果很好的框架,那么它也有可能适用于你的应用
另一种模式 :一个或多个卷积层后面跟随一个池化层,然后一个或多个卷积层后面跟随一个池化层,然后几个全连接层,最后一个softmax
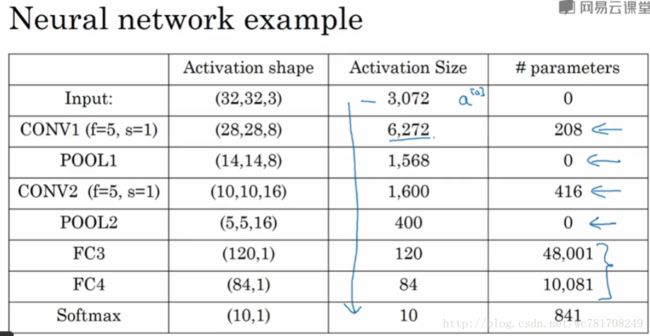
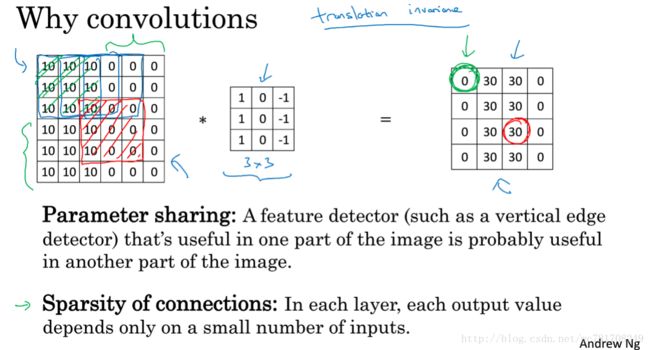
1.11 为什么使用卷积?
与全连接层相比,卷积层 参数共享和稀疏连接
2、深度卷积网络:实例探究
2.1 为什么要进行实例探究?

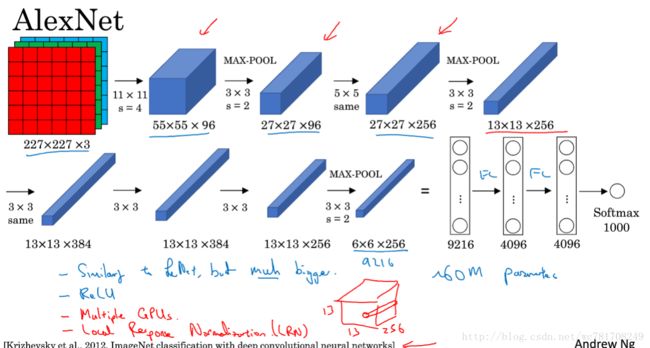
2.2 经典网络
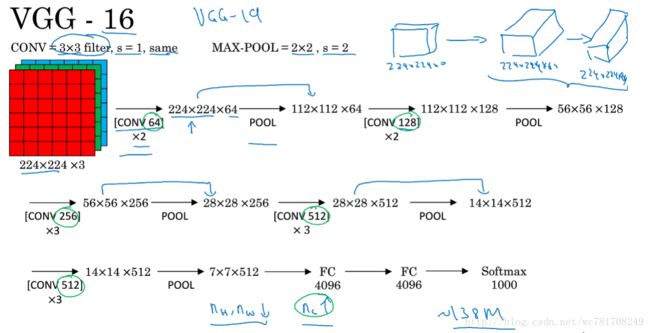
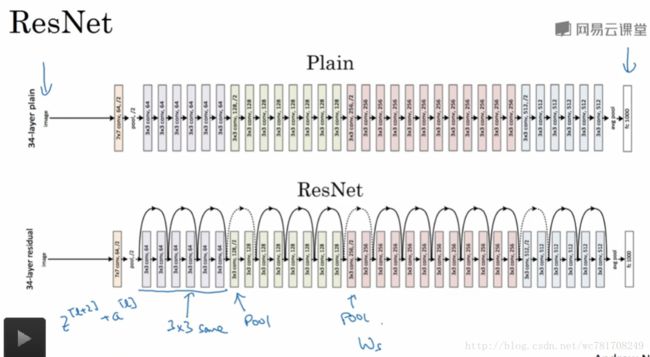
2.3 残差网络
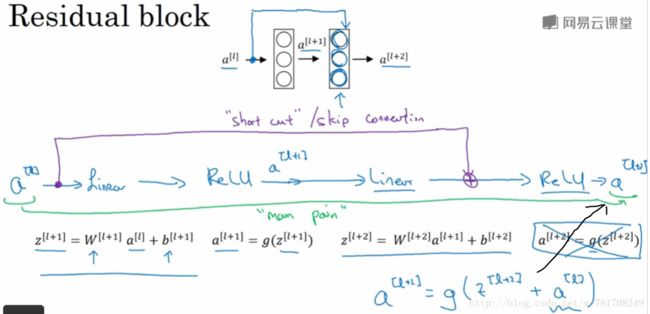
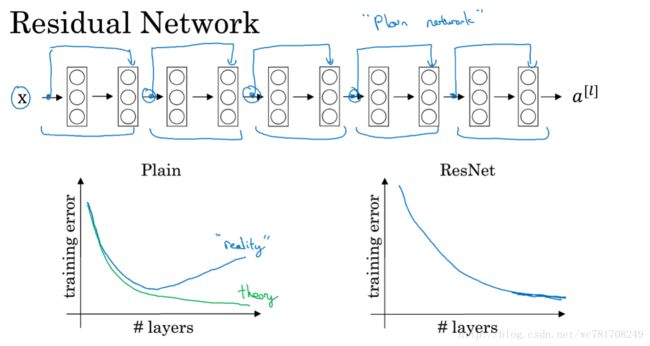
2.4 残差网络为什么有用?
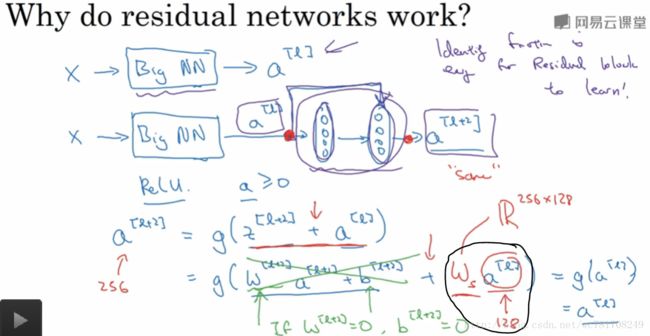
如果 a[l] a [ l ] 与 z[l+1] z [ l + 1 ] 维度不一致,可以 ws∗a[l] w s ∗ a [ l ] 将其变成与 z[l+1] z [ l + 1 ] 维度一致
2.5 网络中的网络以及 1x1卷积

