图像分割算法
我的毕业论文是做图像分割的,至于为啥要做这个,我自己都不知道,更别提做它的意义了,如果非要说,那就是单纯的为了毕业!
面对毕业写文章就是为了整理一下这个过程中我遇到的疑问,以及经过资料查找得到的答案,在此记录下来,就是为了防止自己忘了还可以翻看~(基础不是很好,可能在理解别人的回答时产生了歧义,如有错误还请指正)

图像处理和计算机视觉之间的区别
我当时选题面临的第一个疑问就是图像处理和计算机视觉(CV)之间有什么区别?图像处理重点在于处理图片,是图片到图片的过程。CV的重点是分析和理解图片,是图像到应用的过程,而分割刚好就介于中间。整个流程差不多就是对原始图像先进行图像去噪增强等,接着对特定的目标进行图像分割,最后用统计学的方式进行模式识别。
图像分割中的语义分割、实力分割和全景分割的区别
图像分类的任务就是给定一个图像,正确给出这个图像所属的类别,比如经典的手写数字识别,只需要判断输入的图片是数字几即可。目标检测就是识别图像中存在的内容并标记出其具体位置。
语义分割就是对图像中的每一个像素点进行分类,要具体分割到每一个实例的边缘,但是同一物体的不同实例不需要单独分割出来,比如一幅图像中有好多人,只需要分割出人就行,不用区别是人1,人2,人3等.....

实例分割是目标检测和语义分割的结合,相对目标检测的边界框,实例分割可精确到物体的边缘;相对语义分割,实例分割需要标注出图上同一物体的不同个体(人1,人2,人3...)

全景分割是语义分割和实例分割的结合,要检测出图像中所有的目标并区分出不同的类别

总结起来就是语义分割是最简单的,所以为了顺利毕业,毫不犹豫的选择了语义分割!!!
经典分割网络
第一次接触分割是在医学相关的论文里,所以相比于FCN我更先了解到Unet模型。Unet模型结构很简单,主要就是一个编码和解码的结构。
我没有系统的学过机器学习深度学习相关的理论知识,顶多就是买两本书大概的看一下机器学习有哪些算法,深度学习是个什么东西,所以对于梯度下降、损失函数、激活函数、线性插值等对我来说就是个名词,或者说是基于框架下的一些API,没有想过具体是怎么实现的。
对于代码相关的也都是直接在github上down一些能直接运行的代码,浅改一下网络结构能跑通就完事了,所以就出现了深度学习越学越不懂的情况,本来是针对某一疑问去百度的,结果百度的过程中带出了更多的疑问点......
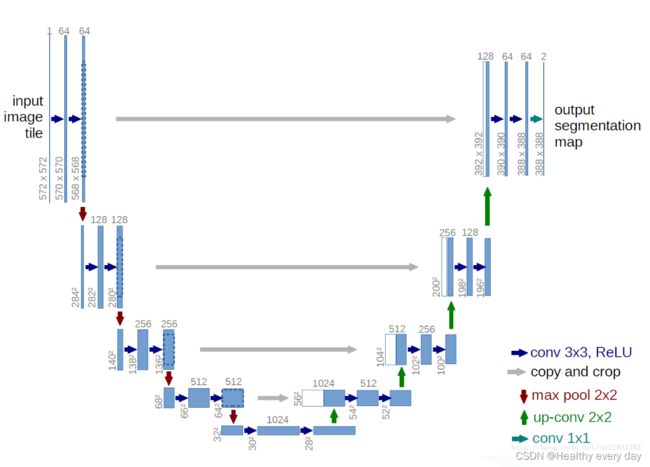
我们都知道分割的网络是去掉了分类网络的全连接(FC)层,然后对特征图进行上采样,那么分类网络FC输出的是什么,最后是怎么实现分类的呢?
全连接层(FC)通俗的理解就是将前面不同卷积层找到特征都拿过来整成一个值,值越大代表正类的可能性就越大,知乎形象比喻(假设你是一只小蚂蚁,你的任务是找小面包。你的视野还比较窄,只能看到很小一片区域。当你找到一片小面包之后,你不知道你找到的是不是全部的小面包,所以你们全部的蚂蚁开了个会,把所有的小面包都拿出来分享了。全连接层就是这个蚂蚁大会~)
CNN 入门讲解:什么是全连接层(Fully Connected Layer)? - 知乎 (zhihu.com)
在FC之后一般会和softmax连用来实现分类的效果,那么如何直观的理解FC+softmax?

