用于压缩视频感知增强的多目标网络自适应时空融合
Adaptive Spatial-Temporal Fusion of Multi-Objective Networks for Compressed
Video Perceptual Enhancement
Abstract
由于两个视频对之间仍然不存在合适的感知相似性损失函数,因此严重压缩视频的感知质量增强是一个难以解决的问题。由于很难设计统一的训练目标,这些目标对同时增强具有平滑内容的区域和具有丰富纹理的区域具有感知友好性,在本文中,我们提出了一种简单而有效的新解决方案,称为“两阶段多目标网络的自适应时空融合”(ASTF),用于自适应融合使用两个不同优化目标训练的网络的增强结果。具体来说,该ASTF将增强帧及其相邻帧作为输入,共同预测掩码,以指示具有高频文本细节的区域。然后,我们使用掩模融合两个增强结果,可以保留平滑内容和丰富的纹理。大量实验表明,该方法在压缩视频感知质量增强方面具有良好的性能。
1. Introduction
近年来,我们见证了互联网上视频数据的爆炸式增长。为了以有限的带宽传输视频,视频压缩对于显著降低比特率至关重要。然而,现有的压缩算法通常会引入伪影,这会严重降低体验质量(QoE)[33、9、5、1、20]。因此,对压缩视频质量增强的研究至关重要。
最近,关于压缩视频质量增强的研究非常有限[33、9、5、25]。多帧质量增强(MFQE 1.0)[33]首先利用时间信息进行矢量量化,MFQE 2.0[9]为了进一步提高性能,还采用了时间融合方案,该方案采用密集光流进行运动补偿。时空可变形融合(STDF)[5]聚集时间信息,同时避免显式光流估计。然而,所有这些方法都使用像素级指标,如MSE、PSNR和SSIM,来计算两幅图像之间的相似性,这无法解释人类感知的许多细微差别。MW-GAN[25]提出了一种基于多级小波包变换的生成对抗网络(GAN),用于恢复高频细节,以提高压缩视频的感知质量。
虽然人类几乎可以毫不费力地快速评估两个图像之间的感知相似性,但其基本过程被认为是相当复杂的。lpips[35]被提出用于评估两幅图像之间的感知相似性。然而,仍然不存在适用于VQE的指标。与空间中单个图像的单图像感知质量增强(关注内在属性)相比,视频感知质量增强带来了额外的挑战,因为它涉及时间闪烁,尽管单独考虑图像感知质量,视频序列中的每个增强帧似乎都得到了很好的增强。具体来说,使用峰值信噪比和SSIM训练的VQE将生成平滑的视频,而使用LPIP训练的生成具有更多文本细节的时间闪烁视频。
为了解决上述问题,我们采用具有自适应时空融合模块的多目标网络来同时增强内容平滑的区域和纹理丰富的区域。具体来说,我们使用两阶段策略进行增强。第一阶段旨在获得较高保真度的相对良好的中间结果。在第二阶段,我们训练了两个基本CVSR[3]模型,用于不同的细化目的。一个用于文本细节,另一个用于时间平滑区域。为了消除时间闪烁并保留文本细节,我们设计了一种新的自适应时空融合方案。具体来说,提出了时空掩码生成模块来生成时空掩码,并用于融合两个网络输出。然后我们使用图像锐化来进一步增强视频。
主要贡献如下:
(1) 我们观察到,由于压缩损失,具有平滑内容和丰富纹理的区域被非相同地退化,为了更好地增强这些区域,我们设计了不同的优化目标,采用两分支架构。
(2) 提出了一种自适应时空融合模块,以结合两个网络分支的优点,同时实现时空一致性以避免闪烁
(3) BasicVSR被用作VQE主干,用于概念验证,实验结果验证了我们的解决方案的有效性
2. Related Work
2.1. Quality Enhancement
在过去几年中,人们提出了大量工作来提高压缩图像的客观质量[19、8、14、16、7、10、28、18、34]。具体来说,非深度学习方法使用形状自适应DCT或稀疏编码来减少块效应、振铃效应和JPEG伪影[8、14、16]。深度学习方法,如D3[28]和深度双域卷积网络(DDCN)[10]利用JPEG压缩的先验知识来提高JPEG压缩图像的质量。