2.6 谷歌 Inception 网络简介
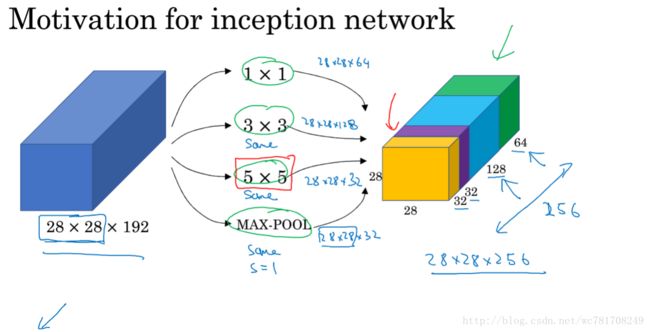
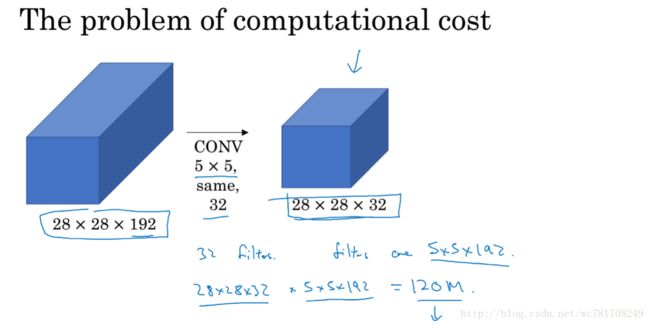
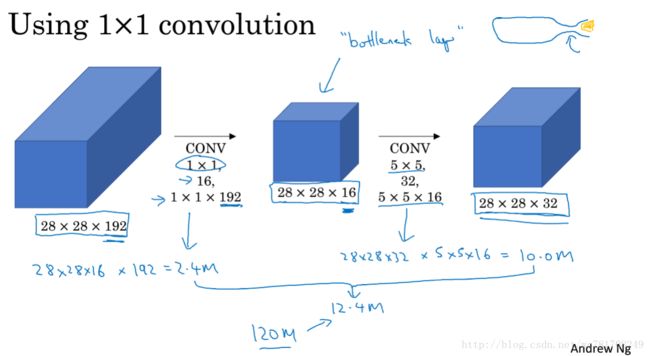
2.7 Inception 网络
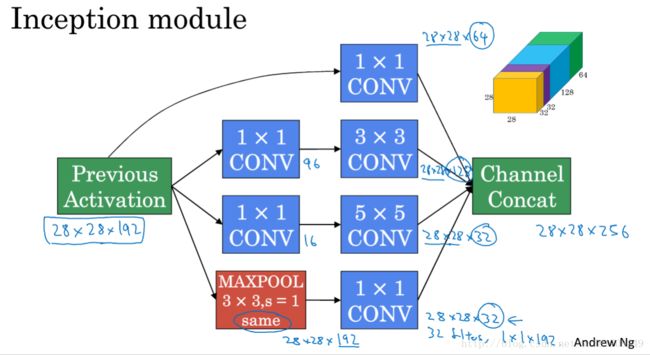
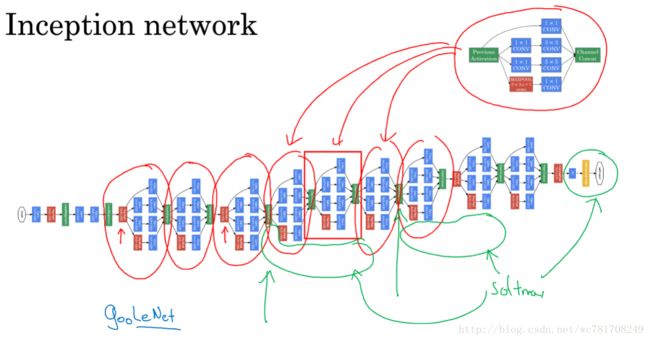
2.8 使用开源的实现方案
git clone github下载地址2.9 迁移学习
数据集:
ImageNet
Ms COCO
Pascal
如:使用Inception_v3模型 1000类,迁移到猫狗检查上
1、如果猫狗图片比较少,冻结Inception_v3模型前n层(不含输出层)所有权重参数(冻结权重参数,权重参数将保持不变),只对输出层修改重新训练权重
2、如果猫狗图片比较多,冻结Inception_v3模型前n-3(自由确定)层所有权重参数,对后3层(或多层 包含输出层)重新训练权重
3、如果猫狗图片比非常多,使用Inception_v3模型前n层(不含输出层)所有权重参数作为新模型的初始权重,对所有层重新训练权重
2.10 数据扩充
镜像
随机裁剪
旋转
剪切图像
局部扭曲
前2种使用比较多
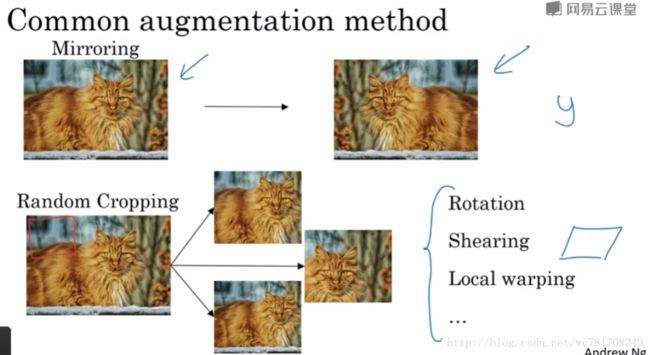
色彩转换(颜色扭曲)
