PyTorch自然语言处理入门与实战 | 文末赠书
文末赠书
注:本文选自人民邮电出版社出版的《PyTorch自然语言处理入门与实战》一书,略有改动。经出版社授权刊登于此。
处理中文与英文的一个显著区别是中文的词之间缺乏明确的分隔符。分词是中文自然语言处理中的一个重要问题,但是分词本身也是困难的,同样面临着自然语言处理的基本问题,如歧义、未识别词等。
本内容主要涉及的知识点有:
中文分词概述。
分词方法的原理。
使用第三方工具分词。
01 中文分词
中文分词的困难主要是因为自然语言的多样性。首先,分词可能没有标准答案,对于某些句子不同的人可能会有不同的分词方法,且都有合理性。其次,合理的分词可能需要一些额外的知识,如常识或者语境。最后,句子可能本身有歧义,不同的分词会产生不同的意义。
中文的语言结构
中文的语言结构可大致分为字、语素、词、句子、篇章这几个层次。如果再细究,字还可以划分为部首、笔画或者读音方面的音节。我们主要看字、语素和词。
语素就是有具体意义的最小的语言单元,很多汉字都有自身的意义,它们本身就是语素。例如“自然”是一个语素,不能拆分,“自”和“然”分开就不再具有原来的意义了;还有很多由一个字构成的语素,如“家”“人”本身就有明确意义。
可以把语素组合起来构成词语,如上面提到的“家”和“人”一起组成“家人”,这是两个语素的意义的融合。通过一些规则来组合语素可以构成大量词。中文有多种多样的构词法,这实际上给按照词表分词的方法带来了困难。因为难以用一个词表包含可能出现的所有词语。
未收录词
用词表匹配的方式分词简单且高效,但问题是无法构造一个包含所有可能出现的词语的词表。词的总量始终在增加,总有新的概念和词语出现,比如语言新的流行用法,以及人名、地名和其他的实体名(如新成立的公司的名字)等。
还有一些习惯用法,如表达“吃饭”,我们可以说“我现在去吃饭”,也可以说“我现在去吃个饭”,还可以说“我这就去吃了个饭”。在问句里可以说“你去不去吃饭?”,或者“你吃不吃饭?”。“吃个饭”“跑个步”“打个球”这类词语都是变化而来的。
歧义
即使有了比较完善的词表,分词还受到歧义问题的影响,同一个位置可能匹配多个词。
中国古文中原本没有标点。文言文中常会看到一些没有意义的语气词,可以用于帮助断句。但是实际上有很多古文的断句至今仍有争议。
比如“下雨天留客天留我不留”这句话,不同的分词方法就有不同的意义。如:下雨天/留客/天留/我不留,意思就是“下雨天要留下客人,天想留客,但我却不要留”;下雨天/留客天/留我不/留,意思就变成了“下雨的天也是留客人的天,要留我吗?留啊!”
这个例子比较夸张,通过特地挑选的词语构造出一个有明显歧义的句子,类似的例子还有很多,而且实际上我们生活中遇到的很多句子在分词上都可能产生歧义。歧义可以通过经验来解决,有一些歧义虽然语义能讲通,但是可能不合逻辑或者与事实不符,又或者和上下文语境冲突,所以人可以排除掉这些歧义。这就说明了想要排除歧义,仅仅通过句子本身是不够的,往往需要上下文、生活常识等。
02 分词原理
中文分词很困难,但是对于语言的处理有很大意义,虽然第5章中介绍的例子并没有分词,但是一般来说如果采用合适的分词方法,可以在自然语言处理任务上取得更好的效果。
基于词典匹配的分词
这个方法比较简单,执行效率高。具体的方法就是按一定顺序扫描语料,同时在词典中查询当前的文字是否构成一个词语,如果构成则把这个词语切分出来。显然,该方法有两个关键点:词典,匹配规则。
词典容易理解,就是把可能出现的词语放到一个数据结构中,等待和语料的比较。例如,可以定义如下词表:{“今天”, “学习”, “天天”, “天气”, “钢铁”, “钢铁厂”, “我们”, “塑钢”}。词表可能需要手工标注给出。
按照匹配规则可分为以下三种具体的算法。
1.最大正向匹配
从开头扫描语料,并匹配词典,遇到最长的匹配时停止匹配[海1] 。例如采用上面定义的词表,使用最大正向匹配给“今天我们参观钢铁厂的车间”这句话分词,得到的结果将是:今天/我们/参观/钢铁厂/的/车/间。
这里算法先匹配到了“钢铁”,然后会尝试匹配“钢铁厂”,发现钢铁厂也在词表中。然后则继续匹配“钢铁厂的”,发现这个词不在词表中,那么则把找到的最长结果“钢铁厂”而不是最早匹配到的“钢铁”切分出来。
如果不用最大匹配而使用最小匹配,即一发现这个词就立刻切分,则这个词表中的钢铁厂永远都不会用到。
另外,这个例子中“车间”也是一个词语,但是词表中没有收录,所以无法正确地切分出来。切分的效果跟词表有很大关系。
同样地,要给句子“今天天气很好”分词,结果为:今天/天气/很/好。虽然“天天”也在词表中,但是不会被匹配,因为匹配到“今天”之后,就从“天气”开始继续匹配了,算法不会查找“天天”是否在词表中。
2. 最大逆向匹配
与最大正向匹配类似,只是扫描的方向是从后向前,在某些情况下会给出与最大正向匹配不同的结果,如“台塑钢铁厂”,台塑是钢铁厂的名字。还是用最初的词表,最大正向匹配的结果为:台/塑钢/铁/厂;最大逆向匹配则得到一个更合理的结果:台/塑/钢铁厂。
3. 双向最大匹配
结合前面两种方法做匹配。这样可以通过两种匹配方式得到结果中的不同之处发现分词的歧义。
4. 最小切分法