全连接层将权重矩阵与输入向量相乘再加上偏置,将n 个(−∞,+∞)的实数映射为K 个(−∞,+∞)的实数(分数);Softmax将K 个(−∞,+∞)的实数映射为K个(0,1)的实数(概率),同时保证它们之和为1,其中k就是类别数。深度学习源码里经常会出现logits,logits在深度学习中就代表全连接层的输出,也就是未经过归一化的概率,然后将logits作为softmax的输入生成一个归一化的概率向量,进而得到属于每一类别的概率。
好了继续回到Unet,Unet在下采样的过程中图像分辨率不断减小,感受野不断的增大,所以为了获得和输入图像大小相同的分割图就需要对得到的低分辨率feature maps,继续处理变成高分辨率的feature maps,我们都知道下采样一般都是通过池化层来实现的,那么上采样是如何恢复图像的呢?有哪几种方法?
在深度学习中,上采样主要有三种方式:插值法(Interpolation)、反卷积 (Deconvolution) 和 反池化 (unPooling) ,关于实现的细节可以看下面的链接
上采样方法_ldd_unique的博客-CSDN博客_上采样
怎样通俗易懂地解释反卷积? - 知乎
反卷积和上采样+卷积的区别? - 知乎
从上图可以看到Unet模型在网络的末端得到了两张特征图,是整个网络输出的类别数量的特征图!!要经过softmax才可以得到对应类别数量的概率图,是针对每个像素点给出其属于哪个类的概率!!对于一个二分类的问题,为什么有的unet结构图给出的输出是1,有的又是2呢,Unet的最后一层具体是怎么实现的?
其实看过unet的代码都知道unet的最后一层都是映射成通道数为1的logits(logits上面有提到哦,就是即将要输入softmax的数据)
def unet(pretrained_weights = None,input_size = (256,256,1)):
inputs = Input(input_size)
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(inputs)
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv1)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool1)
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv2)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool2)
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv3)
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv4)
drop4 = Dropout(0.5)(conv4)
pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv5)
drop5 = Dropout(0.5)(conv5)
up6 = Conv2D(512, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(drop5))
merge6 = concatenate([drop4,up6], axis = 3)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge6)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv6)
up7 = Conv2D(256, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv6))
merge7 = concatenate([conv3,up7], axis = 3)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge7)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv7)
up8 = Conv2D(128, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv7))
merge8 = concatenate([conv2,up8], axis = 3)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge8)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv8)
up9 = Conv2D(64, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv8))
merge9 = concatenate([conv1,up9], axis = 3)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge9)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)
conv9 = Conv2D(2, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)
conv10 = Conv2D(1, 1, activation = 'sigmoid')(conv9)
model = Model(input = inputs, output = conv10)
由上面代码可以看到,conv10将feature转化为了通道数为1的logits,然后经过激活函数sigmoid将logits归一化到0-1之间,并且概率之和为1。那么为什么二分类的logits只要一个通道就可以计算损失呢?因为假设像素的前景的概率为prob,则背景一定是1-prob。对于多分类而言,通常使用softmax函数约束各类的prob相加为1,logits的通道数也由1改为类别数+1(背景)。
预测得到的分割图是如何与标签之间计算损失的呢,我们以常用的交叉熵损失函数为例
交叉熵损失函数

和分类计算损失的过程类似 ,语义分割就是针对每个像素点进行的,见下文
[CE(p,q) = -p*log(q) ],其中 (q) 为预测的概率,(q∈[0,1]), (p) 为标签,(p∈{0,1})。对于概率,所有分类的概率 (q) 之和满足相加等于1,而对于标签,则需要进行one-hot编码,使得有且只有一个分类的 (p) 为1,其余的分类为0。见下图(a)单通道输出损失计算过程 (b)多通道输出损失计算过程

(a)

(b)
具体的实现细节见链接语义分割单通道和多通道输出交叉熵损失函数的计算问题 - 走看看
对于标签图需要对其进行one-hot编码,什么是one-hot编码?为什么要进行one-hot编码?
图像分割中数据预处理 One-hot 编码的两种实现方式_LYNNzZ361的博客-CSDN博客
整个Unet的实现流程差不多就是这样,第一阶段结束!!!