基于卷积神经网络的乳腺癌图像分类
摘要:
乳腺癌是世界范围内癌症死亡的主要原因之一。用苏木精和伊红染色图像对活检组织进行诊断并非易事,专家通常不同意最终诊断。计算机辅助诊断系统有助于降低成本,提高诊断效率。传统的分类方法依赖于针对基于现场知识的特定问题设计的特征提取方法。为了克服基于特征的方法的许多困难,深度学习方法正成为重要的替代方法。提出了一种使用卷积神经网络 (CNNs) 对苏木精和伊红染色的乳房活检图像进行分类的方法。图像分为四类,正常组织,良性病变,原位癌和浸润性癌,分为两类,癌和非癌。网络的体系结构旨在检索不同规模的信息,包括核和整个组织组织。这种设计允许将所提出的系统扩展到整个幻灯片组织学图像。 CNN 提取的特征也用于训练支持向量机分类器。四类的准确度为 77.8%,癌/非癌的准确率为 83.3%。我们的方法对癌症病例的敏感性为 95.6%。
介绍
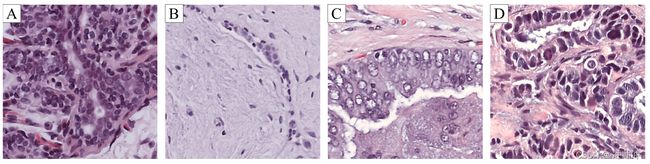
乳腺癌是 20 至 59 岁女性癌症死亡的第一原因,是 59 岁以上女性的第二位癌症死亡原因。在早期阶段诊断和治疗这种病理对于预防疾病的进展和降低其发病率至关重要。乳腺癌的诊断通常包括通过触诊和使用乳房X光摄影或超声成像的定期检查进行初步检测。如果体检显示癌组织生长的可能性,则诊断后进行乳腺组织活检。乳腺组织活检允许病理学家从组织学上评估组织的微观结构和成分。组织学可以区分正常组织、非恶性(良性)和恶性病变,并进行预后评估。良性病变代表与进展为恶性肿瘤没有直接关系的乳房实质正常结构的变化。癌可分为原位癌或侵袭性癌。在原位癌中,细胞被限制在乳腺导管-小叶系统内,而在浸润性癌中,细胞扩散到该结构之外。活检期间采集的组织通常在专家进行视觉分析之前用苏木精和伊红(H&E)染色。在此过程中,评估全玻片组织扫描的相关区域。图1显示了用H&E染色的整张幻灯片图像中提到的每一类照片的一个例子。这种染色增强了细胞核(紫色)和细胞质(粉红色),以及其他感兴趣的结构。
在分析染色组织的过程中,病理学家分析整体组织结构,以及细胞核组织、密度和变异性。例如,浸润性癌组织表现出结构的扭曲,以及更高的细胞核密度和变异性(图1-D),而在正常组织中,结构得以维持,细胞核组织良好(图1-a)。
使用H & E染色活检的诊断过程并非微不足道,专家之间的平均诊断一致性约为75%。手工检查组织学图像需要高度专业的病理学家的工作量。在通常分类中应用形态学标准的主观性促使使用计算机辅助诊断 (CAD) 系统来提高诊断效率并提高观察者之间的一致性。
相关工作:
CAD系统嵌入了图像分析和机器学习方法,以帮助医生在诊断过程中。作为第二意见系统,CAD系统减少了专家的工作量,有助于提高诊断效率和降低成本。为此,通常会尝试复制医生的方法。例如,对核形态的分析可足以将组织分类为良性或恶性 [10] 。图1.使用数据集的显微图像补丁示例 [3] 。由于苏木精和伊红染色,细胞核和细胞质分别呈紫色和粉红色。a正常组织;b良性异常;c恶性原位癌;D恶性浸润性癌。
因此,一些工作侧重于恶性-良性分类的细胞核分析。Kowal等人[11]使用不同的聚类算法对细针活检的显微图像进行细胞核分割。形态学、拓扑学和纹理特征被用于训练分类器,在50名患者的500张图像上实现了84%到93%的准确率。通过对每张10张图像进行多数投票,对病人进行分类,准确率为96-100%。同样,Filipczuk等人[12]和George等人[13]从细针活检中提取了基于核的特征。首先,圆形Hough变换被用于检测候选核,然后用机器学习和Otsu阈值法减少假阳性。