CUDA教程: 2.初识CUDA---CUDA简介
CUDA教程: 2.初识CUDA
在上一章, 我们介绍了GPU的硬件, 这一张呢, 我们来聊聊CUDA编程的细节.
说到编程细节, 无非就是包含: 环境安装, 语法风格, 实现流程(或叫做编程模型), 关键字, 编译这些事. 接下来, 我们就这些内容展开介绍.
异构计算
CUDA是一种异构计算的编程模型, 所谓异构计算, 就是将一个任务分开几份, 分别在不同的设备上执行. 而在CUDA编程模型中, 我们是将主要计算的部分交给GPU来完成, 而逻辑控制和数据预处理等交给CPU来完成.

在CUDA编程模型中有两个重要的词汇: Host & Device
- Host: CPU和内存(host memory)
- Device: GPU和显存(device memory)
我们通常把CPU称作Host(或者主机), 把GPU称作Device(或者设备), 比如:主机函数, 主机变量, 设备函数, 设备内存等.
环境安装
官方给了非常详细的安装步骤:
-
适用设备:
- 所有包含NVIDIA GPU的服务器,工作站,个人电脑,嵌入式设备等电子设备
-
软件安装:
-
Windows:https://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/index.html
只需安装一个.exe的可执行程序 -
Linux:https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
按照上面的教程,需要6 / 7 个步骤即可 -
Jetson: https://developer.nvidia.com/embedded/jetpack
直接利用NVIDIA SDK Manager 或者 SD image进行刷机即可
-
虽然都是英文的, 但是都是一些非常简单的词汇, 建议大家在配置环境之前看一下.
安装好环境之后, 你就可以检查下是否安装成功了:
查看当前设备中GPU状态:
-
服务器,工作站,个人电脑:nvidia-smi
-
Jetson等设备: Jtop
-
查看当前设备参数:
- 在CUDA sample中1_Utilities/deviceQuery文件夹下的deviceQuery程序。以Ubuntu为例,deviceQuery 程序在:/usr/local/cuda/samples/1_Utilities/deviceQuery
CUDA程序编写
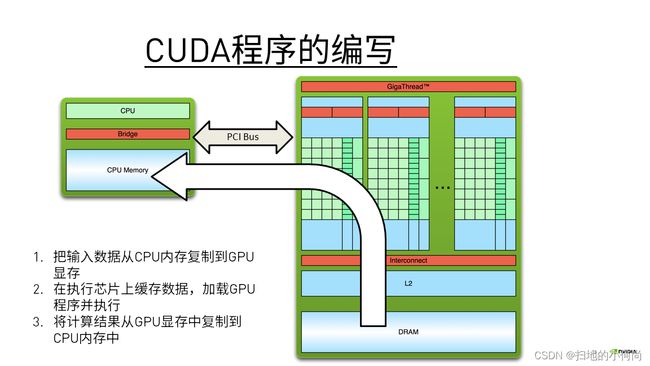
当我们在写CUDA程序时, 那些在GPU上执行的代码和在CPU上执行的代码可以放在一起, 会变成一个".cu"文件
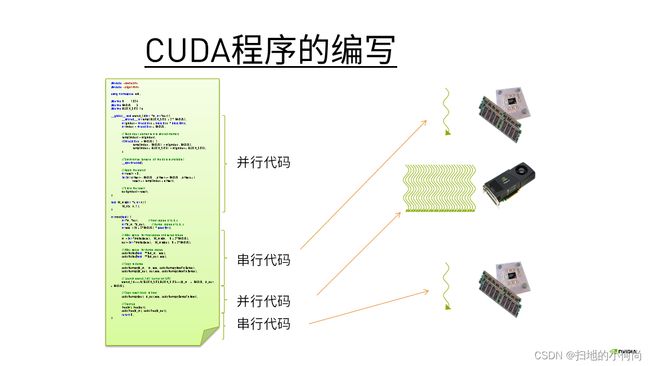
而CUDA编程模型都会遵循一个流程:
- 把输入数据从CPU内存复制到GPU显存
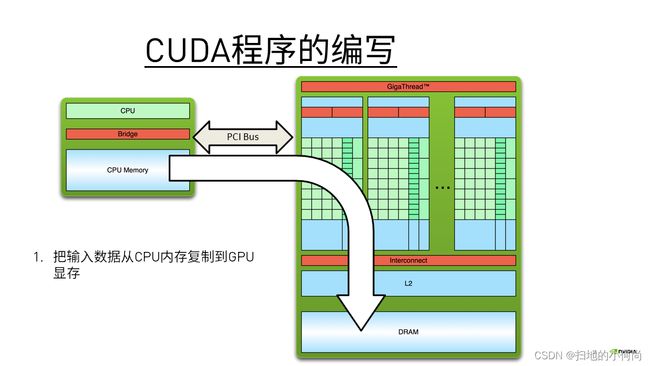
- 在执行芯片上缓存数据,加载GPU程序并执行

