一文了解知识图谱能做什么、本文含Jiagu自然语言处理工具试用、知识图谱实战。
关于知识图谱的简介:
知识图谱(Knowledge Graph)作为大数据时代的重要设施基础,已经在下一代搜索引擎、智能问答系统,文本处理,自然语言处理等智能应用中有了广泛应用。知识图谱规范地定义了知识的存储,并且可以较为方便和高效的进行知识推理和决策。面向特定领域的知识图谱应用研究也越来越多。当前,基于机器人领域的知识图谱应用热度持续升高,但配套的智能问答系统相关技术尚不成熟。
1.知识图谱部分领域的应用
1.1知识图谱简介
知识图谱并非是一个全新的概念,早在2006年,文献[5]就提出了语义网的概念,呼吁推广、完善使用本体模型来形式化表达数据中的隐含语义,RDF(resource description framework)模式(RDF schema)和万维网本体语言(Web ontology language,OWL)的形式化模型就是基于上述目的产生的。随后掀起了一场语义网研究的热潮,知识图谱技术的出现正是基于以上相关研究,是对语义网标准与技术的一次扬弃与升华。知识图谱于2012年5月17日被Google正式提出[6],其初衷是为了提高搜索引擎的能力,增强用户的搜索质量以及搜索体验。目前,随着智能信息服务应用的不断发展,知识图谱已被广泛应用于智能搜索、智能问答、个性化推荐等领域。尤其是在智能搜索中,用户的搜索请求不再局限于简单的关键词匹配,搜索将根据用户查询的情境与意图进行推理,实现概念检索。与此同时,用户的搜索结果将具有层次化、结构化等重要特征。例如,用户搜索的关键词为梵高,引擎就会以知识卡片的形式给出梵高的详细生平、艺术生涯信息、不同时期的代表作品,并配合以图片等描述信息。知识图谱能够使计算机理解人类的语言交流模式,从而更加智能地反馈用户需要的答案[7]。与此同时,通过知识图谱能够将Web上的信息、数据以及链接关系聚集为知识,使信息资源更易于计算、理解以及评价,并且形成一套Web语义知识库。
1.2知识图谱的特点
知识图谱具有如下 3 种特点:① 数据及知识的存储结构为有向图结构。有向图结构允许知识图谱有效地存储数据和知识之间的关联关系;② 具备高效的数据和知识检索能力。知识图谱可以通过图匹配算法,实现高效的数据和知识访问;③ 具备智能化的数据和知识推理能力。知识图谱可以自动化、智能化地从已有的知识中发现和推理多角度的隐含知识。
1.3知识图谱的优势和价值
(1)关系的表达能力强
传统数据库通常通过表格、字段等方式进行读取,而关系的层级及表达方式多种多样,且基于图论和概率图模型,可以处理复杂多样的关联分析,满足企业各种角色关系的分析和管理需要。
(2)像人类思考一样去做分析
基于知识图谱的交互探索式分析,可以模拟人的思考过程去发现、求证、推理,业务人员自己就可以完成全部过程,不需要专业人员的协助。
(3)知识学习
利用交互式机器学习技术,支持根据推理、纠错、标注等交互动作的学习功能,不断沉淀知识逻辑和模型,提高系统智能性,将知识沉淀在企业内部,降低对经验的依赖。
(4)高速反馈
图式的数据存储方式,相比传统存储方式,数据调取速度更快,图库可计算超过百万潜在的实体的属性分布,可实现秒级返回结果,真正实现人机互动的实时响应,让用户可以做到即时决策。
1.4知识图谱在机器人领域的应用
知识图谱最早的应用是提升搜索引擎的能力。随后,知识图谱在辅助智能问答、自然语言理解、大数据分析、推荐计算、物联网设备互联、可解释性机器人等多个方面展现出丰富的应用价值。
