大数据之Hadoop简介及环境搭建
第1章 大数据概论
1.1 大数据概念
大数据(Big Data):指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
主要解决,海量数据的存储和海量数据的分析计算问题。
按顺序给出数据存储单位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB。
1Byte = 8bit 1K = 1024Byte 1MB = 1024K
1G = 1024M 1T = 1024G 1P = 1024T
1.2 大数据特点(4V)
1、Volume(大量)
截至目前,人类生产的所有印刷材料的数据量是200PB,而历史上全人类总共说过的话的数据量大约是5EB。当前,典型个人计算机硬盘的容量为TB量级,而一些大企业的数据量已经接近EB量级。
2、Velocity(高速)
这是大数据区分于传统数据挖掘的最显著特征。在海量的数据面前,处理数据的效率就是企业的生命。
3、Variety(多样)
这种类型的多样性也让数据被分为结构化数据和非结构化数据。相对于以往便于存储的以数据库/文本为主的结构化数据,非结构化数据越来越多,包括网络日志、音频、视频、图片、地理位置信息等,这些多类型的数据对数据的处理能力提出了更高要求。
4、Value(低价值密度)
价值密度的高低与数据总量的大小成反比。如何快速对有价值数据“提纯”成为目前大数据背景下待解决的难题。
1.3 大数据应用场景
1、物流仓储:大数据分析系统助力商家精细化运营、提升销量、节约成本。
2、零售:分析用户消费习惯,为用户购买商品提供方便,从而提升商品销量。经典案例,子尿布+啤酒。
3、旅游:深度结合大数据能力与旅游行业需求,共建旅游产业智慧管理、智慧服务和智慧营销的未来。

4、商品广告推荐:给用户推荐可能喜欢的商品
5、保险:海量数据挖掘及风险预测,助力保险行业精准营销,提升精细化定价能力。
6、金融:多维度体现用户特征,帮助金融机构推荐优质客户,防范欺诈风险。
7、房产:大数据全面助力房地产行业,打造精准投策与营销,选出更合适的地,建造更合适的楼,卖给更合适的人。
8、人工智能
1.4 大数据部门业务流程分析
产品人员提需求(统计总用户数、日活跃用户数、回流用户数等)--> 数据部门搭建数据平台、分析数据指标 --> 数据可视化(报表展示、邮件发送、大屏幕展示等)
1.5 大数据部门常见组织结构

第2章 Hadoop大数据生态
2.1 Hadoop是什么
1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
2.2 Hadoop发展历史
1)Lucene框架是Doug Cutting开创的开源软件,用Java书写代码,实现与Google类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎。
2)2001年年底Lucene成为Apache基金会的一个子项目。
3)对于海量数据的场景,Lucene面对与Google同样的困难,存储数据困难,检索速度慢。
4)学习和模仿Google解决这些问题的办法 :微型版Nutch。
5)可以说Google是Hadoop的思想之源(Google在大数据方面的三篇论文)
GFS --->HDFS Map-Reduce --->MR BigTable --->HBase
6)2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。
7)2005 年Hadoop 作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。
8)2006 年 3 月份,Map-Reduce和Nutch Distributed File System (NDFS) 分别被纳入到 Hadoop 项目中,Hadoop就此正式诞生,标志着大数据时代来临。
9)名字来源于Doug Cutting儿子的玩具大象。
2.3 Hadoop三大发行版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
Hortonworks文档较好。
1.Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/
2.Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
(1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
(5)Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
2.Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
(1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。 (4)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(5)HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。 (6)Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
2.4 Hadoop的优势(4高)
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:能够自动将失败的任务重新分配。
2.5 Hadoop组成
Hadoop1.x和Hadoop2.x区别

2.5.1 HDFS架构概述
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
2.5.2 YARN架构概述

2.5.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
2.6 大数据技术生态体系
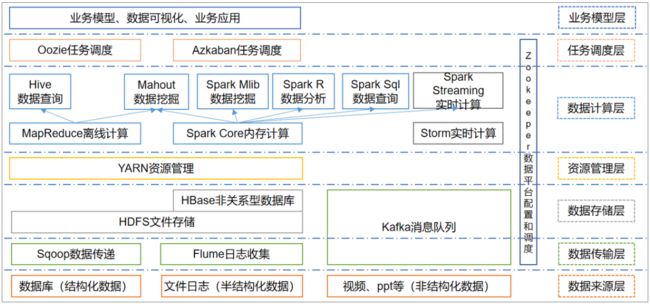
1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
