阿里面试必过的 Java 面试参考指南全集

又到了金三银四找工作的季节,小鱼熬了一晚上为大家展现一篇大厂及阿里面试完整题及详解答。正在为面试发愁的朋友赶紧看过来啦。
大提纲:
1.分布式
一、大型网站系统的特点
高并发,大流l量
高可用
海量数据
用户分布广泛,网络情况复杂
安全环境恶劣
需求快速变更,发布频繁
渐进式发展
二、大型网站架构演化发展历程
初始阶段的网站架构
应用服务和数据服务分离
使用缓存改善网站性能
使用应用服务器集群改善网站的并发处理能力
数据库读写分离
使用反向代理和CDN加速网站响应
使用分布式文件系统和分布式数据库系统
使用NoSQL和搜索引擎
业务拆分
分布式微服务
三、拆分VS集群
四、微服务VSSOA
五、前后端完全分离与Rest规范
六、CAP三进二和Base定理
关系型数据库遵循ACID规则
CAP三进二
BASE定理
分布式一致性理论paxos、raft、zab算法
2.中间件
一、缓存
为什么要使用缓存
优秀的缓存系统Redis
redis为什么这么快
redis的数据类型,以及每种数据类型的使用场景
redis的过期策略以及内存淘汰机制
渐进式ReHash
渐进式rehash的原因
渐进式rehash的步骤
缓存穿透
缓存雪崩
二、消息队列
消息队列应用场景
异步处理
应用解耦
流量削锋
日志处理
消息通讯
消息中间件示例
电商系统
日志收集系统
JMS消息服务
消息模型
消息消费
防止消息丢失
同步的事务——停止等待
同步的事务——连续ARQ
异步的事务——回调机制
消息的幂等处理
消息的按序处理
三、搜索引擎
概述
特点(优势):
使用场景:
倒排索引
创建索引
一些要索引的原文档(Document)
将原文档传给分次组件(Tokenizer)
将得到的词元(Token)传给语言处理组件(Linguistic Processor)
将得到的词(Term)传给索引组件(Indexer)
搜索索引
用户输入查询语句
对查询语句进行词法分析,语法分析,及语言处理
搜索索引,得到符合语法树的文档
根据得到的文档和查询语句的相关性,对结果进行排序
Lucene和ElasticSearch
分词器
3.大数据与高并发
一、秒杀架构设计
业务介绍
业务特点
瞬时并发量大
库存量少
业务简单
技术难点
现有业务的冲击
直接下订单
页面流量突增
架构设计思想
限流
削峰
异步
缓存
整体架构
客户端优化
秒杀页面
防止提前下单
API接入层优化
限制用户维度访问频率
限制商品维度访问频率
SOA服务层优化
秒杀整体流程图
总结
二、数据库架构发展历程
单机MySQL的美好年代
Memcached(缓存)+MySQL+垂直拆分
Mysql主从复制读写分离
分表分库+水平拆分+mysql集群
三、MySQL的扩展性瓶颈
四、为什么要使用NOSQLNOTONLYSQL
五、传统RDBMSVSNOSQL
六、NOSQL数据库的类型
七、阿里巴巴中文站商品信息如何存放
商品基本信息商品描述、详情、评价信息(多文字类)
商品的图片
商品的关键字
商品的波段性的热点高频信息
商品的交易、价格计算、积分累计
大型互联网应用(大数据、高并发、多样数据类型的难点和解决方案)
八、数据的水平拆分和垂直拆分
垂直拆分
水平拆分
拆分原则
案例分析
九、分布式事务
假如没有分布式事务
什么是分布式事务?
XA两阶段提交(2PC)
XA三阶段提交(3PC)
MQ事务
TCC事务
十、BitMap
Bit-map的基本思想
Bit-map应用之快速排序
Bit-map应用之快速去重
Bit-map应用之快速查询
Bit-map扩展——Bloom Filter(布隆过滤器)
总结
应用
十一、Bloom Filter
十二、常见的限流算法
计数器法
滑动窗口
漏桶算法
令牌桶算法
计数器VS滑动窗口
漏桶算法VS令牌桶算法
十三、负载均衡
dns域名解析负载均衡
反向代理负载均衡
http重定向协议实现负载均衡
分层的负载均衡算法
十四、一致性Hash算法
4.数据库
一、数据库范式
1NF(第一范式)
2NF(第二范式)
3NF(第三范式)
二、数据库开发规范
基础规范
命名规范
字段设计规范
总结
三、数据库索引
唯一索引
非唯一索引
主键索引
聚集索引
(聚簇索引)
扩展:聚集索引和非聚集索引的区别?分别在什么情况下使用?