在George等人的[13]中,使用分水岭算法进一步细化了核分割。这两种方法都利用核的形状和纹理特征来训练不同的分类器。Filipczuk等人的[12]达到了98.51%的准确率,每67名患者通过11张图像的多数投票,而George等人的[13]在使用92张图像的单个图像分类中达到了71.9%到97.15%的准确率。除了与细胞核有关的信息,Belsare等人[14]还考虑了组织组织,用于对更复杂的图像进行二元分类。作者评估了来自私人40倍放大率乳腺组织学H&E数据集的70幅图像。空间色彩-纹理图被用于分割细胞腔周围的上皮层,统计纹理特征被用于训练最终的分类器。作者报告的准确率在70%到100%之间。
其他作者专注于对乳腺癌组织学图像进行更复杂的3类分类。例如,Brook等人[15]和Zhang等人[16]都将乳腺癌组织图像分为正常、原位癌和浸润癌。为此,使用了以色列理工学院的数据集[17]。Brook等人[15]使用多个阈值对每个图像进行二值化处理,并使用连接成分统计来训练支持向量机(SVM)分类器,报告了93.4%的平均准确率,通过拒绝20%的图像可以提高到96.4%。Zhang等人[16]使用了一种级联分类方法。Curvelet变换和局部二进制模式(LBP)特征的子集被随机地送入第一组平行的SVM分类器。在给定数量的分类器不一致的图像被拒绝,并由第二组人工神经网络(ANN)对其他随机特征子集进行分析。再一次,有一定数量的分类器不同意的图像被拒绝。这个系统以0.8%的拒绝率达到97%的准确率。
最近,可用计算能力和数据集规模的增加使得卷积神经网络(CNN)可以应用于图像分类问题。与传统的手工提取特征的方法相反,CNN通过优化分类损失函数直接从训练图像斑块中学习有用的特征。这些深度学习模型在不同领域的图像分类挑战中取得了出色的表现[18, 19],包括医学图像分析[20],特别是在组织病理学图像上[21]。
CNN允许减少设计一个分类系统所需的领域知识。正因为如此,方法的性能受所用数据集的影响较小,类似的网络结构可以在不同的问题上取得良好的效果。事实上,Spanhol等人[22]使用Imagenet网络[18]中的一个CNN架构,使用多种放大倍数将H&E乳腺组织活检样本分为良性和恶性肿瘤。在他们的工作中,从初始图像中提取了32×32和64×64像素的斑块并用于训练CNN。最终的分类是通过将斑块概率与总和、乘积或最大规则相结合得到的。研究了两种补丁提取方法,滑动窗口和随机提取。斑块的提取允许通过减少后续层的输入大小来降低模型的复杂性。
作者报告说,在更高的放大率下,准确率下降,这表明他们的CNN结构不能提取更高放大率的相关特征。事实上,对于更高的放大率,只有与核相关的特征被提取出来,这一点将在本文中讨论。
其他作者已经将CNN的结构调整到与乳腺组织学相关的问题上,并取得了成功。例如,Ciresan等人[19]使用101×101个斑块来训练一个CNN,用于H&E染色的乳腺活检切片中的有丝分裂检测。所使用的架构允许研究不同大小的细胞核和它们的邻域。该方法以0.782的F1分数赢得了ICPR 2012有丝分裂检测竞赛。Cruz-Roa等人[23]在100×100像素的整张幻灯片上训练了一个CNN,使用网格采样提取,以检测乳腺组织学幻灯片中的浸润性癌区。
由于问题的全局性,他们的CNN特征提取规模从细胞核到整体组织都有。该方法的表现优于其他最先进的方法,达到了0.780的F1分数。对于这后两项工作,模型通过图像滑动来获得概率图,然后通过阈值处理获得检测结果。在[19]中,通过对训练实例进行任意旋转和镜像,增加了训练数据集的大小和复杂性。