- 将计算结果从GPU显存中复制到CPU内存中
而在GPU上执行的函数, 我们将它成为核函数. 在CPU上执行的函数, 我们称之为主机函数.
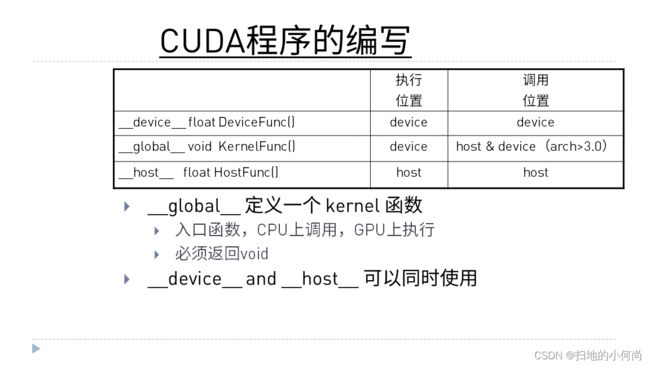
比如: __global__ void KernelFunc()这个函数, 前面的__global__修饰符限定了该函数就是在GPU上执行, 可以在GPU或者CPU上调用.
而__device__修饰符限定了函数只能在GPU上执行和调用.
__host__修饰符限定了函数只能在CPU上执行和调用.
当然如果什么都不加, 那就和__host__一样.
比如在下面代码中:

VecAdd就是核函数, 它在GPU中执行, 在CPU main()函数中被调用
<<<>>>中的内容是执行这个核函数的线程个数, 以及现成层次等, 我们在下一章节进行说明.
那写好了代码之后, 我们就要将写好的代码进行编译:

我们写完代码之后, 将文件以.cu为后缀名的形式保存, 然后就可以使用专门的编译器 nvcc 来进行编译.

CUDA编译工作如下:输入程序经过预处理,用于设备编译编译,编译成CUDA二进制(cubin)或PTX中间代码,存放在fatbinary中。再次对输入程序进行预处理以进行主机编译,并进行合并以嵌入 fatbinary 并将 CUDA 特定的 C++ 扩展转换为标准 C++ 结构。然后 C++ 宿主编译器将带有嵌入式 fatbinary 的综合宿主代码编译成宿主对象。
每当主机程序启动设备代码时,CUDA 运行时系统都会检查嵌入式 fatbinary,以获得当前 GPU 的适当 fatbinary 图像。
CUDA程序默认以全程序编译模式编译,即设备代码不能从单独的文件中引用实体。在整个程序编译模式下,设备链接步骤无效。
当然, 当你引入头文件的时候, 还可以这样编写:

当编译成功之后, 我们就有了一个可执行程序.
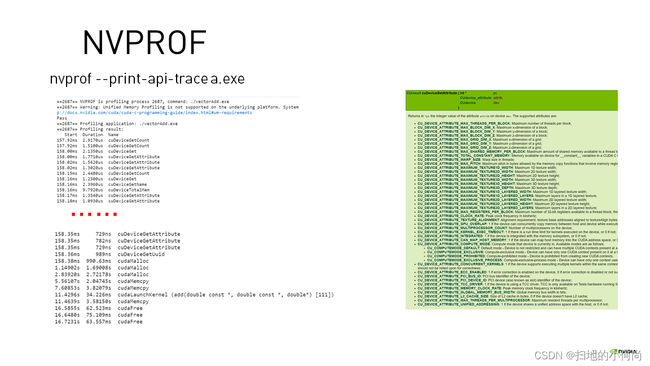
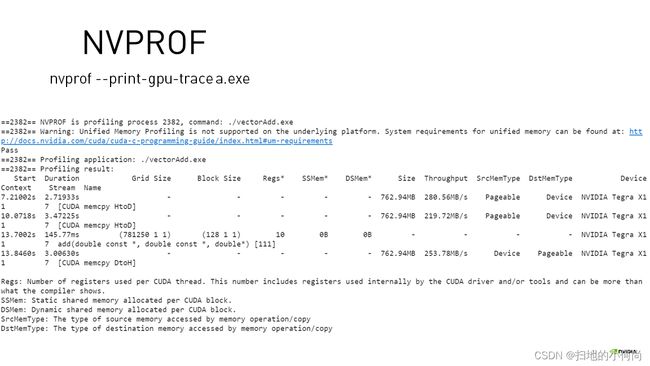
那我们还可以对这个可执行程序进行分析, NVIDIA提供了nvprof, nvvp, nsight等分析工具.