(a)通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
(b)高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
(c)支持通过Kafka服务器和消费机集群来分区消息。
(d)支持Hadoop并行数据加载。
4)Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
5)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
6)Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
10)R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
11)Mahout:Apache Mahout是个可扩展的机器学习和数据挖掘库。
12)ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
2.7 推荐系统框架图

第3章 Hadoop运行环境搭建
3.1 虚拟机环境准备
基本环境:
hostname: hadoop101
ip: 192.168.56.101
user: hadoop # 配置sudo权限
关闭firewalld
sudo systemctl stop firewalld
关闭NetworkManager
sudo systemctl stop NetworkManager
name: 关闭selinux
sudo setenforce 0
sudo sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
在/opt目录下创建文件夹
(1)在/opt目录下创建modules、softwares、datas文件夹
[hadoop@hadoop101 opt]$ sudo mkdir modules
[hadoop@hadoop101 opt]$ sudo mkdir softwares
[hadoop@hadoop101 opt]$ sudo mkdir datas
(2)修改modules、softwares文件夹的所有者
[hadoop@hadoop101 opt]$ sudo chown hadoop:hadoop modules/ softwares/ datas/
[hadoop@hadoop101 opt]$ ll
total 3
drwxr-xr-x 2 hadoop hadoop 4096 Oct 11 20:09 datas
drwxr-xr-x. 2 hadoop hadoop 4096 Oct 11 20:09 modules
drwxr-xr-x. 2 hadoop hadoop 4096 Oct 11 20:09 softwares
3.2 安装JDK
1、将jdk安装包上传到/opt/softwares目录
[hadoop@hadoop101 opt]$ ls softwares/
jdk-8u144-linux-x64.tar.gz logstash-6.3.1.tar.gz
2、 解压JDK到/opt/module目录下
[hadoop@hadoop101 softwares]$ tar -xvf /opt/softwares/jdk-8u144-linux-x64.tar.gz -C /opt/modules/
3、配置JDK环境变量
(1)先获取JDK路径
[hadoop@hadoop101 jdk1.8.0_144]$ pwd
/opt/modules/jdk1.8.0_144
(2)打开/etc/profile文件
[hadoop@hadoop101 jdk1.8.0_144]$ sudo vim /etc/profile
(3)在profile文件末尾添加JDK路径
# JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
(4)保存后退出
:wq
(5)让修改后的文件生效
[hadoop@hadoop101 jdk1.8.0_144]$ source /etc/profile
4、测试JDK是否安装成功
[hadoop@hadoop101 jdk1.8.0_144]$ java -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
3.3 安装Hadoop
1、Hadoop下载地址:
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
2、将hadoop安装包hadoop-2.7.2.tar.gz上传到/opt/softwares
[hadoop@hadoop101 softwares]$ ls
hadoop-2.7.2.tar.gz
3、进入/opt/softwares,将hadoop-2.7.2.tar.gz解压到/opt/modules目录
[hadoop@hadoop101 softwares]$ tar -xvf hadoop-2.7.2.tar.gz -C /opt/modules/
4、检查是否解压成功
[hadoop@hadoop101 softwares]$ ls /opt/modules/
hadoop-2.7.2 jdk1.8.0_144
5、将Hadoop添加到环境变量
(1)获取Hadoop安装路径
[hadoop@hadoop101 hadoop-2.7.2]$ pwd
/opt/modules/hadoop-2.7.2
(2)打开/etc/profile文件
[hadoop@hadoop101 hadoop-2.7.2]$ sudo vim /etc/profile
在profile文件末尾添加JDK路径:(shitf+g)
# HADOOP_HOME
export HADOOP_HOME=/opt/modules/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
(3)保存后退出
:wq
(4)让修改后的文件生效
[hadoop@hadoop101 hadoop-2.7.2]$ source /etc/profile
- 测试是否安装成功
