Python数据分析与挖掘
文章目录
- 前言
- 数据来源
- 可视化及其数据处理
-
- 词云
- 画饼图
- 画走势图
- 根据表中不同字段画条形图
- 画地图
- 合并多个csv文件
- 最后利用各种挖掘算法分析解释
- 感触
前言
前段时间做了个回归模型预测分析,效果不好,只是简单地熟悉了数据挖掘的流程而已,下面记录一些数据挖掘常用到的东西。
数据来源
- 找公开的
- 爬虫
- 现成软件,比如八爪鱼
下面是一个爬历史天气的代码:
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
# -*- coding: utf-8 -*-
"""
Created on Sun May 5 11:11:43 2019
@author: kdc
"""
import requests
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
import os
import csv
import time
def get_one_page(url):
'''
获取网页
'''
print('正在加载'+url)
headers={'User-Agent':'User-Agent:Mozilla/5.0'}
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.content
return None
except RequestException:
return None
def parse_one_page(html):
'''
对网页内容进行解析
'''
soup = BeautifulSoup(html, "lxml")
info = soup.find('div', class_='wdetail')
rows=[]
tr_list = info.find_all('tr')[1:] # 使用从第二个tr开始取
for index, tr in enumerate(tr_list): # enumerate可以返回元素的位置及内容
td_list = tr.find_all('td')
date = td_list[0].text.strip().replace("\n", "") # 取每个标签的text信息,并使用replace()函数将换行符删除
weather = td_list[1].text.strip().replace("\n", "").split("/")[0].strip()
temperature_high = td_list[2].text.strip().replace("\n", "").split("/")[0].strip()
temperature_low = td_list[2].text.strip().replace("\n", "").split("/")[1].strip()
rows.append((date,weather,temperature_high,temperature_low))
return rows
cities = ['tianjin','heilongjiang']
years = ['2012','2013','2014','2015','2016','2017','2018']
months = ['01','02','03','04','05','06','07','08','09','10','11','12']
if __name__ == '__main__':
# os.chdir() # 设置工作路径
for city in cities:
with open(city + '_weather.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(['date','weather','temperature_high','temperature_low'])
for year in years:
for month in months:
url = 'http://www.tianqihoubao.com/lishi/'+city+'/month/'+year+month+'.html'
html = get_one_page(url)
content=parse_one_page(html)
writer.writerows(content)
print(city+year+month+' is OK!')
time.sleep(2)
返回顶部
可视化及其数据处理
-
词云
# -*- coding: utf-8 -*-
"""
Created on Sat May 25 10:04:26 2019
@author: Administrator
"""
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from scipy.misc import imread
from wordcloud.color_from_image import ImageColorGenerator
#将数据打开
text = open("f:\\pachong\\aa.txt",'r',encoding='gbk').read()
#你需要处理的背景图片
bg_pic = imread("f:\\pachong\\picture\\b.jpg")
#汉字要加这个
font=r'C:\\Windows\\Fonts\\STFANGSO.ttf'
#生成词云
wordcloud = WordCloud(mask=bg_pic,background_color='white',font_path=font,scale=1.5).generate(text)
#生成背景图片
image_colors=ImageColorGenerator(bg_pic)
#展示词云
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
#在本地目录下生成该图片
#wordcloud.to_file('f:\\house_price\\词云.pdf')
效果:
这是网易云音乐歌曲《你的酒馆对我打了烊》的评论,有毒啊!

