Druid连接池-数据源配置|使用|销毁
Druid连接池-数据源配置|使用|销毁
- Druid连接池参数配置
-
- DruidDataSource参数配置
- Druid内置监控页面配置
- Druid配置采集web-jdbc关联监控的数据
- Druid连接池数据源创建
-
- 关于注释掉Log4j初始化的代码说明
- DruidDataSource销毁
Druid连接池参数配置
通过使用数据库连接池可以极大提升数据库CURD操作的效率,尝试参考Druid的github官网配置了一些参数。
DruidDataSource参数配置
DruidDataSource-德鲁伊数据源可以理解为它就是正在使用的某个数据库,最普遍的操作就是直接用于获取维护在连接池中的Connection连接对象,而不用自己再重新new对象了,为我们省去了创建、释放Connection对象的时间。
以下是基本的Druid数据的一些参数配置,像:JDBC基本连接参数、连接池初始化/最大容量等参数的配置。官网的配置是整合了Spring框架,通过XML文档配置的,然后通过IOC机制便捷的获取DruidDataSource的对象,可以省去自己编写代码创建数据源对象的繁琐步骤,这也是使用框架开发的好处了吧。
另外值得一提的是,官网的配置直接指定好了初始化时调用的方法init()和销毁时调用的方法close(),在start和shutdown-Spring项目时会自动调用。当然如果通过Servlet技术开发的话,也是可以基于ServletContext监听器(或者说Application域对象的监听器)javax.servlet.ServletContextListener的contextInitialized()和contextDestroyed()方法模拟Spring的IOC机制实现数据源的创建和销毁。
driverClassName=com.mysql.cj.jdbc.Driver
#开启预编译机制|开启批处理机制
url=jdbc:mysql://localhost:3306/数据库名称?useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=GMT&useServerPrepStmts=true&cachePrepStmts=true&rewriteBatchedStatements=true
username=root
password=root
initialSize=5
minIdle=5
maxActive=30
maxWait=60000
poolPreparedStatements=true #是否使用预编译机制
maxPoolPreparedStatementPerConnectionSize=20
filters=log4j,wall,stat
#-------------连接泄漏回收参数--------------------------------
#当未使用的时间超过removeAbandonedTimeout时,是否视该连接为泄露连接并删除
#默认为false
removeAbandoned=false
#泄露的连接可以被删除的超时值, 单位毫秒-默认为300*1000
removeAbandonedTimeoutMillis=300*1000
#标记当Statement或连接被泄露时是否打印程序的stack traces日志。
#默认为false
logAbandoned=true
#连接最大存活时间
#默认-1
#phyTimeoutMillis=-1
Druid内置监控页面配置
Servlet(最常用的用于收发请求和响应的类),Druid内置提供了一个StatViewServlet用于展示Druid的统计信息。其的用途包括:
①提供监控信息展示的html页面
②提供监控信息的JSON API内置监控页面是一个Servlet。
只需要在web.xml中按照Servlet的配置方法配置就行了。官网给出的例子如下,
<!-- 配置 Druid 监控信息显示页面 -->
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
<init-param>
<!-- 允许清空统计数据 -->
<param-name>resetEnable</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<!-- 用户名 -->
<param-name>loginUsername</param-name>
<param-value>druid</param-value>
</init-param>
<init-param>
<!-- 密码 -->
<param-name>loginPassword</param-name>
<param-value>druid</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>DruidStatView</servlet-name>
<url-pattern>/druid/*
Druid配置采集web-jdbc关联监控的数据
监听器(Listener)WebStatFilter用于采集web-jdbc关联监控的数据,其实就是让自己指定想要统计、不想要统计哪些数据。
关于这些init-param参数名称这样写,肯定是因为Druid内部已经预先做好了规范,只要了解参数的作用,并进行配置就可以生效了。
<filter>
<filter-name>DruidWebStatFilterfilter-name>
<filter-class>com.alibaba.druid.support.http.WebStatFilterfilter-class>
<init-param>
<param-name>exclusionsparam-name>
<param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*param-value>
init-param>
<init-param>
<param-name>profileEnableparam-name>
<param-value>trueparam-value>
init-param>
<init-param>
<param-name>resetEnableparam-name>
<param-value>trueparam-value>
init-param>
<init-param>
<param-name>loginUsernameparam-name>
<param-value>druidparam-value>
init-param>
<init-param>
<param-name>loginPasswordparam-name>
<param-value>druidparam-value>
init-param>
<init-param>
<param-name>principalCookieNameparam-name>
<param-value>USER_COOKIEparam-value>
init-param>
<init-param>
<param-name>principalSessionNameparam-name>
<param-value>USER_SESSIONparam-value>
init-param>
filter>
<filter-mapping>
<filter-name>DruidWebStatFilterfilter-name>
<url-pattern>/*url-pattern>
filter-mapping>
Druid连接池数据源创建
通过手写DruidUtil类实现DruidDataSource创建,并提供获取Connection对象的获取方法,向外部提供数据库连接对象,然后配合DButils.jar提供的QueryRunner实现数据库CURD操作。
package com.xwd.utils;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
/**
* @ClassName DruidUtils