[hadoop@hadoop101 hadoop-2.7.2]$ hadoop version
Hadoop 2.7.2
3.4 Hadoop目录结构
1、查看Hadoop目录结构
[hadoop@hadoop101 hadoop-2.7.2]$ ll
total 28
drwxr-xr-x 2 hadoop hadoop 194 May 22 2017 bin
drwxr-xr-x 3 hadoop hadoop 20 May 22 2017 etc
drwxr-xr-x 2 hadoop hadoop 106 May 22 2017 include
drwxr-xr-x 3 hadoop hadoop 20 May 22 2017 lib
drwxr-xr-x 2 hadoop hadoop 239 May 22 2017 libexec
-rw-r--r-- 1 hadoop hadoop 15429 May 22 2017 LICENSE.txt
-rw-r--r-- 1 hadoop hadoop 101 May 22 2017 NOTICE.txt
-rw-r--r-- 1 hadoop hadoop 1366 May 22 2017 README.txt
drwxr-xr-x 2 hadoop hadoop 4096 May 22 2017 sbin
drwxr-xr-x 4 hadoop hadoop 31 May 22 2017 share
2、重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
第4章 Hadoop运行模式
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop官方网站:http://hadoop.apache.org/
4.1 本地运行模式
4.1.1 官方Grep案例
- 创建在hadoop-2.7.2文件下面创建一个input文件夹
[hadoop@hadoop101 hadoop-2.7.2]$ mkdir input
- 将Hadoop的xml配置文件复制到input
[hadoop@hadoop101 hadoop-2.7.2]$ cp etc/hadoop/*.xml input
[hadoop@hadoop101 hadoop-2.7.2]$ ll input
total 48
-rw-r--r-- 1 hadoop hadoop 4436 Nov 7 19:40 capacity-scheduler.xml
-rw-r--r-- 1 hadoop hadoop 774 Nov 7 19:40 core-site.xml
-rw-r--r-- 1 hadoop hadoop 9683 Nov 7 19:40 hadoop-policy.xml
-rw-r--r-- 1 hadoop hadoop 775 Nov 7 19:40 hdfs-site.xml
-rw-r--r-- 1 hadoop hadoop 620 Nov 7 19:40 httpfs-site.xml
-rw-r--r-- 1 hadoop hadoop 3518 Nov 7 19:40 kms-acls.xml
-rw-r--r-- 1 hadoop hadoop 5511 Nov 7 19:40 kms-site.xml
-rw-r--r-- 1 hadoop hadoop 690 Nov 7 19:40 yarn-site.xml
- 执行share目录下的MapReduce程序
[hadoop@hadoop101 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
- 查看输出结果
[hadoop@hadoop101 hadoop-2.7.2]$ cat output/*
1 dfsadmin
4.1.2 官方WordCount案例
- 创建在hadoop-2.7.2文件下面创建一个wcinput文件夹
[hadoop@hadoop101 hadoop-2.7.2]$ mkdir wcinput
- 在wcinput文件下创建一个wc.input文件并写入以下文件
[hadoop@hadoop101 hadoop-2.7.2]$ cd wcinput/
[hadoop@hadoop101 wcinput]$ vim wc.input
[hadoop@hadoop101 wcinput]$ cat wc.input
hello world
hello java
hello big data
hello scala
spark hello world
python hello world
hadoop hdfs
map reduce
hello hadoop
保存退出:
:wq
- 回到Hadoop目录/opt/modules/hadoop-2.7.2执行程序
[hadoop@hadoop101 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
- 查看结果
[hadoop@hadoop101 hadoop-2.7.2]$ cat wcoutput/*
big 1
data 1
hadoop 2
hdfs 1
hello 7
java 1
map 1
python 1
reduce 1
scala 1
spark 1
world 3
4.2 伪分布式运行模式
4.2.1 启动HDFS并运行MapReduce程序
- 分析
(1)配置集群
(2)启动、测试集群增、删、查
(3)执行WordCount案例
- 执行步骤
(1)配置集群
(a)配置:hadoop-env.sh
Linux系统中获取JDK的安装路径:
[hadoop@hadoop101 hadoop-2.7.2]$ echo $JAVA_HOME
/opt/modules/jdk1.8.0_144
修改JAVA_HOME 路径:
export JAVA_HOME=/opt/modules/jdk1.8.0_144
(b)配置:core-site.xml
fs.defaultFS
hdfs://hadoop101:9000
hadoop.tmp.dir
/opt/modules/hadoop-2.7.2/datas/tmp
(c)配置:hdfs-site.xml
