单人脸的关键点检测
闲暇之余做了一个简单的单人的脸部关键点检测,使用的pytorch框架,别人训练好的现成模型。其中人脸检测模型是YOLOface5(onnx格式的权重),关键点检测模型是PFLD(能检测98个关键点),是别人在原论文中用MobileOne改了骨干网训练好的,我直接拿来用了。这里感谢AnthonyF333,其训练和pytorch转onnx代码均已给出,地址为GitHub - AnthonyF333/PFLD_GhostOne。最终我的项目放到了github上,地址为:https://github.com/luoyoutao/FaceKeyPoints。
废话不多说,我直接上代码了(这个代码可以直接运行,不过有些路径参数需要根据自己的实际项目来更改一下)。
首先,导入需要的包:
import cv2
import time
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import torch
import onnxruntime
import torchvision.transforms as transforms下面是检测的主函数(会调用一些其他函数,在后面):
整体的流程是:
1、设置一些路径参数;
2、加载模型;
3、onnx的预热,即模型第一次预测需要花费大量的时间启动GPU,为了让真实检测时顺畅,先给模型喂一个数据。
检测的流程:
1、将原图复制一份,缩放到640*640。如果直接让输入视频或者摄像头的尺寸为640*640,那么检测就更快,且更方便。
2、送入yolo5face模型,输出shape是(12500, 16),即有12500个box,每个box16个数据,分别是center_x, center_y, w, h, threse, ....。然后将center_x, center_y, w, h转换成x1, y1, x2, y2,即对角线坐标。可能会检测到多个人脸,我这里由于检测单人的,所有直接取检测分数值最大的box,nms函数就简单得多。先sort排序,返回第一个box即可。我参考的这个项目,他是按照多人检测的,你可以根据自己的需求来即可。
3、将检测出的人脸送入PFLD模型,出来的结果直接是98个x, y坐标,然后再将坐标对应到原图上去,就可以在原图上绘制点和框了。
if __name__ == "__main__":
# ---1、参数设置---
use_cuda = True # 使用cuda - gpu
facedetect_input_size = (640, 640) # 人脸检测器的输入大小
pfld_input_size = (112, 112) # 关键点检测器的输入大小
face_path = "./onnx_models/yolov5face_n_640.onnx" # 人脸检测器器路径
pfld_path = "./onnx_models/PFLD_GhostOne_112_1_opt_sim.onnx" # 关键点检测器路径
video_path = "./kk.mp4" # 检测的视频文件路径,如果你用摄像头,就不管这个,注释掉即可
# ---2、获取模型--- # 这里需要注意,如果onnx需要使用gpu,则只能且仅安装onnxruntime-gpu这个包,若你装了onnxruntime,是用CPU,需要把其卸载掉再装-GPU版本的
facedetect_session = onnxruntime.InferenceSession( # 加载检测人脸的模型
path_or_bytes=face_path,
# providers=['CPUExecutionProvider'],
providers=['CUDAExecutionProvider']
)
pfld_session = onnxruntime.InferenceSession( # 加载检测关键点的模型
path_or_bytes=pfld_path,
# providers=['CPUExecutionProvider'],
providers=['CUDAExecutionProvider']
)
# 3、tensor设置
detect_transform = transforms.Compose([transforms.ToTensor()]) # 人脸的
pfld_transform = transforms.Compose([ # 关键点的
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 归一化
])
# 4、加载视频
cap = cv2.VideoCapture(video_path) # 如果不填路径参数就是获取摄像头
# 5、先预热一下onnx
data_test = torch.FloatTensor(1, 3, 640, 640)
input_test = {facedetect_session.get_inputs()[0].name: to_numpy(data_test)} # 把输入包装成字典
_ = facedetect_session.run(None, input_test)
# 6、下面开始繁琐的检测和处理程序
x = [0 for i in range(98)] # 初始化存放需要检测的关键点的x坐标
y = [0 for i in range(98)] # 初始化存放需要检测的关键点的y坐标
while cap.isOpened():
ret, frame = cap.read() # type(frame) =
if not ret: # 读取失败或已经读取完毕
break
start = time.time()
# 先将每一帧,即frame转成RGB,再实现ndarray到image的转换
img0 = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
iw, ih = img0.size
# 检测人脸前的图像处理
# 处理方法是:先缩放,使宽或者高到640,且选择缩放比例小的那个维度(宽/高)
# pad_image函数参数:Image格式的图像、人脸检测器的输入大小640 * 640
# 返回处理过的图像,最小的缩放尺度(宽高谁大缩放谁),填充的宽、填充的高(宽高只有一个需要填充)
pil_img_pad, scale, pad_w, pad_h = pad_image(img0, facedetect_input_size) # 尺寸处理
# 转换成tensor
tensor_img = detect_transform(pil_img_pad)
detect_tensor_img = torch.unsqueeze(tensor_img, 0) # 给tensor_img加一个维度,维度大小为1
if use_cuda:
detect_tensor_img = detect_tensor_img.cuda()
# 先检测到人脸
inputs = {facedetect_session.get_inputs()[0].name: to_numpy(detect_tensor_img)} # 把输入包装成字典
outputs = facedetect_session.run(None, inputs) # type(outputs)
preds = outputs[0][0] # shape=(25200, 16) 每一维的组成: center_x、center_y、w、h、thresh, ...
