机器学习算法(二十二):局部离群因子检测方法 (Local Outlier Factor, LOF)
目录
1 离群点挖掘方法
2 LOF 算法背景
3 LOF算法简介
3.1 距离度量尺度
3.1.1 Eucild(欧几里得)距离
3.1.2 Hamming(汉明)距离
3.1.3 Mahalanobis(马氏)距离
3.1.4 球面距离
3.2 第 k 距离
3.3 k 距离邻域
3.4 可达距离
3.5 局部可达密度
3.6 局部离群因子
3.7 复杂度
4 LOF离群因子检测算法python3 实现
1 离群点挖掘方法

2 LOF 算法背景
基于密度的离群点检测方法的关键步骤在于给每个数据点都分配一个离散度,其主要思想是:针对给定的数据集,对其中的任意一个数据点,如果在其局部邻域内的点都很密集,那么认为此数据点为正常数据点;而离群点则是距离正常数据点最近邻的点都比较远的数据点。通常有阈值进行界定距离的远近。在基于密度的离群点检测方法中,最具有代表性的方法是局部离群因子检测方法 (Local Outlier Factor, LOF)。
3 LOF算法简介
Local Outlier Factor(LOF)是基于密度的经典算法,由慕尼黑大学的Markus M. Breunig等发表在2000年的数据库顶级会议SIGMOD上,论文为《LOF: Identifying Density-Based Local Outliers》。
LOF旨在发现数据集中的异常模式。在LOF之前,对异常的认知是非黑即白的,一个样本点要不是正常点,要不是异常点。而Breunig等想量化每个样本点的异常程度,并认为这取决于样本点跟周围邻居的密度对比。LOF的核心思想是,异常与否,取决于局部环境,因而被命名为”局部异常因子算法”。
LOF的优点在于它简单,直观,不需要知道数据集的分布,并能量化每个样本点的异常程度。
在众多的离群点检测方法中,LOF 方法是一种典型的基于密度的高精度离群点检测方法。在 LOF 方法中,通过给每个数据点都分配一个依赖于邻域密度的离群因子 LOF,进而判断该数据点是否为离群点。
- 若异常分数 LOF 接近1,则说明样本点p的局部密度跟邻居的接近。
- 若异常分数 LOF 小于1,表明p处于一个相对密集的区域,不像一个异常点。
- 若异常分数 LOF 远大于1,表明p跟其他点比较疏远,很可能是一个异常点。
3.1 距离度量尺度
设对于没有相同点的样本集合 ![]() ,假设共有
,假设共有 ![]() 个检测样本,数据维数为
个检测样本,数据维数为 ![]() ,对于
,对于
![]()
针对数据集 ![]() 中的任意两个数据点
中的任意两个数据点 ![]() ,定义如下几种常用距离度量方式
,定义如下几种常用距离度量方式
3.1.1 Eucild(欧几里得)距离
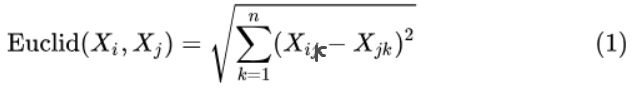
3.1.2 Hamming(汉明)距离
注:汉明距离使用在数据传输差错控制编码里面,用于度量信息不相同的位数。
取 ![]() ,易见
,易见  与
与 ![]() 中有 2 位数字不相同,因此 与
中有 2 位数字不相同,因此 与 ![]() 的汉明距离为 2。
的汉明距离为 2。
对于数据处理,一种技巧是先对连续数据进行分组,化为分类变量(分组变量),对分类变量可以引入汉明距离进行度量。——沃兹基 · 硕德
3.1.3 Mahalanobis(马氏)距离
设样本集 ![]() 的协方差矩阵为
的协方差矩阵为 ![]() ,记其逆矩阵为
,记其逆矩阵为 ![]() ,
,
- 若
 可逆,对 做 SVD 分解(奇异值分解),得到:
可逆,对 做 SVD 分解(奇异值分解),得到:
![]()
- 若 不可逆,则使用广义逆矩阵
 代替
代替  ,对其求彭罗斯广义逆,有:
,对其求彭罗斯广义逆,有:
![]()
则两个数据点 ![]() 的马氏距离为
的马氏距离为

注:马氏距离表示数据的协方差距离,利用 Cholesky 变换处理不同维度之间的相关性和度量尺度变换的问题,是一种有效计算样本集之间的相似度的方法。
3.1.4 球面距离
球面距离其实是在欧式距离基础上进行转换得到的,并不是一种独特的距离度量方式,在地理信息转换中经常使用,本文对此进行详细介绍。

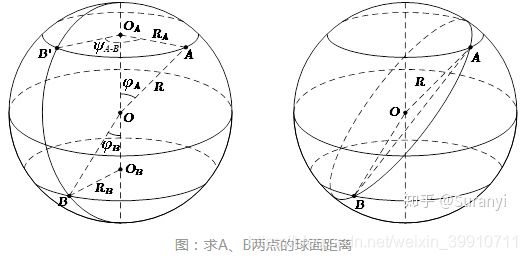
设 ![]() 两点的球面坐标为
两点的球面坐标为 ![]() 。若该球体为地球,则
。若该球体为地球,则 ![]() 分别代表纬度和经度。(下文的
分别代表纬度和经度。(下文的 ![]() 为
为 ![]() 的余角,便于推导所使用的记号)
的余角,便于推导所使用的记号)