dfs.replication
1
(2)启动集群
(a)格式化NameNode(第一次启动时格式化,之后不需要格式化)
[hadoop@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format
# 下面这行代表格式成功
21/11/07 20:13:24 INFO common.Storage: Storage directory /opt/modules/hadoop-2.7.2/datas/tmp/dfs/name has been successfully formatted.
(b)启动NameNode
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/modules/hadoop-2.7.2/logs/hadoop-hadoop-namenode-hadoop101.out
(c)启动DataNode
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/modules/hadoop-2.7.2/logs/hadoop-hadoop-datanode-hadoop101.out
(3)查看集群
(a)查看是否启动成功
[hadoop@hadoop101 hadoop-2.7.2]$ jps | grep -v Jps
2528 DataNode
2403 NameNode
(b)web端查看HDFS文件系统
windows配置hosts
192.168.56.101 hadoop101
http://hadoop101:50070/dfshealth.html#tab-overview
(c)查看产生的Log日志
日志目录:/opt/modules/hadoop-2.7.2/logs
[hadoop@hadoop101 logs]$ ll
total 60
-rw-rw-r-- 1 hadoop hadoop 24108 Nov 7 20:16 hadoop-hadoop-datanode-hadoop101.log
-rw-rw-r-- 1 hadoop hadoop 718 Nov 7 20:15 hadoop-hadoop-datanode-hadoop101.out
-rw-rw-r-- 1 hadoop hadoop 27709 Nov 7 20:16 hadoop-hadoop-namenode-hadoop101.log
-rw-rw-r-- 1 hadoop hadoop 718 Nov 7 20:14 hadoop-hadoop-namenode-hadoop101.out
-rw-rw-r-- 1 hadoop hadoop 0 Nov 7 20:14 SecurityAuth-hadoop.audit
(d)查看集群信息
[hadoop@hadoop101 current]$ pwd
/opt/modules/hadoop-2.7.2/datas/tmp/dfs/name/current
[hadoop@hadoop101 current]$ cat VERSION
#Sun Nov 07 20:13:24 CST 2021
namespaceID=1202142462
clusterID=CID-6415cfba-4e8a-46ec-bdcf-0bd815e665d7
cTime=0
storageType=NAME_NODE
blockpoolID=BP-1930525962-192.168.56.101-1636287204165
layoutVersion=-63
[hadoop@hadoop101 current]$ pwd
/opt/modules/hadoop-2.7.2/datas/tmp/dfs/data/current
[hadoop@hadoop101 current]$ cat VERSION
#Sun Nov 07 20:16:00 CST 2021
storageID=DS-9a007717-2d15-4f5e-8b7b-796a1fb06f09
clusterID=CID-6415cfba-4e8a-46ec-bdcf-0bd815e665d7
cTime=0
datanodeUuid=90ed98e8-1f45-4f22-a6e2-e78b810c418d
storageType=DATA_NODE
layoutVersion=-56
注意:重新格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
(4)操作集群
(a)在HDFS文件系统上创建一个input文件夹
[hadoop@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -mkdir -p /user/hadoop/input
(b)将测试文件内容上传到文件系统上
[hadoop@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -put wcinput/wc.input /user/hadoop/input
(c)查看上传的文件是否正确
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -ls /user/hadoop/input
Found 1 items
-rw-r--r-- 1 hadoop supergroup 123 2021-11-07 20:35 /user/hadoop/input/wc.input
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -cat /user/hadoop/input/wc.input
hello world
hello java
hello big data
hello scala
spark hello world
python hello world
hadoop hdfs
map reduce
hello hadoop
(d)运行MapReduce程序
[hadoop@hadoop101 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/hadoop/input /user/hadoop/output