对于压缩视频,大多数方法使用单帧质量增强方法来处理视频增强[4、26、32]。受多帧超分辨率的激励,MFQE[33]是第一个利用相邻帧进行压缩视频增强的人。然后提出了MFQE 2.0[9],它是MFQE的扩展版本。这两种MFQE方法都采用了时间融合方案,该方案结合了密集光流进行运动补偿。由于压缩伪影可能会严重扭曲视频内容并破坏帧之间像素方向的对应,因此估计的光流往往不准确和不可靠,从而导致质量增强无效。时空可变形融合(STDF)[5]聚集时间信息,同时避免显式光流估计。所有上述方法都试图最小化像素损失,如MSE、PSNR和SSIM,以获得与人类判断不符的高客观质量。最近,MW-GAN[25]提出了一种基于多级小波包变换的生成对抗网络来恢复高频细节,以提高压缩视频的感知质量。
2.2. Video Super Resolution
最接近我们的工作是视频超分辨率(VSR)。VSR和VQR之间的显著差异是VSR需要最终的上采样层。几种VSR方法[2、23、29]使用光流估计帧之间的运动,并使用空间扭曲进行对齐。其他方法使用更复杂的隐式对齐方法[24、27、15、12、13、3]。具体来说,TDAN[24]和EDVR[27]采用可变形卷积来对齐不同的帧。BasicVSR[3]提出解开VSR的一些最基本组件,如传播、对齐、聚集和上采样,并发现双向传播与简单的基于光流的特征对齐相结合足以优于许多最先进的方法。在这项工作中,我们采用BasicVSR作为我们的基础模型,我们将删除最终的上采样层。
3. Proposed Method
给定一个高度压缩的视频,我们方法的目标是产生高质量的结果,与参考地面真实情况具有最佳的感知质量。具体来说,我们使用两阶段策略进行增强。如图1所示,第一阶段旨在获得相对良好的高保真中间结果。在此阶段,使用Charbonnier损失[17]训练基本CVSR[3]模型。在第二阶段,我们训练了两个基本CVSR模型,用于不同的细化目的。使用折中损失函数Charbonnier损失+lpips损失来训练一个改进的BasicVSR模型(我们称其为EnhanceNet2)。另一个refine BasicVSR模型(称为EnhanceNet1)仅使用lpips损失进行训练。在这里,lpips损耗[35]是一种学习的客观视频质量测量,更符合人类感知。这样,EnhanceNet1更善于恢复纹理以满足人类感知需求,但它可以导致视频平滑区域的时间闪烁,同时EnhanceNet2将产生更平滑的结果,尤其是时间闪烁被很好地消除。为了克服这个问题,我们设计了一种新的自适应时空融合方案。具体来说,提出了时空掩码生成模块来生成时空掩码,并用于融合两个网络输出。然后,我们使用图像锐化来进一步增强高斯核大小为3的视频。
3.1. EnhanceNet
对于阶段1中的粗增强网,我们使用Charbonnier损失[17]生成高保真度的粗结果例如PSNR和SSIM。然而,根据之前的研究[35],传统的指标(L2/PSNR,SSIM)与人类的判断不一致。Charbonnier损耗是l1范数的可微变体:
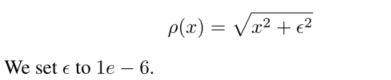
根据我们的观察,很难设计统一的训练目标,这些目标对同时增强内容平滑的区域和纹理丰富的区域具有感知友好性。因此,客观质量和感知质量之间的权衡对于解决这个问题很重要,这类似于感知失真权衡[6]
在第二阶段,我们训练了两个基本的CVSR模型,分别关注感知质量和客观质量与感知质量之间的权衡。具体来说,我们仅使用lpips损失[35]来训练Refine EnhanceNet1,以产生专注于恢复纹理细节的结果,这与人类感知判断一致。但它也可能导致视频平滑区域出现时间闪烁的缺点。为了克服这个问题,我们微调 EnhanceNet2使用trade-off loss函数训练。
![]()
产生结果的重点是恢复平滑的结果,这是客观质量和感知质量之间的权衡。注意,我们设置α=0.15和β=10000,使Charbonnier损耗几乎是lpips损耗的三倍。我们在lpips损耗中使用VGG网络进行训练,在lpips损耗中使用Alex网络进行验证
3.2. ASTF
我们设计了一种新的自适应时空融合方案(ASTF),其动机是Refine EnhanceNet1擅长恢复纹理细节,Refine EnhanceNet2擅长恢复平滑区域,这是我们都需要的两种权衡模型。具体来说,时空掩码生成模块用于生成时空掩码,以表示视频的非平滑区域,并将Refine EnhanceNet2的结果作为输入。我们采用了3×3×3像素的时空块。