如图所示,连接OA、OB、AB,在 ![]() 和
和 ![]() 中计算:
中计算:
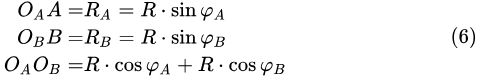
由于 ![]() 与
与 ![]() 是异面直线,
是异面直线, ![]() 是它们的公垂线,所成角度经度差为
是它们的公垂线,所成角度经度差为 ![]() ,利用异面直线上两点距离公式:
,利用异面直线上两点距离公式:
![]()
在 ![]() 中,由余弦定理:
中,由余弦定理:
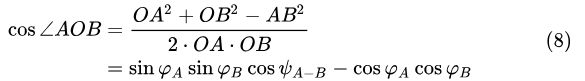
由于此处的 ![]() 代表纬度的补角,对其进行转换:
代表纬度的补角,对其进行转换:
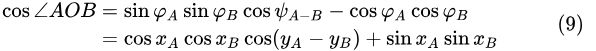
因此,点 ![]() 的球面距离为:
的球面距离为:
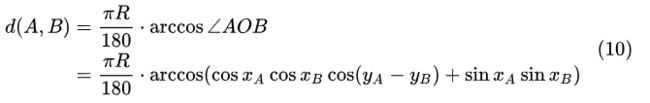
此外还有 Chebyshev(切比雪夫)距离、Minkowski(闵科夫斯基)距离、绝对值距离、Lance & Williams 距离,具体问题具体分析,选择合适的度量方式。
总结:统一使用 ![]() 表示点
表示点 ![]() 和点
和点 ![]() 之间的距离。根据定义,易知交换律成立:
之间的距离。根据定义,易知交换律成立:
![]()
3.2 第 k 距离
定义: ![]() 为点
为点 ![]() 的第
的第 ![]() 距离,
距离, ![]() ,满足如下条件
,满足如下条件
- 在集合中至少存在
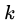 个点
个点 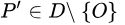 ,使得
,使得 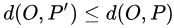
- 在集合中至多存在
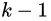 个点
个点 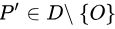 ,使得
,使得 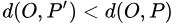
简言之:点 ![]() 是距离
是距离 ![]() 最近的第
最近的第 ![]() 个点:
个点:

点P是离O最近的第5个点,第5距离内部有4个点,第5距离内共有6个点。点O的第5距离与第6距离相等。
3.3 k 距离邻域
定义:设 ![]() 为点
为点 ![]() 的第
的第 ![]() 距离邻域,满足:
距离邻域,满足:
![]()
注:此处的邻域概念与国内高数教材略有不同(具体的点,而非区间)。该集合中包含所有到点![]() 距离小于点
距离小于点 ![]() 第 k 邻域距离的点。易知有
第 k 邻域距离的点。易知有 ![]() ,如上图,点
,如上图,点 ![]() 的第 5 距离邻域为:
的第 5 距离邻域为:
![]()
3.4 可达距离
定义 点 ![]() 到点
到点 ![]() 的第 k 可达距离定义为:
的第 k 可达距离定义为:
![]()
注:即点 ![]() 到点
到点 ![]() 的第 k 可达距离至少是点
的第 k 可达距离至少是点 ![]() 的第 k 距离。距离
的第 k 距离。距离 ![]() 点最近的 k 个点,它们到
点最近的 k 个点,它们到![]() 的可达距离被认为是相当的,且都等于
的可达距离被认为是相当的,且都等于 ![]() 。
。
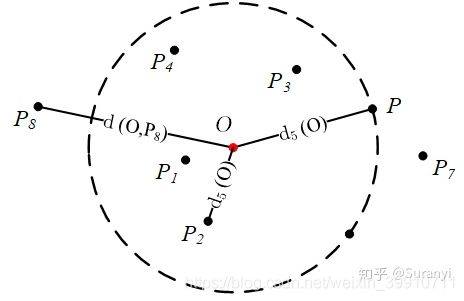
点P到点O的第5可达距离,在计算样本点的可达密度时,此部分总是取d(O)的,即与第k距离有关。若求新样本点在旧样本域内的离群密度,式(14)才会发挥作用。
3.5 局部可达密度
定义:局部可达密度定义为:

注:表示点 ![]() 的第 k 邻域内所有点到
的第 k 邻域内所有点到 ![]() 的平均可达距离,位于第 k 邻域边界上的点即使个数大于1,也仍将该范围内点的个数计为 k 。注意,是O的邻域点 Nk(O) /P到O的第 k 可达距离,不是O到 Nk(O)的第 k可达距离,一定要弄清楚关系。并且,如果有重复点,那么分母的可达距离之和有可能为0,则会导致lrd变为无限大,下面还会继续提到这一点。
的平均可达距离,位于第 k 邻域边界上的点即使个数大于1,也仍将该范围内点的个数计为 k 。注意,是O的邻域点 Nk(O) /P到O的第 k 可达距离,不是O到 Nk(O)的第 k可达距离,一定要弄清楚关系。并且,如果有重复点,那么分母的可达距离之和有可能为0,则会导致lrd变为无限大,下面还会继续提到这一点。