(e)查看输出结果
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -cat /user/hadoop/output/*
big 1
data 1
hadoop 2
hdfs 1
hello 7
java 1
map 1
python 1
reduce 1
scala 1
spark 1
world 3
(f)将测试文件内容下载到本地
[hadoop@hadoop101 hadoop-2.7.2]$ rm -rf wcoutput/*
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -get /user/hadoop/output/part-r-00000 ./wcoutput/
(g)删除输出结果
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -rm -r /user/hadoop/output
4.2.2 启动YARN并运行MapReduce程序
- 分析
(1)配置集群在YARN上运行MR
(2)启动、测试集群增、删、查
(3)在YARN上执行WordCount案例
- 执行步骤
(1)配置集群
(a)配置yarn-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.8.0_144
(b)配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop101
(c)配置:mapred-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.8.0_144
(d)配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
[hadoop@hadoop101 hadoop]$ mv mapred-site.xml.template mapred-site.xml
[hadoop@hadoop101 hadoop]$ vim mapred-site.xml
mapreduce.framework.name
yarn
(2)启动集群
(a)启动前必须保证NameNode和DataNode已经启动
[hadoop@hadoop101 hadoop-2.7.2]$ jps | grep -v Jps
2528 DataNode
2403 NameNode
(b)启动ResourceManager
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/modules/hadoop-2.7.2/logs/yarn-hadoop-resourcemanager-hadoop101.out
(c)启动NodeManager
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/modules/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-hadoop101.out
(d)查看是否启动成功
[hadoop@hadoop101 hadoop-2.7.2]$ jps | grep -v Jps
2528 DataNode
2403 NameNode
3484 ResourceManager
3725 NodeManager
(3)集群操作
(a)YARN的浏览器页面查看
(b)删除文件系统上的output文件
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -rm -r /user/hadoop/output
(c)执行MapReduce程序
[hadoop@hadoop101 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/hadoop/input /user/hadoop/output
(d)查看运行结果
4.2.3 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
- 配置mapred-site.xml,在文件中添加如下内容:
mapreduce.jobhistory.address
hadoop101:10020
mapreduce.jobhistory.webapp.address
hadoop101:19888
- 启动历史服务器
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/modules/hadoop-2.7.2/logs/mapred-hadoop-historyserver-hadoop101.out
- 查看历史服务器是否启动
[hadoop@hadoop101 hadoop-2.7.2]$ jps | grep -v Jps
2528 DataNode
2403 NameNode
4311 JobHistoryServer
3484 ResourceManager
3725 NodeManager
- 查看JobHistory:http://hadoop101:19888/jobhistory
4.2.4 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
- 配置yarn-site.xml,在该文件里面增加如下配置
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
- 关闭NodeManager 、ResourceManager和HistoryServer
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
stopping nodemanager
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop resourcemanager
stopping resourcemanager
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh stop historyserver