它用于融合Refine EnhanceNet1和Refine EnhanceNet2的输出:


直观地说,当区域平滑时,其局部方差较小,否则,其局部方差较大。因此,平滑区域将更依赖于EnhanceNet2的输出,而丰富纹理区域将从EnhanceNet1获得更多恢复的细节。使用时间滑动窗口,也可以很好地消除时间闪烁效应。
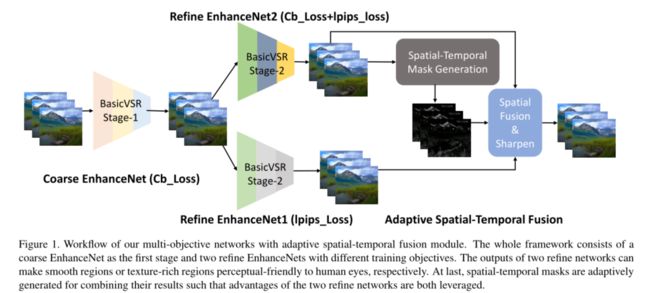
具有自适应时空融合模块的多目标网络的工作流程。整个框架包括一个作为第一阶段的粗增强网和两个具有不同训练目标的细化增强网。两个细化网络的输出分别使平滑区域和纹理丰富区域对人眼具有感知友好性。最后,自适应地生成时空掩码以组合其结果,从而充分利用两个优化网络的优势
4. Experiments
4.1. Datasets
我们使用高压缩视频质量增强挑战(轨迹2固定QP,感知)[30]的训练视频和测试视频进行实验。训练数据总共有200对压缩和未压缩视频。测试数据有10个压缩视频。具体来说,我们将训练视频分为训练数据(190个视频)和验证数据(10个视频,“001”、“021”、“041”、“061”、“081”、“101”、“121”、“141”、“161”、“181)。注意,我们使用官方代码将原始、压缩(和增强)视频转换为RGB域
4.2. Implementation Details
我们使用没有像素洗牌层的BasicVSR作为我们的基本模型。对于这两个阶段的训练,我们从原始视频和相应的压缩视频中随机裁剪64×64个片段作为训练样本。进一步使用数据增强(即旋转或翻转)来更好地利用这些训练样本。学习速率最初设置为2e−4并且在整个培训过程中,学习方案设置为CosineAnnealingLR_Restart。β1=0.9、β2=0.99和 =1e-10的Adam优化器.在第1阶段中,我们从头开始训练EnhanceNet,并伴随着Charbonnier损失[17]。在第二阶段,我们使用第一阶段的结果作为第二阶段的输入。我们分别使用lpips损失[35]和权衡损失函数训练EnhanceNet1和EnhanceNet2。我们采用PSNR、SSIM、lpips[35]和FID[11,21]来评估我们10个验证视频的质量增强性能。
=1e-10的Adam优化器.在第1阶段中,我们从头开始训练EnhanceNet,并伴随着Charbonnier损失[17]。在第二阶段,我们使用第一阶段的结果作为第二阶段的输入。我们分别使用lpips损失[35]和权衡损失函数训练EnhanceNet1和EnhanceNet2。我们采用PSNR、SSIM、lpips[35]和FID[11,21]来评估我们10个验证视频的质量增强性能。
4.3. Quantitative Results
在表1中,我们为每个验证视频提供了PSNR和SSIM。可以看出,第一阶段的结果具有最高的PSNR和SSIM值。EnhanceNet2(cb+lpips)结果的∆PSNR与EnhanceNet(第1阶段)结果相比,为-0.08 dB。EnhanceNet1(lpips)结果的∆PSNR与EnhanceNet(第1阶段)结果相比,为-1.15 dB。在我们的时空融合模块之后,时空融合(fuse)结果的 PSNR与EnhanceNet(第1阶段)结果相比,为-0.14 dB。自适应时空融合(fuse)结果只是EnhanceNet1和EnhanceNet2的 trade-off。我们还提供了图像锐化后结果的PSNR和SSIM,这是最低值。虽然它是我们所有阶段中的最低峰值信噪比,但它具有更好的人类感知能力,我们将在后面讨论。
PSNR与EnhanceNet(第1阶段)结果相比,为-0.14 dB。自适应时空融合(fuse)结果只是EnhanceNet1和EnhanceNet2的 trade-off。我们还提供了图像锐化后结果的PSNR和SSIM,这是最低值。虽然它是我们所有阶段中的最低峰值信噪比,但它具有更好的人类感知能力,我们将在后面讨论。