这种方法要求句子切分结果是按照词典匹配后切分数量[海2] 最少的一种[海3] 情况。这样可以保证尽量多的匹配词典中的词汇。因为无论是正向匹配还是逆向匹配,都有可能把正常的词切开从而导致一些词语无法被匹配到。
基于概率的分词
这种方法不依赖于词典。但是需要从给定的语料中学习词语的统计关系。这种方法的思想是比较不同分词方法可能出现的概率。这个概率则根据最初给定的语料计算来估计。目标就是找到一种概率最高的分法,就认为这种分发是最佳的分词。这种方法的好处是可以结合整个句子的字符共同计算概率。
例如,有一个包含很多文字、经过人工分词之后的语料,可以先统计采用不同分词方法后词语共同出现的频率[海1] 。之后再给定待分词的语料,枚举可能的分词结果,根据之前统计的频率来估算这种分词结果出现的概率,并选择出现概率最高的分词结果作为最终结果。
例如,句子“并广泛动员社会各方面的力量”,可以先根据一个词表找出几种可能的分词方法:
['并', '广泛', '动员', '社会', '各', '方面', '的', '力量']
['并', '广泛', '动员', '社会', '各方', '面', '的', '力量']
['并', '广泛', '动员', '社会', '各方', '面的', '力量']
然后可以根据这些词语共同出现的频率找到最可能的情况,选择一个最终结果。
利用该方法分词的示例代码如下。
#!/usr/bin/env python3
import sys
import os
import time
class TextSpliter(object):
def __init__(self, corpus_path, encoding='utf8', max_load_word_length=4):
self.dict = {}
self.dict2 = {}
self.max_word_length = 1
begin_time = time.time()
print('start load corpus from %s' % corpus_path)
# 加载语料
with open(corpus_path, 'r', encoding=encoding) as f:
for l in f:
l.replace('[', '')
l.replace(']', '')
wds = l.strip().split(' ')
last_wd = ''
for i in range(1, len(wds)): # 下标从1开始,因为每行第一个词是标签
try:
wd, wtype = wds[i].split('/')
except:
continue
if len(wd) == 0 or len(wd) > max_load_word_length or not wd.isalpha():
continue
if wd not in self.dict:
self.dict[wd] = 0
if len(wd) > self.max_word_length:
# 更新最大词长度
self.max_word_length = len(wd)
print('max_word_length=%d, word is %s' %(self.max_word_length, wd))
self.dict[wd] += 1
if last_wd:
if last_wd+':'+wd not in self.dict2:
self.dict2[last_wd+':'+wd] = 0
self.dict2[last_wd+':'+wd] += 1
last_wd = wd
self.words_cnt = 0
max_c = 0
for wd in self.dict:
self.words_cnt += self.dict[wd]
if self.dict[wd] > max_c:
max_c = self.dict[wd]
self.words2_cnt = sum(self.dict2.values())
print('load corpus finished, %d words in dict and frequency is %d, %d words in dict2 frequency is %d' % (len(self.dict),len(self.dict2), self.words_cnt, self.words2_cnt), 'msg')
print('%f seconds elapsed' % (time.time()-begin_time), 'msg')
def split(self, text):
sentence = ''
result = ''
for ch in text:
if not ch.isalpha():
result += self.__split_sentence__(sentence) + ' ' + ch + ' '
sentence = ''
else:
sentence += ch
return result.strip(' ')
def __get_a_split__(self, cur_split, i):
if i >= len(self.cur_sentence):