贡献:
在我们的工作中,提出了一种用于分析乳腺癌H&E染色组织学图像的CNN。与之前的方法不同,我们对四类医学相关性进行图像分类:i)正常组织,ii)良性病变,iii)原位癌和iv)浸润性癌。
为此,提出了一种新的乳腺癌图像数据集。此外,所提出的CNN体系结构设计用于整合多种组织学尺度的信息,包括细胞核、细胞核组织和整体结构组织。考虑到尺度信息,CNN也可用于全玻片组织学图像的斑块分类。采用数据增强的方法来增加训练集中的用例数。使用CNN提取的特征的SVM分类也用于比较目的。
材料和方法
数据
图像数据集由Bioimaging 2015乳腺组织学分类挑战赛[3]中的高分辨率(2040×1536像素)、未压缩和带注释的H&E染色图像组成。所有图像均在相同的采集条件下数字化,放大率为200倍,像素大小为0。42μm×0.42μm。每幅图像都标有四个类别中的一个:i)正常组织,ii)良性病变,iii)原位癌和iv)浸润性癌。标记由两名病理学家进行,他们仅根据图像内容提供诊断,没有指定分类的感兴趣区域。专家之间意见不合的案例被丢弃。挑战的目标是提供每个输入图像的自动分类。
该数据集由 249 张图像的扩展训练集和 20 张图像的单独测试集组成。 在这些数据集中,四个类别是平衡的。 选择图像以便可以从图像内容客观地确定病理分类。 额外的 16 幅图像测试集提供了模糊度增加的图像,我们将其称为“扩展”数据集。
The training and test datasets are publicly available at Bioimaging Challenge 2015 Breast Histology Dataset - Datasets - CKAN.
预处理:
在分析之前,使用 [24] 中提出的方法对图像进行归一化。该方法考虑了用于组织学载玻片制备的染色技术。首先,使用对数变换将图像的颜色转换为光密度 (OD)。然后,将奇异值分解 (SVD) 应用于 OD 元组以找到具有较高方差的 2D 投影。然后将生成的颜色空间变换应用于原始图像。最后,拉伸图像直方图,使动态范围覆盖数据的下 90%。图 2 显示了标准化前后的两张图像。
图像分类
在本文所描述的工作中,通过首先用分块分类器处理几个分块,然后组合所有图像分块的分类结果以获得最终的分块图像来执行图像分类。
将乳腺癌组织学图像分为四个目标类别之一,必须依赖于核相关特征以及与整体组织相关的特征的提取。细胞核特征有助于区分癌细胞和非癌细胞,并应包括单个细胞核信息,如颜色和形状,以及细胞核组织特征,如密度或可变性。不同的是,组织结构信息对于区分原位癌和浸润性癌是必要的。因此,分类应该基于从小于一个核大小到几个核宽的特征。
数据集图像的视觉分析表明,核半径范围为 3 到 11 个像素(1.26μm 到 4.62μm)。此外,在我们最初的观察中,我们假设大约 128 × 128 像素的斑块应该足以覆盖相关的组织结构。然而,在我们的数据集中,标签被分配给 2040 × 1536 像素的整个图像,这意味着不能保证小区域包含相关的诊断信息。这促使使用 512 × 512 像素的更大图像块,以确保可以为每个图像块提供更可靠的标签。如增强补丁数据集部分所述,从训练数据集生成补丁数据集。
对一张图像进行分类的过程如下。 首先,原始图像被分成十二个连续的不重叠的补丁。 补丁类概率是使用按补丁训练的 CNN 和 CNN+SVM 分类器计算的。 然后,使用三种不同的补丁概率融合方法之一获得图像分类:i)多数投票,其中图像标签被选为最常见的补丁标签,ii)最大概率,其中具有较高类别概率的补丁决定 图像标签和 iii) 概率总和,其中补丁类概率被求和并分配具有最大值的类。 通过使用以下顺序对恶性类进行优先级排序来解决平局:
