【OpenCV】OCR文档识别
文章目录
- 前言
- 一、pytesseract
- 二、PPOCR
- 三、百度API
- 四、TrWebOCR
- 总结
前言
OCR文档识别方法有多种,例如EasyOCR,PP-OCR,cnOCR,PP_OCR等。
本文介绍pytesseract,百度API和TrWebOCR方法以及PP_OCR四种方法。
其实只有第一种方法使用了OpenCV的相关算法。
一、pytesseract
参考这篇文章,写的很详细,不在赘述。
opencv项目实战(2)——文档扫描OCR识别
二、PPOCR
百度的产品。
先安装这3个库。
pip install paddlepaddle
pip install shapely
pip install paddleocr
在py文件同一级目录下放置一个待识别文字的图片。

然后执行以下代码:
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
# 输入待识别图片路径
img_path = r"yy.jpg"
# 输出结果保存路径
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores)
im_show = Image.fromarray(im_show)
im_show.show()
三、百度API
还是分两步走,第一步获取鉴权数据。
# import requests
# # client_id 为官网获取的AK, client_secret 为官网获取的SK
# host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【client_id 】&client_secret=【client_secret 】'
# response = requests.get(host)
# if response:
# print(response.json())
搜索百度AI进去控制台,在下图位置找到应用。
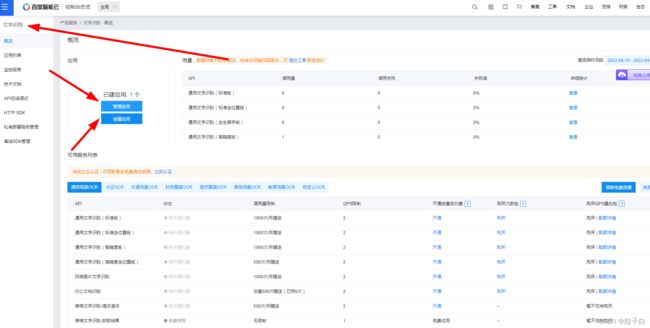
创建应用获取SK和SK。
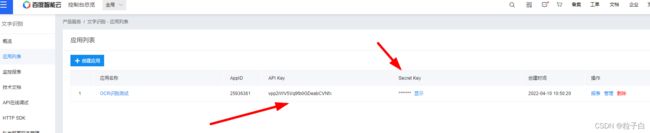
获取鉴权Token。运行以下代码获取的到access_token,请注意,不是refresh_token。
import requests
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【AK】&client_secret=【SK】'
response = requests.get(host)
if response:
print(response.json())
第二步,打开图片上传。
import requests
import base64
'''
通用文字识别(高精度版)
'''
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
# 二进制方式打开图片文件
f = open('E:\VSCode\EasyOCR/555.jpg', 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
access_token = '24.3772970dc5e6f054177e3fb7.2592000.1652151337.282335-25936381'#从第一步获取的Token
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json())
四、TrWebOCR
这里是用群晖的docker部署TrWebOCR环境。
端口配置如下:
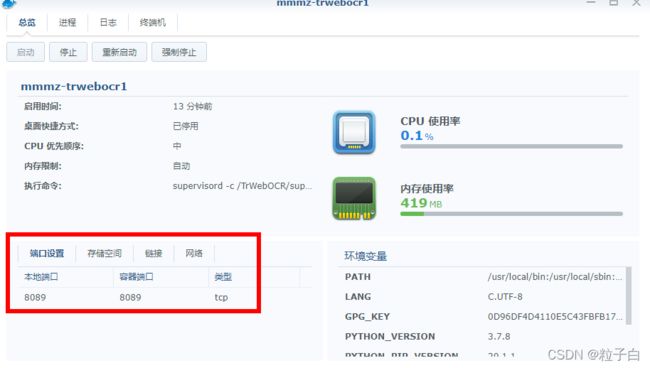
浏览器访问IP:8089

识别效果如下:
还有一种方法通过调用API方法实现,同百度API的区别是,百度API有500还是1000的免费额度,超过付费,而这个方法是免费的。但是精度没有百度API好。
百度是一家好公司,有能力就支持一下。
import requests
import json
url = 'http://192.168.8.177:8089/api/tr-run/'
img1_file = {
'file': open('E:\VSCode\EasyOCR/555.jpg', 'rb')
}
res = requests.post(url=url, data={'compress': 0}, files=img1_file)
data=res.text
print(res.text)
jsonobj = json.loads(data)
toCntPercent = jsonobj['data']['raw_out']
print(toCntPercent)
#把文字提取出来
mystr = str(toCntPercent)
obj=re.compile(r"(.*?)'(?P.*?)'" ,re.S)
all_date=obj.finditer(mystr)
for it in all_date:
mydate=it.group("temp")
print(mydate)
图片如下:

提取结果:

总结
建议使用PP-OCR。群晖不一定每个人都有,但是docker部署,只要是linux系统,基本上按照TrWebOCR的Gitee网页说明的几个步骤部署还是很快的。详情看TrWebOCR链接