1.4.1辅助机器人嵌入式的搜索
互联网的终极形态是万物的互联,而搜索的终极目标是对万物的直接搜索。传统搜索引擎依靠网页之间的超链接实现网页的搜索,而语义搜索是直接对事物进行搜索,如人物、机构、地点等。这些事物可能来自文本、图片、视频、音频、IoT 设备等各种信息资源。而知识图谱和语义技术提供了关于这些事物的分类、属性和关系的描述,使得搜索引擎可以直接对事物进行索引和搜索,如图1-1所示。

图1-1 知识图谱辅助搜索
1.4.2辅助机器人问答
人与机器人通过自然语言进行问答与对话是人工智能实现的关键标志之一。除了辅助搜索,知识图谱也被广泛用于人机问答交互中。在产业界,IBM Watson 背后依托 DBpedia和Yago等百科知识库和WordNet等语言学知识库实现深度知识问答。Amazon Alex主要依靠True Knowledge公司积累的知识图谱。度秘、Siri的进化版Viv、小爱机器人、天猫精灵背后都有海量知识图谱作为支撑。
伴随着机器人和 IoT 设备的智能化浪潮的掀起,基于知识图谱的问答对话在智能驾驶、智能家居和智能厨房等领域的应用层出不穷。典型的基于知识图谱的问答技术或方法包括:基于语义解析、基于图匹配、基于模板学习、基于表示学习和深度学习以及基于混合模型等。在这些方法中,知识图谱既被用来辅助实现语义解析,也被用来匹配问句实体,还被用来训练神经网络和排序模型等。知识图谱是实现人机交互问答必不可少的模块。
1.4.3辅助机器人数据分析
知识图谱和语义技术也被用于辅助进行数据分析与决策。例如,大数据公司 Palantir基于本体融合和集成多种来源的数据,通过知识图谱和语义技术增强数据之间的关联,使得用户可以用更加直观的图谱方式对数据进行关联挖掘与分析。
知识图谱在文本数据的处理和分析中也能发挥独特的作用。例如,知识图谱被广泛用来作为先验知识从文本中抽取实体和关系,如在远程监督中的应用。知识图谱也被用来辅助实现文本中的实体消歧(Entity Disambiguation)、指代消解和文本理解等。
近年来,描述性数据分析(Declarative Data Analysis)受到越来越多的重视。描述性数据分析是指依赖数据本身的语义描述实现数据分析的方法。不同计算性数据分析主要以建立各种数据分析模型,如深度神经网络,而描述性数据分析突出预先抽取数据的语义,建立数据之间的逻辑,并依靠逻辑推理的方法(如DataLog)来实现数据分析。
1.4.4辅助机器人语言理解
背景知识,特别是常识知识,被认为是实现深度语义理解(如阅读理解、人机问答等)必不可少的构件。一个典型的例子是Winograd Schema Challenge(WSC竞赛)。WSC由著名的人工智能专家 Hector Levesque 教授提出,2016年,在国际人工智能大会 IJCAI上举办了第一届WSC竞赛。WSC主要关注那些必须要叠加背景知识才能理解句子语义的NLP任务。例如,在下面这个例子中,当描述it是big时,人很容易理解it指代trophy;而当it与small搭配时,也很容易识别出it指代suitcase。
The trophy would not fit in the brown suitcase because it was too big(small).What was too big(small)?