# batch_process_output参数:人脸预测结果、阈值、缩放尺度、填充宽、填充高、原宽、原高
# 返回经过筛选的框 type(preds) = list preds[0].shape = 5即,[x1, y1, x2, y2, score]
preds = np.array(batch_process_output(preds, 0.5, scale, pad_w, pad_h, iw, ih))
if preds.shape[0] == 0: # 如果当前帧没有检测出人脸来,继续检测人脸
cv_img = cv2.cvtColor(np.asarray(img0), cv2.COLOR_RGB2BGR)
cv2.imshow('ii', cv_img)
cv2.waitKey(1)
continue
# nms处理,为了简便,我直接返回score最大的box
det = nms(preds)
# 得到裁剪出输入关键点检测器的人脸图、缩放尺度、x_offset、y_offset
cut_face_img, scale_l, x_offset, y_offset = cut_resize_letterbox(img0, det, pfld_input_size)
# 转换成tensor
tensor_img = pfld_transform(cut_face_img)
pfld_tensor_img = torch.unsqueeze(tensor_img, 0) # 给tensor_img加一个维度,维度大小为1
if use_cuda:
pfld_tensor_img = pfld_tensor_img.cuda()
# 送入关键点检测器进行检测
inputs = {'input': to_numpy(pfld_tensor_img)}
outputs = pfld_session.run(None, inputs)
preds = outputs[0][0]
radius = 2
draw = ImageDraw.Draw(img0) # 通过draw在原图img0上绘制人脸框和关键点
for i in range(98):
x[i] = preds[i * 2] * pfld_input_size[0] * scale_l + x_offset
y[i] = preds[i * 2 + 1] * pfld_input_size[1] * scale_l + y_offset
draw.ellipse((x[i] - radius, y[i] - radius, x[i] + radius,
y[i] + radius), (0, 255, 127))
draw.text(xy=(90, 30), text='FPS: ' + str(int(1 / (time.time() - start))),
fill=(255, 0, 0), font=ImageFont.truetype("consola.ttf", 50))
draw.rectangle((det[0], det[1], det[2], det[3]), outline='yellow', width=4)
cv_img = cv2.cvtColor(np.asarray(img0), cv2.COLOR_RGB2BGR)
cv2.imshow('ii', cv_img)
cv2.waitKey(1)
cap.release()
下面是一些检测过程中用到的函数(处理检测过程中的数据,按照使用的先后顺序介绍):
1、pad_image()函数。功能:将原图复制一份,对复制的图像进行尺度缩放和填充。具体操作是,先将图像尺寸设置到640*640,将宽或高大的边resize到640,然后小的边按照尺度resize到640,这时小边一定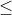 640,因此填充黑色像素即可,这个过程是需要记录压缩的尺度和填充的长度的,便于后面检测到的关键点坐标对应到原图上。
640,因此填充黑色像素即可,这个过程是需要记录压缩的尺度和填充的长度的,便于后面检测到的关键点坐标对应到原图上。
def pad_image(image, target_size):
'''
image: 图像
target_size: 输入网络中的大小
return: 新图像、缩放比例、填充的宽、填充的高
'''
iw, ih = image.size # 原图像尺寸
w, h = target_size # 640, 640
scale = min(w / iw, h / ih) # 缩放比例选择最小的那个(宽高谁大缩放谁)(缩放大的,填充小的)
nw = int(iw * scale + 0.5)
nh = int(ih * scale + 0.5)
pad_w = (w - nw) // 2 # 需要填充的宽
pad_h = (h - nh) // 2 # 需要填充的高
image = image.resize((nw, nh), Image.Resampling.BICUBIC) # 缩放图像(Resampling需要PIL最新版,python3.7以上)
new_image = Image.new('RGB', target_size, (128, 128, 128)) # 生成灰色的新图像
new_image.paste(image, (pad_w, pad_h)) # 将image张贴在生成的灰色图像new_image上
return new_image, scale, pad_w, pad_h # 返回新图像、缩放比例、填充的宽、填充的高
2、to_numpy()函数。将tensor转换为numpy,这里是推理,故不用计算梯度,直接转为无梯度的numpy。
def to_numpy(tensor_data):