图 2. 组织学图像归一化。 A和C原始图像; 标准化后的 B 和 D 图像。

i) 侵袭性,2原位,2良性和4正常。这一标准增加了对癌症分类的敏感性,损害了非癌症分类,这对第二意见系统更有意义。
增强补丁数据集
从训练集中的标准化图像创建一个增强的面片数据集。与其他CNN分类问题相比,使用的数据集样本数较少[18]。因此,网络可能容易过度适应。将图像分割为补丁可以增加数据集的复杂性和维度。通过修补程序旋转和镜像的数据增强进一步改进了数据集。这是可能的,因为所研究的问题是旋转不变性,即医生可以在不改变诊断的情况下从不同方向研究乳腺癌组织学图像。因此,旋转和镜像允许增加数据集的大小,而不会降低其质量。修补和数据集增强已经成功地用于类似的组织学分类问题 [19] 。然而,它们尚未用于癌症分类。
首先,将图像分成512×512像素大小的小块,重叠50%。图1显示了一些示例补丁。通过分别减去红色、绿色和蓝色通道的平均值来执行面片规格化。然后,通过组合kπ/2旋转、k={0,1,2,3}和垂直反射,将每个面片转换为八个不同的面片。这导致与原始250训练图像共有of70000个不同的补丁。每个修补程序都被认为具有与原始映像相同的类标签。
用于斑块分类的CNN
CNN用于将512×512组织学图像分为四个组织类别。CNN是一种前馈神经网络,专门用于视觉模式识别。神经元连接到重叠的局部图像块(感受野),并以卷积图的形式排列,所有神经元共享相同的权重。这允许卷积映射用作局部图像过滤器,在所有图像位置检测相同的模式,并减少待训练的参数的总数 [25] 。该网络被组织成分层结构,在每一级上,将较低级别的特征组合成较高级别的特征,直到获得图像类标签。
所提出的网络结构遵循了以前成功应用CNN进行图像分类的共同趋势[18, 19, 26],有几个卷积-集合层对,然后是一个全连接网络。在我们的实验中,提供最佳结果的架构总结在表1中,并在图3中说明,它是由以下设计考虑的结果。
输入层。输入层有三个512×512像素的通道,对应于从图像中提取的归一化的RGB斑块。
地图的深度和数量。如前所述,乳腺癌组织分类需要在几个特征尺度上进行分析。在目标图像中,细胞核的半径在3到11像素之间,因此需要探索细胞核尺度的特征、细胞核组织的特征和结构尺度的特征。
因此,拟议的网络结构具有足够的神经图谱的卷积层,以代表这三个特征中的每个特征的尺度范围,如表1所示。最后的全连接网络对整个图像补丁的信息进行整合,并提供最终的分类。大的输入尺寸和多尺度的网络设计使得该方法可以扩展到整个幻灯片图像。
表1. 拟议的卷积神经网络结构。左侧注释显示与网络层的组织学关联。A-边缘;B-细胞核;C-细胞核组织;D-结构和组织组织。

最大限度地汇集。低级别的信息需要在空间上对图像区域进行整合,以及在核算高级别的信息时进行简化。最大集合层允许在不增加网络中的参数数量的情况下实现这种复杂性的降低。最大池化层使用的跨度等于池化大小。
非饱和非线性: 卷积层和全连接层均由整流线性单元组成,激活函数f(x) = max(0,x) 。选择这种非线性是为了帮助避免梯度消失并提高训练速度 。
输出层: 输出由我们的神经元组成,对应于四个类中的每一个,并使用softmax激活函数进行归一化。
该模型使用75%的训练集进行训练,并在剩余图像上进行验证。验证集是为每个纪元随机选择的。训练过程在所有等级(50个阶段)的验证精度稳定后停止。网络权重随机初始化,自适应学习速率梯度下降,反向传播算法用于权重更新 [28] 。所选损失函数为分类交叉熵。

