被热捧的云原生,和大数据怎么结合才能驱动商业?

导语 | 近几年炙手可热的云原生首先由Matt Stine提出并延续使用至今,但其并没有标准的、严格的定义,比较公认的四要素是:DevOps、微服务、持续交付、以及容器,更多的则是偏向应用系统的一种体系架构和方法论。那么在云上如何改进大数据基础架构让其符合云原生标准,同时给企业客户带来真真切切的数据分析成本降低和性能保障是一个开放性的话题。本文由腾讯专家工程师、腾讯云EMR技术负责人陈龙在 Techo TVP开发者峰会「数据的冰与火之歌——从在线数据库技术,到海量数据分析技术」 的《云原生环境下大数据基础技术演进》演讲分享整理而成,与大家分享和探讨在云上如何实现存储计算云原生,以及未来下一代云原生大数据基础架构。
点击可观看精彩演讲视频
一、云原生标准和大数据基础技术
今天分享的内容分为四个部分:第一部分是云原生标准和大数据基础技术;第二部分是大数据基础技术如何实现云原生;第三部分是腾讯云大数据云原生解决方案;第四部分是下一代云原生大数据基础技术。
接下来看云原生标准和大数据基础技术,以及什么才是云原生的大数据基础技术。
1. 云原生的核心思想
“云原生”这个词,这几年非常火热,对于这个词,可谓仁者见仁,智者见智。一个产品如果不加上“云原生”,好像就落后于这个时代,那么云原生讲的到底是什么?它所宣扬的核心思想又是什么?我们首先来看定义,云原生首先是由马特·斯泰恩提出并延用至今,比较公认的包含四个要素,第一个是DevOps,第二个是微服务,第三个是持续交付,第四个是容器化。

DevOps实际上就是开发和运维的综合体,不像开发和产品经常兵戎相见,DevOps实际上是敏捷思维,是一种沟通文化,也是一种组织形式,为云原生提供持续交付能力。持续交付是不误时开发,不停机更新,小步快跑,反传统瀑布模型开发,这就要求开发版本和稳定版本并存,持续交付需要很多工具或者流程来支持。
再来看微服务,几乎所有的云原生都包含微服务这个定义。跟微服务相对应的是单体应用,微服务有理论基础——康威定律,指导如何拆这个服务。但是凡是能称为定律的东西,文字看起来都很简单,能够真正掌握其精髓或者对其理解透彻是非常困难的,有时候微服务拆不好的话,反而是一种灾难。一个微服务到底拆得好不好,实际上受限于架构师对于这个业务场景的理解和宏观抽象的能力。
而容器化是指采用开源技术栈,一般是指K8S和Docker进行容器化,基于微服务架构来提高整个系统的灵活性和扩展性,借助敏捷方法、DevOps支持持续迭代,基于云基础设施实现弹性伸缩、动态调度、优化整个资源利用率。
因此把这四个因素加以宏观归纳,其实云原生讲的就是两个词:成本和效率,即在开发整个软件的时候实现工业化生产。
2. 大数据的云原生定义
结合刚才的讨论,云原生讲的内容就是让源码在变成一个产品的过程中要充分利用云计算软件交付模型,来构建和运行应用程序,从而实现整个软件生产的工业化,进而实现降本增效。
按照这个原理怎么推导出大数据的云原生?“大数据”也是目前比较火热的一个词,我个人理解大数据其实是对超大规模数据集的分析处理技术。对于大数据,比较官方的定义有两种:第一种,麦肯锡认为:指数据的规模超过了常规的数据库工具获取、管理、存储和分析的数据集合,但是同时也强调并不是超过特定规模的数据才算是大数据。第二种,国际IDC数据公司则认为大数据有四个特征:数据规模大;数据流转快;类型多;价值密度低。
可以看到无论哪种定义,大数据的基本特征就是规模非常大,常规的管理手段很难处理它,这就意味着要更为复杂的分布式系统、并行计算等才能解决,复杂也意味着成本上升和效率下降。
因此,结合刚才的分析,我觉得大数据云原生就是要充分利用云基础设施来解决超大规模数据集的获取、管理、存储和分析问题,并在这个过程中实现成本降低和效率提升,从而实现数据驱动商业。

