MySQL主从搭建和性能优化(一)——MySQL主从搭建、MySQL性能优化(统计总记录数问题、原理分析、索引的分类、最左匹配原则、索引独立原则)、MySQL 查询执行流程
MySQL主从搭建和性能优化(一)——MySQL主从搭建、MySQL性能优化(统计总记录数问题、原理分析、索引的分类、最左匹配原则、索引独立原则)、MySQL 查询执行流程
一、MySQL主从搭建
1、引言和介绍
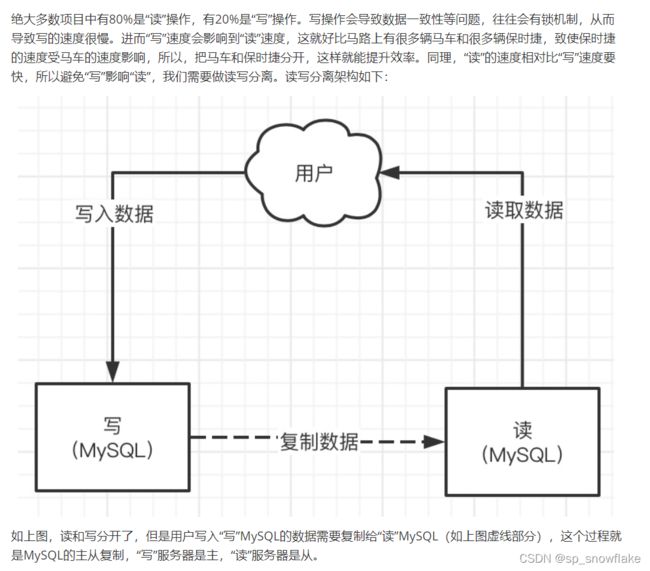
主从架构简略图:
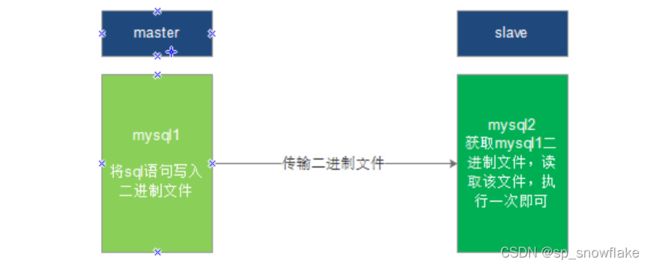
2、开始主从搭建
a、创建并启动 mysql 容器
下面命令创建并启动 mysql 容器:
docker run --name 容器名称 -e MYSQL_ROOT_PASSWORD=数据库密码 -d -p 映射端口:3306 mysql:数据库版本 --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci
接着就是通过上面的命令开启两个 mysql,接着授权给从机服务器:
然后进到 mysql 里面(也可以直接在 mysql 里面执行): docker exec -it 容器名 /bin/bash
接着就是登录 mysql:mysql -u用户名 -p密码
b、设置主从
接着在主机那里执行:GRANT REPLICATION SLAVE ON *.* TO root1@’%’ IDENTIFIED BY ‘root’;
上面的命令解释下:
*. * :因为这里权限分的比较细,所以这个意思是:用户能够操作哪个库里面的哪张表。这里 * . * 就是任何库的任何表。
root1:这个是主机名字,可以随意取。
%:不限制任何 url,从哪里都能登录。如果限制了 ip,那么即便用户名密码输入正确,也不能登录。
但是不会立马生效,要么重启 mysql,要么刷新:flush privileges
c、开启主从配置文件
输入命令:show variables like '%log_bin%';
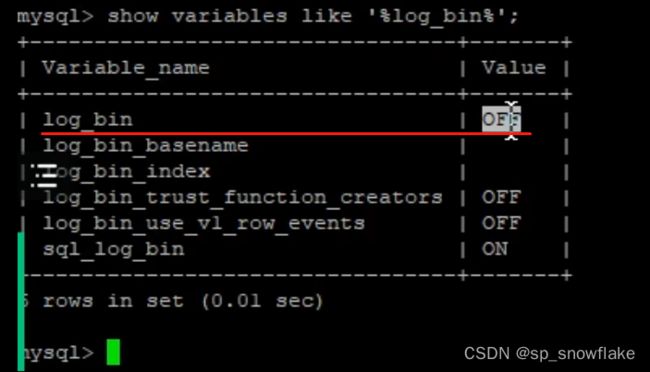
这里处于关闭状态,意味着任何操作都不会记录下来,所以要去开启;先进到这个目录里面:
这里面有个 mysqld . cnf。
![]()
接着这里有个 mysql . cnf

