全网最全持续集成接口自动化-jmeter+ant+jenkins
ant 批量执行Jmeter
一、环境准备
1、JDK环境:Java Downloads | Oracle
2、ANT环境:Apache Ant - Binary Distributions
3、Jmeter:Apache JMeter - Download Apache JMeter
4、将 jmeter的extras目录中ant-jmeter-1.1.1.jar包拷贝至ant安装目录下的lib目录中
5、修改Jmeter的bin目录下jmeter.properties文件的配置:jmeter.save.saveservice.output_format=xml
以上三样配置完环境变量就可以开始进入接口自动化持续集成的精彩世界
二、Jmeter脚本准备
可参考:http://www.cnblogs.com/hito/p/5050769.html
三、ant的build.xml文件
四、执行
进入build.xml的文件路径下,Shift加右键,选中在此处打开命令行,输入命令:ant,然后回车

五、结果查看

六、HTML报告扩展
在用 loadrunner 的时候可以生成一个 HTML 的报告,并且里面包含各种图表,各种详细的数据。而在使用 Jmeter 测试完后并不能直接生成 Html 的报告(无论是用 GUI 还是命令行启动)。
经过查找资料发现 Jmeter 的 extras 目录下有生成 HTML 的 xsl 样式表,其实 Jenkins+ant+Jmeter 生成的 HTML 报告也是调用了这里的样式表生成的,于是
通过 xsltproc report.jtl > test.html,或者 ant 也可以。这个命令把Jmeter 的结果文件转换为 HTML 的报告。结果如下:
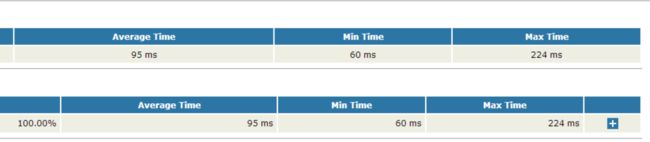
这里虽然能生成 HTML 报告了,但是这个报告太弱了,基本不能用,包含的参数太少。所以需要对这个报告进行扩展。因为 Jmeter 本身的聚合报告的数据还是比较全的,
因此打算按照那个报告的值进行扩展。
xsltproc,xlst介绍
XSL 指扩展样式表语言(EXtensible Stylesheet Language),把 XML 转换为HTML 用的就是 xls 编写的样式表,所以如果要扩展这个报告,首先要对 xls
熟悉,才能更改和扩展样式表。
xsltproc 是一个快速 XSLT 引擎,它可以将通过 XSL 层叠样式表把 XML 转换为相应格式的文件,比如:HTML,XHTML,PDF
比如将 XML 转换为 HTML,使用格式如下:
xsltproc xsl-html.xsl hoto.xml -o html.html (这里还可以直接把样式表文件写入 jtl 文件的 href 属性中,直观的告诉这个 XML 用哪个样式表)
xls 中查找 XML 用的 xpath,因此还需要对 xpath 熟悉,xsltproc 这个引擎用的是 xpath1.0 版本,因此在样式表中使用 xpath 是不能使用 xpath2.0 的函数
和一些属性。 个人对 xpath 还算熟悉,但是对 xls 一点也不熟悉,没办法为了能够扩展报告,直接学习 xls 和 xpath。(关于 xls 会再写一遍博客介绍,顺便把使用过程中 的问题和经验汇总)
如果直接使用 ant 和 Jmeter 集成后也是可以直接生成的,但是 ant 转换 HTML 的引擎也是只支持 xpath1.0,后来经过了解大部分的引擎都不支持xpath2.0,所以 期中不能使用 xpath2.0 的函数。
90%Line 时间
为了能够显示 90%Line 的时间,首先要对这个指标熟悉,这个指标值得是一组数据,在 90% 的位置的数据的时间,所以我们扩展的时候只要知道了 90% 位置的索引,那么就能取得这个值了。 以下是部分关键代码
这里主要是获得时间元素的集合,以及 90%line 的位置,有了这两个参数后就可以进行后续的扩展了,扩展后的效果图如下:

因为 90%Line 和 95%Line,99%Line 计算原理都是一致的,因此只要计算出一个值其他的值也很好计算
QPS 扩展
Jmeter 的具合报告有 Throughput 这个值,这个在 loadrunner 中是表示为吞吐量的,这里可以表示 QPS 或者 TPS(在使用了事务的情况下),个人把这个称为 QPS,因为更直观。
和 %90Line 同样的道理,首先必须知道这个值是怎么计算出来,经过查找资料和官网的比较,发现这个值是通过如下的公式计算出来的:
官网的截图:

Throughput = (number of requests) / (total time)
total time = 测试结束时间 - 测试开始时间
测试结束时间 = MAX(请求开始时间 + Elapsed Time) 测试开始时间 = MIN(请求开始时间)
知道了公式,那么计算就容易了,以下是关键代码:
扩展后的结果如下:

吞吐量扩展
在 loadrunner 中吞吐量就是 Throughput,在 Jmeter 的聚合报告中最后一列的值就是 loadrunner 中的 Throughput,为了便于区分,我把这里的值称为Throughput,
也就是吞吐量。
经过查找资料发现吞吐量的计算和 QPS 的计算公式是一样的,因为也就是如下的公式:
Throughput = (请求的总字节数) / (total time)
这里的 total time 计算和 QPS 是一样的,而总字节数直接把所有请求的加起来即可,关键代码如下:
因为这里显示的字节,最后的结果我打算以 KB 的单位显示,因此这里需要除以1024,扩展后的结果如下

TPS扩展
TPS 在 Jmeter 中虽然某些情况和 QPS 是一致的,但是还是有不一致的地方,因此这里也需要扩展,这样的结果看着更清晰明了。
首先和其他的参数扩展一样,需要知道计算公式,这里的计算公式和 QPS 也是一样的,只是数据的集合不一样,以下是扩展后的效果。

在扩展的过程中进一步发现 Jmeter 的聚合结果中最后的”总体“一行在某些情况下计算的数值是不准确的。如果脚本中不包含事务,那么这里的结果是准确的,如果都包含事务并且把
Generate parent sample 选中后这里的结果也是准确的,在脚本中有事务并且没有选中 Generate parent sample,或者有些有事务有些没有时,这时的结果就不准确了,因为查看计算
方式发现它把所有的请求都算进去了。
比如,一个 jtl 文件中即包含 HTTP 请求也包含事务,因为事务只是对之前请求的一个统计,本身是不发送请求的,所以计算总的吞吐量、QPS,TPS 时是不能这么算的。
所以在扩展的过程中分成了两个样式表,一个样式表处理包含事务,或者没有事务的情况,这时的结果以 QPS 衡量;一个样式表处理全都是事务的情况,这时候的结果以 TPS 衡量,这样
就准确了。
测试
扩展了好几个指标,这些指标的正确性如何呢?需要在多种情况下进行测试,经过测试后各个指标都是正确的。但是还没有在大的数据量级别下测试,如果测试后发现哪里会有问题,会及时
更改。
切记:由于样式表中是按照 lb 进行请求区分的,因此这里的 lable 不能重复,本身也不应该重复,包括 Jmeter 的聚合报告都是以 lable 进行区分的
PS:在扩展过程中的难点一是公式如何计算的,二是xls这个 指扩展样式表语言不是很熟悉,本身也有很多限制,会在下个博客中说明。但是用过后感觉还是很不错的既熟悉了 xpath 还熟悉了 xls。