3. 如何实现大数据云原生
在明确大数据基础云原生目标之后,我们来看要通过什么手段或措施来实现大数据云原生。
数据驱动企业的商业发展,数据作为企业最重要的资产之一,由企业的系统产生,而企业的系统多种多样,比如CRM系统、IOT设备、OA系统、HR系统等,这些系统产生的数据在宏观上又可以分为结构化和非结构化数据,这些数据经过分析和转换之后变成企业运行的各类指标,企业决策者就根据这些指标来调整整个企业的经营方向。结合刚才的分析,要在这个过程中实现云原生处理这些问题,我们需要的一些规则和措施是什么?我觉得有四点:
第一是工业化交付,什么叫工业化交付?就是在现阶段很难完成单一系统处理掉所有的数据问题,那么需要一个生态级的系统去处理数据问题,交付工业化是指当我需要某一个系统的时候可以分钟级去创建这些系统,并提供管控和运维能力。
第二是成本量化,成本量化分为两个维度,一是存储成本量化,二是计算成本量化。是指处理数据的系统所使用的存储资源或者是计算资源能够有量化的能力。
第三是负载自适应,是指分析处理这些数据的系统所使用的资源规模应该随着数据规模的变化而变化。
第四是面向数据,对于企业来讲,数据是企业最重要的资产之一,而不是处理数据的这些系统或者技术本身。假设我是一个做物流公司的,我买一架飞机是让整个物流效率提升,而不是这个飞机的制造技术,所以面向数据应该是充分利用云平台基础能力,去解决数据分析问题,让企业更加聚焦于发现数据之间的关系、挖掘数据的价值,进而更好地实现数据驱动。

基于这些准则和措施,我们再结合一些落地的技术,看看如何实现大数据云原生。
在现阶段所有的大数据基础分析都是围绕Hadoop生态技术构建,我们以数据流来看这个问题。系统产生的日志数据或者ERP产生的数据又或者IOT等其它产生的数据,一般会进入消息管道,之后按照场景可能分为流场景或者批场景,分别有流处理引擎和批处理引擎,处理完成之后进入数据服务层,进入后,数据消费终端再通过OLAP引擎或者其它数据服务存储组件来消费这些数据。要实现大数据云原生来处理这些问题,即在整个处理系统上对于每一个子模块或者系统实现工业化交付,在整个生态处理链路上的每一个子模块或者系统,它所使用的存储资源或者是计算资源能够做到成本量化。它占用的资源应该随着整个数据处理的负载变化而变化,通过这一系列的手段来实现面向数据,接下来我们看每一个准则如何详细实现。
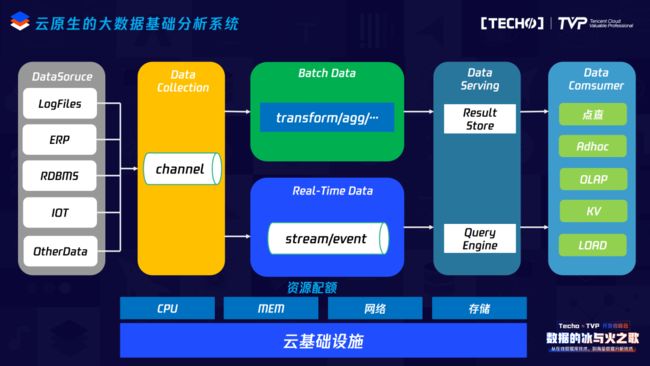
二、大数据基础系统云原生实现
在现阶段,其实Hadoop生态的技术栈已经成为大数据基础处理的事实标准,要实现云原生处理大数据基础问题,也就是要结合云基础设施和Hadoop生态技术栈实现工业化交付、成本量化、负载自适应和面向数据,基于Hadoop生态实现工业化交付不仅仅是指集群的创建,应该还包括管控、运维、数据API等。在常规情况下可能不会频繁地创建集群,但是数据在云上的时候,我的数据可能在云存储,在需要的时候分钟级拉起一个集群去计算,计算完成后去释放这个集群,这时工业化交付就变得相当重要,即使你是一个常驻集群,对日常集群的管控和运维也是工业化交付的一部分,那么成本量化是指整个Hadoop集群所使用的存储资源或者计算资源在云上能够有透视的能力。第三个是负载自适应,是指整个Hadoop生态系统组件所使用的IaaS层规模应该随着处理数据量的变化而变化,尽量减少人工干预。
通过综上三条措施,最后让企业看见的是数据流动,而非系统本身,最终实现面向数据。