* @Description: com.xwd.utils
* @Auther: xiwd
* @Date: 2022/2/17 - 02 - 17 - 2:33
* @version: 1.0
*/
public class DruidUtil {
//properties
private static PropertyUtil propertyUtil =null;
private static DruidDataSource dataSource;//数据源对象
// private static Logger logger;//日志打印对象
//setter
//getter
//static block
static {
//实例化Logger对象
// logger = Logger.getLogger(DruidUtil.class);
//加载配置文件
propertyUtil=new PropertyUtil("/druid.properties");
try {
//实例化数据源对象
dataSource = (DruidDataSource) DruidDataSourceFactory.createDataSource(propertyUtil.getProperties());
// logger.fatal("Druid DataSource has been initialized SUCCESSFULLY!");
} catch (Exception e) {
e.printStackTrace();
// logger.fatal("Druid DataSource initialized FAILED!");
}
}
//constructors
//methods
/**
* 获取数据源DataSource对象
* @return
*/
public static DruidDataSource getDruidDataSource(){
return dataSource;
}
/**
* 获取数据库连接Connection对象
* @return Connection对象
*/
public static Connection getConnection(){
Connection connection = null;
try {
connection = dataSource.getConnection();
} catch (SQLException e) {
e.printStackTrace();
return connection;
}
return connection;
}
/**
* 将数据库连接对象归还到数据库连接池中
* @param connection Connection-数据库连接对象
*/
public static void returnResources( Connection connection){
returnResources(null,null,connection);
}
/**
* 将数据库连接对象归还到数据库连接池中
* @param statement Statement-SQL语句执行器
* @param connection Connection-数据库连接对象
*/
public static void returnResources( Statement statement,Connection connection){
returnResources(null,statement,connection);
}
/**
* 将数据库连接对象归还到数据库连接池中
* @param resultSet ResultSet-结果集
* @param statement Statement-SQL语句执行器
* @param connection Connection-数据库连接对象
*/
public static void returnResources(ResultSet resultSet, Statement statement,Connection connection){
if (null!=resultSet) {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (null!=statement) {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (null!=connection) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
关于注释掉Log4j初始化的代码说明
由于Druid内置提供了四种LogFilter(Log4jFilter、Log4j2Filter、CommonsLogFilter、Slf4jLogFilter),用于输出JDBC执行的日志。这些Filter都是Filter-Chain扩展机制中的Filter,在一开始已经配置了参数,指定使用log4j打印日志。
filters=log4j,wall,stat
但是在使用时,还需要引入log4j.jar包或者pom坐标,并准备好log4j.properties配置文件。
#默认error及其以上级别日志都会被记录下来
log4j.rootLogger=debug,stdout,logfile
#
#打印日志到控制台上
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.err
log4j.appender.stdout.layout=org.apache.log4j.SimpleLayout
#
#通过文件记录日志
log4j.appender.logfile=org.apache.log4j.FileAppender
#日志文件路径
log4j.appender.logfile.File=d:/sys.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %l %F %p %m%n
DruidDataSource销毁
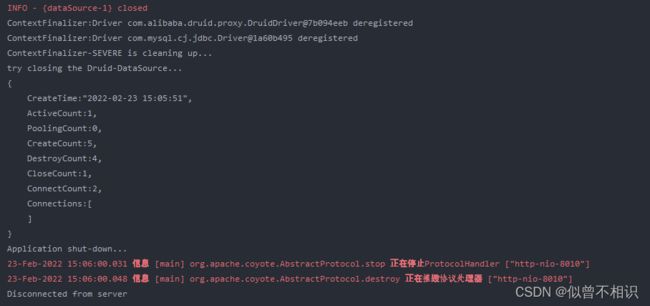
上面提到Druid官网数据源初始化参数的例子显然是整合了spring框架的,很容易配置DruidDataSource数据源的销毁方法close(),但是在使用Servlet开发时,可能很容易忽略此项。然后,就可能导致Tomcat服务shutDown时,爆出如下内容:
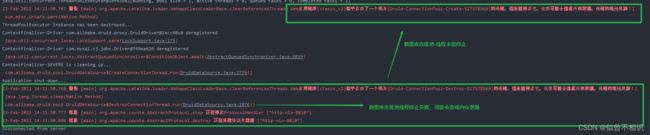
如何解决?结合已有配置参数,猜想可能是因为没有做DruidDataSource数据源销毁的操作。既然官方配置文档提示了要使用close()方法,那么就可以在ServletContext监听器实现类中的contextDestroyed()方法中,进行数据源的关闭操作。
@Override
public void contextDestroyed(ServletContextEvent sce) {
//ServletContext销毁方法
//销毁自定义的线程池对象
// destroyThreadPoolExector(sce);
//释放驱动
//releaseDriverResources();
//释放Druid数据库连接池资源
releaseDruidSources();
//提示关闭服务器应用
System.out.println("Application shut-down...");
}
/**
* 释放数据库连接池资源
*/
private void releaseDruidSources() {
System.out.println("try closing the Druid-DataSource...");
AbandonedConnectionCleanupThread.checkedShutdown();
DruidDataSource druidDataSource = DruidUtil.getDruidDataSource();
druidDataSource.close();
System.out.println(druidDataSource);
}