EGES召回原理与优化
文章目录
- 一、什么是EGES召回
- 二、为什么我们需要双塔召回
- 三、EGES过程与优化点
-
- 采样用户行为序列
- 构建物料的有向图
- 随机游走生成物料序列
- 利用word2vec生成物料embedding(之前用序列生成正负样本);
- 四、其他
-
- loss设置
- 特征改进
- 新物料冷启动embedding
- 五、离线评估
一、什么是EGES召回
上一篇我们提到DSSM召回,是经典的U2I召回,这一篇EGES是I2I召回。 通过用户行为日志取得物料序列,生成图后利用物料的共现性用skip-gram生成物料embedding。
上线时现获得最近互动/点击序列物料然后用这些物料的embedding去Faiss召回候选物料
二、为什么我们需要双塔召回
这是淘宝发表在 KDD 2018 上的关于商品 embedding 生成的文章,主要为了解决商品推荐系统面临三个主要问题:可扩展性、稀疏性和冷启动问题。
稀疏性:由于用户往往只与少量物料进行交互,因此很难训练出准确的推荐模型,尤其是对于交互次数很少的用户或物品。它通常被称为“稀疏”问题。
冷启动:在推荐场景,每小时都有数以百万计的新物料不断上传。这些物料没有用户行为。处理这些物料或预测用户对这些物料的偏好具有挑战性,这就是所谓的“冷启动”问题。
我的理解下是,因为只对item建立embedding,那么及时一个item只有少数人互动/点击,也能在整个Graph上有多条边可以供随机游走产生序列。
三、EGES过程与优化点
1, 采样用户行为序列
2, 构建物料的有向图;
3, 随机游走生成物料序列;
4, 利用word2vec生成物料embedding(之前用序列生成正负样本);
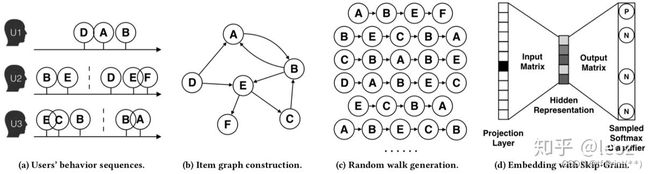
具体就这几个步骤中的一些优化点展开:
采样用户行为序列
- 采样用户互动和点击的序列
- 使用了上一章DSSM中热度打压的方法, 热度过高的物料不采入序列
- 两次互动/点击之间超过1小时算成两个序列
构建物料的有向图
- 边的权重为两个物料id之间出现的个数
随机游走生成物料序列
- 使用石塔西前辈的Graph Embedding代码中RandomWalker构建随机游走。
- 采用一种有偏的随机游走策略(node2vec ),通过引入两个超参数来决定游走是偏向于向远离初始点的方向探索,还是围绕初始点附近进行探索,因此更加灵活,但是初始化的效率比较低。参数设置:walker = RandomWalker(G, p=2, q=4)
- 游走最大走五步,walk_length=5。 同一个节点最多走三次,walk_repeat_num=3
利用word2vec生成物料embedding(之前用序列生成正负样本);
- 正样本采样:得到游走序列后, skip-gram 窗口设置为4, 代码如下
traces = self.walker.simulate_walks(self.num_walks, self.walk_length, workers=2, verbose=10)
traces = list(filter(lambda x: len(x) > 2, traces))
# skip-gram
pairs = []
for trace in tqdm(traces, desc="generate pos sample"):
for i in range(len(trace)):
center = trace[i]
left = max(0, i - self.window_size) # skip-gram 窗口
right = min(len(trace), i + self.window_size + 1)
# for j in range(left, right):
# pair = [center, trace[j], 1]
# if i == j or pair in pairs:
# continue
# pairs.append(pair)
pairs.extend([(center, x, 1) for x in trace[left:i]])