接下来我们看一下交付工业化如何实现。交付工业化就是要充分利用云基础设施一键化构建云上的数据分析系统,并同时提供管控、任务、查询或者管理的一些API能力,通过这些API能力大幅降低使用整个大数据分析的技术成本和运维成本,在现阶段数据处理需要一个生态级的解决方案,可以根据数据规模或者业务场景选择一键化构建云上通过Hadoop服务、流计算服务、实时数仓服务或者数据湖服务,基于不同的解决方案,可以通过API来提交任务。举个例子,通过API来提交一个Spark任务,在Spark完成计算之后,我直接释放这个集群,或者是通过API直接提交,或者通过我们的数据湖服务,按照扫描的数据量进行付费。通过这种工业化交付能力可以大幅降低整个大数据分析的资源成本。

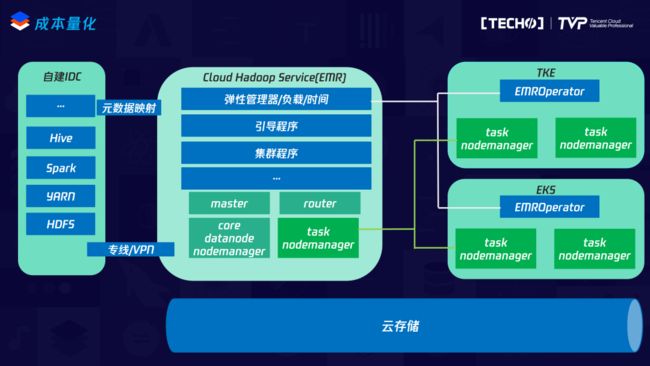
要实现大数据分析成本量化,就必须基于现有的Hadoop架构进行改进,对于一个常规的Hadoop集群而言,它的拓扑结构分为分布式协调节点,主要部署zookeeper、journalNode这种进程,主节点主要部署Namenode、ResourceManager,计算节点主要部署DataNode、Nodemanager进程,但是现实情况是计算资源和存储资源并不对等,有时候计算是瓶颈,有时候存储是瓶颈,特别是在基于云存储的情况下。这时候只需要保留较少的存储节点用于存储、计算的中间临时结果以及日志等,基于成本量化准则,我们把一个Hadoop集群的拓扑进行了改进,分为Master、router、core和task,Master是类比之前传统模式下的Master节点,主要部署Namenode、ResourceManager。Router节点可以用来部署一些无状态的服务,比如HiveServer2这种类型的进程,同时还可以利用云上的基础设施来简化整个大数据分析领域里的高可用问题。举个例子:presto的coordinator问题,可以将presto的coordinator部署在router上,通过云的负载均衡来实现容灾,在故障的时候自动切换。Core节点类似于传统模式下的计算节点,里面部署DataNode、Nodemanager,在云上的时候可以只用选取很少的core节点。Task节点是弹性节点,它里面只会部署计算进程,基于这种架构可以实现四类大数据基础分析服务。