索引实现机制
索引建立原则
四、MyISAMvsInnoDB
五、并发事务带来的问题
丢失更新
脏读(未提交读)
不可重复读
幻读(Phantom Read)
六、事务隔离级别及锁的实现机制
一级封锁协议(对应read uncommited)
二级封锁协议(对应read commited)
三级封锁协议(对应reapetableread)
最强封锁协议(对应Serialization)
七、MVCC(多版本并发控制)
八、间隙锁与幻读
间隙锁(Next-Key锁)
RR级别下防止幻读
5.设计模式与实践
一、OOP五大原则SOLID
单一责任原则
开放封闭原则
里氏替换原则
依赖倒置原则
接口分离原则
二、设计模式
三、代理模式
定义与举例
静态代理
动态代理
JDK动态代理
CGLIB动态代理
四、面向切面编程(AOP)
基本思想
登录验证
基于RBAC的权限管理
角色访问控制(RBAC)
执行流程分析
日志记录
日志记录最佳实践
事务处理
统一异常处理
五、工厂模式
简单工厂
工厂方法
抽象工厂
六、控制反转IOC
七、观察者模式
八、Zookeeper
ZK简述
存储结构
znode
znode中的存在类型
应用场景
统一命名服务
负载均衡
统一配置管理
集群管理
服务器动态上下线
写数据流程
Leader选举
6.数据结构与算法
一、树
二、BST树
三、BST树
四、AVL树
五、红黑树
六、B-树
七、B+树
八、字典树
九、跳表
十、HashMap
简介
内部实现
存储结构-字段
功能实现-方法
1.确定哈希桶数组索引位置
2.分析HashMap的put方法
3.扩容机制线程安全性
十一、ConcurrentHashMap
锁分段技术
CAS无锁算法
实现方式
存在的缺点
十二、ConcurrentLinkedQueue
延迟更新tail节点
延迟删除head节点
十三、Topk问题
简述
解决方案
实际运行
(1)单机+单核+足够大内存
(2)单机+多核+足够大内存
(3)单机+单核+受限内存
(4)多机+受限内存
经常被提及的该类问题
重复问题
十四、资源池思想
作用
线程池
连接池
十五、JVM内存管理算法
判断对象是否存活
引用计数法
可达性分析算法
垃圾回收算法
标记-清除算法(Mark-Sweep)
复制算法(Copying)
标记-整理算法(Mark-Compact)
分代收集算法(GenerationalCollection)
十六、容器虚拟化技术,Doocker思想
为什么会有docker
docker理念
实现方式
docker的组成
镜像
容器
仓库
总结
十七、持续集成、持续发布,jenkins
持续集成
手动部署
自动部署
7.面试题举例
一、设计一个分布式环境下全局唯一的发号器
1、UUID
2、数据库自增长序列或字段
3、数据库sequence表以及乐观锁
4、Redis生成ID
5、Twitter的snowflake算法
二、设计一个带有过期时间的LRU缓存
问题描述
问题分析
过期时间实现
维护一个线程
惰性删除
三、设计一个分布式锁
什么是分布式锁?
我们需要怎样的分布式锁?