返回顶部
-
画饼图
# -*- coding: utf-8 -*-
"""
Created on Mon May 6 22:15:50 2019
@author: Administrator
"""
import pandas as pd
###正常显示中文
import matplotlib.pyplot as plot
import matplotlib
matplotlib.rcParams['font.sans-serif']=['SimHei'] #使用指定的汉字字体类型(此处为黑体)
#matplotlib.rcParams['axes.unicode_minus']=False #用来正常显示负号
####主要功能片段
city='chengdu'
citydict={'tianjin':'天津','chengdu':'成都','qujing':'曲靖'}
try:
#gbk不行那就utf_8
data = pd.read_csv(r'f:\\pachong\\'+city+'_weather.csv',encoding='gbk')
except IOError as e:
print(e)
pieData=data['weather'].value_counts()
after={}
labels = []
# 取出前几个,剩余的所占比重小,所有的作为其他显示
cnt = 0
required_cnt=7
sum=0
for key, value in pieData.items():
cnt += 1
if cnt > required_cnt:
sum=sum+value
#print("{}:{}".format(key, value))
if cnt <= required_cnt:
after.update({key:value})
labels.append(key)
after.update({'其它':sum})
labels.append('其它')
#设置标题名
plot.title(citydict[city]+"天气百分比")
#为饼状图的每个区间安排颜色'lightskyblue'浅蓝色
colors = ['orange','red','pink','lightskyblue','teal','green']
#表示八个扇区“邻居”之间的缝隙距离
explode = (0.03, 0.02, 0.02, 0.03,0.03, 0.02, 0.02,0.02)
patches, l_text, p_text = plot.pie(pd.Series(after), explode=explode,labels=labels,colors=colors,
labeldistance=1.06, autopct='%3.0f%%', shadow=False,
startangle=90, pctdistance=0.6)
# labeldistance,文本的位置离远点有多远,1.1指1.1倍半径的位置
# autopct,圆里面的文本格式,%3.1f%%表示小数有三位,整数有一位的浮点数
# shadow,饼是否有阴影
# startangle,起始角度,0,表示从0开始逆时针转,为第一块。一般选择从90度开始比较好看
# pctdistance,百分比的text离圆心的距离
# patches, l_texts, p_texts,为了得到饼图的返回值,p_texts饼图内部文本的,l_texts饼图外label的文本
# 改变文本的大小
# 方法是把每一个text遍历。调用set_size方法设置它的属性
for t in l_text:
t.set_size = (30)
for t in p_text:
t.set_size = (20)#去掉=号修改字体大小
# 设置x,y轴刻度一致,这样饼图才能是圆的
plot.axis('equal')
plot.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))#legend为左上角那种集合的说明
# loc: 表示legend的位置,包括'upper right','upper left','lower right','lower left'等
# bbox_to_anchor: 表示legend距离图形之间的距离,当出现图形与legend重叠时,可使用bbox_to_anchor进行调整legend的位置
# 由两个参数决定,第一个参数为legend距离左边的距离,第二个参数为距离下面的距离
plot.grid()
#plot.savefig('f:\\'+citydict[city]+'.pdf')
plot.show()
效果:
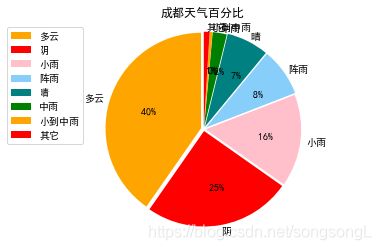
返回顶部
-
画走势图
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sun May 5 20:29:47 2019
@author: kimmel
"""
'''date weather temperature_high(℃) temperature_low(℃)'''