Answer 0:the trophy Answer 1:the suitcase
这个看似非常容易的问题,机器却毫无办法。正如自然语言理解的先驱 Terry Winograd 所说的,当一个人听到一句话或看到一段句子的时候,会使用自己所有的知识和智能去理解。这不仅包括语法,也包括其拥有的词汇知识、上下文知识,更重要的是对相关事物的理解。
1.4.5辅助机器人设备互联
人机对话的主要挑战是语义理解,即让机器理解人类语言的语义。另外一个问题是机器之间的对话,这也需要技术手段来表示和处理机器语言的语义。语义技术也可被用来辅助设备之间的语义互联。OneM2M 是2012年成立的全球最大的物联网国际标准化组织,其主要是为物联设备之间的互联提供“标准化黏合剂”。OneM2M 关注了语义技术在封装设备数据的语义,并基于语义技术实现设备之间的语义互操作的问题。此外,OneM2M还关注设备数据的语义和人类语言的语义怎样适配的问题。如图1-2所示,一个设备产生的原始数据在封装了语义描述之后,可以更加容易地与其他设备的数据进行融合、交换和互操作,并可以进一步链接进入知识图谱中,以便支持搜索、推理和分析等任务。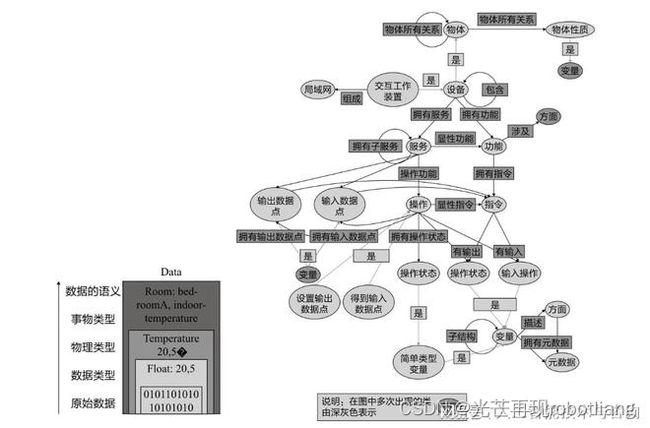
图1-2 设备语义的封装
2.OpenKG开源工具的试用
2.1 Jiagu自然语言处理工具概述
Jiagu以BiLSTM等模型为基础,使用大规模语料训练而成。将提供中文分词、词性标注、命名实体识别、情感分析、知识图谱关系抽取、关键词抽取、文本摘要、新词发现等常用自然语言处理功能。参考了各大工具优缺点制作,将Jiagu回馈给大家。
2.2 Jiagu自然语言处理工具部署到本地
2.2.1下载Jiagu
首先我们进入OpenKG官网找到该项目开源的页面。这是思知机器人公司开源的一个知识图谱工具。然后我们进入Github进行下载该项目即可即可。

图2-1 OpenKG官网查看Jiagu
图2-2 Github查看Jiagu开源项目
2.2.2为Jiagu创建虚拟环境
我们首先需要安装有anaconda来创建环境
首先我们打开anaconda依次输入如下命令即可
conda create -n Jiagu python=3.8
conda activate Jiagu
然后再输入python3 setup.py install

图2-3 用anaconda创建一个虚拟环境
图2-4 安装JiaguNLP工具
图2-5 成功安装Jiagu
接下来安装numpy
图2-6 numpy安装
接下来还需要再安装matplotlib

图2-7 matplotlib安装
这样我们所需的三个包,jiagu、matplotlib、numpy就安装完成了。
2.3 Jiagu实例运行使用
2.3.1分词、词性标注、命名实体识别
运行python代码如下:
import jiagu
#jiagu.init() # 可手动初始化,也可以动态初始化
text = '厦门明天会不会下雨'
words = jiagu.seg(text) # 分词
print(words)
pos = jiagu.pos(words) # 词性标注
print(pos)