基于数据库做分布式锁
1、基于乐观锁
2、基于悲观锁
基于Redis做分布式锁
1、基于redis的setnx()、expire()方法做分布式锁
2、基于redis的setnx()、get()、getset()方法做分布式锁
基于ZooKeeper做分布式锁
使用分布式锁的注意事项
分布式可重入锁的设计
四、设计一个分布式环境下的统一配置中心
配置中心概述
演进中的配置
配置中心之简版
配置中心之性能改进
配置中心之可用性改进
五、如何准备HR面试
分布式
需要完整资料文档的朋友滴滴我
一、大型网站系统的特点
高并发,大流量
需要面对高并发用户,大流量访问。Google日均PV 3亿,日IP访问数3亿;腾讯QQ的最大在线用户数1.4亿(2011年数据)。
高可用
系统7 x 24小时不间断服务。
海量数据
需要存储、管理海量数据,需要使用大量服务器。Facebook每周上传的照片数量接近10亿,百度收录的网页数目有数百亿,Google有近百万台服务器为全球用户提供服务。
用户分布广泛,网络情况复杂
许多大型互联网站都是为全球用户提供服务的,用户分布范围广,各地网络情况千差万别在国内,还有各个运营商网络互通难的问题。
安全环境恶劣
由于互联网的开放性,使得互联网站更容易受到攻击,大型网站几乎每天都会被黑客攻击。
需求快速变更,发布频繁
和传统软件的版本发布频率不同,互联网产品为快速适应市场,满足用户需求,其产品发布频率极高。一般大型网站的产品每周都有新版本发布上线,中小型网站的发布更频繁,有时候一天会发布几十次。
渐进式发展
几乎所有的大型互联网网站都是从一个小网站开始,渐进地发展起来的。Facebook是扎克伯格同学在哈佛大学的宿舍里开发的;Google的第一台服务器部署在斯坦福大学的实验室;阿里巴巴是在马云家的客厅诞生的。好的互联网产品都是慢慢运营出来的,不是一开始就开发好的,这也正好与网站架构的发展演化过程对应。
二、大型网站架构演化发展历程
大型网站的技术挑战主要来自于庞大的用户,高并发的访问和海量的数据,任何简单的业务一旦需要处理数以P计的数据和面对数以亿计的用户,问题就会变得很棘手。大型网站架构主要解决这类问题。
初始阶段的网站架构
大型网站都是从小型网站发展而来,网站架构也是一样,是从小型网站架构逐步演化而来。
小型网站最开始没有太多人访问,只需要一台服务器就绰绰有余,这时的网站架构如下图所示:
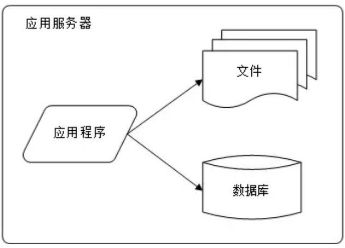
应用程序、数据库、文件等所有资源都在一台服务器上。
应用服务和数据服务分离
随着网站业务的发展,一台服务器逐渐不能满足需求:越来越多的用户访问导致性能越来越差,越来越多的数据导致存储空间不足。这时就需要将应用和数据分离。应用和数据分离后整个网站使用3台服务器:应用服务器、文件服务器和数据库服务器。这3台服务器对硬件资源的要求各不相同:
应用服务器需要处理大量的业务逻辑,因此需要更快更强大的CPU;
