长链到短链转化
文章目录
-
- 1:为什么将长链转化为短链?
- 2:短链跳转的基本原理
- 3:将长链转化为短链(Hash)
-
- 3.1:hash
-
- 3.1.1:hash算法的选取
- 3.1.2hash后还是有点长
- 3.1.3:解决hash冲突
- 3.2:自增序列算法
1:为什么将长链转化为短链?
1、链接变短,在对内容长度有限制的平台发文,可编辑的文字就变多了(比如短信链接,微博链接等对字数有要求)
2、我们经常需要将链接转成二维码的形式分享给他人,如果是长链的话二维码密集难识别
3、便于用户粘贴复制,形式上比较美观
2:短链跳转的基本原理
在浏览器输入短链地址后,返回状态码302(重定向)和location 值为长链的响应,然后浏览器会再请求这个长链以得到最终的响应。

由上面可以看出,主要的步骤就是通过长链重定向到短链,重定向有301和302(推荐使用):
–301,代表 永久重定向,也就是说第一次请求拿到长链接后,下次浏览器再去请求短链的话,不会向短网址服务器请求了,而是直接从浏览器的缓存里拿,这样在 server 层面就无法获取到短网址的点击数了,如果这个链接刚好是某个活动的链接,也就无法分析此活动的效果。所以我们一般不采用 301。
–302,代表 临时重定向,也就是说每次去请求短链都会去请求短网址服务器(除非响应中用 Cache-Control 或 Expired 暗示浏览器缓存),这样就便于 server 统计点击数,所以虽然用 302 会给 server 增加一点压力,但在数据异常重要的今天,这点代码是值得的,所以推荐使用 302!
3:将长链转化为短链(Hash)
3.1:hash
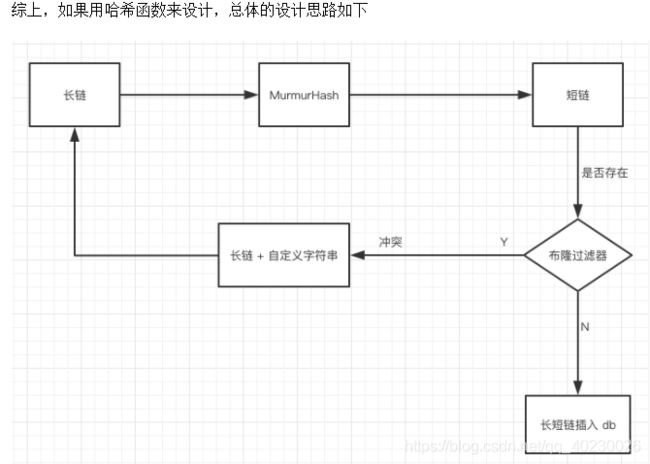
通过Hash将长链转化成一串字母,然后固定固定短链域名+Hash后的字母作为短链。
3.1.1:hash算法的选取
MD5,SHA 等算法是加密算法,会在性能上有所损失,可以使用 Google 出品的 MurmurHash 算法,MurmurHash 是一种非加密型哈希函数,适用于一般的哈希检索操作,性能优于 MD5,SHA 等算法。
MurmurHash 提供了两种长度的哈希值,32 bit,128 bit,为了让网址尽可通地短,我们选择 32 bit 的哈希值,32 bit 能表示的最大值近 43 亿,已经足够应付大多数的场景了。
3.1.2hash后还是有点长
MurmurHash 算法hash之后的数字是10进制,可以再将这串数字转化成64进制,进一步缩短长度。
3.1.3:解决hash冲突
将一个长链hash之后,在经过64进制的转化,得到短链后缀,可以将长链和这个后缀 存入mysql数据库,进行映射。为了避免多个长链对应一个短链后缀的出现,可以给锻炼后缀字段设置一个唯一索引,当进行存储时,如果发生hash冲突,这一条数据就无法添加进数据库。然后,拿到这个长链,在长串上拼接一个自定义好的字段,对拼接好的字符串再去做hash,然后64进制转化,然后存储。再有hash冲突,重复上面的操作。
当然如果在数据量很大的情况下,冲突的概率会增大,此时我们可以加布隆过滤器来进行优化。用所有生成的短网址构建布隆过滤器,当一个新的长链生成短链后,先将此短链在布隆过滤器中进行查找,如果不存在,说明 db 里不存在此短网址,可以插入!
3.2:自增序列算法
我们可以维护一个 ID 自增生成器,比如 1,2,3 这样的整数递增 ID,当收到一个长链转短链的请求时,ID 生成器为其分配一个 ID,再将其转化为 62 进制,拼接到短链域名后面就得到了最终的短网址.
主要有以下四种获取 id 的方法
1、类 uuid
简单地说就是用 UUID uuid = UUID.randomUUID(); 这种方式生成的 UUID,UUID(Universally Unique Identifier)全局唯一标识符,是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的,但这种方式生成的 id 比较长,且无序,在插入 db 时可能会频繁导致页分裂,影响插入性能。
2、Redis
用 Redis 是个不错的选择,性能好,单机可支撑 10 w+ 请求,足以应付大部分的业务场景,但有人说如果一台机器扛不住呢,可以设置多台嘛,比如我布置 10 台机器,每台机器分别只生成尾号0,1,2,… 9 的 ID, 每次加 10 即可,只要设置一个 ID 生成器代理随机分配给发号器生成 ID 就行了。
图片
不过用 Redis 这种方案,需要考虑持久化(短链 ID 总不能一样吧),灾备,成本有点高。
3、Snowflake
用 Snowflake 也是个不错的选择,不过 Snowflake 依赖于系统时钟的一致性。如果某台机器的系统时钟回拨,有可能造成 ID 冲突,或者 ID 乱序。
4、Mysql 自增主键
这种方式使用简单,扩展方便,所以我们使用 Mysql 的自增主键来作为短链的 id。简单总结如下:

那么问题来了,如果用 Mysql 自增 id 作为短链 ID,在高并发下,db 的写压力会很大,这种情况该怎么办呢。
考虑一下,一定要在用到的时候去生成 id 吗,是否可以提前生成这些自增 id ?
方案如下:
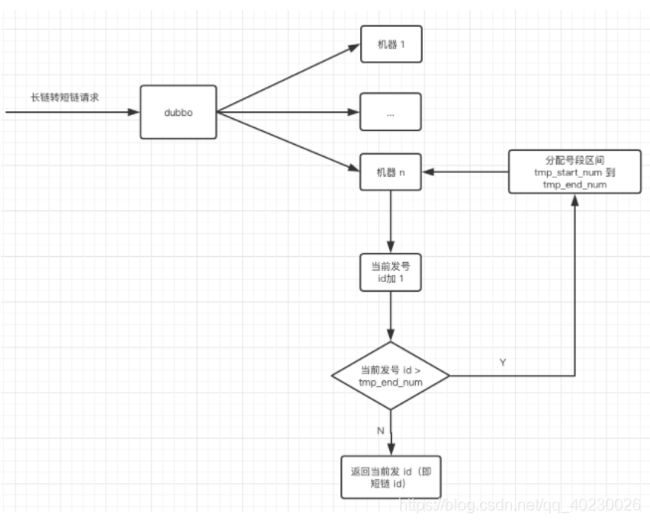
设计一个专门的发号表,每插入一条记录,为短链 id 预留 (主键 id * 1000 - 999) 到 (主键 id * 1000) 的号段,如下
发号表:url_sender_num

如图示:tmp_start_num 代表短链的起始 id,tmp_end_num 代表短链的终止 id。
当长链转短链的请求打到某台机器时,先看这台机器是否分配了短链号段,未分配就往发号表插入一条记录,则这台机器将为短链分配范围在 tmp_start_num 到 tmp_end_num 之间的 id。从 tmp_start_num 开始分配,一直分配到 tmp_end_num,如果发号 id 达到了 tmp_end_num,说明这个区间段的 id 已经分配完了,则再往发号表插入一条记录就又获取了一个发号 id 区间。
画外音:思考一下这个自增短链 id 在机器上该怎么实现呢, 可以用 redis, 不过更简单的方案是用 AtomicLong,单机上性能不错,也保证了并发的安全性,当然如果并发量很大,AtomicLong 的表现就不太行了,可以考虑用 LongAdder,在高并发下表现更加优秀。
整体设计图如下:
解决了发号器问题,接下来就简单了,从发号器拿过来的 id ,即为短链 id,接下来我们再创建一个长短链的映射表即可, 短链 id 即为主键,不过这里有个需要注意的地方,我们可能需要防止多次相同的长链生成不同的短链 id 这种情况,这就需要每次先根据长链来查找 db 看是否存在相关记录,一般的做法是给长链加索引,但这样的话索引的空间会很大,所以我们可以对长链适当的压缩,比如 md5,再对长链的 md5 字段做索引,索引就会小很多。这样只要根据长链的 md5 去表里查是否存在相同的记录即可。所以我们设计的表如下
CREATE TABLE `short_url_map` (
`id`int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT'短链 id',
`lurl`varchar(10) DEFAULT NULL COMMENT'长链',
`md5`char(32) DEFAULT NULL COMMENT'长链md5',
`gmt_create`int(11) DEFAULT NULL COMMENT'创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
当然了,数据量如果很大的话,后期就需要分区或分库分表了。
注意:本文多来自https://mp.weixin.qq.com/s/YTrBaERcyjvw7A0Fg2Iegw