如果 ![]() 和周围邻域点是同一簇,那么可达距离越可能为较小的
和周围邻域点是同一簇,那么可达距离越可能为较小的 ![]() ,导致可达距离之和越小,局部可达密度越大。如果
,导致可达距离之和越小,局部可达密度越大。如果 ![]() 和周围邻域点较远,那么可达距离可能会取较大值
和周围邻域点较远,那么可达距离可能会取较大值 ![]() ,导致可达距离之和越大,局部可达密度越小。
,导致可达距离之和越大,局部可达密度越小。
部分资料这里使用 ![]() 而不是
而不是 ![]() 。笔者查阅大量资料及数据测试后认为,此处应为
。笔者查阅大量资料及数据测试后认为,此处应为 ![]() ,否则
,否则 ![]() 会因为过多点在内部同一圆环上(如式13中的
会因为过多点在内部同一圆环上(如式13中的 ![]() 位于同一圆环上)而导致
位于同一圆环上)而导致 ![]() 是一个偏大的数,提示此处的密度低,可能为离群值。
是一个偏大的数,提示此处的密度低,可能为离群值。
此外,本文 3.1 开头指出“没有样本点重合”在这里也能得到解释:如果考虑重合样本点,可能会造成此处的可达密度为 ![]() 或下文的
或下文的 ![]() 为
为 ![]() 形式,计算上带来困扰。
形式,计算上带来困扰。
注意:若有k个或以上的点跟![]() 重合,即到
重合,即到![]() 的距离是0,则ρ无法计算,要排除这种情况。或者,k-distance都加上一个很小的值,避免ρ无法计算。
的距离是0,则ρ无法计算,要排除这种情况。或者,k-distance都加上一个很小的值,避免ρ无法计算。
3.6 局部离群因子

注 表示点 ![]() 的邻域
的邻域 ![]() 内其他点的局部可达密度与点
内其他点的局部可达密度与点 ![]() 的局部可达密度之比的平均数。如果这个比值越接近1,说明
的局部可达密度之比的平均数。如果这个比值越接近1,说明 ![]() 的邻域点密度差不多,
的邻域点密度差不多, ![]() 可能和邻域同属一簇;如果这个比值小于1,说明
可能和邻域同属一簇;如果这个比值小于1,说明 ![]() 的密度高于其邻域点密度,
的密度高于其邻域点密度, ![]() 为密集点;如果这个比值大于1,说明
为密集点;如果这个比值大于1,说明![]() 的密度小于其邻域点密度,
的密度小于其邻域点密度,![]() 可能是异常点。
可能是异常点。
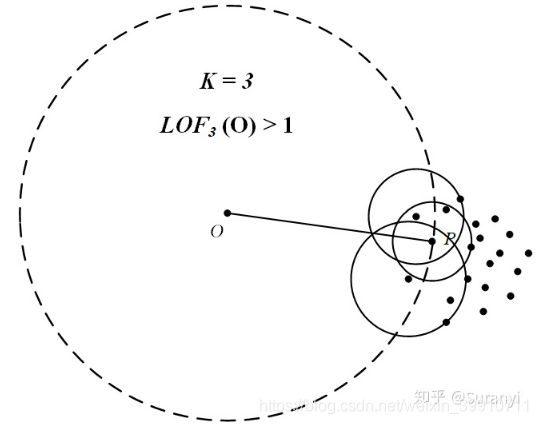
点O的 LOF 值大于1,提示为可能的异常点。
3.7 复杂度
LOF算法要计算样本点两两之间的距离,时间复杂度是O(n^2)。
4 LOF离群因子检测算法python3 实现
import pandas as pd
from sklearn.neighbors import LocalOutlierFactor
def lof(data, predict=None, k=5, method=1, plot=False):
# 判断是否传入测试数据,若没有传入则测试数据赋值为训练数据
try:
if predict == None:
predict = data.copy()
except Exception:
pass
predict = pd.DataFrame(predict)
# 计算 LOF 离群因子
clf = LocalOutlierFactor(n_neighbors=k + 1, algorithm='auto', contamination=0.1, n_jobs=-1)
clf.fit(data)
# 记录 k 邻域距离
predict['k distances'] = clf.kneighbors(predict)[0].max(axis=1)
# 记录 LOF 离群因子,做相反数处理
predict['local outlier factor'] = -clf._decision_function(predict.iloc[:, :-1])
# 根据阈值划分离群点与正常点
outliers = predict[predict['local outlier factor'] > method].sort_values(by='local outlier factor')
inliers = predict[predict['local outlier factor'] <= method].sort_values(by='local outlier factor')
return outliers, inliers