ner = jiagu.ner(words) # 命名实体识别
print(ner)

图2-8 分词、词性标注、命名实体识别
2.3.2 demo测试
接下来我们运行demo进行测试
测试代码如下:
import jiagu
# jiagu.init() # 可手动初始化,也可以动态初始化
text = '苏州的天气不错'
words = jiagu.seg(text) # 分词
print(words)
words = jiagu.cut(text) # 分词
print(words)
pos = jiagu.pos(words) # 词性标注
print(pos)
ner = jiagu.ner(words) # 命名实体识别
print(ner)
# 字典模式分词
text = '思知机器人挺好用的'
words = jiagu.seg(text)
print(words)
# jiagu.load_userdict('dict/user.dict') # 加载自定义字典,支持字典路径、字典列表形式。
jiagu.load_userdict(['思知机器人'])
words = jiagu.seg(text)
print(words)
text = '''
该研究主持者之一、波士顿大学地球与环境科学系博士陈池(音)表示,“尽管中国和印度国土面积仅占全球陆地的9%,但两国为这一绿化过程贡献超过三分之一。考虑到人口过多的国家一般存在对土地过度利用的问题,这个发现令人吃惊。”
NASA埃姆斯研究中心的科学家拉玛·内曼尼(Rama Nemani)说,“这一长期数据能让我们深入分析地表绿化背后的影响因素。我们一开始以为,植被增加是由于更多二氧化碳排放,导致气候更加温暖、潮湿,适宜生长。”
“MODIS的数据让我们能在非常小的尺度上理解这一现象,我们发现人类活动也作出了贡献。”
NASA文章介绍,在中国为全球绿化进程做出的贡献中,有42%来源于植树造林工程,对于减少土壤侵蚀、空气污染与气候变化发挥了作用。
据观察者网过往报道,2017年我国全国共完成造林736.2万公顷、森林抚育830.2万公顷。其中,天然林资源保护工程完成造林26万公顷,退耕还林工程完成造林91.2万公顷。京津风沙源治理工程完成造林18.5万公顷。三北及长江流域等重点防护林体系工程完成造林99.1万公顷。完成国家储备林建设任务68万公顷。
'''
keywords = jiagu.keywords(text, 5) # 关键词抽取
print(keywords)
summarize = jiagu.summarize(text, 3) # 文本摘要
print(summarize)
# jiagu.findword('input.txt', 'output.txt') # 根据大规模语料,利用信息熵做新词发现。
# 知识图谱关系抽取
text = '姚明1980年9月12日出生于上海市徐汇区,祖籍江苏省苏州市吴江区震泽镇,前中国职业篮球运动员,司职中锋,现任中职联公司董事长兼总经理。'
knowledge = jiagu.knowledge(text)
print(knowledge)
# 情感分析
text = '很讨厌还是个懒鬼'