PCA颜色增强
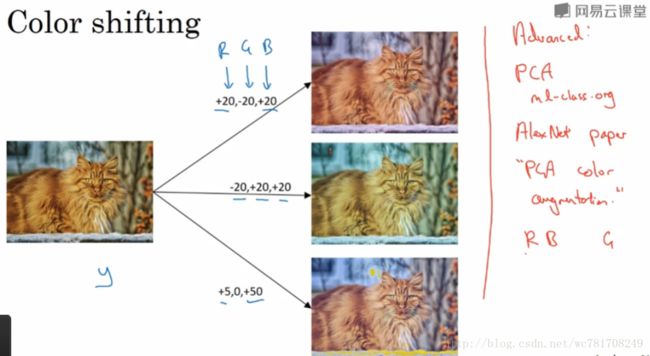
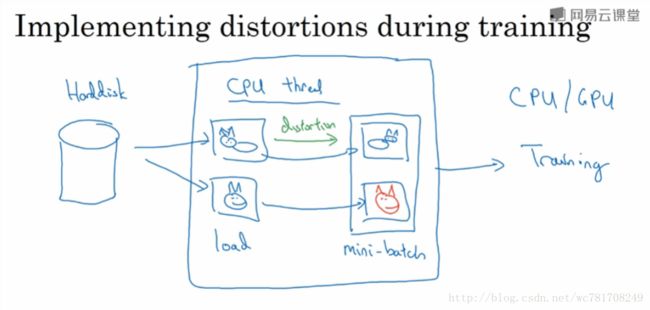
2.11 计算机视觉现状
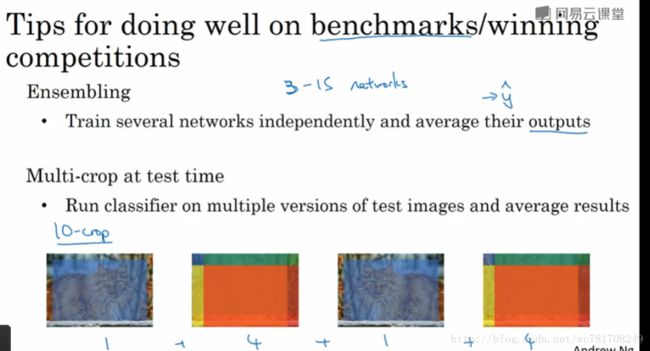
Ensembling:
独立训练几个神经网络,并平均输出它们的输出
随机初始化,比方说随机选择三个、五个或七个神经网络,然后训练所有这些神经网络,然后平均它们的输出,另外对它们的输出y^ y^ 进行平均的计算很重要的,不要平均它们的权重,这是行不通的
假如你有7个神经网络,7个不同的预测,然后平均它们,这可能让你在基准上提高1%~2%
但是这意味着要对每张图片进行测试,你可能需要在从3到15个不同的网络中运行一个图片,这是很典型的,因为这3到15个网络可能让你的运行时间变慢,甚至更多时间,所以技巧之一的集成是人们用于基准和赢得比赛的利器,但我认为这几乎从不用于生产实际的客户服务
Multi-crop at test time:
Multi-crop是一种将数据扩展应用到您的测试图像的形式
举个例子,让我们看看猫的形象,然后把它复制4遍(包括2个镜像版本)
10-crop:
假设你取这个中心区域crop 然后通过你的分类器去运行它
取左上角的crop,运行在你的分类器
取右上角,运行在你的分类器
左下角 ,运行在你的分类器
右下角 ,运行在你的分类器
5x2=10
通过分类器来运行这十张图片,然后对结果进行平均

