MMDetection 快速开始,训练自定义数据集
本文将快速引导使用 MMDetection ,记录了实践中需注意的一些问题。
环境准备
基础环境
- Nvidia 显卡的主机
- Ubuntu 18.04
- 系统安装,可见 制作 USB 启动盘,及系统安装
- Nvidia Driver
- 驱动安装,可见 Ubuntu 初始配置 - Nvidia 驱动
开发环境
下载并安装 Anaconda ,之后于 Terminal 执行:
# 创建 Python 虚拟环境
conda create -n open-mmlab python=3.7 -y
conda activate open-mmlab
# 安装 PyTorch with CUDA
conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.2 -c pytorch -y
# 安装 MMCV
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.6.0/index.html
# 安装 MMDetection
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -r requirements/build.txt
pip install -v -e .
pytorch==1.7.0 时多卡训练会发生问题,需参考此 Issue。命令参考:
conda install pytorch==1.7.0 torchvision==0.8.1 cudatoolkit=10.2 -c pytorch -y
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.7.0/index.html
更多安装方式,可见官方文档:
- MMDetection - Installation
- MMCV - Installation
现有模型进行推断
Faster RCNN
以 R-50-FPN 为例,下载其 model 文件到 mmdetection/checkpoints/。之后,进行推断,
conda activate open-mmlab
cd mmdetection/
python demo/image_demo.py \
demo/demo.jpg \
configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth

现有模型进行测试
准备数据集
下载 COCO 数据集,如下放进 mmdetection/data/coco/ 目录,
mmdetection
├── data
│ ├── coco
│ │ ├── annotations
│ │ ├── train2017
│ │ ├── val2017
│ │ ├── test2017
测试现有模型
cd mmdetection/
# single-gpu testing
python tools/test.py \
configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
--out results.pkl \
--eval bbox \
--show
# multi-gpu testing
bash tools/dist_test.sh \
configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
2 \
--out results.pkl \
--eval bbox
效果如下,
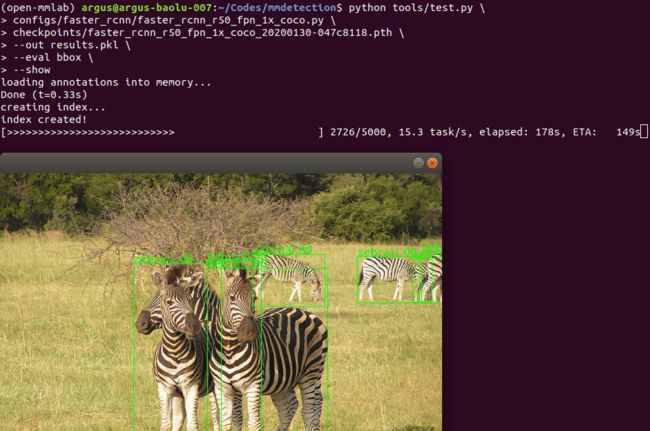
结果如下,
loading annotations into memory...
Done (t=0.33s)
creating index...
index created!
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 5000/5000, 15.3 task/s, elapsed: 328s, ETA: 0s
writing results to results.pkl
Evaluating bbox...
Loading and preparing results...
DONE (t=0.89s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=26.17s).
Accumulating evaluation results...
DONE (t=4.10s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.374
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.581
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.404
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.212
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.410
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.481
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.517
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.517
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.517
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.326
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.557
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.648
OrderedDict([('bbox_mAP', 0.374), ('bbox_mAP_50', 0.581), ('bbox_mAP_75', 0.404), ('bbox_mAP_s', 0.212), ('bbox_mAP_m', 0.41), ('bbox_mAP_l', 0.481), ('bbox_mAP_copypaste', '0.374 0.581 0.404 0.212 0.410 0.481')])
标准数据集训练模型
准备数据集
同前一节的 COCO 数据集。
准备配置文件
配置文件为 configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py。
需要依照自己的 GPU 情况,修改 lr 学习速率参数,说明如下:
lr=0.005for 2 GPUs * 2 imgs/gpulr=0.01for 4 GPUs * 2 imgs/gpulr=0.02for 8 GPUs and 2 img/gpu (batch size = 8*2 = 16), DEFAULTlr=0.08for 16 GPUs * 4 imgs/gpu
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# optimizer
