[1] Sébastien Bubeck and Nicolò Cesa-Bianchi. Regret Analysis of Stochastic and Nonstochastic Multi-armed Bandit Problems. In Foundations and Trends in Machine Learning, Vol 5: No 1, 1-122, 2012
[2] Wei Chen, Yajun Wang, and Yang Wang. Combinatorial Multi-Armed Bandit: General Framework, Results and Applications. In Proceedings of the 30th International Conference on Machine Learning (ICML'2013), Atlanta, Georgia, U.S.A., June 2013. View abstract, Download PDF, View external link
[3] Tian Lin, Bruno Abrahao, Robert Kleinberg, John C.S. Lui, and Wei Chen. Combinatorial Partial Monitoring Game with Linear Feedback and its Applications. In Proceedings of the 31st International Conference on Machine Learning (ICML'2014), Beijing, China, June 2014. View abstract, Download PDF
[4] Shouyuan Chen, Tian Lin, Irwin King, Michael R. Lyu, and Wei Chen. Combinatorial Pure Exploration of Multi-Armed Bandits. In Proceedings of the 27th Annual Conference on Advances in Neural Information Processing Systems (NIPS'2014), Montreal, Canada, December 2014. View abstract, Download PDF
[5] Tian Lin, Jian Li, and Wei Chen. Stochastic Online Greedy Learning with Semi-bandit Feedbacks. In Proceedings of the 28th Annual Conference on Advances in Neural Information Processing Systems (NIPS'2015), Montreal, Canada, December 2015. View abstract, Download PDF
[6] Wei Chen, Yajun Wang, Yang Yuan, and Qinshi Wang. Combinatorial Multi-Armed Bandit and Its Extension to Probabilistically Triggered Arms. In Journal of Machine Learning Research 17 (2016) 1-33, 2016. View abstract, Download PDF
[7] Shuai Li, Baoxiang Wang, Shengyu Zhang, and Wei Chen. Contextual Combinatorial Cascading Bandits. In Proceedings of the 33rd International Conference on Machine Learning (ICML'2016), New York, NY, USA, June 2016. View abstract, Download PDF
[8] Wei Chen, Wei Hu, Fu Li, Jian Li, Yu Liu, and Pinyan Lu. Combinatorial Multi-Armed Bandit with General Reward Functions. In Proceedings of the 29th Annual Conference on Advances in Neural Information Processing Systems (NIPS'2016), Barcelona, Spain, December 2016. View abstract, Download PDF
[9] Qinshi Wang, and Wei Chen. Improving Regret Bounds for Combinatorial Semi-Bandits with Probabilistically Triggered Arms and Its Applications. In Proceedings of the 30th Annual Conference on Advances in Neural Information Processing Systems (NIPS'2017), Long Beach, U.S.A., December 2017. View abstract
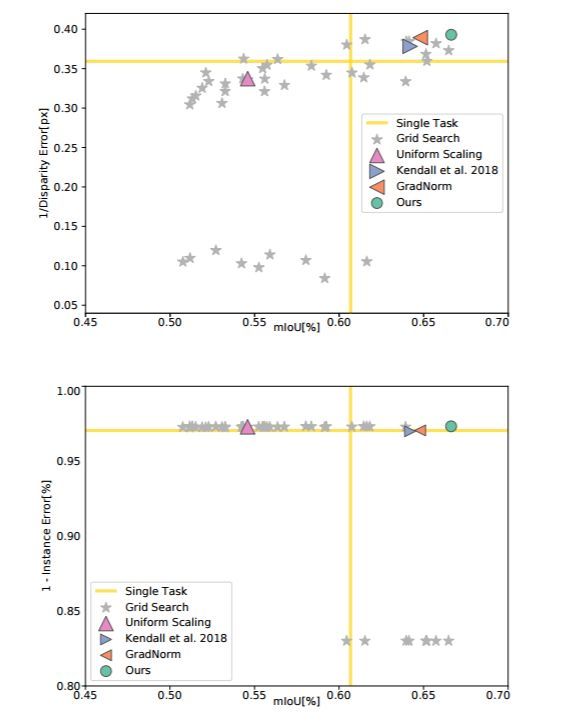
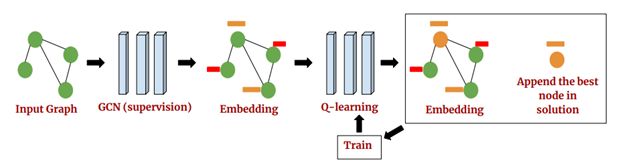
最近,通过“Learning Heuristics Over Large Graphs Via Deep Reinforcement Learning”一文(arxiv.org/pdf/1903.03332.pdf),研究者朝着现实世界的问题迈出了重要一步。在论文中,作者训练了一个图卷积网络来解决大型问题,如最小顶点覆盖(MVC)和最大覆盖问题(MCP)。他们使用流行的贪婪算法来训练神经网络嵌入图形,并预测每一阶段要选择的下一个节点,然后使用DQN算法对其进行进一步的训练。
最近受我的朋友委托用js+HTML做一个像手册一样的程序,里面要有可展开的大纲,模糊查找等功能。我这个人说实在的懒,本来是不愿意的,但想起了父亲以前教我要给朋友搞好关系,再加上这也可以巩固自己的js技术,于是就开始开发这个程序,没想到却出了点小问题,我做的查找只能绝对查找。具体的js代码如下:
function search(){
var arr=new Array("my
实例:
CREATE OR REPLACE PROCEDURE test_Exception
(
ParameterA IN varchar2,
ParameterB IN varchar2,
ErrorCode OUT varchar2 --返回值,错误编码
)
AS
/*以下是一些变量的定义*/
V1 NUMBER;
V2 nvarc
Spark Streaming简介
NetworkWordCount代码
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
代码示例:
# include <stdio.h>
//冒泡排序
void sort(int * a, int len)
{
int i, j, t;
for (i=0; i<len-1; i++)
{
for (j=0; j<len-1-i; j++)
{
if (a[j] > a[j+1]) // >表示升序
nginx日志分割 for linux 默认情况下,nginx是不分割访问日志的,久而久之,网站的日志文件将会越来越大,占用空间不说,如果有问题要查看网站的日志的话,庞大的文件也将很难打开,于是便有了下面的脚本 使用方法,先将以下脚本保存为 cutlog.sh,放在/root 目录下,然后给予此脚本执行的权限
复制代码代码如下:
chmo
http://bukhantsov.org/2011/08/how-to-determine-businessobjects-service-pack-and-fix-pack/
The table below is helpful. Reference
BOE XI 3.x
12.0.0.
y BOE XI 3.0 12.0.
x.
y BO
大家都知道吧,这很坑,尤其是用惯了mysql里的自增字段设置,结果oracle里面没有的。oh,no 我用的是12c版本的,它有一个新特性,可以这样设置自增序列,在创建表是,把id设置为自增序列
create table t
(
id number generated by default as identity (start with 1 increment b