stopping historyserver
[hadoop@hadoop101 hadoop-2.7.2]$ jps | grep -v Jps
2528 DataNode
2403 NameNode
- 启动NodeManager 、ResourceManager和HistoryServer
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/modules/hadoop-2.7.2/logs/yarn-hadoop-resourcemanager-hadoop101.out
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/modules/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-hadoop101.out
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/modules/hadoop-2.7.2/logs/mapred-hadoop-historyserver-hadoop101.out
[hadoop@hadoop101 hadoop-2.7.2]$ jps | grep -v Jps
2528 DataNode
2403 NameNode
4533 ResourceManager
4934 JobHistoryServer
4778 NodeManager
- 删除HDFS上已经存在的输出文件
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -rm -r /user/hadoop/output
- 执行WordCount程序
[hadoop@hadoop101 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/hadoop/input /user/hadoop/output
- 查看日志
4.2.5 配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-2.7.2.jar/ core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-2.7.2.jar/ hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-2.7.2.jar/ yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-2.7.2.jar/ mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个目录下,用户可以根据项目需求重新进行修改配置。
4.3 完全分布式运行模式
4.3.1 编写集群分发脚本xsync
为方便不同主机之间的文件拷贝,编写一个xsync同步脚本
- rsync 远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
(1)基本语法
rsync -av $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
选项参数说明
| 选项 | 功能 |
|---|---|
| -a | 归档拷贝 |
| -v | 显示复制过程 |
(2)案例实操
(a)把hadoop101机器上的/opt/softwares目录同步到hadoop102服务器的root用户下的/opt/目录
[hadoop@hadoop101 softwares]$ rsync -av /opt/softwares/ hadoop102:/opt/softwares/
sending incremental file list
./
hadoop-2.7.2.tar.gz
jdk-8u144-linux-x64.tar.gz
sent 383,267,298 bytes received 57 bytes 85,170,523.33 bytes/sec
total size is 383,173,529 speedup is 1.00
- 编写xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -av /opt/modules hadoop@hadoop102:/opt/
(b)期望脚本:
xsync 要同步的文件名称
(c)说明:在/home/hadoop/bin目录下存放的脚本,hadoop用户可以在系统任何地方直接执行。
(3)脚本实现
(a)在/home/hadoop目录下创建bin目录,并在bin目录下创建xsync文件,文件内容如下:
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if ((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=101; host<104; host++)); do
echo ------------------- hadoop$host --------------
rsync -av $pdir/$fname $user@hadoop$host:$pdir
done
(b)修改脚本 xsync 具有执行权限
[hadoop@hadoop101 bin]$ chmod +x xsync
(c)配置环境变量并使其生效
# ~/bin
export PATH=$PATH:/home/hadoop/bin
(d)测试,使用方法:xsync 目录/文件名
[hadoop@hadoop101 bin]$ xsync xsync
fname=xsync
pdir=/home/hadoop/bin
------------------- hadoop101 --------------
sending incremental file list
sent 59 bytes received 12 bytes 142.00 bytes/sec
total size is 499 speedup is 7.03
