Rotated_Faster_Rcnn
rotated faster rcnn
文章目录
- 训练
-
- rpn_head.forward_train
-
- rpn_head.forward
- rpn_head.loss
- rpn_head.get_bboxes
- roi_head.forward_train()
-
- bbox_forward_train
-
- _bbox_forward(x, rois)
- bbox_head.get_targetes
- bbox_head.loss
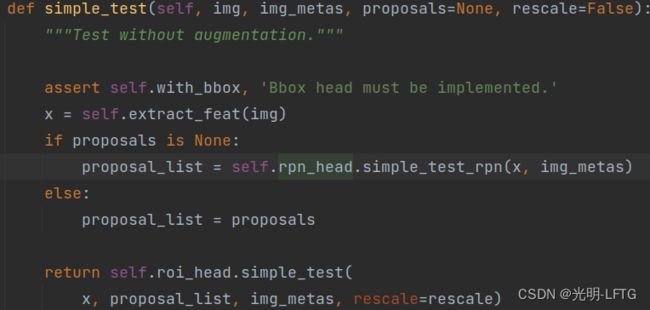
- 测试
下面的图片没有画完,只花了roi_head.forward部分,但是代码分析是全的
总结一下从rpn开始一直沿用的是hbb,一直到bbox_head才预测了shape为n,5的结果
然后通过loss来学习。
但是p2rb需要用的是旋转的roi_extractor提取方式
所以准备再看一遍oriented_rcnn
训练

rpn_head.forward_train

但在这之前必须经历outs=self(x),也就是rpn_head.forward部分
可以看到loss和props是分别self.loss self.get_bboxes获得的。
rpn_head.forward
forward–>forward_single所以下面直接分析forward_single
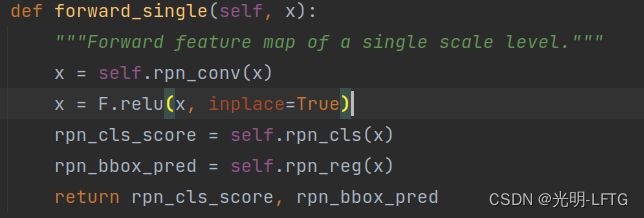
可以看到forward_single非常简单,直接卷积层获得两个–>得分和bbox
feat_channels默认256,如下是rpn_reg和rpn_cls的定义,下面被我的id挡住的是
(self.feat_channels, self.num_anchors4 , 1)
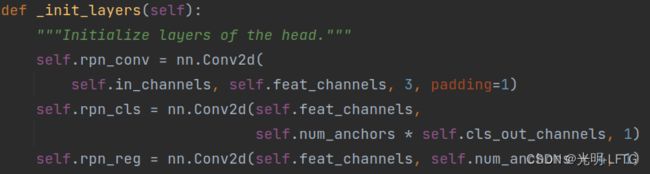
这里看到其实是4就是知道rpn生成的仍然是hbb而不是obb。
rpn_head.loss
下面三个函数共同组成了rpn_head.loss
self.get_anchors
self.get_targets
self.loss_single
也很好理解,毕竟是anchor-based,会根据cfg生成anchor
又会把每一个anchor做一个和gt的匹配
然后再利用bbox_preds, cls_scores计算损失,前面两个部分实际上不会传入bbox_preds, cls_scores
因为没有旋转框,所以和mmdetection的应该无异
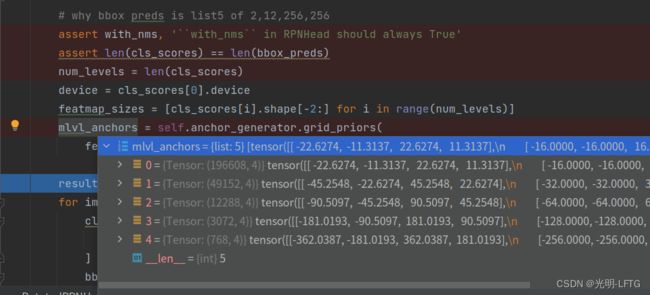
rpn_head.get_bboxes
包含两个部分:
self.anchor_genertor.grid_priors(featmap_sizes,device)
get_bboxes_single
从下图可以看到,生成了许许多多的anchors
下面展示以下get_bboxes_single的cfg部分

这里0-3层会保留得分前2000所对应的框
而4层(也就是第五层)会保留所有框
对于这一共8768个框,会使用torch.cat把list5得到tensor 8768,4
下面的代码有三个部分:
torch.cat把所有层的prop整合在一起
decode把所有框的xyxy表达出来
nms对8768个框做一个筛选(保留了3000多个框,可见框与框之间重复的挺严重的,keep是保留的框的id,但是下面的roi其实用不到,所以不用往下传了)
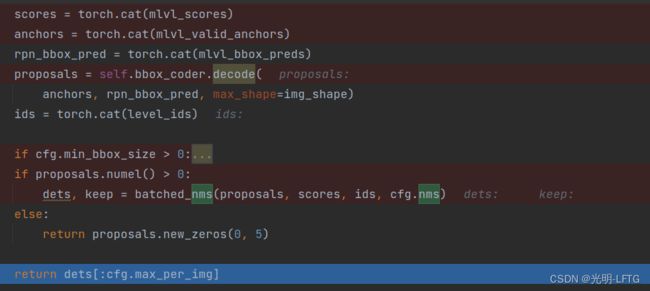
所以—nms到底在哪一步使用了,终于搞懂了!
然后由于cfg里面有一个键值叫max_per_img=2000所以最终nms之后保留前2000个框。至此结束get_bboxes
其实并没有结束,注意它会把每个batch里面的每一个图片单独作一次,最后返回的是一个result_list