在表2中,我们为每个验证视频提供了LPIP[35]和FID[11,21]。可以看出,EnhanceNet1(lpips)结果的值最低,使用图像感知度量得到的结果最好。然而,增强网络1(EnhanceNet1,lpips)结果存在时间闪烁问题,这对于视频人类感知判断非常重要。我们使用EnhanceNet2(cb+lpips)来减少时间闪烁,并生成lpips和FID值大于EnhanceNet1(lpips)结果的结果。为了利用时空信息,我们使用我们提出的ASTF融合EnhanceNet1(lpips)结果和EnhanceNet2(cb+lpips)结果,它可以生成值为的结果增强子网络1和增强子网络2(cb+lpips)值之间的lpips和FID。我们还提供了图像锐化后的LPIP和FID结果。与PSNR和SSIM类似,图像锐化后的结果并不优于图像锐化前的结果,但是否具有更好的人类感知能力,我们将在后面讨论。在挑战的测试阶段,我们提出的方法(团队VUE)获得了60分,排名第五。根据15名受试者的平均意见分数(MOS)值对分数进行排序。分数范围从s=0(最差质量)到s=100(最佳质量)。地面实况视频以s=100为标准提供给受试者,但要求受试者根据视觉质量而不是与地面实况的相似性对视频进行评级。更多详情见报告文件[31]。
4.4. Qualitative Results
图2提供了验证和测试框架的定性结果。第一列是压缩帧。第二列是我们的增强帧。前两行是验证帧。最后两行是测试帧。可以看出,压缩后的帧失真、模糊,缺乏文本细节。而我们的增强帧可以减少这些伪影,并具有更多的文本细节。
此外,图3提供了验证帧的每一步结果,包括压缩的低质量输入帧、阶段1的EnhanceNet结果、使用lpips损失训练的EnhanceNet1结果、使用权衡损失函数训练的EnhanceNet2结果、时空融合结果、融合的锐化结果、时空掩码和地面真值。可以看出,第1阶段的增强网可以减少大部分失真,但仍然存在过度模糊问题。EnhanceNet1(lpips)的结果有更多的文本细节,但会导致一些伪影。与EnhanceNet和EnhanceNet1相比,EnhanceNet2(cb+lpips)的结果分别是平滑和文本细节的权衡。使用EnhanceNet2(cb+LPIP)的结果生成的时空掩码表示具有高像素值的高频区域。时空融合(fuse)结果同时具有增强子网络1(lpips)和增强子网络2(cb+lpips)的优点,在低频区域平滑,在高频区域具有更多的文本细节。结果(融合+锐化)通过图像锐化进行处理,以进一步增强人类感知。请注意,结果(fuse)似乎比结果(fuse+锐化)更类似于groundtruth。然而,不考虑地面实况结果(融合+锐化)具有更好的人类感知效果。因此,我们选择结果(融合+锐化)作为最终提交结果,提交给NTIRE 2021高压缩视频质量增强挑战赛的track-2。
4.5. Analysis and Discussions
与定量结果和定性结果相比,PSNR和SSIM值最高的结果并不是最佳的人类感知结果。我们还进行了用户研究,以评估时间性能。用于验证和测试视频,我们的结果(fuse)和结果(fuse+锐化)在减少平滑区域的时间闪烁方面比EnhanceNet1(lpips)的结果有更好的性能。Charbonnier损失[17]有助于生成平滑区域,lpips损失[35]有助于生成文本细节。我们可以看到,仅使用一个损失函数(Charbonnier损失或lpips损失)训练的任何一个模型都无法实现由人类感知判断的良好增强视频。需要同时考虑时间的闪烁和文本细节的缺乏。我们提出的自适应时空融合(ASTF)利用了增强网络1(lpips)和增强网络2(cb+lpips)的优点,具有更好的人类感知视频增强性能。
5. Conclusion
我们在NTIRE 2021重压缩视频质量增强挑战中介绍了我们的轨道2固定QP感知方法。为了应对这一挑战,我们提出了自适应傅立叶变换(ASTF)来自适应融合使用两个不同优化目标训练的网络的增强结果。训练具有不同损失函数的BasicVSR增强模型,分别恢复平滑细节和文本细节。融合操作可以结合两种网络的优点。我们的方法是一种通用方法,可用于任何其他视频增强主干。实验表明,我们的时空融合模块可以同时保留平滑和高频细节,从而获得更好的人类感知效果。