self.split_set.append(cur_split)
return
j = min(self.max_word_length, len(self.cur_sentence) - i + 1)
while j > 0:
if j == 1 or self.cur_sentence[i:i+j] in self.dict:
self.__get_a_split__(cur_split + [self.cur_sentence[i:i+j]], i+j)
if j == 2:
break
j -= 1
def __get_cnt__(self, dictx, key):
# 获取出现次数
try:
return dictx[key] + 1
except KeyError:
return 1
def __get_word_probablity__(self, wd, pioneer=''):
if pioneer == '':
return self.__get_cnt__(self.dict, wd) / self.words_cnt
return self.__get_cnt__(self.dict2, pioneer + ':' + wd) / self.__get_cnt__(self.dict, pioneer)
def __calc_probability__(self, sequence):
probability = 1
pioneer = ''
for wd in sequence:
probability *= self.__get_word_probablity__(wd, pioneer)
pioneer = wd
return probability
def __split_sentence__(self, sentence):
if len(sentence) == 0:
return ''
self.cur_sentence = sentence.strip()
self.split_set = []
self.__get_a_split__([], 0)
print(sentence + str(len(self.split_set)))
max_probability = 0
for splitx in self.split_set:
probability = self.__calc_probability__(splitx) # 计算概率
print(str(splitx)+ ' - ' +str(probability))
if probability > max_probability: # 测试是否超过当前记录的最高概率
max_probability = probability
best_split = splitx
return ' '.join(best_split) # 把list 拼接为字符串
if __name__ == '__main__':
btime = time.time()
base_path = os.path.dirname(os.path.realpath(__file__))
spliter = TextSpliter(os.path.join(base_path, '199801.txt'))
with open(os.path.join(base_path, 'test.txt'), 'r', encoding='utf8') as f:
with open(os.path.join(base_path, 'result.txt',), 'w', encoding='utf8') as fr:
for l in f:
fr.write(spliter.split(l))
print ('time elapsed %f' % (time.time() - btime))基于机器学习的分词
这种方法的缺点是需要标注好的语料做训练数据训练分词模型。模型可以对每个字符输出标注,表示这个字符是否是新的词语的开始。例如下面介绍到的结巴分词工具就使用了双向GRU模型做分词。
03 使用第三方工具分词
上一节给出了分词的基本方法,这些基本的方法在实际应用中往往不能取得最好的效果,可以简单地借助一些第三方工具完成分词任务。
S-MSRSeg
S-MSRSeg是微软亚洲研究院自然计算语言计算组(Natural Language Computing Group)开发并于2004年发布的中文分词工具,是MSRSeg的简化版本,S-MSRSeg没有提供新词识别等功能。
S-MSRSeg不是开源软件,但是可免费下载,下载地址为https://www.microsoft.com/en-us/download/details.aspx?id=52522。
下载并解压后需要建立一个data文件夹,把“lexicon.txt”“ln.bbo”“neaffix.txt”“neitem.txt”“on.bbo”“peinfo.txt”“pn.bbo”“proto.tbo”“table.bin”文件放入该文件夹中。然后把要分词的文件放入一个文本文件中,比如新建一个test.txt文件,但是这个文件需要使用GBK编码,如果使用UTF8编码则会导致无法识别。比如写入以下几个句子。
