CS231n 笔记- 对抗模型和对抗训练
目录
对抗样本案例
对抗干扰是系统性问题
对抗干扰是欠拟合
构造对抗样本
对抗样本的迁移率
现实中的应用
防御
对抗训练
Virtual Adversarial Training
总结
对抗样本案例

大熊猫的图像加上微小的扰动,人眼看不出来区别,但是模型把最右边的图片分类成长臂猿,而且置信度还比他之前把图片分类成大熊猫的置信度还高
对抗干扰是系统性问题
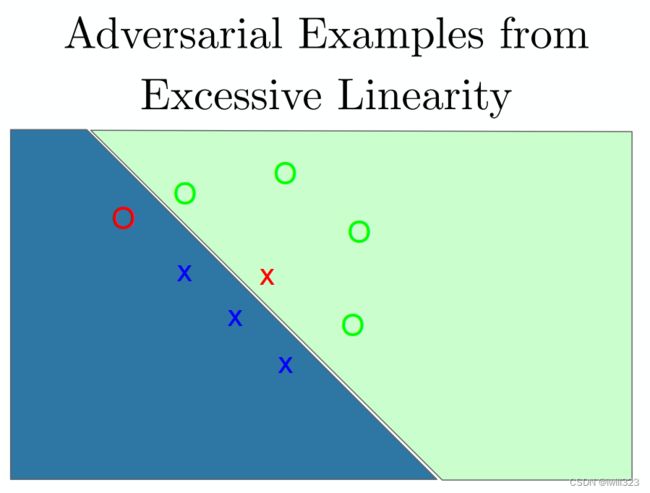
扰动导致模型分类出错有点类似于过拟合问题:模型能够很好地适应训练集,但是对测试集是未知的,所以可能随机犯错。如下图,O和X符号代表样本,区域代表模型得出的分类区域(由于过拟合,所以区域形状很别扭)。最左和最右的X和O是对抗样本,模型判断失误了,所以标红。如果真的是过拟合导致的分类失误,那么重新拟合一次模型或者拟合一个不一样的模型,我们会期望在测试集上的点随机地犯错误。但结果是,不同的模型容易在同一个对抗样本上犯错,并且会指定同样的类给他们。将原始样本和对抗样本的区别(输入空间上的offset向量)与clean example相加,几乎总能得到一个对抗样本.

对抗干扰源于线性
对抗干扰更像是欠拟合,而不是过拟合。比如下图中模型是线性的,决策边界本应该是C形的,没有拟合出来。对于决策边界很远的区域,模型对分类结果有很高的置信度,但分类结果就是错的。这和上面大熊猫的例子挺类似。
根据Ian Goodfellow,神经网络主要是基于线性块构建的,从输出到输出的映射是(分段)线性的,从参数到输出的映射是非线性的。这些线性函数很容易优化,不幸的是,如果一个线性函数具有许多输入,那么它的值可以非常迅速地改变。如果我们用 ϵ 改变每个输入,那么权重为w 的线性函数可以改变 ϵ ∥w∥1 之多,如果 w 是高维的这会是一个非常大的数。
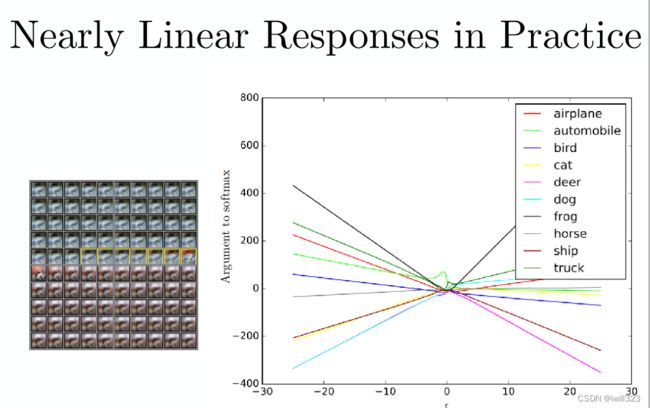
他的意思是深度学习在对抗样本上的表现类似于下图的规律:对抗样本的产生是因为,模型线性程度过高(far too linear)。换句话说,线性模型容易受到攻击
用eplison对输入进行加减,可以看到输出结果近似线性
构造对抗样本
要注意,扰动不能真的改变样本的分类,比如下面的第一行和第三行。对抗样本不是噪声

于是,在构造对抗样本时,用最大范数来限制扰动,即没有一个像素的改变能够超过epsilon。也就是说,L2范数可以很大,但是不能集中于某个部分,这样会改变分类结果,就像上图的第一行第三行。
利用线性假设构造攻击:对网络进行线性近似,对损失函数进行一阶Taylor近似展开,根据Taylor展开,在最大范数限制下,最大化损失函数,该方法叫FGSM(Fast Gradient Sign Method)。要想让J变大,让x~-x和梯度同号就行了,所以取梯度的符号,乘以eplison再加上x。还有其他更厉害的方法。