sentiment = jiagu.sentiment(text)
print(sentiment)
# 文本聚类(需要调参)
docs = [
"百度深度学习中文情感分析工具Senta试用及在线测试",
"情感分析是自然语言处理里面一个热门话题",
"AI Challenger 2018 文本挖掘类竞赛相关解决方案及代码汇总",
"深度学习实践:从零开始做电影评论文本情感分析",
"BERT相关论文、文章和代码资源汇总",
"将不同长度的句子用BERT预训练模型编码,映射到一个固定长度的向量上",
"自然语言处理工具包spaCy介绍",
"现在可以快速测试一下spaCy的相关功能,我们以英文数据为例,spaCy目前主要支持英文和德文"
]
cluster = jiagu.text_cluster(docs)
print(cluster)
代码运行结果截图如下:
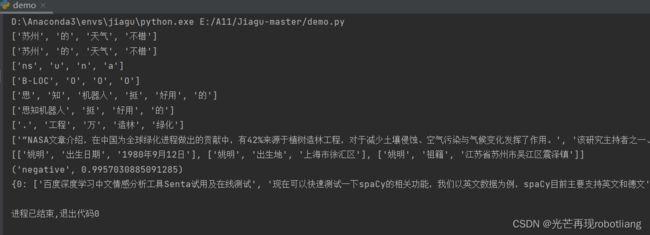
图2-9 demo运行成功
2.3.3中文分词
运行代码如下:
import jiagu
text = '汉服和服装、维基图谱'
words = jiagu.seg(text)
print(words)
# jiagu.load_userdict('dict/user.dict') # 加载自定义字典,支持字典路径、字典列表形式。
jiagu.load_userdict(['汉服和服装'])
words = jiagu.seg(text) # 自定义分词,字典分词模式有效
print(words)
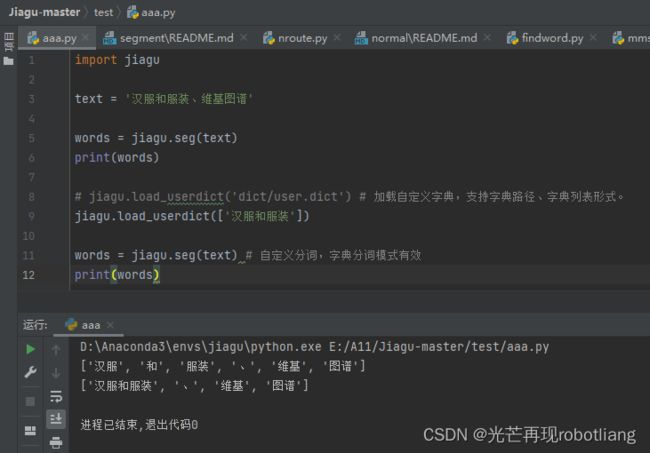
图2-10运行中文分词
2.3.4知识图谱关系抽取
本案例只能使用百科的描述进行测试。作者提出效果更佳的后期将会开放api。
代码如下:
import jiagu
# 吻别是由张学友演唱的一首歌曲。
# 《盗墓笔记》是2014年欢瑞世纪影视传媒股份有限公司出品的一部网络季播剧,改编自南派三叔所著的同名小说,由郑保瑞和罗永昌联合导演,李易峰、杨洋、唐嫣、刘天佐、张智尧、魏巍等主演。
text = '姚明1980年9月12日出生于上海市徐汇区,祖籍江苏省苏州市吴江区震泽镇,前中国职业篮球运动员,司职中锋,现任中职联公司董事长兼总经理。'
knowledge = jiagu.knowledge(text)
print(knowledge)
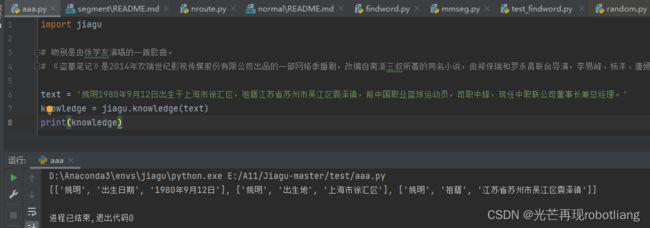
图2-11 运行关系抽取
2.3.5关键词抽取
代码如下:
import jiagu
text = '''
该研究主持者之一、波士顿大学地球与环境科学系博士陈池(音)表示,“尽管中国和印度国土面积仅占全球陆地的9%,但两国为这一绿化过程贡献超过三分之一。考虑到人口过多的国家一般存在对土地过度利用的问题,这个发现令人吃惊。”
NASA埃姆斯研究中心的科学家拉玛·内曼尼(Rama Nemani)说,“这一长期数据能让我们深入分析地表绿化背后的影响因素。我们一开始以为,植被增加是由于更多二氧化碳排放,导致气候更加温暖、潮湿,适宜生长。”
“MODIS的数据让我们能在非常小的尺度上理解这一现象,我们发现人类活动也作出了贡献。”