第三周 目标检测
3.1 目标定位
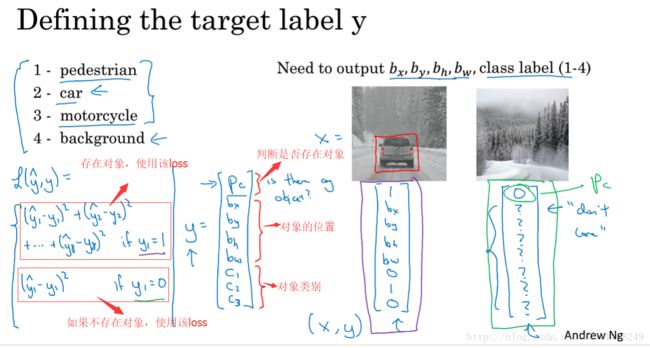
实际中,可以不对c1,c2,c3 和softmax激活函数应用对数损失函数,并输出其中一个元素值
通常做法是对边界框坐标应用平方差或类似方法,对pc应用逻辑回归函数,甚至采用平方预测误差也是可以的
3.2 特征点检测
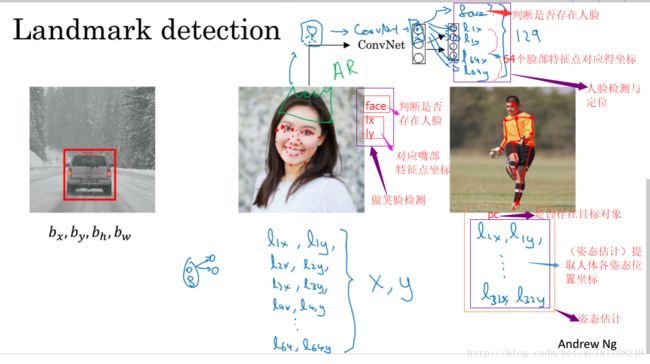
3.3 目标检测
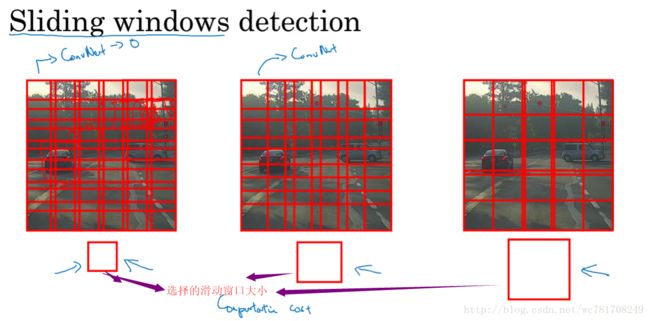
滑动窗口目标检测
以某一步幅滑动这些方框窗口,遍历整张图片,对这些方形区域进行分类,判断里面有没有汽车
滑动窗口木匾检测算法也有很明显的缺点,就是计算成本,因为你在图片中剪切出太多小方块,卷积网络要一个个地处理,如果你选用的步幅很大,显然会减少卷积网络的窗口个数,但是粗粒度可能会影响性能,反之,如果采用小粒度或小步幅传递给卷积网络的小窗口会特别多,这意味着超高的计算成本

