基于python文本挖掘的电商产品评论数据情感分析报告
背景
近年来,随着互联网的广泛应用和电子商务的迅速发展,网络文本及用户评论分析意义日益凸显,因此网络文本挖掘及网络文本情感分析技术应运而生,通过对文本或者用户评论的情感分析,企业能够进行更有效的管理等。对于客户来说,可以借鉴别人的购买历史以及评论信息,更好的辅助自己制定购买决策。
流程分析

框架
工具准备
一、导入数据
二、数据预处理
(一)去重
(二)数据清洗
(三)分词、词性标注、去除停用词、词云图
三、模型构建
(一)决策树
(二)情感分析
(三)基于LDA模型的主题分析
工具准备
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.pylab import style #自定义图表风格
style.use('ggplot')
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
plt.rcParams['font.sans-serif'] = ['Simhei'] # 解决中文乱码问题
import re
import jieba
import jieba.posseg as psg
import itertools
#conda install -c anaconda gensim
from gensim import corpora,models #主题挖掘,提取关键信息
# pip install wordcloud
from wordcloud import WordCloud,ImageColorGenerator
from collections import Counter
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
import graphviz
import warnings
warnings.filterwarnings("ignore")
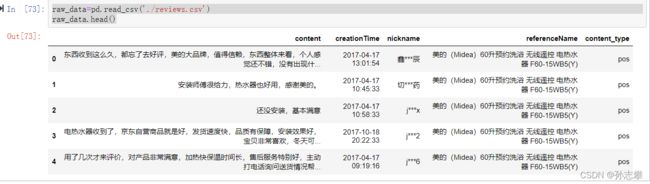
一、导入数据
raw_data=pd.read_csv('./reviews.csv')
raw_data.head()
二、数据预处理
(一)去重
删除系统自动为客户做出的评论。
reviews=raw_data.copy()
reviews=reviews[['content', 'content_type']]
print('去重之前:',reviews.shape[0])
reviews=reviews.drop_duplicates()
print('去重之后:',reviews.shape[0])

(二)数据清洗
查看清洗前数据:
# 清洗之前
content=reviews['content']
for i in range(5,10):
print(content[i])
print('-----------')

清洗之后,将数字、字母、京东美的电热水器字样都删除:
#清洗之后,将数字、字母、京东美的电热水器字样都删除
info=re.compile('[0-9a-zA-Z]|京东|美的|电热水器|热水器|')
content=content.apply(lambda x: info.sub('',x)) #替换所有匹配项
for i in range(5,10):
print(content[i])
print('-----------')

(三)分词、词性标注、去除停用词、词云图
目标
输入:
- content、content_type
- 共有1974条评论句子
输出: - 构造DF,包含: 分词、对应词性、分词所在原句子的id、分词所在原句子的content_type
- 共有6万多行
非结构化数据——>结构化数据
#分词,由元组组成的list
seg_content=content.apply( lambda s: [(x.word,x.flag) for x in psg.cut(s)] )
seg_content.shape
len(seg_content)
print(seg_content[5])
jieba.setLogLevel(jieba.logging.INFO)

#得到各分词在第几条评论
n_content=[ [x+1]*y for x,y in zip(list(seg_content.index),list(n_word))] #[x+1]*y,表示复制y份,由list组成的list
index_content_long=sum(n_content,[]) #表示去掉[],拉平,返回list
len(index_content_long)
#分词及词性,去掉[],拉平
seg_content.head()
seg_content_long=sum(seg_content,[])
seg_content_long
type(seg_content_long)
len(seg_content_long)
#得到加长版的分词、词性
word_long=[x[0] for x in seg_content_long]
nature_long=[x[1] for x in seg_content_long]
len(word_long)
len(nature_long)
#content_type拉长
n_content_type=[ [x]*y for x,y in zip(list(reviews['content_type']),list(n_word))] #[x+1]*y,表示复制y份
content_type_long=sum(n_content_type,[]) #表示去掉[],拉平
len(content_type_long)
review_long=pd.DataFrame({'index_content':index_content_long,
'word':word_long,
'nature':nature_long,
'content_type':content_type_long})
review_long.shape
review_long.head()