pairs.extend([(center, x, 1) for x in trace[i + 1:right]])
- 负样本:按照节点入度作为采样权重全局采样 。Multinomial:权重采样。 5倍负采样。
四、其他
loss设置
按照上面正样本负样本采样最后得到下面式样的样本:
item(center) item(positive) 1
item(center) item(negative1) 0
使用binary cross entropy求loss, 其中label表示y。 u,v分别是中心节点和它的邻居节点
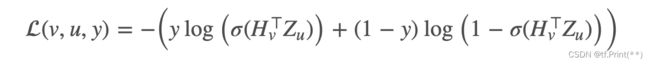
def loss(self, src_embeddings, dst_embeddings, labels):
# TODO concat or dot product embeddings for SoftMax and then cross_entropy
# skip-gram把多分类问题转化为0-1分类问题
logits = torch.sum(src_embeddings * dst_embeddings, dim=-1)
logits = self.sigmoid(logits)
logits = torch.clamp(logits, min=1e-7, max=1 - 1e-7)
return torch.mean(- (labels * torch.log(logits) + (1 - labels) * torch.log(1 - logits)))
特征改进
因为我们的实现场景, 物料变化很快时效性很强,所以没有使用物料id。
而是将物料特征从embedding table拿到后平均池化得到相应物料embedding。
并且因为没有id可以标识记录每个物料对应的 阿尔法 权重, 因此这边本质不是EGES, 而是GES
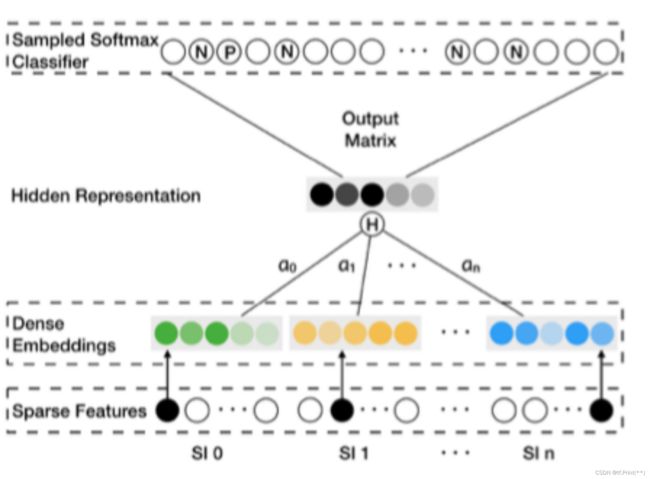
新物料冷启动embedding
对于新商品,在入库时就需要基于其 side information 查询相应的 embedding,如果是EGES的话因为找不到其对应权重向量,所以直接求平均 embedding 作为新商品的 embedding 并缓存
五、离线评估
Embedding 的离线评估是很困难的。原文提出一种连接预测的方式,也就是把图中随机选一些有向边作为正例,随机构造一些不存在的有向边作为负例来测试模型。除了这种方式,还可以通过选择一些典型的 case 来将各维度的 embedding 进行可视化,或者召回相似列表,看看是否满足主观预期,但是这种方式可以用来理解和优化,不适合用于评估。( 淘宝商品向量生成模型 EGES)
相关链接:
链接1: GES、EGES:阿里结合side information的推荐系统召回算法
为什么不直接拿用户的行为序列进行embedding,而是先利用用户序列构造一个item graph,然后进行随机左右,回过头来再生成序列,我觉有有两方面原因可以考虑,一是样本分布的问题,因为直接拿用户的行为序列,会存在一些item出现的次数很少,而不能进行充分的训练,而经过随机游走(随机游走会将每个node作为游走种子N次)之后,就能够避免训练不充分这种情况,再就是兼顾了有部分序列在用户真实序列中没有出现,但是在实际情况中很有可能出现的这种情况,例如上图中,U1真实序列是D->A->B,但在实际中,有很多的B->E,这样如果直接拿用户的真实序列,就不会有A->B->E这种序列,这样可能就直观上认为A与E没有相似性,但实际情况可能由于用户U1因为一些原因,如没有给用户U1曝光B,导致用户U1在浏览完A后就没有继续浏览B了,所以兼顾了这种情况。
链接2: 淘宝商品向量生成模型 EGES
链接3: i2i召回算法:EGES