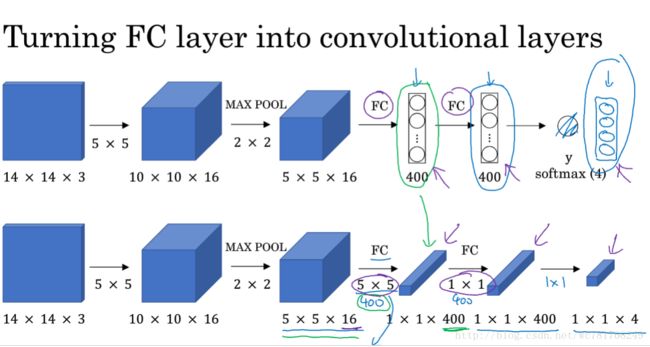
3.4 卷积的滑动窗口实现
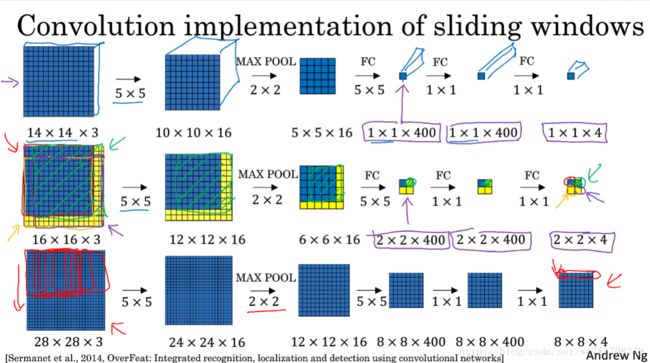
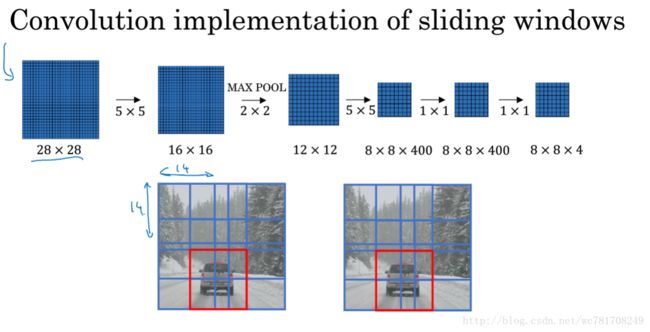
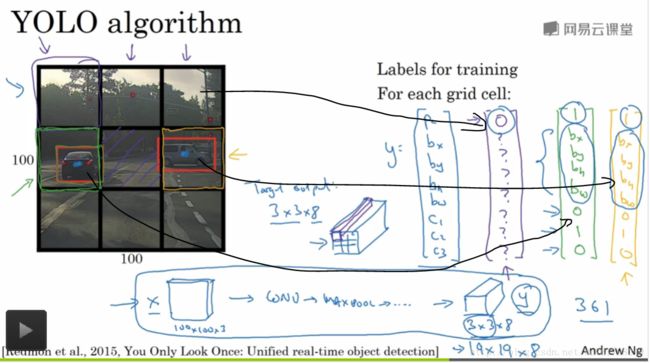
3.5 Bounding Box 预测
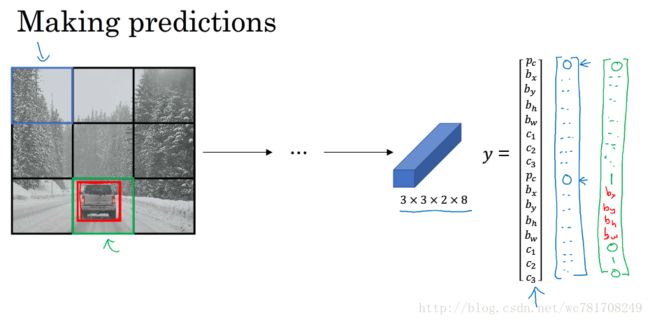
YOLO 算法 得到精确的边界
具体做法:
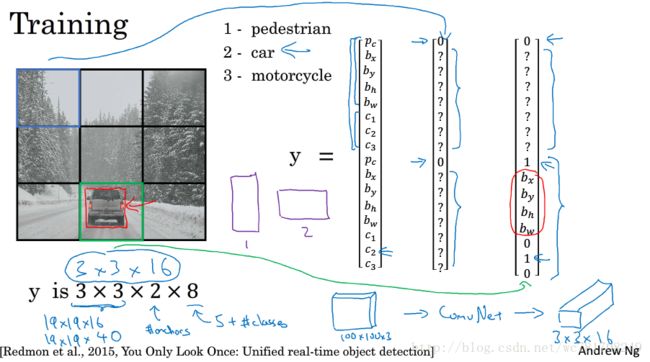
假设输入得图像大小100x100,然后在图像上放上一个网格,为了方便,这里是有3x3网格,实际上会使用更加精细的网格 如:19x19
基本思路:
使用图像分类和定位算法,然后将算法应用到9个格子上,你使用图像定位算法
采用图像分类和定位算法,逐一应用在图像的9个格子中,更具体是 你需要定义训练标签,所以对于9个格子中的每一个,指定一个标签y,y是8维向量和之前看到的一样
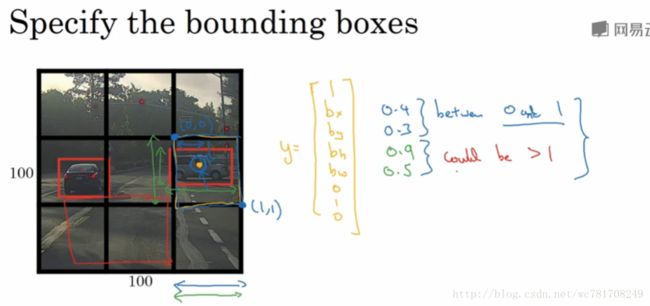
3.6 交并比

