Concurrent Programming —— JUC(java.util.concurrent)
Concurrent Programming
Concurrent Programming —— Introduction
Concurrent Programming —— Pessimistic Lock and Monitor
Concurrent Programming —— JMM(Java Memory Model)
Concurrent Programming ——Thread Pool
Concurrent Programming —— JUC(java.util.concurrent)
Concurrent Programming —— JUC(Java.Util.Concurrent)
- Concurrent Programming
- 前言
- 1. AQS
- 2. ReentrantLcok原理
-
- 2.1 非公平锁加锁原理
- 2.2 释放锁
- 2.3 可重入原理和可打断原理
- 2.4 await()和 signal()原理
- 3. ReentrantReadWriteLock
-
- 3.1 读写锁原理
- 4. ConcurrentHashMap
- Concurrent Programming
前言
本文将介绍java.until.concurrent工具包中AQS、ReentrantLcok的原理、ReentrantReadWriteLock和ConcurrentHashMap

1. AQS
AQS(ABstractQueuedSynchronizer),是阻塞式锁和相关的同步器工具的框架
特点:
- 用
state属性来表示资源的状态(独占和共享),子类需要定义如何维护这个状态,控制如何获取锁和释放锁
getState- 获取状态
setSate- 设置状态
compareAndSetState- 乐观锁设置状态
独占:只有一个线程能访问 共享:多线程访问 - 提供了基于FIFO (先入先出)的等待队列,类似于
Monitor的EntryList - 通过条件变量来实现等待、唤醒机制,支持多个条件变量,类似于Monitor的WaitSet
子类要实现以下方法来达到阻塞式锁的效果:
tryAcquire - 尝试获取锁
tryRelease - 尝试释放锁
tryAquireShared- 尝试获取共享锁
tryReleaseShared - 尝试释放共享锁
isHeldExclusively - 是否是独占锁
2. ReentrantLcok原理
2.1 非公平锁加锁原理
非公平锁中使用的NonfairSync是继承与AQS,当线程之间没有竞争时,线程会直接获得锁,并将NofairSync中的state从0设置为1,exclusiveOwnerThread指向获得锁的线程

当有的别的线程来准备获取锁的时候,发现CAS尝试把0 -> 1失败后,会调用tryAcquire(再次尝试获取锁),如果state已经是1,表明失败,失败的线程会进入Node队列中,Node队列中的元素waitStatus默认为0,Node队列的创建是懒惰,只有碰到获取锁失败的线程,才会去创建这个队列,Node队列的一个元素是哨兵元素,用来占位和负责唤醒后一位线程的作用,不与线程相关联,如下图所示

在队列中的线程会一个死循环中继续尝试获取锁,失败后进入park阻塞,具体过程如下:
会先获取前驱节点,如果前驱节点是head节点,就再次调用tryAcquire方法,如果state还是1,就会失败并准备进入park阻塞,会调用shouldParkAfterFailedAcquire,如果是第一次调用,会将前驱节点的waitStatus设置为-1,并返回false,并再循环一次,尝试获取锁,失败后再次调用shouldParkAfterFailedAcquire,这时发现waitStatus已经是-1,就返回true,并park当前线程,使其进入阻塞状态
2.2 释放锁
当锁被释放后,NonfairSync的state就会变成0,exclusiveOwnerThread也会被设置为null,并开始检查waitSet是否为null,如果waitSet不为null且头节点的waitStatus为-1,就表明需要去唤醒其它线程来重新竞争这个锁,这时候头节点就会去唤醒离它最近的一个后续节点,让它去竞争锁,竞争成功后会去更新头节点,把原来的节点断块,把自己刚才所在的位置设置为新的头节点