------------------- hadoop102 --------------
sending incremental file list
xsync
sent 605 bytes received 35 bytes 1,280.00 bytes/sec
total size is 499 speedup is 0.78
------------------- hadoop103 --------------
sending incremental file list
xsync
sent 605 bytes received 35 bytes 426.67 bytes/sec
total size is 499 speedup is 0.78
4.3.2 集群配置
- 集群部署规划
| hadoop101 | hadoop102 | hadoop103 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
- 删除之前在hadoop101上部署的伪分布式hadoop,并重新解压到/opt/modules目录下
# 删除之前配置的hadoop
rm -rf hadoop-2.7.2/
# 重新解压hadoop到/opt/modules
tar -xvf hadoop-2.7.2.tar.gz -C /opt/modules/
- 配置集群
(1)核心配置文件
配置core-site.xml
[hadoop@hadoop101 hadoop]$ vi core-site.xml
在该文件中编写如下配置
fs.defaultFS
hdfs://hadoop101:9000
hadoop.tmp.dir
/opt/modules/hadoop-2.7.2/datas/tmp
(2)HDFS配置文件
配置hadoop-env.sh
[hadoop@hadoop101 hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_144
配置hdfs-site.xml
[hadoop@hadoop101 hadoop]$ vi hdfs-site.xml
在该文件中编写如下配置
dfs.replication
3
dfs.namenode.secondary.http-address
hadoop103:50090
(3)YARN配置文件
配置yarn-env.sh
[hadoop@hadoop101 hadoop]$ vi yarn-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_144
配置yarn-site.xml
[hadoop@hadoop101 hadoop]$ vi yarn-site.xml
在该文件中增加如下配置
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop102
(4)MapReduce配置文件
配置mapred-env.sh
[hadoop@hadoop101 hadoop]$ vi mapred-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_144
配置mapred-site.xml
[hadoop@hadoop101 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@hadoop101 hadoop]$ vi mapred-site.xml
在该文件中增加如下配置
mapreduce.framework.name
yarn
- 在集群上分发配置好的Hadoop配置文件
[hadoop@hadoop101 hadoop]$ xsync /opt/modules/hadoop-2.7.2/
- 查看文件分发情况
[hadoop@hadoop102 hadoop]$ cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
4.3.4 集群单点启动
(1)如果集群是第一次启动,需要格式化NameNode
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs namenode -format
(2)在hadoop101上启动NameNode
[hadoop@hadoop101 hadoop-2.7.2]$ hadoop-daemon.sh start namenode
[hadoop@hadoop101 modules]$ jps
2267 NameNode
(3)在hadoop101、hadoop102以及hadoop103上分别启动DataNode
[hadoop@hadoop101 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
[hadoop@hadoop101 modules]$ jps
2267 NameNode
2365 DataNode
[hadoop@hadoop102 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
[hadoop@hadoop102 hadoop-2.7.2]$ jps
3190 DataNode
[hadoop@hadoop103 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
[hadoop@hadoop103 ~]$ jps
2522 DataNode
4.3.5 SSH无密登录配置
- 配置ssh
(1)基本语法
ssh另一台电脑的ip地址
(2)ssh连接时出现Host key verification failed的解决方法
[hadoop@hadoop101 hadoop] $ ssh 192.168.1.102
The authenticity of host '192.168.1.102 (192.168.1.102)' can't be established.
RSA key fingerprint is cf:1e:de:d7:d0:4c:2d:98:60:b4:fd:ae:b1:2d:ad:06.
Are you sure you want to continue connecting (yes/no)?