optimizer = dict(type='SGD', lr=0.005, momentum=0.9, weight_decay=0.0001)
训练模型
cd mmdetection/
# single-gpu training
python tools/train.py \
configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
--work-dir _train
# multi-gpu training
bash ./tools/dist_train.sh \
configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
2 \
--work-dir _train
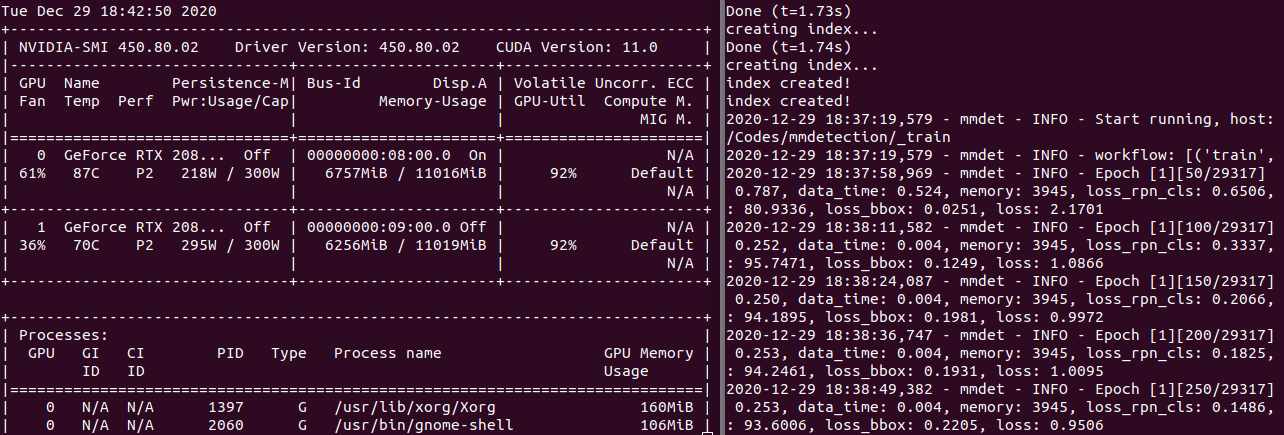
自定义数据集训练模型
自定义数据集
这里从 Pascal VOC 数据集拿出 cat 作为自定义数据集来演示,
conda activate open-mmlab
# Dataset Management Framework (Datumaro)
pip install 'git+https://github.com/openvinotoolkit/datumaro'
# pip install tensorflow
datum convert --input-format voc --input-path ~/datasets/VOC2012 \
--output-format coco --output-dir ~/datasets/coco_voc2012_cat \
--filter '/item[annotation/label="cat"]'
数据集需要是 COCO 格式,以上直接用 datum 从 VOC 拿出 cat 并转为了 COCO 格式。
准备配置文件
添加 configs/voc_cat/faster_rcnn_r50_fpn_1x_voc_cat.py 配置文件,内容如下:
# The new config inherits a base config to highlight the necessary modification
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# We also need to change the num_classes in head to match the dataset's annotation
model = dict(
roi_head=dict(
bbox_head=dict(num_classes=1)))
# Modify dataset related settings
dataset_type = 'COCODataset'
classes = ('cat',)
data_root = '/home/john/datasets/'
data = dict(
train=dict(
img_prefix=data_root + 'VOC2012/JPEGImages/',
classes=classes,
ann_file=data_root + 'coco_voc2012_cat/annotations/instances_train.json'),
val=dict(
img_prefix=data_root + 'VOC2012/JPEGImages/',
classes=classes,
ann_file=data_root + 'coco_voc2012_cat/annotations/instances_val.json'),
test=dict(
img_prefix=data_root + 'VOC2012/JPEGImages/',
classes=classes,
ann_file=data_root + 'coco_voc2012_cat/annotations/instances_val.json'))
evaluation = dict(interval=100)
# Modify schedule related settings
optimizer = dict(type='SGD', lr=0.005, momentum=0.9, weight_decay=0.0001)
total_epochs = 10000
# Modify runtime related settings
checkpoint_config = dict(interval=10)
# We can use the pre-trained model to obtain higher performance
# load_from = 'checkpoints/*.pth'
model配置num_classes=1为类别数量dataset配置为准备的自定义数据集schedule配置训练的lr及迭代轮次total_epochsruntime可配置checkpoint间隔多少存一个。默认 1 epoch 1 个,空间不够用
配置可对照 __base__ 的内容覆盖修改,更多说明见官方文档。
训练模型
# single-gpu training
python tools/train.py \
configs/voc_cat/faster_rcnn_r50_fpn_1x_voc_cat.py \
--work-dir _train_voc_cat
# multi-gpu training
bash ./tools/dist_train.sh \
configs/voc_cat/faster_rcnn_r50_fpn_1x_voc_cat.py \
2 \
--work-dir _train_voc_cat
断点恢复时,
bash ./tools/dist_train.sh \
configs/voc_cat/faster_rcnn_r50_fpn_1x_voc_cat.py \
2 \
--work-dir _train_voc_cat \
--resume-from _train_voc_cat/epoch_100.pth
如发生 ModuleNotFoundError: No module named 'pycocotools' 错误,这样修正:
pip uninstall pycocotools mmpycocotools
pip install mmpycocotools
查看训练 loss
pip install seaborn
python tools/analyze_logs.py plot_curve \
_train_voc_cat/*.log.json \
--keys loss_cls loss_bbox \
--legend loss_cls loss_bbox
可用 keys 见 log.json 记录。
测试模型
# single-gpu testing
python tools/test.py \
configs/voc_cat/faster_rcnn_r50_fpn_1x_voc_cat.py \
_train_voc_cat/latest.pth \
--out results.pkl \
--eval bbox \
--show
# multi-gpu testing
bash tools/dist_test.sh \
configs/voc_cat/faster_rcnn_r50_fpn_1x_voc_cat.py \
_train_voc_cat/latest.pth \
2 \
--out results.pkl \
--eval bbox
GoCoding 个人实践的经验分享,可关注公众号!