第一种是传统模式,传统模式下可以完全保留IDC整个集群下的架构,整个集群不存在弹性节点,通过云上EMR提供的引导程序和集群程序,可以大幅降低使用整个Hadoop集群的运维问题,同时云上EMR还针对云存储做了大量内核层面的优化,在整个集群存储量不够的时候快速转移数据到云存储,同时基于云上海量的计算资源可以快速扩容集群。
第二种模式是计算存储分离模式,在这种模式下整个数据在云存储,需要计算的时候,可以分钟级拉起一个上千节点的集群进行计算,算完之后释放掉集群,或者说维持集群在较小的规模,需要的时候分钟级扩容到较大的规模。
第三种是混合云方案,在IDC集群还没有迁移到云上的时候,可以通过VPN或者专线将IDC环境和云环境打通,打通后在云上构建EMR集群,通过EMR集群识别IDC集群文件系统和元数据方式,快速扩展IDC自建集群的算力,在计算完成之后释放云上EMR集群。
第四种方式是混合计算,现在容器集群TKE或者STKE这种集群里部署的主要是以业务系统为主,这类系统有一个特点,它白天的时候负载很高,夜晚的时候负载很低,我的EMR有这种能力,在容器集群负载很低的时候可以快速把容器集群的资源加入到EMR集群。
通过这四种计算方式灵活的使用云上存储资源和计算资源,从而大幅降低大数据分析的硬件成本,腾讯云也提供了这种能力。
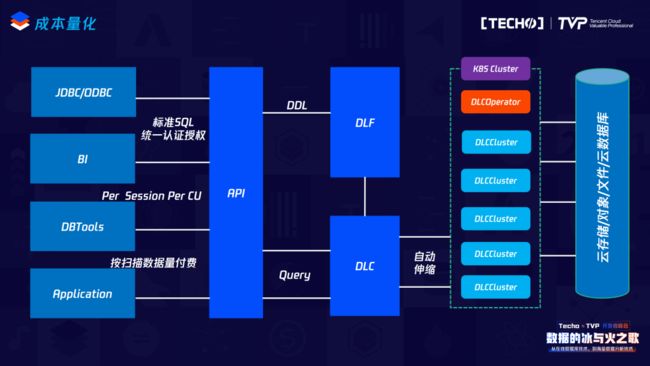
这就是我们的数据湖解决方案,我们实现了按照扫描数据量进行付费的计算优化,分析系统比如BI或者一些可视化的数据管理工具以及应用程序,它可以通过JDBC或者ODBC的方式连接到我们的服务。在服务层我们提供统一的认证和授权,同时在查询的时候可以设置每一个SQL所使用的资源情况,在这个解决方案中DLF管理云上所有的元数据,同时它还负责数据的入库服务,提交的SQL会交由DLC去执行,可以根据DLC数据的资源账单来进行付费。
再看负载自适应,基于Hadoop集群如何实现负载自适应。右侧上面这张图是某集群真实的负载图,常规情况下,集群规模的大小应该是时间线×峰值的矩形面积,利用云上海量的计算资源实现负载自适应,让整个集群规模的大小随着负载的变化而变化。目前EMR支持两种形式的伸缩,第一个是按照负载伸缩,第二个是按照时间伸缩,按照负载伸缩的模式,可以根据资源调度组件YARN上vocre和vmem阻塞情况实现自动扩容或者缩容;按照时间段的模式,让实际使用者可以根据自己的业务情况,在高峰时段扩容,在低峰时段缩容。