mysql 配置文件里面有两个类,分别是 mysql 和 mysqld。mysql 是配客户端的, mysqld 是配服务端的。像我们能够在控制台输入 mysql 有反应的就是客户端;这只是链接 mysql 的一个工具而已。
当然了,配置文件的位置也有可能是: /etc/mysql/my.cnf ,这个要看自己的系统和 MySQL 版本。
因为博主操作这部分的时候用的是 docker 操作的,没有 vi 这些工具,所以把里面的内容复制好以后,在外面新建文件,并粘贴到里面去,再拷贝到 docker 容器中:
先配置文件:
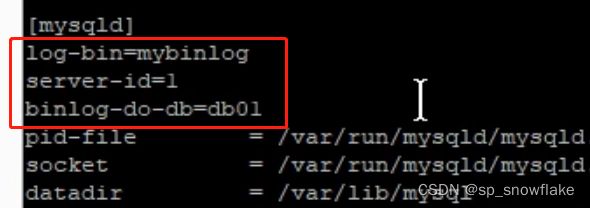
解释上面新增三行:
1、日志文件。路径可写可不写;如果不写,则会出现在配置文件相同目录下面。
2、给服务取个 id:因为在集群里面,每一个 mysql 都要有。都不一样即可。
3、配置需要同步的库:master 上面有很多的库,但并不是所有的库都需要同步到从机上面去。
然后保存退出。
接着拷贝到 docker 里面的 mysql 里面去:
docker cp ./mysqld.cnf mysql容器名:/etc/mysql/mysql.conf.d/
然后重启这个 mysql:
docker restart mysql容器名
接着进到容器里面去,登录mysql,然后查看 master 目前状态:

如果这里的日志文件写满了,会自己换一个日志文件接着写。如果没满,重启了一样会换一个新的文件来写。
到这只要能看到这些东西,就说明主机已经配好了。
d、配置从机
还是修改配置文件,就在刚刚主机那个位置,修改:

从机只要这个即可。
同样的拷贝进从机里面。然后重启。进到容器里面。
如果从机输入下面的命令,会什么都没有:

然后在从机这里输入下面命令,配置 (切记这里配置的时候,要再去主机确认下日志文件名和偏移量) :
change master to master_host='主机ip',master_port=主机端口,master_user='主机名',master_password='主机密码' ,master_log_file='主机日志文件', master_log_pos=主机日志文件偏移量;
然后输入启动从机命令:
start slave;
接着查看:

然后效果:
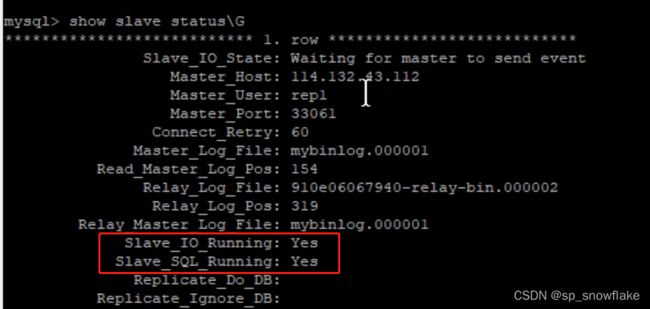
上图中红色框框那两个是最重要的,都为 yes 才是配置成功;否则就是主从搭建失败。如果有问题,去看下面的出错提示。
测试:
在主机中执行新建数据库(前面指定的数据库名)数据表操作,从机刷新就可以发现也跟着有,主机新建数据更改数据,从机都能同步。
注意:如果给从机对应的数据库进行一些更改操作,导致与主机的数据不一样,会立马就出错,这时可以去查看是否还是两个 yes,一般这个时候就不是了;这时就失去了主从同步了。需要重新配置!
二、MySQL 性能优化
1、统计总记录数问题
先来看下统计总记录数问题。先来个提问:以下三种 sql 语句,哪个快哪个慢?它们之间的区别以及应该使用哪一个效率更高呢?
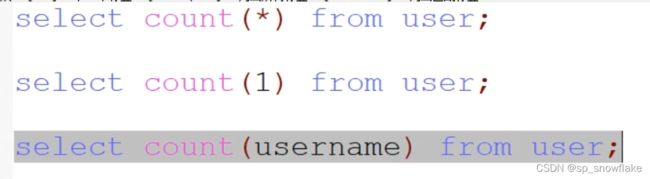
a、explain——mysql 执行计划
在 sql 语句前面加 explain,就可以查看 sql 语句的执行计划,意思是 mysql 打算如何执行你的这句 sql 语句。
效果:
![]()
字段解释:

最右边的字段,Extra:Using index,意思是使用了索引。
经测试可知,前两句执行结果是一样的,第三句执行结果就不同了。
2、原理分析
在搞原理之前,先要了解下索引结构:
a、索引结构
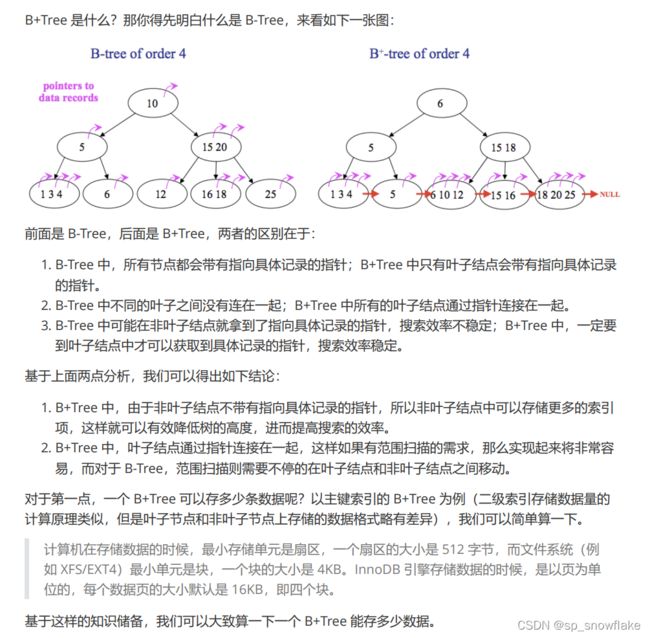


b、两类索引
这里先了解两类索引,下面使用的案例跟上面不是同一种类型。

c、原理分析
既然是聚合函数,那么就需要对返回的结果集进行一行行的判断,这里就涉及到一个问题,返回的结果是啥?我们分别来看:
1、对于 select count(1) from user; 这个查询来说,InnoDB 引擎会去找到一个最小的索引树去遍历(不一定是主键索引),但是不会读取数据,而是读到一个叶子节点,就返回 1,最后将结果累加。
2、对于 select count(id) from user; 这个查询来说,InnoDB 引擎会遍历整个主键索引,然后读取id 并返回,不过因为 id 是主键,就在 B+ 树的叶子节点上,所以这个过程不会涉及到随机 IO(并不需要回表等操作去数据页拿数据),性能也是 OK 的。
3、对于 select count(username) from user; 这个查询来说,InnoDB 引擎会遍历整张表做全表扫描,读取每一行的 username 字段并返回,如果 username 在定义时候设置了 not null,那么直接统计username 的个数;如果 username 在定义的时候没有设置 not null,那么就先判断一下 username 是否为空,然后再统计。
最后再来说说 select count() from user; ,这个 SQL 的特殊之处在于它被 MySQL 优化过,当MySQL 看到 count() 就知道你是想统计总记录数,就会去找到一个最小的索引树去遍历,然后统计记录数。
因为主键索引(聚集索引)的叶子节点是数据,而普通索引(非主键索引)的叶子节点则是主键值,所以普通索引的索引树要小一些。然而在上文的案例中,如果我们只有主键索引,那么最终使用的就是主键索引。
如果这块有主键索引和非主键索引的前提下,执行这个语句 select count(id) from user;那么这里采用的并不是主键索引,而是非主键索引,用的索引树小的那个。这里原先并不是这样,是 mysql 优化过后才采用这种方案。
这里做一个小结:count(*) 和 count(1) 是没区别的。
d、覆盖索引