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
try:
data = pd.read_csv(r'F://pachong//tianjin_weather.csv',encoding='gbk')
except IOError as e:
print(e)
x = np.arange(0,365,1)
plt.figure(figsize=(10,6))
#正常显示负号
plt.rcParams['axes.unicode_minus'] = False
#表中有好多年的数据,用365乘以某数可以限定到某年到某年
#plt.plot(x,data['temperature_high'][365*0:365*1],label='Temperature_high',color='red' , alpha=0.8)
#plt.plot(x,data['temperature_low'][365*0:365*1],label='Temperature_low', color='blue')
plt.plot(x,data['temperature_high'][365*6:365*7],label='Temperature_high',color='red' , alpha=0.8)
plt.plot(x,data['temperature_low'][365*6:365*7],label='Temperature_low', color='blue')
plt.xlabel("Time(day)")
plt.ylabel(("%s%c%s")%("Temperature(",u"\u2103",")"))
plt.ylim(-30,45)
y_ticks = np.arange(-30,45,5)
plt.yticks(y_ticks)
plt.legend()
#plt.savefig(r'f:\\tianjin.pdf')
plt.show()
效果:
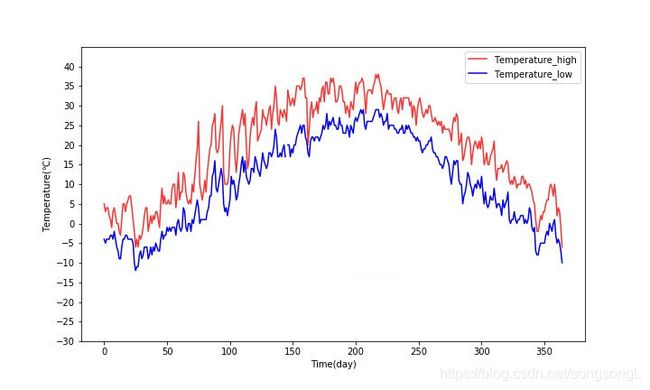
返回顶部
-
根据表中不同字段画条形图
# -*- coding: utf-8 -*-
"""
Created on Wed May 8 12:54:47 2019
@author: Administrator
"""
import matplotlib.pyplot as plt
import pandas as pd
###正常显示中文
import matplotlib
city='tj'
citydict={'city':'全国部分城市平均','tj':'天津','bj':'北京','cd':'成都','gz':'广州','sh':'上海','sz':'深圳','wh':'武汉','hz':'杭州','gy':'贵阳','cs':'长沙','cq':'重庆','qj':'曲靖','km':'昆明'}
matplotlib.rcParams['font.sans-serif']=['SimHei'] #使用指定的汉字字体类型(此处为黑体)
df = pd.read_csv(r'C:\Users\Administrator\Desktop\lianjia-beike-spider-master\data\ke\xiaoqu\all\all_city'+'.csv',encoding='gbk')
var = df.groupby('城市')['挂牌均价'].mean()
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.set_xlabel('地区')
ax1.set_ylabel('房价')
ax1.set_title(citydict[city]+'各区平均房价')
var.plot(kind='bar')
plt.savefig('f:\\'+citydict[city]+'房价.pdf')
plt.show()
效果:

返回顶部
-
画地图
# -*- coding: utf-8 -*-
"""
Created on Wed May 8 12:54:47 2019
@author: Administrator
"""
import pandas as pd
from pyecharts import Map,Geo
###正常显示中文
import matplotlib
city='tj'
citydict={'city':'全国部分城市平均','tj':'天津','bj':'北京','cd':'成都','gz':'广州','sh':'上海','sz':'深圳','wh':'武汉','hz':'杭州','gy':'贵阳','cs':'长沙','cq':'重庆','qj':'曲靖','km':'昆明'}
matplotlib.rcParams['font.sans-serif']=['SimHei'] #使用指定的汉字字体类型(此处为黑体)
df = pd.read_csv(r'C:\Users\Administrator\Desktop\lianjia-beike-spider-master\data\ke\xiaoqu\all\all_city'+'.csv',encoding='gbk')