评估对象检测的精度
3.7 非极大值抑制
该算法可以对每个对象只检测一次,只输出概率最大的结果
首先这个19x19网格上泡一下算法,得到19x19x8的输出尺寸
然后 去除所有边界框 ,我们将所有的预测 所有边界框pc小于或等于某个阈值,如0.6的边界框去除
剩下的边界框,一直选择概率pc最高的边界框,然后把它输出成预测结果,再去掉所有剩下的边界框
如果有3个类别,需对这3个类别分别做非极大值抑制


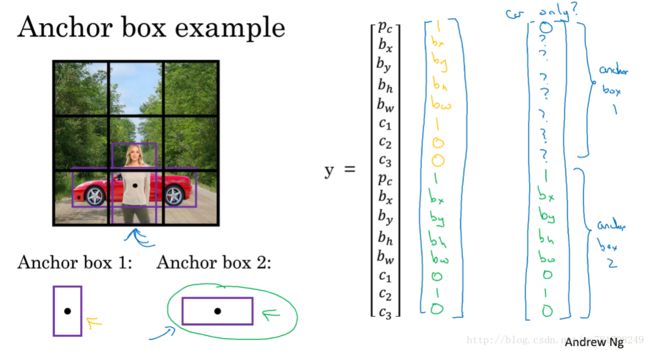
3.8 Anchor Boxes
多个对象重叠时,如何设置标签
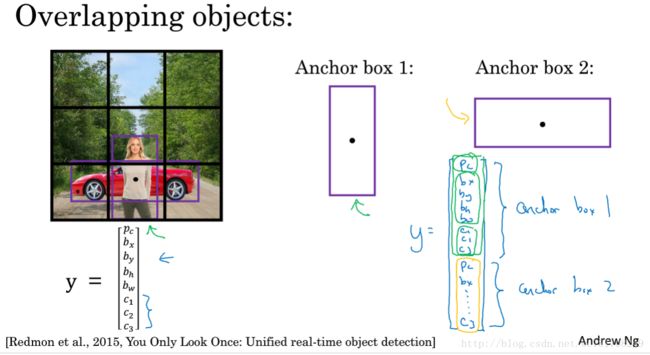

3.9 YOLO 算法

3.10 (选修)RPN 网络


第四周 特殊应用:人脸识别和神经风格转换
4.1 什么是人脸识别?