return tensor_data.detach().cpu().numpy() if tensor_data.requires_grad else tensor_data.cpu().numpy()3、batch_process_output()函数。预测出来的人脸框数据是中心点+宽高,我们需要转换为左上右下的对角线坐标,且需要转换到对应原图上的坐标,因此需要原图缩放尺度和填充的像素值。最后返回了前五个数据,即x1, y1, x2, y2, score。
def batch_process_output(pred, thresh, scale, pad_w, pad_h, iw, ih):
'''
iw, ih为图像原尺寸
'''
bool1 = pred[..., 4] > thresh # bool1.shape = [num_box] 里面的值为bool(True/False)
pred = pred[bool1] # pred.shape = [n, 16],即筛选出了置信度大于thresh阈值的n个box
ans = np.copy(pred)
ans[:, 0] = (pred[:, 0] - pred[:, 2] / 2 - pad_w) / scale # x1
np.putmask(ans[..., 0], ans[..., 0] < 0., 0.) # 将所有box的小于0.的x1换成0.
ans[:, 1] = (pred[:, 1] - pred[:, 3] / 2 - pad_h) / scale # y1
np.putmask(ans[..., 1], ans[..., 1] < 0., 0.) # 将所有box的小于0.的y1换成0.
ans[:, 2] = (pred[:, 0] + pred[:, 2] / 2 - pad_w) / scale # x2
np.putmask(ans[..., 2], ans[..., 2] > iw, iw) # 将所有box的大于iw的x2换成iw
ans[:, 3] = (pred[:, 1] + pred[:, 3] / 2 - pad_h) / scale # y2
np.putmask(ans[..., 3], ans[..., 3] > ih, ih) # 将所有box的大于ih的y2换成ih
ans[..., 4] = ans[..., 4] * ans[..., 15] # score
return ans[:, 0:5]4、nms()函数。这里预测单人脸,我直接返回score第一的box。
def nms(preds): # NMS筛选box
arg_sort = np.argsort(preds[:, 4])[::-1]
nms = preds[arg_sort] # 按照score降序将box排序
# 单脸检测,直接返回分数最大的box
return nms[0]5、 cut_resize_letterbox()函数。从原图中裁剪出人脸框再resize到112*112。
def cut_resize_letterbox(image, det, target_size):
# 参数分别是:原图像、检测到的某个脸的数据[x1,y1,x2,y2,score]、关键点检测器输入大小
iw, ih = image.size
x, y = det[0], det[1]
w, h = det[2] - det[0], det[3] - det[1]
facebox_max_length = max(w, h) # 以最大的边来缩放
width_margin_length = (facebox_max_length - w) / 2 # 需要填充的宽
height_margin_length = (facebox_max_length - h) / 2 # 需要填充的高
face_letterbox_x = x - width_margin_length
face_letterbox_y = y - height_margin_length
face_letterbox_w = facebox_max_length
face_letterbox_h = facebox_max_length
top = -face_letterbox_y if face_letterbox_y < 0 else 0
left = -face_letterbox_x if face_letterbox_x < 0 else 0
bottom = face_letterbox_y + face_letterbox_h - ih if face_letterbox_y + face_letterbox_h - ih > 0 else 0
right = face_letterbox_x + face_letterbox_w - iw if face_letterbox_x + face_letterbox_w - iw > 0 else 0
margin_image = Image.new('RGB', (iw + right - left, ih + bottom - top), (0, 0, 0)) # 新图像,全黑的z
margin_image.paste(image, (left, top)) # 将image贴到margin_image,从左上角(left, top)位置开始
face_letterbox = margin_image.crop( # 从margin_image中裁剪图像
(face_letterbox_x, face_letterbox_y, face_letterbox_x + face_letterbox_w, face_letterbox_y + face_letterbox_h))
face_letterbox = face_letterbox.resize(target_size, Image.Resampling.BICUBIC) # 重新设置图像尺寸大小
# 返回:被裁剪出的图像也是即将被送入关键点检测器的图像、缩放尺度、x偏移、y偏移
return face_letterbox, facebox_max_length / target_size[0], face_letterbox_x, face_letterbox_y上面即是所有的代码了,若有指教,欢迎评论交流。