图3。卷积神经网络结构,如表1所示。原始图像有512×512像素和3个RGB通道。橙色和紫色方块分别代表卷积核和最大池核。
表 2. 用于性能评估的图像(和补丁)数量。总共考虑了 36 个图像和 512 个补丁。

为了比较,CNN提取的特征用于训练支持向量机分类器(CNN+SVM)。 第二个全连接层的激活被用作特征。 使用径向基函数内核,并通过对训练数据使用 3 倍交叉验证的穷举搜索获得最佳参数。 分类器使用整个训练集进行训练。
结果评价
用灵敏度和精确度来评价方法的性能。此评估针对初始集和扩展集以补丁方式和图像方式执行。在非癌和癌的二元分类中,也考虑将正常与良性结局和原位与侵袭性结果分别分组。表2详细说明了使用的图像和修补程序的数量。
结果
分片分类
在表3和表4中分别示出了贴片精度和灵敏度。对于CNN和CNN + SVM分类器,总体精度 (初始加扩展数据集) 是66.7% 的,65.0% 的是CNN + SVM分类器。由于扩展数据集的复杂性增加,我们系统的性能较低。当仅考虑两个类别(非癌和癌)(CNN为77.6%,CNN+SVM为76.9%)时,总体准确度增加。这表明,正常/良性和原位/侵入性分类在它们之间具有相似的特征。此外,所提出的系统对癌斑分类的总体敏感性约为81%。
表 3. Patch-wise 准确率 (%)(2 和 4 类)

表 4. 补丁敏感度 (%)(2 和 4 类)

图像分类
按图像分类的结果分别显示在表5和表6中。多数人投票显示了最好的结果,四个类别的总体准确率达到了77.8%。
表5. 使用不同投票规则(2类和4类)的图像准确率(%)

表6. 使用多数投票(2类和4类)的图像灵敏度(%)


图4. 卷积神经网络第一层(A,B)和第二层(C)的激活实例。对具有诊断意义的不同结构进行了分析。
无论使用CNN还是CNN+SVM进行补丁式分类,都是不变的。在这两种方法中,最大概率是表现最差的方法,表明它不是一个适合这个问题的策略。关于二进制分类,与四类问题相比,两个分类器的总体准确率都有所提高。此外,CNN+SVM似乎优于CNN模型,最佳投票方法的总准确率达到了83.3%。相比之下,CNN的表现只在使用多数投票的扩展集上更好。补丁式分类的准确率较低的原因是,补丁标签是从图像标签中获得的,没有任何关于异常位置的信息。这种方法是次优的,因为无论图像类别如何,正常组织区域也可能存在。因此,在训练集中引入了噪声,导致了较低的斑块精确度。尽管如此,该网络仍然关注图像的相关细节。例如,图4显示了CNN第一层和第二层的激活情况,其中相关的诊断结构,如低核和高核密度区域的核或基质组织,正在被优先考虑。
特征可视化
图5显示了初始训练集的二维表示以及最后一个卷积层和第二个全连接层的激活。这些表示来自于t-SNE的应用,它是一种高效的参数化嵌入技术,用于降维,保留了样本之间的距离[29]。在这些表示中,每个点都对应于一个补丁,点与点之间的二维距离是多维空间中原始欧几里得距离的近似值。在图5-C中,测试集斑块也被表示出来。如图5-A和5-B所示,CNN倾向于在较高的层中对同一类别的样本进行近似。这表明这些层在训练后从初始数据中提取了相关的特征。在图5-C中,斑块出现在由一个类别主导的集群中,表明在两个全连接层之后,不同标签的斑块之间有很好的区分。不同的是,不同类别的点的存在可能代表了错误分类的斑块。尽管如此,整体的斑块组织表明,全连接层的激活是使用建议的SVM模型进行分类的有用特征。
与最先进的技术比较