Host key verification failed.
(3)解决方案如下:直接输入yes
- 无密钥配置
(1)免密登录原理
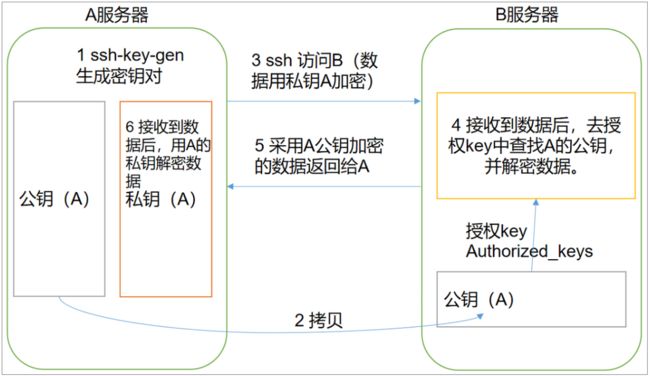
(2)生成公钥和私钥:
[hadoop@hadoop101 ~]$ ssh-keygen -t rsa
然后敲(三个回车),就会在~/.ssh目录生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(3)将公钥拷贝到要免密登录的目标机器上
[hadoop@hadoop101 ~]$ ssh-copy-id hadoop101
[hadoop@hadoop101 ~]$ ssh-copy-id hadoop102
[hadoop@hadoop101 ~]$ ssh-copy-id hadoop103
注意:
还需要在hadoop101上采用root账号,配置一下无密登录到hadoop101、hadoop102、hadoop103;
还需要在hadoop102上采用hadoop账号配置一下无密登录到hadoop101、hadoop102、hadoop103服务器上。
- .ssh文件夹下(~/.ssh)的文件功能解释
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
|---|---|
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过得无密登录服务器公钥 |
4.3.6 群起集群
- 配置slaves
/opt/modules/hadoop-2.7.2/etc/hadoop/slaves
[hadoop@hadoop102 hadoop]$ vi slaves
在该文件中增加如下内容:
hadoop101
hadoop102
hadoop103
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
[hadoop@hadoop101 hadoop]$ xsync slaves
- 启动集群
(1)如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[hadoop@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format
(2)启动HDFS
[root@hadoop101 ~]# start-dfs.sh
[hadoop@hadoop101 ~]$ jps
5648 Jps
5367 DataNode
5261 NameNode
[hadoop@hadoop102 hadoop-2.7.2]$ jps
2929 DataNode
3041 Jps
[hadoop@hadoop103 ~]$ jps
3396 SecondaryNameNode
3476 Jps
3290 DataNode
(3)启动YARN
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
(4)Web端查看SecondaryNameNode
(a)浏览器中输入:http://hadoop103:50090/status.html
(b)查看SecondaryNameNode信息
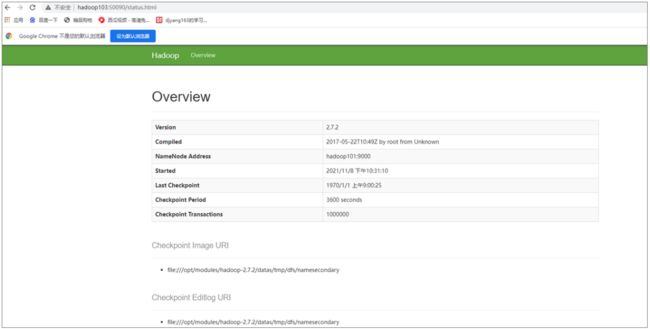
- 集群基本测试
(1)上传文件到集群
上传小文件
[hadoop@hadoop101 ~]$ hdfs dfs -mkdir -p /user/hadoop/input
[hadoop@hadoop101 ~]$ hdfs dfs -put input/wc.txt /user/hadoop/input
上传大文件
[hadoop@hadoop101 ~]$ hdfs dfs -put /opt/softwares/hadoop-2.7.2.tar.gz /user/hadoop/input
(2)上传文件后查看文件存放在什么位置
(a)查看HDFS文件存储路径
[hadoop@hadoop101 subdir0]$ pwd
/opt/modules/hadoop/datas/tmp/dfs/data/current/BP-1292485737-192.168.56.101-1636379461328/current/finalized/subdir0/subdir0
(b)查看HDFS在磁盘存储文件内容
[hadoop@hadoop101 subdir0]$ cat blk_1073741825
my name is jack yan
jack yan
jack
i like learn program course
program
hello world
hello shenzhen
(3)下载
[hadoop@hadoop101 ~]$ ls
bin input
[hadoop@hadoop101 ~]$ hdfs dfs -get /user/hadoop/input/hadoop-2.7.2.tar.gz
[hadoop@hadoop101 ~]$ ls
bin hadoop-2.7.2.tar.gz input
4.3.7 集群启动/停止方式总结
- 各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start/stop namenode/datanode/secondarynamenode
(2)启动/停止YARN
yarn-daemon.sh start/stop resourcemanager/nodemanager
- 各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh / stop-yarn.sh
4.3.8 集群时间同步
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔五分钟,同步一次时间。
![]()
在这里时间服务器搭在hadoop100机器上,hadoop集群的其他机器上安装ntp同步hadoop100上的时间
搭建服务器及时间同步的过程可参考:搭建本地时间同步服务器 - 简书