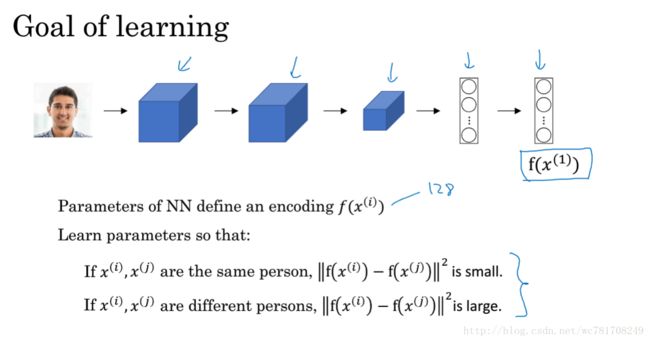
4.2 One-Shot 学习
每个人脸只有一个样本,训练一次
传统的通过给每个人贴上对应得标签 0,1,2,3…. 已经不适应于该问题,因为每一类(每个人脸只有一个样本,而传统的这种贴标签的方法需要大量的样本)
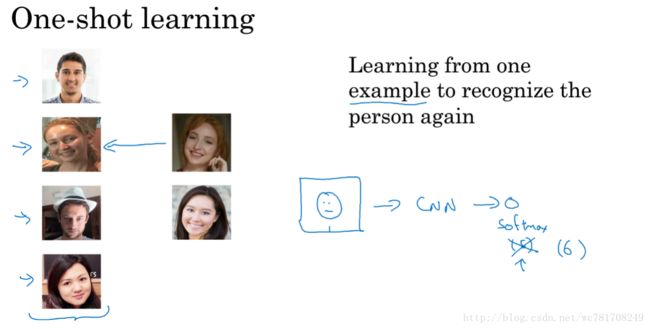
解决方法:训练2张图像的相似程度函数

4.3 Siamese 网络
图像–>卷积神经网络–>编码
类似于自编码中的encodeing部分
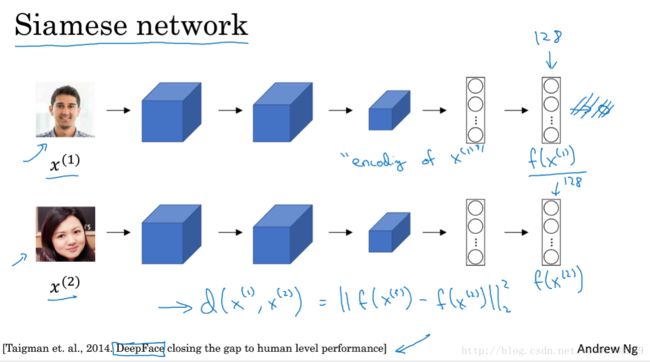
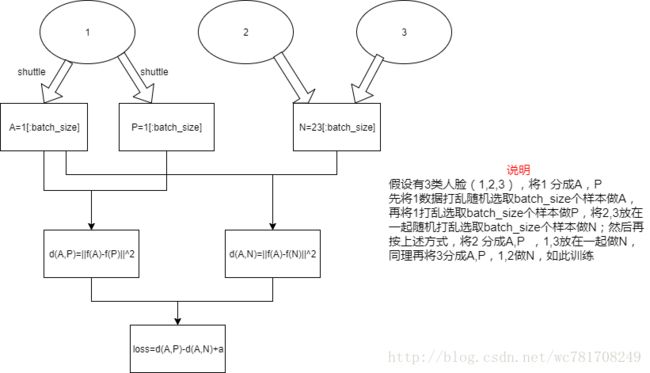
4.4 Triplet 损失
A,P,N(其中A,P 来自同一人 不同图像,A,N来自不同人)
loss function: ||f(A)−f(p)||2+α<=||f(A)−f(N)||2 | | f ( A ) − f ( p ) | | 2 + α <= | | f ( A ) − f ( N ) | | 2