因为是非公平锁,因此别的不在waitSet的线程也可以去和被唤醒的线程进行竞争锁,如果竞争失败,线程会回到waitSet中的原先的位置,等待新一次的唤醒
2.3 可重入原理和可打断原理
当已经获取锁的线程,再次获取锁的时候,会先判断exclusiveOwnerThread是否是当前线程,如果是则state会+1,
释放锁的时候,需要多次释放,每一次释放都会将state-1,直到state = 0的时候才会将锁完全释放掉
可打断原理:
不可打断模式(默认),即使被打断,仍然会留在AQS队列中,等获得锁后,继续运行(打断标记设置为true)才能知道自己被打断了并进行打断,无法在阻塞状态被打断
可打断模式:acquireInterruptibly()方法 直接抛出异常,离开AQS,停止等待锁
2.4 await()和 signal()原理
await()流程
每个条件变量都有一个ConditionObject来维护不满足条件的线程
当调用了await()方法后,会将线程加入ConditionObject的双向链表中,并将status设置为-2,表示等待状态,并将持有锁的线程释放锁,并去唤醒waitSet中的等待线程
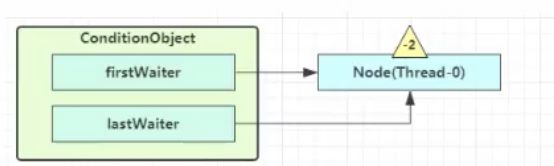
signal()流程:
调用signal()方法时,会检查调用的线程是否持有锁,如果不是会抛出异常,并判断ConditionObject的waitSet是否为空,如果不为空,则去唤醒第一个线程,并更新头节点,被唤醒的线程会进入NonfairSync的等待列表,加入到队列尾部,并将前驱节点的waitStatus设置为-1,然后持锁线程会释放锁,让waitSet中的线程进行竞争
3. ReentrantReadWriteLock
当读操作远远高于写操作时,使用读写锁,让读-读可以并发,提高性能
//要先获得ReentrantReadWriteLock对象,在分别获得读锁和写锁进行不同的操作
ReentrantReadWriteLock rw = new ReentrantReadWriteLock();
ReentrantReadWriteLock.ReadLock t = rw.readLock();
ReentrantReadWriteLock.Write w = rw.writeLock();
//在读操作时上读锁
public Object read(){
r.lock();
try{
}finally{
r.unlock();
}
}
//写操作时上写锁
public void write(){
w.lock();
try{
}finally{
w.unlock();
}
}
在写锁上锁后,读锁就无法获取到,不能进行读操作
读锁不支持条件变量
重入时升级不支持:有读锁的情况下去获取写锁,会导致获取写锁永远等待
重入时可以降低锁等级,先获取写锁,再获取读锁
3.1 读写锁原理
用的是同一个Sync同步器,因此等待队列、state也是同一个
state的高16位表示的是读锁,而低16位表示的是写锁