Cruz-Roa等人[23]使用CNNs对整个玻片的高分辨率图像斑块进行分类,认为是浸润性癌。实现的灵敏度为79.6%。

图5. 使用t-SNE[29]对训练斑块及其在CNN的不同层上的激活进行二维投影。A 训练斑块;B 最后一个卷积层;C 第二个全连接层。菱形代表测试图像。
总的来说,我们的方法对浸润性癌的补丁式分类的灵敏度为74.1%。由于几个原因,这些结果不能直接比较。1.我们的方法是对4个类别的斑块进行区分,而不是[23]中考虑的分割问题,后者只关注浸润性癌和非浸润性癌的区域分类;2.在以前的工作中,斑块状的整个幻灯片图像的基础真相是可用的。在我们的案例中,只有与整个幻灯片图像中较小的部分相对应的图像地基真相是可用的。因此,在我们的数据集中,训练集和测试集中的一些斑块可能不包含被正确分类的相关信息,从而降低了斑块分类的准确性。
尽管如此,我们的方法性能显示与[23]接近,特别是当考虑到我们的方法不是一个专门的浸润性癌症检测方法。对于[23]中的CNN结构和图像分辨率,他们的算法分析了尺寸在4μm到100μm之间的空间相关特征。乳腺细胞核的直径约为6μm,这表明没有考虑质地等亚核特征。这表明作者报告的良好的分类结果是基于组织结构特征。相比之下,我们的架构能够捕捉大小在1.3μm和94μm之间的特征。这使得CNN不仅能够学习单个细胞核的特征,还能学习结构的组织。
在Spanhol等人的工作中[22],CNN被用来对良性或恶性肿瘤的不同放大倍数的乳腺癌组织学图像进行分类。对于200倍的放大率,达到的准确率约为84%。在我们的工作中,使用CNN时,非癌/癌组织分类的整体图像准确率约为81%,使用SVM分类器时为83%。尽管我们的训练是在考虑4个类别的情况下进行的,但这些方法呈现出类似的性能。此外,[22]中使用的数据集包含了大约2000张参考放大率的图像,这是一个很大的训练集。由于所提出的数据增强方法,我们能够用较少的训练实例来训练一个更复杂的模型。此外,在[22]中,图像的选择方式是只出现诊断的相关区域,而在我们的案例中,分类的非相关区域同时出现在补丁式训练和测试集中,这会误导网络训练。
考虑到Spanhol等人[22]的CNN架构和图像分辨率,在200倍的放大率下,可以学习到尺寸在0.2μm和7μm之间的空间相关特征。然而,如果细胞核的直径约为6μm,那么报告的网络结构就不能通过其卷积层学习更高尺度的特征。此外,作者对不同的放大倍数使用相同的CNN架构,这意味着对较低的放大倍数学习了较大的特征。如前所述,细胞核组织也与诊断过程有关。他们在较低的放大率下取得了更好的结果,这表明照顾到相关尺度的分析对于CNN架构的分类成功是很重要的。相比之下,我们更复杂的架构适用于在多个相关尺度上学习特征。
结论
提出了一种基于CNN的H&E染色组织学乳腺癌图像的分类方法。所有相关的特征都由网络学习,减少了对现场知识的需求。图像被分类为正常组织、良性病变、原位癌和浸润性癌。另外,也可以进行二元分类,即癌或非癌。为此,网络的架构被设计为从不同的相关尺度中提取信息,包括细胞核和整体组织。该网络是在一个增强的补丁数据集上训练的,并在另一组图像上进行测试。数据集的增强和基于尺度的网络设计对该方法的成功都很重要。提取的特征也被用于训练SVM分类器。CNN和SVM分类器都取得了相当的结果。所提出的分类方案允许获得高灵敏度的癌症病例,这对病理学家来说是有意义的。我们系统的性能与最先进的方法相似或更胜一筹,尽管使用的是更小和更具挑战性的数据集。最后,由于网络的设计考虑到了多种生物尺度,所提出的系统可以扩展到与临床相关的整个乳房组织学图像分类。