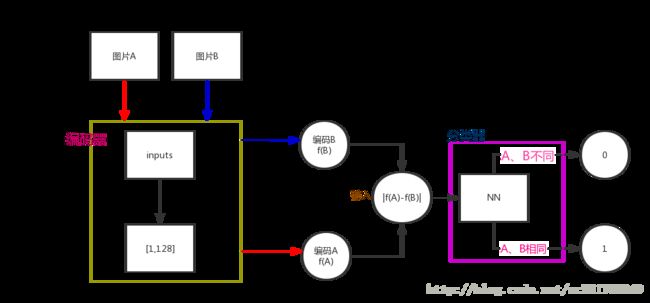
4.5 面部验证与二分类
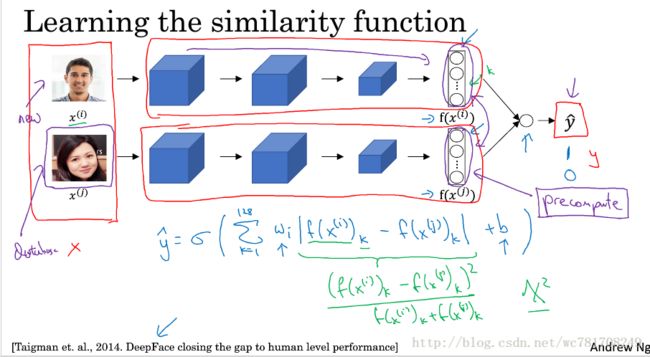

验证两张图片是否是同一人,
将图片进行编码, 在将编码 之差输入到新的神经网络中,同一人输出1,否则0
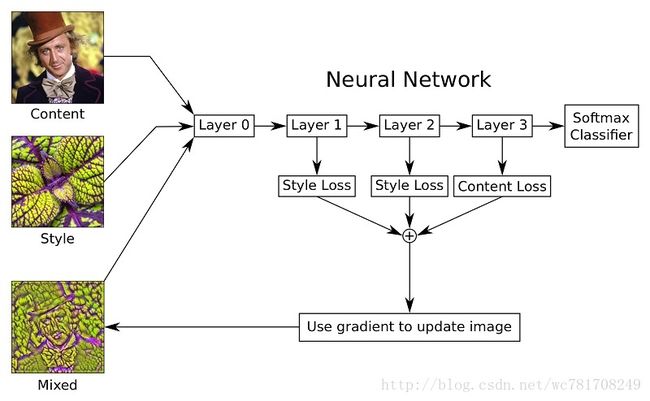
流程图
4.6 什么是神经风格转换?

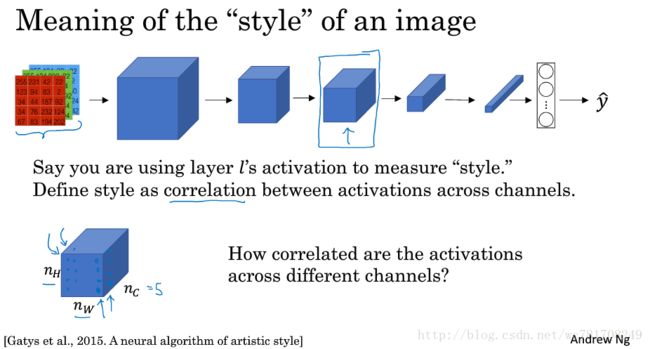
4.7 深度卷积网络在学什么?


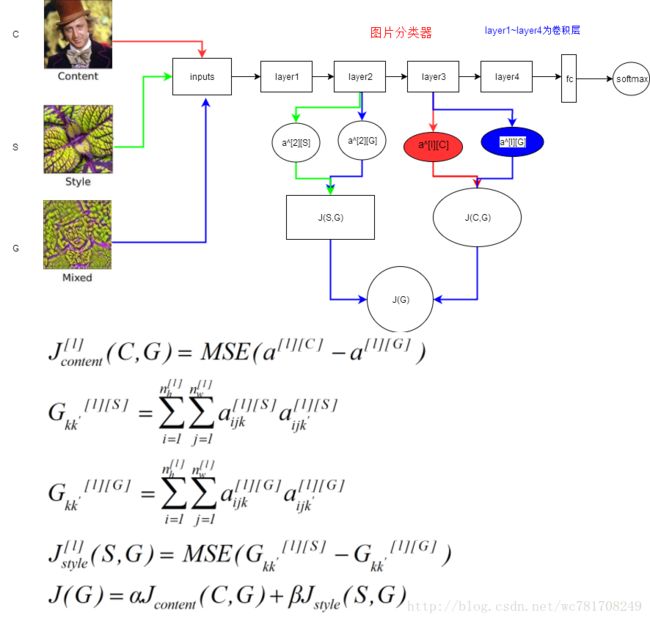
4.8 代价函数


4.9 内容代价函数

4.10 风格损失函数


流程图
参考:https://zhuanlan.zhihu.com/p/27697553