我们在实现负载自适应的时候,还要保证整个业务的SLA,也就是在缩容的时候要做到对业务无感知,要控制应用失败率。假设有一个流式场景,一旦AM节点分配在了弹性节点,那么在缩容这个弹性节点的时候一定会导致流式任务的失败。同理,对于YARN里失败次数超过2次的Container,下一次分配在弹性节点上时,如果再下线这个弹性节点,同样会导致这个应用的失败,所以我们做负载自适应的时候在内核层面做了大量的优化,来规避这种情况。了解成本量化、负载自适应之后,我们接下来看如何实现面向数据。
我以一个数据1转换到数据2来说明面向数据的问题。在数据处理领域我们可以将问题抽象为如何高效地将一个数据集有效转化为另外一个数据集,随着这个数据规模越来越大,使用的工具或者技术也会越来越复杂,在GB的时候我们可能需要数据库或者一些其他单机系统就可以完成,在TB的时候可能需要MPP或者并行计算才能完成,当上升到PB的时候可能需要分布式存储以及分布式计算才能完成,随着系统越来越复杂,数据问题就慢慢演变成技术问题、资源问题和运维问题。还是举刚才那个例子,假设我做物流,当我的物流就在一个区域内的时候,我可能需要一个三轮车就可以解决问题,当我的业务发展到跨城域的时候,可能需要汽车,发展到跨省或者跨国际的时候,我可能需要飞机或者火车,但是在数据处理领域现实情况是很多企业为了解决这些数据问题,不得不去解决处理这些数据问题的火车和飞机,从而偏离了数据作为企业最重要资产之一的目标。整个社会生产力进化的方向一定是分工更加细化,因此我理解的面向数据是要充分利用云基础设施去解决数据分析问题,那么我们接下来看面向数据如何落地。

还是以实际的数据处理流为例,比如应用系统输出数据到数据库或是日志,这些数据库或者日志里面的数据经过数据同步工具会进入到云存储或者消息管道。增量的数据,比如CDC里面的数据,它会进入消息管道或者进入流批处理引擎,处理完成之后,会进入实时数仓或者云存储。在这张图里每一根线是处理这个数据自动化的生产线,每一个节点相当于是处理这个数据的引擎,对于企业和开发者来说,云上提供的每一个引擎之间无缝对接,对于企业来讲只需要关注整个数据流动本身即可,而不需要去关注数据处理技术本身。在解决了面向数据的同时,还必须要保证整个大数据分析的高性能,我们接下来看腾讯云大数据分析基础性能这一层是如何保障的。

为了保障云上大数据处理的性能,腾讯云大数据提供从基础设施硬件层到组件内核以及到架构的多方面优化,如果你选择的是传统模式来构建大数据应用,云主机提供了多种多样的硬件供选择。举个例子,比如一个NoSQL HBase应用,对RT要求在毫秒以内,那么你可以使用IT系列的集群来构建集群。在这里我重点介绍计算存储分离场景下的性能保证,在传统模式下,计算进程和存储进程是部署在一起的,特别是在离线计算的场景下,为什么要这么做?原因是计算程序的体积远远小于数据的体积,所以现在主流的像YARN这种调度器在调度的时候都会充分考虑数据的亲和性,它在做计算任务切片和调度的时候会考虑整个计算任务的数据分布情况,并把这些计算任务调度到数据所在的节点,在这些节点上构建计算程序并执行,以获得良好的性能;但是在计算存储分离这种场景下,情况刚好反过来,整个数据在云存储,数据量特别大的时候会有一定的性能损耗,因此我们引入了CacheService,同时改造了内核,做到对计算引擎透明,上层整个应用无需感知到CacheService的存在,同时我们可以根据数据的元数据信息,比如表或者分区的访问信息,智能地从云存储里加载数据到CacheService里,以提升性能。接下来我们看腾讯云大数据云原生解决方案。