在 python3 中,sklearn 模块提供了 LOF 离群检测算法: sklearn.neighbors.LocalOutlierFactor — scikit-learn 1.1.0 documentation
核心函数:
clf = LocalOutlierFactor(n_neighbors=20, algorithm=’auto’, leaf_size=30, metric=’minkowski’, p=2, metric_params=None, contamination=0.1, n_jobs=1)import numpy as np
from sklearn.neighbors import LocalOutlierFactor
data = np.random.randint(6, 10, (30, 6))
a = data[-1, :]
data = np.row_stack((data, a))
data = np.row_stack((data, a))
clf = LocalOutlierFactor(n_neighbors=5)
predict = clf.fit_predict(data)
negative_outlier_factor = clf.negative_outlier_factor_
print(predict)
(1)主要参数
- n_neighbors :即上文提及的 k ,检测的邻域点个数超过样本数则使用所有的样本进行检测。
- algorithm :{'auto','ball_tree','kd_tree','brute'},默认='auto'。用于计算最近邻居的算法:
-
'ball_tree'将使用 BallTree
-
'kd_tree'将使用 KDTree
-
'brute'将使用暴力搜索。
-
“auto”将尝试根据传递给fit方法的值来决定最合适的算法。
-
- contamination = 0.1:范围为 (0, 0.5),表示样本中的异常点比例,默认为 0.1
- n_jobs = -1:并行任务数,设置为-1表示使用所有CPU进行工作
- p = 2:距离度量函数,默认使用欧式距离。当p = 1时,这等效于使用manhattan_distance(l1),当对p = 2,等效于使用euclidean_distance(l2)。对于任意p,使用minkowski_distance(l_p)。
(2)主要函数
- 无监督学习,只需要传入训练数据data,传入的数据维度至少是 2 维:
clf.fit(data)- 获取第 k 距离邻域内的每一个点到中心点的距离,并按从小到大排序,返回
 数组,[距离,样本索引]:
数组,[距离,样本索引]:
clf.kneighbors(data)- 获取每一个样本点的 LOF 值,该函数范围 LOF 值的相反数,需要取反号。clf._decision_function 的输出方式更为灵活:若使用 clf._predict(data) 函数,则按照原先设置的 contamination 输出判断结果(按比例给出判断结果,异常点返回-1,非异常点返回1):
-clf._decision_function(data)5 LOF优缺点
优点:
LOF 的一个优点是它同时考虑了数据集的局部和全局属性。异常值不是按绝对值确定的,而是相对于它们的邻域点密度确定的。当数据集中存在不同密度的不同集群时,LOF表现良好,比较适用于中等高维的数据集。
缺点:
LOF算法中关于局部可达密度的定义其实暗含了一个假设,即:不存在大于等于 k 个重复的点。
当这样的重复点存在的时候,这些点的平均可达距离为零,局部可达密度就变为无穷大,会给计算带来一些麻烦。在实际应用时,为了避免这样的情况出现,可以把 k-distance 改为 k-distinct-distance,不考虑重复的情况。或者,还可以考虑给可达距离都加一个很小的值,避免可达距离等于零。
另外,LOF 算法需要计算数据点两两之间的距离,造成整个算法时间复杂度为 。为了提高算法效率,后续有算法尝试改进。FastLOF (Goldstein,2012)先将整个数据随机的分成多个子集,然后在每个子集里计算 LOF 值。对于那些 LOF 异常得分小于等于 1 的,从数据集里剔除,剩下的在下一轮寻找更合适的 nearest-neighbor,并更新 LOF 值。
异常检测:局部异常因子LOF算法在python中实现:异常检测:局部异常因子LOF算法在python中实现_大奸猫的博客-CSDN博客_lof算法python
LOF离群因子检测算法及python3实现:LOF离群因子检测算法及python3实现 - 知乎
【机器学习】一文读懂异常检测 LOF 算法(Python代码)_风度78的博客-CSDN博客