写锁加锁流程与ReentrantLock没有区别,当读锁想要获取锁的时,会调用tryAcquireShared方法,如果写锁占有方法返回-1,表示获取失败,返回0表示获取锁成功,但不会唤醒后继节点,返回正整数,表示获取锁成功,数值表示还有几个后继节点需要被唤醒,失败也会进入waitSet进行等待,进入waitSet的等待过程也与ReentrantLock的流程相似,但是读锁的Node类型是shared表示是共享的而不是ReentrantLock中exclusive,独占的,当加入写锁的时候,Node类型也是exclusive的
当写锁释放的时候,会去唤醒waitSet中的锁,如果成功唤醒且Node的类型是shared,就会去检查下一个Node的类型是不是shared,如果是也尝试将其唤醒,如果不是shared类型就不会进行唤醒,当读锁释放时,需要将所有的读锁都释放才能去唤醒写锁,当state的值为0时,才会去唤醒写锁
4. ConcurrentHashMap
Java在JUC工具包中提供了线程安全的集合类,这些类主要通过三种方法来是实现线程安全:
- Blocking:基于锁,通过阻塞的方式
- CopyOnWrite:修改开销大
- Concurrent类型的容器:
通过cas优化,吞吐量高
弱一致性:遍历时,即使容器发生修改,迭代器可以继续遍历,内容是旧的,求大小弱一致性,size操作未必是100%准确,读取弱一致性
非线程安全容器遍历时发生修改,会使用fail-fast机制让遍历失败,抛出ConcurrentModificationException,不再遍历
HashMap线程不安全问题:
HashMap Java 8中hash冲突的元素放在链表的尾部,7中是放在头部的
HashMap扩容时会出现并发死链问题(JDK 7 中出现),JDK 8中修改了插入方法,让扩容时死链不再形成,但是容易导致扩容时数据丢失问题
死链问题:
当HashMap进行扩容是,会重新计算元素的hash值,并把它放到新的位置上,当两个线程通过进行扩容时,当一个线程已经完成扩容后,但另一个还没有完成时,因为线程不安全,未完成的线程会获取到完成迁移的元素,因为是头插入,因此当前准备迁移的元素会变成,迁移后链表的最后一个,而未迁移前,该元素在链表的最前面,因此再次发生迁移时,再次插入链表的头,就会导致链表变成环形链表,无法完成迁移工作,导致进入死循环
ConcurrentHashMap:
类中的属性是用volatile所修饰的,是懒惰初始的,创建时仅仅计算来table的大小,在第一次使用是才真正创建
与普通HashMap方法一样,但是是线程安全的
虽然每个操作时原子性的,但是组合起来不一定线程安全
map. computeIfAbsent()往map里放key 线程安全 保证get put方法组合的原子性
ConcurrentHashMap的初始化大小都是2^n的大小
get流程:
get方法没有加任何的锁,先用spread方法确保返回结果是正确的hash值,并找到桶下表,并判断链表是否为空,不为空则遍历链表并用equals方法找到对的元素,如果头节点的链表hash值是负数,表示链表在扩容中或者treebin中就会调用find方法来查找元素
public V get(Object key) {
ConcurrentHashMap.Node<K,V>[] tab; ConcurrentHashMap.Node<K,V> e, p; int n, eh; K ek;
//获取正确的hash值
int h = spread(key.hashCode());
//判断table是否为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//判断头节点的hash值是否和元素的hash一样
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//hash值小于0说明链表在扩容,或者元素在红黑数中,调用find方法去查询
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
//如果头节点不是要找的元素,遍历链表找到相同的元素
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
//没找到返回null
return null;
}
put流程:
调用put方法时候,会传入一个boolean来判断是否是第一次put,先获取hash值,并遍历hash表,如果hash表为空,则初始化table,初始化是使用了CAS,如果不为空,则创建链表头节点,添加链表头时使用了CAS,当需要扩容时,可以帮助扩容,当发生桶下标冲突时,会锁住链表的头节点,再次确认链表头节点是否被移动过,并判断节点是普通节点还是红黑数节点,如果是正常节点,则遍历链表,找到相同key并更新,当遍历到最后一个节点还是没有相同的key,则新增一个Node追加在链表尾部,如果是红黑树则查处key是否在树中,如果是则返回相应的TreeNode,并更新值,如果不是则创建新的TreeNode,完成后释放锁,添加Node后会进行判断链表长度是否超过阀值,如果超过则进行一次扩容,扩容后长度还是超过8,链表就会变成红黑树
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//计算hash值
int hash = spread(key.hashCode());
int binCount = 0;
for (ConcurrentHashMap.Node<K,V>[] tab = table;;) {
ConcurrentHashMap.Node<K,V> f; int n, i, fh; K fk; V fv;
//如果table为空初始化table
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//头节点为空,可以放入元素使用CAS把元素放在链表头
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new ConcurrentHashMap.Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
//如果头节点hash为-1,表示正在扩容,帮助扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
//发生了桶下标的冲突
else {
V oldVal = null;
//锁住链表头节点
synchronized (f) {
//确保头节点没有被移动
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
//遍历链表
for (ConcurrentHashMap.Node<K,V> e = f;; ++binCount) {
K ek;
//找到相同的key
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
//更新value
if (!onlyIfAbsent)
e.val = value;
break;
}
ConcurrentHashMap.Node<K,V> pred = e;
//到最后一个节点,新增Node,添加链表到尾部
if ((e = e.next) == null) {
pred.next = new ConcurrentHashMap.Node<K,V>(hash, key, value);
break;
}
}
}
//链表变成了红黑树
else if (f instanceof ConcurrentHashMap.TreeBin) {
ConcurrentHashMap.Node<K,V> p;
binCount = 2;
if ((p = ((ConcurrentHashMap.TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ConcurrentHashMap.ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
//判断添加元素后是否需要将链表变成红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//size+1
addCount(1L, binCount);
return null;
}
扩容transfer流程:
先创建nextTable(新table),大小为原来table的两倍,再把旧table中的值复制到新table中,然后再以一个链表为单位进行搬迁,当链表的头为null时,表明已经搬迁完了,就会把头节点变成ForwardingNode,当发现链表头已经是ForwardingNode了就会去处理下一个链表,当链表中有元素没有被处理,就会把链表头锁住(synchronized)然后进行处理
Concurrent Programming
Concurrent Programming —— Introduction
Concurrent Programming —— Pessimistic Lock and Monitor
Concurrent Programming —— JMM(Java Memory Model)
Concurrent Programming ——Thread Pool
Concurrent Programming —— JUC(java.util.concurrent)