三、腾讯云大数据基础云原生解决方案
腾讯云大数据在大数据处理基础的各个环节,都提供了完善的产品能力支持。在存量数据导入方面,可以直接通过对象存储提供的工具,让数据导入到对象存储,增量数据的处理可以通过流计算的CDC能力,也可以直接写入kafka,或者通过EMR集群里面的sqoop或者Spark导入到集群。数据进入云上后,按照流批两种场景,在批处理场景我们提供了EMR或者DLC进行处理,流处理场景则提供了全托管的服务Oceanus。同时在数据服务层,我们提供了搜索解决方案ES、实时数仓GP和ClickHouse,EMR也提供了基于Hadoop全生态的服务层组件,可以满足数据服务层的一些需求,同时这些产品提供了完善的监控、API、决策权限以及SDK,可以大幅简化大数据分析的代价,以此完成大数据领域里面常见的点查、adhoc、olap或者Nosql等应用。

在大数据处理领域,计算引擎主要分批流两种,批以Spark为主,流以Flink为主,目前也有融合的趋势,各有各的生态,谁能胜出还不一定。而为了解决复杂的数据服务层问题,目前也出现了delta相关的数据湖技术以及一些闭源的项目来尝试统一数据服务层。接下来是我对数据服务层的一些思考。
无论数据服务层怎么变,商业上必须要实现以最低成本和高性能完成数据分析。举个例子,现阶段在以Hive来构建数仓的情况下,更新某个分区表下面一小部分数据的时候,要进行大量的无效计算,进而浪费大量的IO和CPU资源,导致成本居高不下。现在Hadoop生态领域没有一个组件能够解决掉所有的数据问题,随着场景越来越复杂,引入的组件会越来越多,这会导致数据大量冗余,进而造成成本升高。同时对于一个分布式系统而言,数据结构、算法和数据分区是保证高性能的前提,但现在每个计算引擎都有上百个参数,而且还不包含JVM或者是操作系统内核本身的参数。把这些参数暴露给开发者或是使用者,对于使用者来说是相当迷茫的。从另外一个层面来说,对于一个单节点的性能,其实是机器硬件能力的衍生,在现阶段情况下你写的代码是否能够真正把这个机器合理的硬件发挥到极致,要打一个很大的问号,因此我觉得下一代大数据基础处理引擎有可能是这样的:

受限于硬件体系结构限制,现在单核CPU的频率已经到上限,针对单机扩展它的性能,一定是numa架构的多CPU模式,而在这种模式下,代码执行只要跨了numanode,性能就会出现成倍的抖动。在分布式场景下,数据跨节点之间的Shuffle是不可避免的,现在Linux内核对大量的数据包进行封包和解包,也会浪费大量宝贵的CPU资源,同时在编程模型上很难有编程框架能够做到对单个函数调用扩大资源限制,即使是cgroup也只能做到进程或者线程级,同样对于io也很难做到针对每个io设置quote。特别是在存储层面,可能需要根据存储数据的重要程度以及成本,提供不同的存储成本。在数据组织层,需要提供统一的DataFormat,但是现在Hadoop生态里有各种各样的数据格式。因此我觉得下一代计算引擎有可能是这样:首先在接入层,基于SQL提供统一的认证,同时还可以基于SQL设置这个SQL执行的资源组。在计算调度层,根据SQL设置的资源组精确控制每个算子的资源开销,以及每个算子的IO基本单位,这个算子在底层实际执行的时候,通过编程框架来保证每次函数执行都不会出现跨Node的情况,同时在继续做shuffle的时候可以通过RDMA或者DPDK技术来进一步提升性能,从而简化整个数据服务层架构并获得良好的性能。
讲师简介

陈龙
腾讯云专家工程师
腾讯云EMR技术负责人,专家工程师,2011年加入腾讯,先后主导开发了腾讯云Redis,负责腾讯云云数据库HBase以及EMR等多款云产品的技术工作,Apache Hbase Contributor,向Apache Hive等多个开源项目贡献过代码,目前专注于腾讯云EMR技术建设工作。
点击观看峰会的精彩总结视频????
关注云加社区,回复关键词:“数据”,
可获取峰会当天全程回顾视频链接