数据库服务器需要快速磁盘检索和数据缓存,因此需要更快的磁盘和更大的内存;
文件服务器需要存储大量用户上传的文件,因此需要更大的硬盘。
此时,网站系统的架构如下图所示:
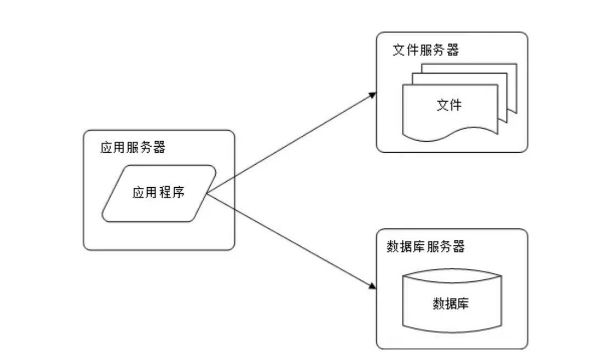
应用和数据分离后,不同特性的服务器承担不同的服务角色,网站的并发处理能力和数据存储空间得到了很大改善,支持网站业务进一步发展。但是随着用户逐渐增多,网站又一次面临挑战:数据库压力太大导致访问延迟,进而影响整个网站的性能,用户体验受到影响。这时需要对网站架构进一步优化。
使用缓存改善网站性能
网站访问的特点和现实世界的财富分配一样遵循二八定律:80%的业务访问集中在20%的数据上。既然大部分业务访问集中在一小部分数据上,那么如果把这一小部分数据缓存在内存中,就可以减少数据库的访问压力,提高整个网站的数据访问速度,改善数据库的写入性能了。网站使用的缓存可以分为两种:缓存在应用服务器上的本地缓存和缓存在专门的分布式缓存服务器上的远程缓存。
本地缓存的访问速度更快一些,但是受应用服务器内存限制,其缓存数据量有限,而且会出现和应用程序争用内存的情况。
远程分布式缓存可以使用集群的方式,部署大内存的服务器作为专门的缓存服务器,可以在理论上做到不受内存容量限制的缓存服务。
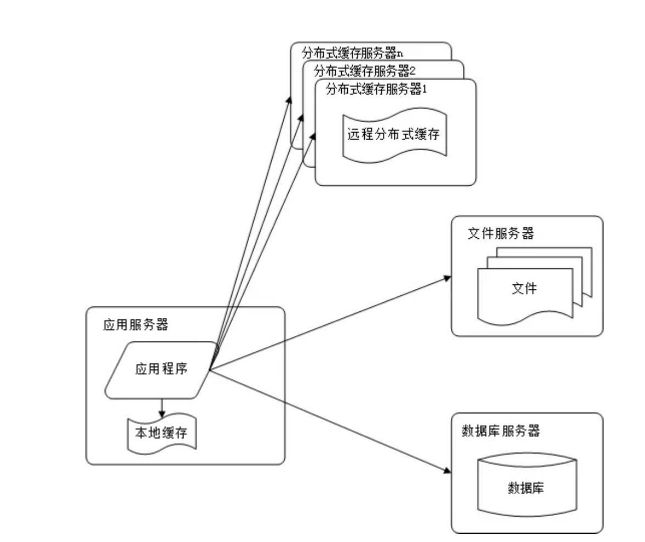
使用缓存后,数据访问压力得到有效缓解,但是单一应用服务器能够处理的请求连接有限,在网站访问高峰期,应用服务器成为整个网站的瓶颈。
使用应用服务器集群改善网站的并发处理能力
使用集群是网站解决高并发、海量数据问题的常用手段。当一台服务器的处理能力、存储空间不足时,不要企图去更换更强大的服务器,对大型网站而言,不管多么强大的服务器,都满足不了网站持续增长的业务需求。这种情况下,更恰当的做法是增加一台服务器分担原有服务器的访问及存储压力。对网站架构而言,只要能通过增加一台服务器的方式改善负载压力,就可以以同样的方式持续增加服务器不断改善系统性能,从而实现系统的可伸缩性。应用服务器实现集群是网站可伸缩架构设计中较为简单成熟的一种,如下图所示:

通过负载均衡调度服务器,可以将来自用户浏览器的访问请求分发到应用服务器集群中的任何一台服务器上,如果有更多用户,就在集群中加入更多的应用服务器,使应用服务器的压力不再成为整个网站的瓶颈。
数据库读写分离
网站在使用缓存后,使对大部分数据读操作访问都可以不通过数据库就能完成,但是仍有一部分读操作(缓存访问不命中、缓存过期)和全部的写操作都需要访问数据库,在网站的用户达到一定规模后,数据库因为负载压力过高而成为网站的瓶颈。目前大部分的主流数据库都提供主从热备功能,通过配置两台数据库主从关系,可以将一台数据库服务器的数据更新同步到另一台服务器上。网站利用数据库的这一功能,实现数据库读写分离,从而改善数据库负载压力。如下图所示:

应用服务器在写数据的时候,访问主数据库,主数据库通过主从复制机制将数据更新同步到从数据库,这样当应用服务器读数据的时候,就可以通过从数据库获得数据。为了便于应用程序访问读写分离后的数据库,通常在应用服务器端使用专门的数据访问模块,使数据库读写分离对应用透明。
使用反向代理和CDN加速网站响应
随着网站业务不断发展,用户规模越来越大,由于中国复杂的网络环境,不同地区的用户访问网站时,速度差别也极大。有研究表明,网站访问延迟和用户流失率正相关,网站访问越慢,用户越容易失去耐心而离开。为了提供更好的用户体验,留住用户,网站需要加速网站访问速度。主要手段有使用CDN和方向代理。如下图所示:

CDN和反向代理的基本原理都是缓存。
CDN部署在网络提供商的机房,使用户在请求网站服务时,可以从距离自己最近的网络提供商机房获取数据反向代理则部署在网站的中心机房,当用户请求到达中心机房后,首先访问的服务器是反向代理服务器,如果反向代理服务器中缓存着用户请求的资源,就将其直接返回给用户
使用CDN和反向代理的目的都是尽早返回数据给用户,一方面加快用户访问速度,另一方面也减轻后端服务器的负载压力。
使用分布式文件系统和分布式数据库系统
任何强大的单一服务器都满足不了大型网站持续增长的业务需求。数据库经过读写分离后,从一台服务器拆分成两台服务器,但是随着网站业务的发展依然不能满足需求,这时需要使用分布式数据库。文件系统也一样,需要使用分布式文件系统。如下图所示:
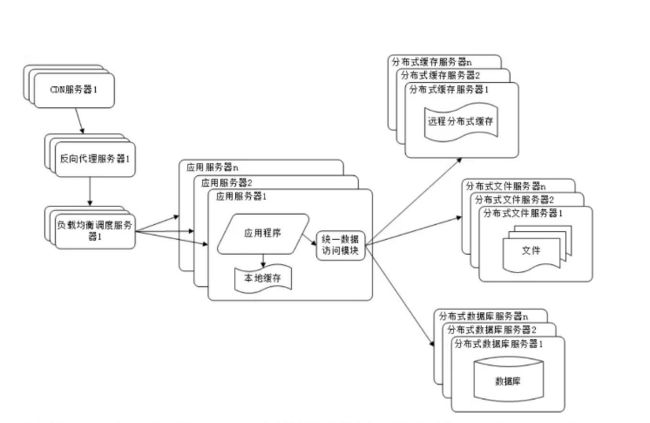
分布式数据库是网站数据库拆分的最后手段,只有在单表数据规模非常庞大的时候才使用。不到不得已时,网站更常用的数据库拆分手段是业务分库,将不同业务的数据部署在不同的物理服务器上。
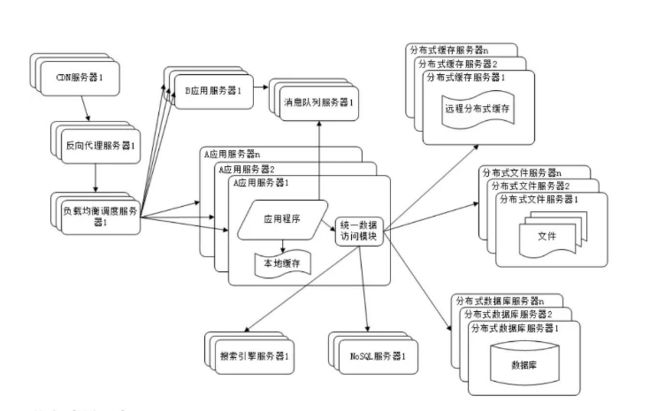
使用NoSQL和搜索引擎
随着网站业务越来越复杂,对数据存储和检索的需求也越来越复杂,网站需要采用一些非关系数据库技术如NoSQL和非数据库查询技术如搜索引擎。如下图所示:

NoSQL和搜索引擎都是源自互联网的技术手段,对可伸缩的分布式特性具有更好的支持。应用服务器则通过一个统一数据访问模块访问各种数据,减轻应用程序管理诸多数据源的麻烦。
业务拆分
大型网站为了应对日益复杂的业务场景,通过使用分而治之的手段将整个网站业务分成不同的产品线。如大型购物交易网站都会将首页、商铺订单、买家、卖家等拆分成不同的产品线,分归不同的业务团队负责。具体到技术上,也会根据产品线划分,将一个网站拆分成许多不同的应用,每个应用独立部署。应用之间可以通过一个超链接建立关系(在首页上的导航链接每个都指向不同的应用地址),也可以通过消息队列进行数据分发,当然最多的还是通过访问同一个数据存储系统来构成一个关联的完整系统,如下图所示:
由于本文详解内容过长就不一一展现,需要完整资料文档的朋友滴滴我。希望对大家有所帮助!