(2)去除标点符号、去除停用词

#去除标点符号
review_long_clean=review_long[review_long['nature']!='x'] #x表示标点符合
review_long_clean.shape
#导入停用词
stop_path=open('./stoplist.txt','r',encoding='UTF-8')
stop_words=stop_path.readlines()
len(stop_words)
stop_words[0:5]
#停用词,预处理
stop_words=[word.strip('\n') for word in stop_words]
stop_words[0:5]
#得到不含停用词的分词表
word_long_clean=list(set(word_long)-set(stop_words))
len(word_long_clean)
review_long_clean=review_long_clean[review_long_clean['word'].isin(word_long_clean)]
review_long_clean.shape
(3)在原df中,再增加一列,该分词在本条评论的位置
#再次统计每条评论的分词数量
n_word=review_long_clean.groupby('index_content').count()['word']
n_word
index_word=[ list(np.arange(1,x+1)) for x in list(n_word)]
index_word_long=sum(index_word,[]) #表示去掉[],拉平
len(index_word_long)

review_long_clean['index_word']=index_word_long
review_long_clean.head()

(5)词云图
n_review_long_clean.nature.value_counts()
n_review_long_clean.to_csv('./1_n_review_long_clean.csv')
font=r"C:\Windows\Fonts\msyh.ttc"
background_image=plt.imread('./pl.jpg')
wordcloud = WordCloud(font_path=font, max_words = 100, background_color='white',mask=background_image) #width=1600,height=1200, mode='RGBA'
wordcloud.generate_from_frequencies(Counter(review_long_clean.word.values))
wordcloud.to_file('1_分词后的词云图.png')
plt.figure(figsize=(20,10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
 其中“服务”、“师傅”、“东西”、“收费”、“客服”、“售后”、“物流”、“速度”、“免费”、“上门”、“人员”、“信赖”、“品牌”、“安装费”出现次数较多
其中“服务”、“师傅”、“东西”、“收费”、“客服”、“售后”、“物流”、“速度”、“免费”、“上门”、“人员”、“信赖”、“品牌”、“安装费”出现次数较多
说明人们比较关注这些方面,比如从词云可以看出“售后服务”、“物流速度”等等比较受关注
三、模型构建
(一)基于决策树的情感分类
#第一步:构造特征空间和标签
Y=[]
for ind in review_long_clean.index_content.unique():
y=[ word for word in review_long_clean.content_type[review_long_clean.index_content==ind].unique() ]
Y.append(y)
len(Y)
X=[]
for ind in review_long_clean.index_content.unique():
term=[ word for word in review_long_clean.word[review_long_clean.index_content==ind].values ]
X.append(' '.join(term))
len(X)
X
Y

决策树的构建:
#第二步:训练集、测试集划分
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=7)
#第三步:词转向量,01矩阵
count_vec=CountVectorizer(binary=True)
x_train=count_vec.fit_transform(x_train)
x_test=count_vec.transform(x_test)
#第四步:构建决策树
dtc=tree.DecisionTreeClassifier(max_depth=5)
dtc.fit(x_train,y_train)
print('在训练集上的准确率:%.2f'% accuracy_score(y_train,dtc.predict(x_train)))
y_true=y_test
y_pred=dtc.predict(x_test)
print(classification_report(y_true,y_pred))
print('在测试集上的准确率:%.2f'% accuracy_score(y_true,y_pred))

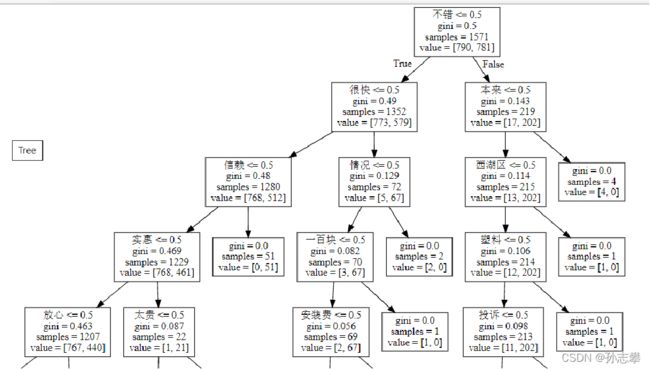
第五步:画决策树:
cwd=os.getcwd()
dot_data=tree.export_graphviz(dtc
,out_file=None
,feature_names=count_vec.get_feature_names())
graph=graphviz.Source(dot_data)
graph.format='svg'
graph.render(cwd+'/tree',view=True)
graph