推荐系统多目标学习之loss权重
前言
多目标学习是推荐算法中很常见的关键点, 通常信息流推荐算法的有ctr, 互动率, 时长等目标。假如只单独优化其中一个肯定无法留存用户或者创收, 譬如只看点击率ctr的话很容易出现一些标题党, 只看互动率的话很多转发保平安的帖子会排序分很高。 因此如何在一个共识或者一套模型中实现多种目标的提升是很多算法组的期望。
多目标学习分类与演近
对于多目标学习的各类方法,很多文章进行了很好的总结。 譬如下面两个链接。
https://lumingdong.cn/multi-task-learning-in-recommendation-system.html#多目标排序综述
https://mp.weixin.qq.com/s/c7BdWUM9BFQZfzWP7C_wfQ
为了方便理解阅读,我也在这里主要讲述下各种从易到难的方法:
1, 通过样本权重进行多目标优化
对二分类问题cross entropy loss进行reweight, 对目标样本加权。 方法原理比较简单,但是需要一定业务知识,并且不断尝试。下面这个链接是业界写的最清晰的。
https://zhuanlan.zhihu.com/p/271858727
2,多模型分数融合
针对每个要优化的目标建立单独的模型, 将每个模型的预测分根据一定的权重加权融合给推荐系统, 这个权重通常通过abtest测出来, 在我司,组内主要kpi指标那个权重会远大于其他两个权重。
这种方式也是工业界大多数公司采取的比较实际的方法。
3, 多任务深度学习
最后这种方法, 广泛存在于学术论文与能落地的一些顶尖大厂, 使用深度学习实现多目标的优化。 通常多目标之间有个共享层(可以是hard-parameter或者moe层)然后共享层上面接上两三个单独的深度层来优化各个目标。
共享层的好处是能够让多任务之间可以学习到相关信息,共同信息。 对于只有稀疏数据的任务也可以从其他稍密数据的任务中学习, 并且多任务互相约束调整不容易进入局部最优点。
业界出名的多任务学习是阿里的ESSM和谷歌的MMOE,这类多任务深度学习的主要难点就是多个loss相加时的权重问题。
讲述这些方法有以下链接
https://zhuanlan.zhihu.com/p/269492239
https://zhuanlan.zhihu.com/p/56613537
a, 对不同任务采用不同学习率
b, 对不同任务采用不同优化器
c, 先训练a任务再训练b任务
d, 先简单相加loss, 最后根据loss曲线稳定的量级进行加权,使得loss量级保持一致
e,利用任务的不确定性作为loss权重
f, 利用任务的训练学习难度来作为权重loss权重
重点介绍e, f 与其 实现
利用任务的不确定性作为loss权重
原文在这里:
《Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics》
首先作者用一个回归问题的概率模型来解释这个不确定性
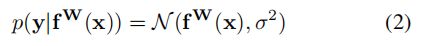
所有回归值落在预测值y方差sigma左右
多个任务的概率如下图推倒, 最后引出公式7
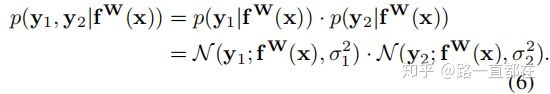

对于分类问题, 作者给出下列公式, 但是由于我们的场景是二分类问题,这边sigmoid可以是softmax。 至于为什么 f(x) 要除以sigma的平方, 作者说这边sigma类比吉布斯分布/ 玻尔兹曼分布的温度, 解释的不是很清晰,我个人理解就是温度越高系统越不稳定, 类似方差越大, 不确定性也大
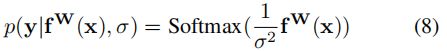
作者给出了一个回归一个分类多任务学习的最终公式
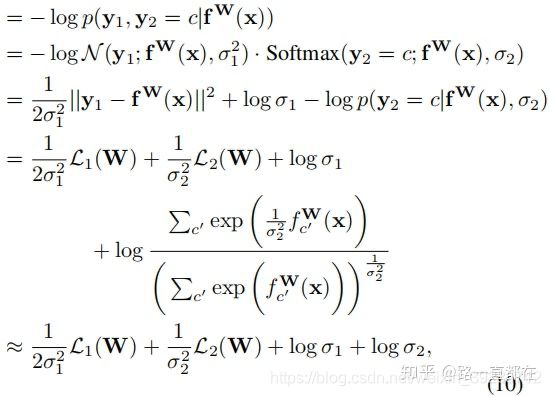
我的双分类问题的实现
loss = tf.exp(-log_var_1)* loss_1 + tf.exp(-log_var_2)* loss_2 + log_var_1 + log_var_2
第一, 公式中对于分类问题, sigma之前的分母系数为1,因此我们置1
第二,为什么实现中使用e的log(方差),这是防止分母为0。
log_var 初始值为设置为0.0
最后的理解, sigma这边原文提出来是一个可以学习的参数, 因此我们也将作为tf variable 一起训练。 其次 sigma不仅作为loss的权重, 它作为公式尾的一个系数, 也起到正则化的作用。
利用任务的训练学习难度来作为权重loss权重
上面一种方法可以看到作者倾向于不确定性更小的任务主导训练(我理解为更容易的任务), 这也比较好理解, 让容易任务主导共享层, 难的任务能更直接获得共享知识。
但是李飞飞这篇文章不这么认同,《Dynamic task prioritization for multitask learning》
她觉得难的任务应该给予更高的权重, 先肯最硬的骨头。
所谓的难易,主要体现在kpi上, 也就是文中说的Kt, 这个值可以是acc也可以是auc。我在这里使用auc。
文中提出这里最终kpi要使用一个平滑表示, 这也比较好理解。 因此我这里将k设置为一个variable, 初始值为0.0, 每次传入后续function中进行迭代。
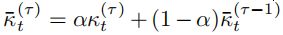
作者给出最终权重loss公式是 :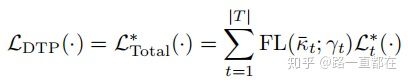
这其中使用了focal loss封装在kpi外面,作用是 focal loss给那些容易区分的样本更小的权重,使得在训练过程中,模型能更聚焦那些困难任务。
我的三分类问题的实现
# Dynamic Task Prioritization
def focal_loss_dtp(auc,k,alpha=0.95, gamma=2.0):
k = alpha * auc + (1-alpha) * k
return -tf.pow(1-k, gamma) * tf.log(k)
dtp_1 = focal_loss_dtp(auc_1[1], k_1)
dtp_2 = focal_loss_dtp(auc_2[1], k_2)
dtp_3 = focal_loss_dtp(auc_3[1], k_3)
loss = dtp_1 * loss_1 + dtp_2 * loss_2 + dtp_3 * loss_3
至于为什么上面两种阐述的方法正好大相径庭, 这篇知乎最下面也给出了一定的解释。https://zhuanlan.zhihu.com/p/269492239。
不确定性建模似乎可以适用于标签噪声更大的数据,而DTP可能在干净的标注数据里效果更好。具体还有待我们的实验。