e、如果是 MyISAM 引擎呢?

f、建议使用自增的主键
根据前面学习的知识,这里捋一下为什么在数据库中建议使用自增的主键:

如果业务中想使用不是自增的东西作主键,可以在表中加一个业务无关的字段,比如 id,用这个来作主键;如果有需要,其他的字段可以创建成一个唯一非空的索引,这样跟主键的效果也差不多。
3、索引的分类
a、按功能划分

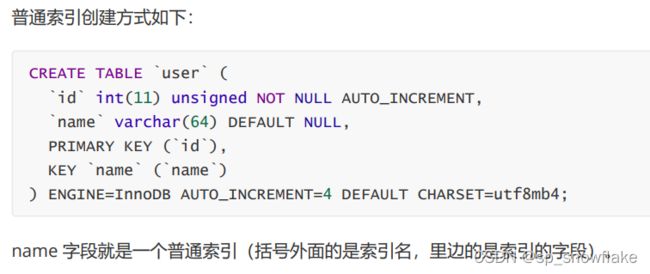
(1)、普通索引
普通索引就是最最基础的索引,这种索引没有任何的约束作用,它存在的主要意义就是提高查询效率。
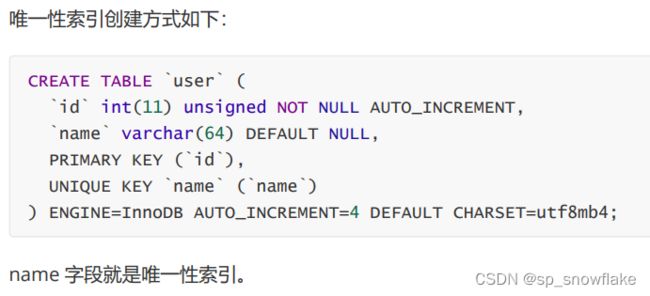
(2)、唯一性索引
唯一性索引则在普通索引的基础上增加了数据唯一性的约束,一张表中可以同时存在多个唯一性索引; 加唯一性索引虽然可能导致插入变慢, 不过影响不是特别大。唯一性索引是可以为 null 的。
(3)、主键索引
主键索引则是在唯一性索引的基础上又增加了不为空的约束(换言之,添加了唯一性索引的字段,是可以包含 NULL 值的),即 NOT NULL+UNIQUE ,一张表里最多只有一个主键索引,当然一个主键索引中可以包含多个字段。
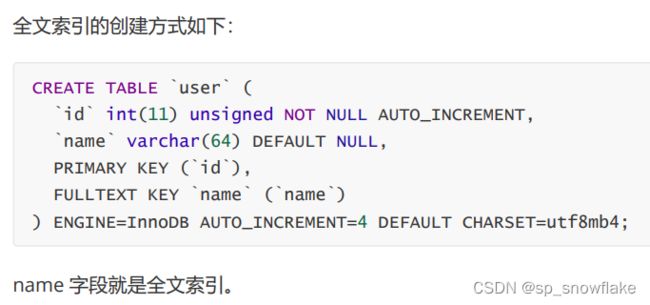
(4)、全文索引
全文索引其实很少在 MySQL 中用,如果项目中有做全文索引的需求,一般可以通过 Elasticsearch或者 Solr 来做,目前比较流行的就是 Elasticsearch 了。