var = df.groupby('城市')['挂牌均价'].mean()
data=list(var.items())
attr, value = Geo.cast(data)
Geo = Geo("全国部分城市房价热力图", "数据来源房价信息表", title_color="#fff", title_pos="center", width=1200, height=600, background_color='#404a59')
Geo.add("房价热力图", attr, value, visual_range=[0, 20000], type='heatmap',visual_text_color="#fff", symbol_size=15, is_visualmap=True, is_roam=False)
Geo.show_config()
Geo.render(path="f:\\a1.html")
#世界地图:
map0 = Map("世界地图示例", width=1200, height=600)
map0.add("世界地图", attr, value, maptype="world", is_visualmap=True, visual_text_color='#000')
map0.render(path="f:\\a2.html")
#中国地图
# maptype='china' 只显示全国直辖市和省级
# 数据只能是省名和直辖市的名称
map1 = Map("中国地图",'中国地图', width=1200, height=600)
map1.add("", attr, value, visual_range=[0, 50], maptype='china', is_visualmap=True, visual_text_color='#000')
map1.show_config()
map1.render(path="f:\\a3.html")
#省份地图
province= {'云南': 6}
provice=list(province.keys())
values=list(province.values())
map2 = Map("云南地图",'云南', width=1200, height=600)
map2.add('云南', provice, values, visual_range=[1, 10], maptype='云南', is_visualmap=True, visual_text_color='#000')
map2.show_config()
map2.render(path="f:\\a4.html")
'''
#区县地图
quxian = []
values3 = []
map3 = Map("aa",'aa', width=1200, height=600)
map3.add("xx", quxian, values3, visual_range=[1, 10], maptype='xx', is_visualmap=True, visual_text_color='#000')
map3.render(path="f:\\a5.html")
'''
效果:
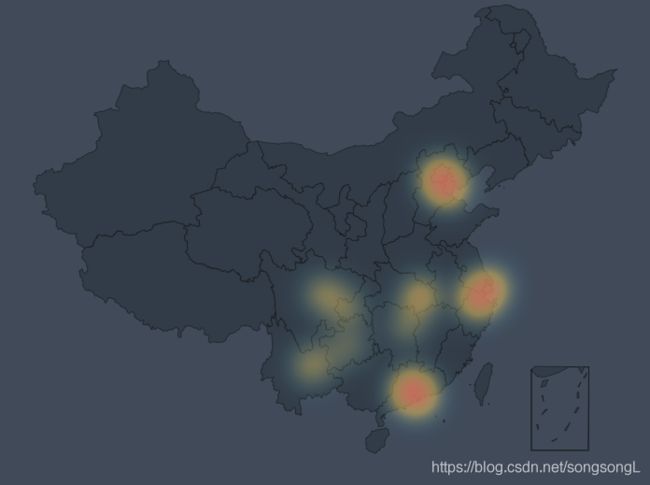
返回顶部
-
合并多个csv文件
import pandas as pd
import os
Folder_Path = r'C:\Users\Administrator\Desktop\\all' #要拼接的文件夹及其完整路径,注意不要包含中文
SaveFile_Path = r'f:\\xx' #拼接后要保存的文件路径
SaveFile_Name = r'all.csv' #合并后要保存的文件名
#修改当前工作目录
os.chdir(Folder_Path)
#将该文件夹下的所有文件名存入一个列表
file_list = os.listdir()
#读取第一个CSV文件并包含表头
df = pd.read_csv(Folder_Path +'\\'+ file_list[0],encoding="gbk") #或UTF-8
#将读取的第一个CSV文件写入合并后的文件保存
df.to_csv(SaveFile_Path+'\\'+ SaveFile_Name,encoding="gbk",index=False)
#循环遍历列表中各个CSV文件名,并追加到合并后的文件
for i in range(1,len(file_list)):
try:
df = pd.read_csv(Folder_Path + '\\'+ file_list[i],encoding="gbk")
except:
pass
df.to_csv(SaveFile_Path+'\\'+ SaveFile_Name,encoding="gbk",index=False, header=False, mode='a+')
返回顶部
最后利用各种挖掘算法分析解释

感触
对于新手而言,前期数据处理还是挺好玩的,刨除数据挖掘不说,自己搞点小东西玩玩也是好玩的。到真正的挖掘分析部分就有点吃不消了,书上那些人家总结好的算法,说实话,不能很好理解,只能是按照人家分析步骤自己也照着做,最终得出个什么结果。
返回顶部