roi_head.forward_train()
调用assigner和sampler
之后bbox_forward_train(),这个函数是roi_head.forward_train()的主体
bbox_forward_train
这张图片是函数的输入,下面的图片是函数主体
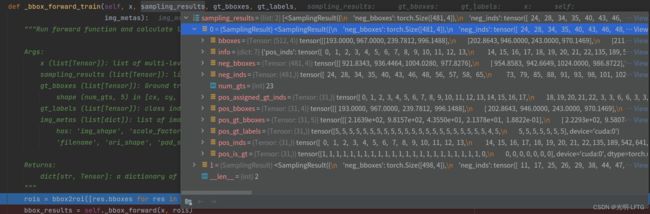
函数主体,可以看到包含
bbox2roi这个部分只是给box加一个id
得到1024, 5 这里5的第一个是img_id
_bbox_forward显然这一部分的内容是比较多的
get_targers
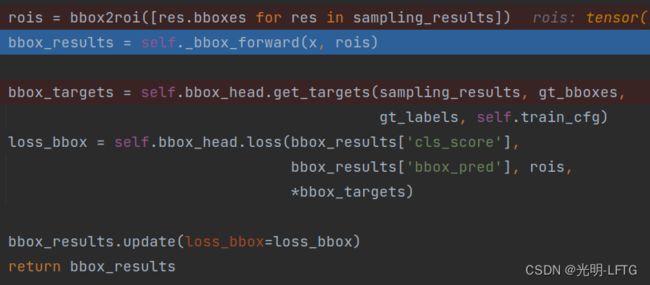
_bbox_forward(x, rois)
这里roi_extractor只是利用rois获得,虽然x有5层,这里只利用了前四层
得到1024 256 7 7,这就是roi的具体输出
所以256 7 7 就可以送入全连接层,是的
with_shared_head=False
self.bbox_head(bbox_feats)显然是最重要的部分
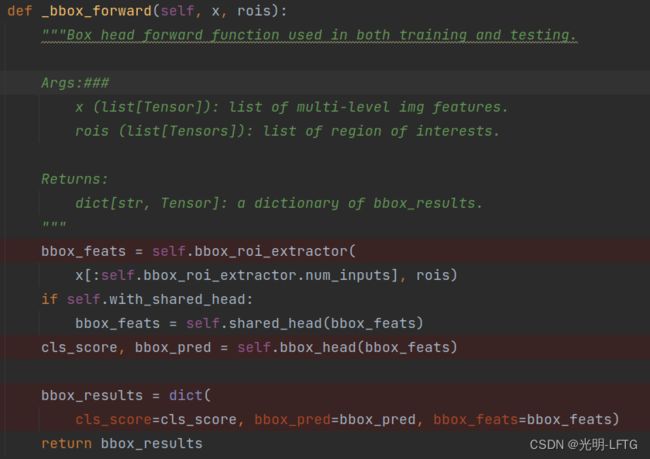
下面这张图片展示了bbox_head的主体

所以bbox_head就是使用了flatten之后,两个共享全连接层,然后分别使用两个并列的全连接层获取cls_scores和bbox_pred
所以即使bbox_pred输出五个维度,‘并且第五个维度应该是角度,这里可以看到它实际上并没有作任何限制。
下图展示了bbox_forward最终返回的字典内容。

bbox_head.get_targetes

可以看到主要是调用了get_target_single()
调用single之前,先从sample result中读取了正负例和gt
下面输出的labels中,如果15是背景的意思,而0-14是前景,这里会把正例放前面,负例放在后面,负例只有分类损失。
这里的bbox_targets虽然是512,5但是里面所有的负例对应的行都为0,并且weights也为0,不会参与运算。

其实一个不那么显然的部分就是bbox_targets,它对于正例的具体数值到底是多少呢?
其实是deltaXYWHA的编码方式得到的。(起码需要知道,输入第一个是xyxy,而gt是cxcywha,即下面的pos_bboxes,pos_gt_bboxes)

说明白了get_targets返回的是什么,就可以进入最后的loss阶段,可以发现get_targets就是为了计算loss服务的,并且encode之后不需要decode因为不需要输出。
bbox_head.loss
![]()
从配置可见端倪。

这里的pos_bbox_pred实际上是前_bbox_forward(x, rois)的输出的一部分
这里实际上没有在具体的预测角度,而是encoder之后的结果,并且用此来训练
然后bbox_targets实际上是前面bbox_head.get_targets的结果。

测试