并广泛动员社会各方面的力量
今天我们参观台塑钢铁厂的车间
今天天气很好
我这会先去吃个饭然后在当前文件夹下打开cmd窗口,输入命令“s-msrseg.exe test.txt”开始分词,结果如图1所示。
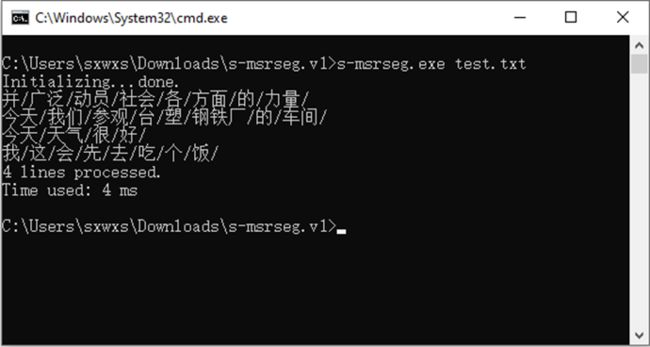
图1 S-MSRSeg输出的结果
压缩包内的“msr.gold.1k.txt”文件是1千句已经手工分词的中文句子,而“msr.raw.1k.txt”则是没有分词的句子。
“cl-05.gao.pdf”是详细介绍该工具原理的论文Chinese Word Segmentation and Named Entity Recognition: A Pragmatic Approach。
注意:保存文本文件时需要手动选择编码为GBK或ANSI,否则工具无法正常识别文本,可能会出现乱码。
ICTCLAS
ICTCLAS是中科院开发的开源的汉语分词系统,官方网站是http://ictclas.nlpir.org/,代码仓库地址为https://github.com/NLPIR-team/NLPIR,而ICTCLAS的源码位于https://github.com/NLPIR-team/nlpir-analysis-cn-ictclas。
因为该工具使用Java开发,可以直接下载打包好的jar文件。源码仓库中有使用说明和代码示例。
结巴分词
这是使用Python开发的开源中文分词工具,代码仓库地址为:https://github.com/fxsjy/jieba。
可使用pip命令安装:pip install jieba。
结巴分词支持四种模式:精确模式,可以实现较高精度的分词,有解决歧义的功能;全模式,可以把句子中所有词语都扫描出来,但是不解决歧义,这种模式的优点是速度快;搜索引擎模式,可以在精确模式的基础上对长词再切分,有利于搜索引擎的匹配;paddle模式,使用百度的飞桨框架实现的基于机器学习的分词,并可以标注词语的词性。
基本的使用方法如下。
import jieba
print('/'.join(list(jieba.cut("并广泛动员社会各方面的力量"))))jieba.cut是用于分词的函数,返回的是一个生成器,可以使用list构造器把生成器转换为list,然后使用join方法合成一个字符串便于展示,上面代码执行的结果如下。
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\sxwxs\AppData\Local\Temp\jieba.cache
Loading model cost 0.969 seconds.
Prefix dict has been built successfully.
'并/广泛/动员/社会/各/方面/的/力量'pkuseg
使用pkuseg默认配置进行分词的代码如下。
import pkuseg
seg = pkuseg.pkuseg() # 以默认配置加载模型
text = seg.cut('并广泛动员社会各方面的力量') # 进行分词
print(text)输出的结果如下。
['并', '广泛', '动员', '社会', '各', '方面', '的', '力量']还可以开启词性标注模式。
import pkuseg
seg = pkuseg.pkuseg(postag=True) # 开启词性标注功能
text = seg.cut('并广泛动员社会各方面的力量') # 进行分词和词性标注
print(text)输出的结果如下。
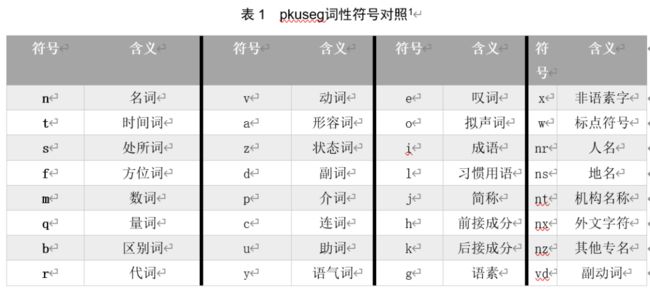
[('并', 'c'), ('广泛', 'ad'), ('动员', 'v'), ('社会', 'n'), ('各', 'r'), ('方面', 'n'), ('的', 'u'), ('力量', 'n')]pkuseg词性符号的对应关系如表1所示。
另外还可以通过pkuseg方法的model_name参数指定特定领域的模型。该方法的可选参数如表2所示。

使用词性分析或者其他一些参数可能需要额外下载模型,会在需要时自动下载。或者可以到项目的Releas 页面下载:https://github.com/lancopku/pkuseg-python/releases。
送书福利
送书方式:关注下面视频号,然后在微信公众号「Python数据之道」的本文文末留言,选取精心留言的 3 位同学,赠送《PyTorch自然语言处理入门与实践》,书籍由「出版社」赞助。
留言内容:学习Python的心得,以及与本文内容相关即可
截止时间:2022年12月17日20:00,结果公布后24小时内未与我联系视为放弃。
送书规则:
1. 截止时间前关注上面视频号+公众号文末留言;
2. 从留言中选出获奖同学,获得本次的书籍;每人限得一本。
3. 建议参与本次活动的读者在截止时间前添加阳哥的微信(公号后台回复“w”添加)好友,以防找不到人!
4. 我会在截止时间或之后在本文留言区公告赠书结果,请大家留意。
5. 没有意义的留言不会被选中(例如我想要书,求点赞等)