NASA文章介绍,在中国为全球绿化进程做出的贡献中,有42%来源于植树造林工程,对于减少土壤侵蚀、空气污染与气候变化发挥了作用。
据观察者网过往报道,2017年我国全国共完成造林736.2万公顷、森林抚育830.2万公顷。其中,天然林资源保护工程完成造林26万公顷,退耕还林工程完成造林91.2万公顷。京津风沙源治理工程完成造林18.5万公顷。三北及长江流域等重点防护林体系工程完成造林99.1万公顷。完成国家储备林建设任务68万公顷。
'''
keywords = jiagu.keywords(text, 5) # 关键词
print(keywords)

图2-12运行关键词抽取
2.3.6情感分析
代码如下:
import jiagu
text = '很讨厌还是个懒鬼'
sentiment = jiagu.sentiment(text)
print(sentiment)
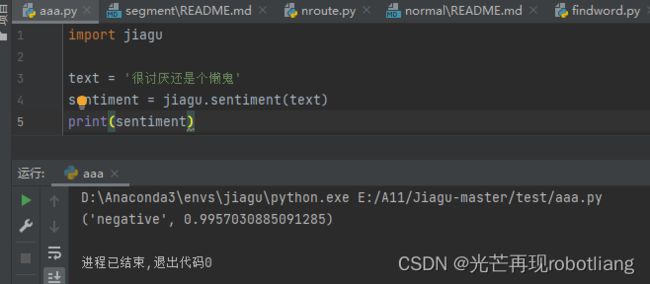
图2-13 运行情感分析
2.3.7文本聚类
代码如下:
import jiagu
docs = [
"百度深度学习中文情感分析工具Senta试用及在线测试",
"情感分析是自然语言处理里面一个热门话题",
"AI Challenger 2018 文本挖掘类竞赛相关解决方案及代码汇总",
"深度学习实践:从零开始做电影评论文本情感分析",
"BERT相关论文、文章和代码资源汇总",
"将不同长度的句子用BERT预训练模型编码,映射到一个固定长度的向量上",
"自然语言处理工具包spaCy介绍",
"现在可以快速测试一下spaCy的相关功能,我们以英文数据为例,spaCy目前主要支持英文和德文"
]
cluster = jiagu.text_cluster(docs)
print(cluster)
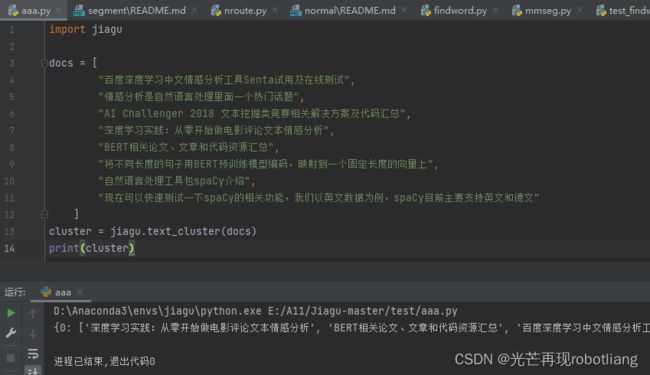
图2-14 运行文本聚类
2.3.8词性说明
n 普通名词 nt 时间名词 nd 方位名词 nl 处所名词
nh 人名 nhf 姓 nhs 名 ns 地名
ni 机构名 nz 其他专名 v 动词
vd 趋向动词 vl 联系动词 vu 能愿动词 a 形容词
f 区别词 m 数词 q 量词 d 副词
r 代词 p 介词 c 连词 nn 族名
u 助词 e 叹词 o 拟声词
i 习用语 j 缩略语 h 前接成分
k 后接成分 g 语素字 x 非语素字
w 标点符号 ws非汉字字符串 wu 其他未知的符号
2.3.9命名实体说明
B-PER、I-PER 人名
B-LOC、I-LOC 地名
B-ORG、I-ORG 机构名
2.4 报错与解决
报错1:代码运行报错:TypeError: Population must be a sequence or set. For dicts, use list(d)
解决报错1:
修改:用list()包起来即可
features = random.sample(list(dataSet.columns.values[:-1]), int(math.sqrt(m - 1)))
3.OPENKG与Neo4j的交互联动