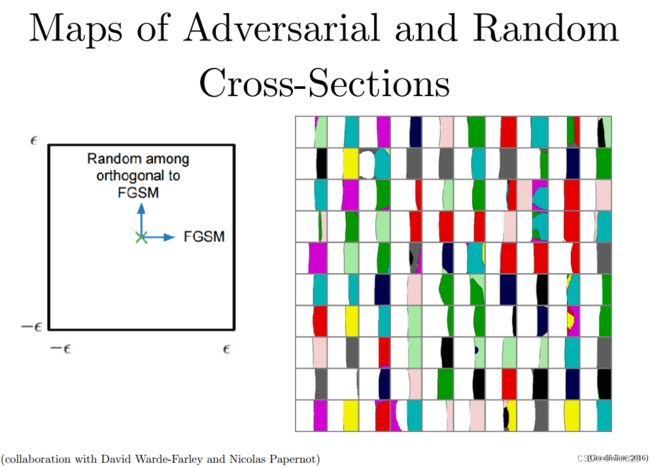
下图展现了在 CIFAR10上的决策边界。左图中X表示clean样本,往右是FGSM法对数据的攻击方向,往上是其随机的正交方向,右图中,每一个单元格中白色表示分类是正确的,其他不同颜色表示错误分类。每个单元格中决策边界近似线性,说明了对抗样本存在于线性空间,当穿过边界进入对抗空间内后(沿着和梯度方向能形成很大内积的方向),便得到了对抗样本,
对抗样本的迁移率
训练模型的时候,我们希望模型泛化能力强,不同的模型(我的理解是模型参数不一样)在不同数据上训练,得到的权重几乎一样(如下图),所以对一个模型有用的对抗样本,对另一个模型也有用

可以计算模型之间的迁移率,数字越高说明对抗样本有越高的几率从一种模型应用到另一种模型

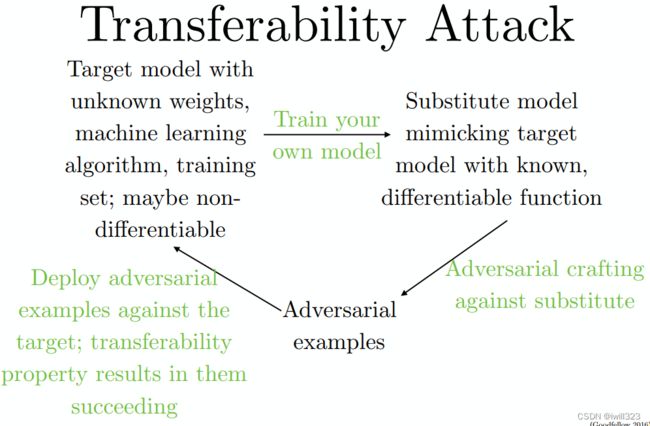
攻击者可能不知道一个模型的结构、算法、参数等,可以训练自己的模型,构造对抗样本。一种方法是在自己的训练集上针对想要攻击的任务上标签,另一种是没有自己的训练集,但有限制地访问模型,可以将观察模型的输入输出,作为自己的训练集。自己模型的对抗样本有可能迁移并影响到模板模型
现实中的应用
对抗样本可以用来攻击AI软件或网络(比如识别恶意信息的网络)。有的机器学习系统通过摄像头感知信息,可以把对抗样本打印下来,能够欺骗这样的系统,甚至用来生产样本的模型和被欺骗的ML系统不一样也可以奏效

防御
没有好的防御方法。以下都失效

对抗训练adversarial training
深度神经网络在对抗样本上训练:对于训练集上的每个输入,给他加上一个攻击,然后映射到和原始输入相同的标签。有一些效果。对抗训练非常吃数据,每次更新权重时呀构造新的对抗样本。
对抗训练的一个意义在于,减少原有独立同分布的测试集的错误率。可以视为一种正则化的手段
下图中淡绿色的线使用FGSM法的对抗样本训练,得跑很长时间训练,并且在同样的对抗样本上测试,优化算法很难从一个到另一个泛化。蓝色的线比红色更低,因为在对抗样本上训练是一个很好的正则化措施,抑制红线的过拟合

其他模型还不如深度神经网络,不会通过对抗训练收到很好的效果。线性模型怎么变都是线性的,注定失败

Virtual Adversarial Training
可以在有标签的数据集上训练

对抗样本也提供了一种实现半监督学习的方法,在没有标签的数据集上训练。在点 x 处,模型为其分配标签y^。模型的标记 y^ 未必是真正的标签,但如果模型是高品质的,那么 y^ 提供正确标签的可能性很大。可以搜索一个对抗样本 x′,导致分类器输出一个标签 y′ 且 y′ ̸= ^ y。不使用真正的标签,而是由训练好的模型提供标签产生的对抗样本被称为虚拟对抗样本。可以训练分类器为 x 和 x′ 分配相同的标签,鼓励分类器学习一个沿着未标签数据所在流形上任意微小变化都很鲁棒的函数。驱动这种方法的假设是,不同的类通常位于分离的流形上,并且小扰动不会使数据点从一个类的流形跳到另一个类的流形上

可以用在文本分类上,降低识别错误率

总结
• Attacking is easy
• Defending is difficult
• Adversarial training provides regularization and semi-supervised learning