3.1 功能设计
OpenKG主要关注知识图谱数据(或者称为结构化数据、语义数据、知识库)的开放,广义上OpenKG属于开放数据的一种。它是中国中文信息学会语言与知识计算专业委员会于2015年发起和倡导的开放知识图谱社区联盟项目。旨在推动以中文为基础的知识图谱数据的开放、互联与众包,以及知识图谱算法、工具和平台的开源开放工作。
Neo4j是一个高性能的,NOSQL数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事物特性的java持久化引擎。Neo4j也可以看作是一个高性能的图引擎,该引擎具有成熟数据库所有特性。登录openKG中文开放知识图谱获取图谱csv文件,将文件导入neo4j中并运行,之后对其进行图谱可视化,关系联接可视化。本次openKG与neo4j项目我将学习如何把Neo4j 知识图谱CSV导入之海洋鱼类知识百科。
3.2 csv导入流程
3.2.1 下载csv文件
然后我们进入OpenKG官网下载海洋鱼类百科知识图谱的CSV文件,如图3-2。其csv编码格式为UTF-8格式。
图3-1 网页下载CSV文件

图3-2 下载好的CSV文件
3.2.2导入csv文件
接下来进行的是导入该csv文件我们可以首先进入neo4j的主目E:\NEO4J_HOME\bin
然后cmd输入命令,如图3-3;然后等待几秒钟,即可成功导入这两个csv文件。
显示导入37449nodes(节点),114863relationships(关系),572742properties。
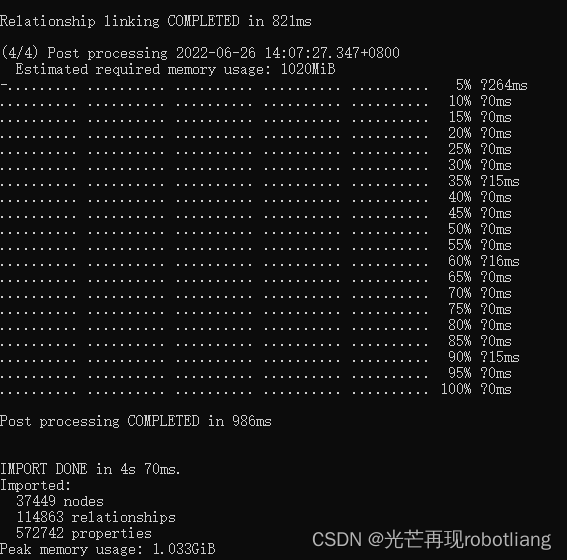
图3-3 成功导入csv文件
3.2.3 修改neo4j默认数据库
修改配置文件,将conf文件夹下的neo4j.conf中dbms.active_database = neo4j.db 修改为
dbms.active_database =自己的数据库名称.db,并将前面的#号删除。
这里我修改neo4j为onepice.db
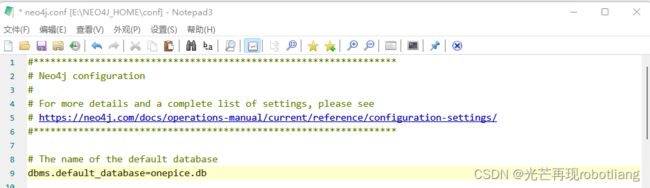
图3-4修改neo4j默认数据库
3.2.4 运行启动Neo4j网页版
首先我们进入NEO4J_HOME\bin\打开cmd输入neo4j.bat.console运行neo4j网页,进入localhost地址为http://localhost:7474/即可看到网页版页面,如图3-1。
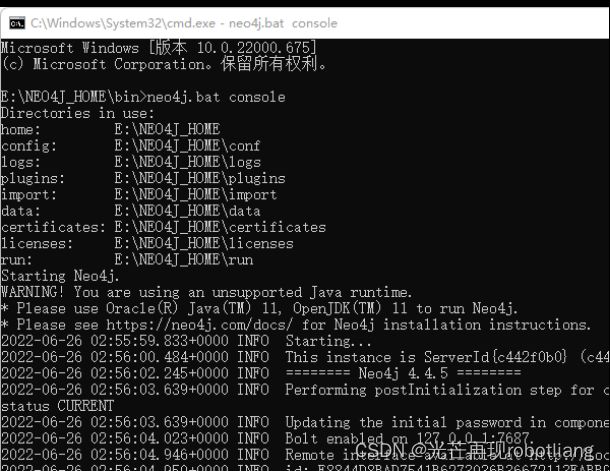
图3-5启动localhost的neo4j
3.3 可视化和知识查询操作
3.3.1可视化整张知识图谱
在Neo4j本地⽹⻚终端中输⼊:MATCH (n) RETURN (n)。

图3-6 图谱可视化
3.3.2 知识查询
例如,若要在在Neo4j本地⽹⻚终端中查询尼罗口孵、秘鲁鳀、莫桑比克口孵非鲫这三种鱼类的分布国家区域 ,则输⼊:
MATCH p=()-->() RETURN p LIMIT 25,输入如下图所示。
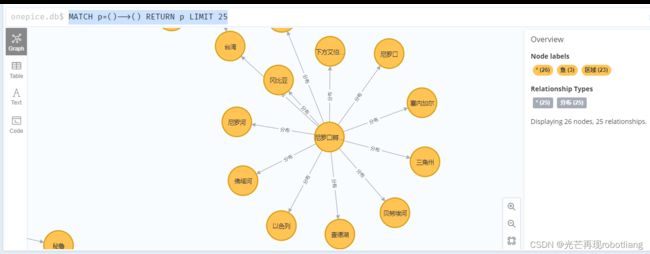
图3-7 知识查询