不过 MySQL 的全文索引并不好用,有这方面的需求还是直接上 Es 吧。
b、按物理实现划分

(1)、聚集索引
聚集索引在存储的时候,可以按照主键(不是必须,看情况)来排序存储数据,B+Tree 的叶子结点就是完整的数据行,查找的时候,找到了主键也就找到了完整的数据行。
为什么叫聚集索引呢?索引跟数据保存在一起就是聚集索引。 所以主键索引就是聚集索引。但是聚集索引不一定是主键索引!
在聚集索引里,表中数据行按索引的排序方式进行存储,对查找行很有效。只有当表包含聚集索引时,表内的数据行才会按找索引列的值在磁盘上进行物理排序和存储。每张表只能有一个聚集索引,原因很简单,因为数据行本身只能按一个顺序存储。
当我们基于 InnoDB 引擎创建一张表的时候,都会创建一个聚集索引,每张表都有唯一的聚集索引:
- 如果这张表定义了主键索引,那么这个主键索引就作为聚集索引。
- 如果这张表没有定义主键索引,那么该表的第一个唯一非空索引作为聚集索引。
- 如果这张表也没有唯一非空索引,那么 InnoDB 内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个 6 个字节的列,该列的值会随着数据的插入自增。
聚集索引最主要的优势就是查询快。如果要查询完整的数据行,使用非聚集索引往往需要回表才能实现,而使用聚集索引则能一步到位。
不过聚集索引也有一些劣势:
- 聚集索引可以减少磁盘 IO 的次数,这在传统的机械硬盘中是很有优势的,不过要是固态硬盘或者内存(有时候为了提高操作效率,数据库服务器会整一个比较大的内存),这个优势就不明显了。
- 聚集索引在插入的时候,最好是主键自增,自增主键插入的时候比较快,直接插入即可,不会涉及到叶子节点分裂等问题(不需要挪动其他记录);而其他非自增主键插入的时候,可能要插入到两个已有的数据中间,就有可能导致叶子节点分裂等问题,插入效率低(要挪动其他记录)。如果聚集索引在插入的时候不是自增主键,插入效率就会比较低。
(2)、非聚集索引
非聚集索引我们一般也称为二级索引或者辅助索引,对于非聚集索引,数据库会有单独的存储空间来存放。
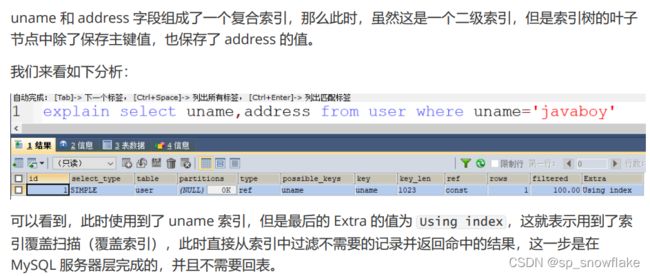
非聚集索引在查找的时候要经过两个步骤,例如执行 select * from user whereusername=‘javaboy’ (假设 username 字段是非聚集索引),那么此时需要先搜索 username 这一列索引的 B+Tree,这个 B+Tree 的叶子结点存储的不是完整的数据行,而是主键值,当我们搜索完成后得到主键的值,然后拿着主键值再去搜索主键索引的 B+Tree,就可以获取到一行完整的数据。
所以如果我们在查询中用到了非聚集索引,那么就会搜索两棵 B+Tree,第一次搜索 B+Tree 拿到主键值后再去搜索聚集索引的 B+Tree,这个过程就是所谓的回表。
一张表只能有一个聚集索引,但可以有多个非聚集索引。使用聚集索引的时候,数据的查询效率高,但如果对数据进行插入,删除,更新等操作,效率会比非聚集索引低。
4、最左匹配原则
我们常说,MySQL 中的 like 要慎用,因为会全表扫描,这是一件可怕的事!不过呢,也看情况,有的like 其实也能用索引:有的时候 like 用索引效率很高,有的时候 like 虽然用了索引效率却低的可怕。
a、索引的最左匹配
先举个例子:

username 和 age 组成了复合索引,复合索引名为 username,下文提到的 username 索引都是指该复合索引。
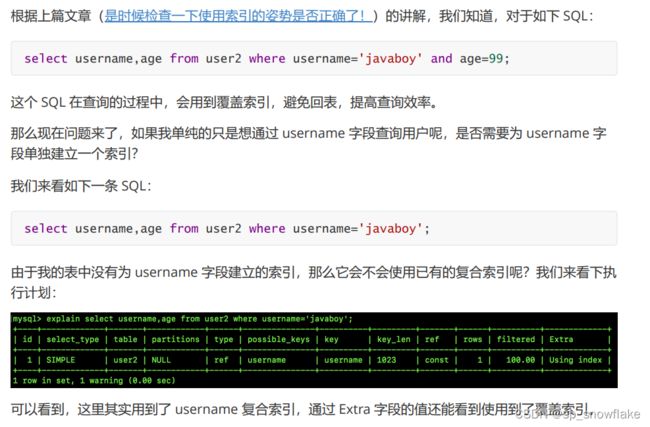
为什么会这样呢?在 B+Tree 这种索引结构中,可以利用索引的“最左匹配”来定位记录。最左匹配既可以是匹配复合索引中的前几个字段,也可以是匹配第一个字段的前几个字符,在上面的案例中,我们匹配的是复合索引中的第一个字段。
可以看到上面的 username 和 age 组成了复合索引,但是这个复合索引的顺序是怎样的呢?是 username 还是 age 呢? 其实是 username + age。比如 zhagnsan20,lisi55。这里会把 username + age 拼成一个完整字符串然后去排序。在底层存储的时候,先按照 username 去排序,当 username 相同再按照 age 去排序。
age 在 username 索引树里面是无序的。
执行一条筛选 age 的 sql 语句测试:

虽然 age 是复合索引的一部分,但是竟然用不了,就是这个原因。在复合索引里面 username 在最左边,所以生成的树排序就是按照 username 的来。
所以小结一下:在联合索引里面,可以 username +age 来搜索,也可以单 usernname 搜索,但是不能 age 搜索。
这里额外啰嗦一下:
可以看到,这里的索引是非聚集索引,非聚集索引的叶子节点存储的就是主键的值,如果此时搜索出来的字段加上主键 id,还是覆盖索引吗?测试一下:

结果:在非聚集索引里面叶子结点存储的值就是主键的值。因为上面的结果确实还是覆盖索引。但是如果搜索出来的字段再加上其他的,那么再次搜索就需要回表了。
b、like 的最左匹配分情况
(1)、以 xxx 开头
那么现在如果只是 username 的前几个字符搜索,也能使用到覆盖索引吗?
答案是看情况。
比如匹配的是第一个字段的前几个字符,如下:


从这执行计划中首先可以确认这个查询也用到了 username 复合索引。
不过这里的查询计划和前面的不太一样,两条 SQL 的区别在于一个是等于号一个是模糊匹配,查询计划的主要区别在于 type 和 Extra:
- 前面的 type 为 ref 表示通过索引查找数据,一般出现等值匹配的时候,type 会为 ref;后面这个type 为 range 表示这是一个索引的范围扫描(因为是模糊匹配,而模糊匹配可以形成扫描区间)。
- 前面的 ref 为 const 表示与索引列进行等值匹配的是一个常量。
- 前面的 Extra 为 Using index 表示使用到了覆盖索引;后面的 Extra 为 Using where;Usingindex ,表示用到了索引,但是还需要进行过滤。
(2)、包含 xxx
如果是 like ‘%xxx%’ 这种包含性质的。那就用不到索引了。
题外话:最左匹配不一定是 like,但是 like 里面一定会有最左匹配的问题。
c、重复、冗余索引
上面的例子中可以看到,无论是 username + age 或者是单 username ,都能使用索引,所以如果数据库中再加上 username 索引就是多余的了:

d、最左匹配第二个例子
为了更好的理解上面所说的最左匹配,再来举一个例子:

看上图,之前明明说了 age 是无序的,为什么还是用到了 username 索引呢?
这时候就要看到 Extra 里面,除了有 Using index,还有 Using where。首先这里先把 mysql 架构分为两层(这里仅展示部分,并不是全部层):
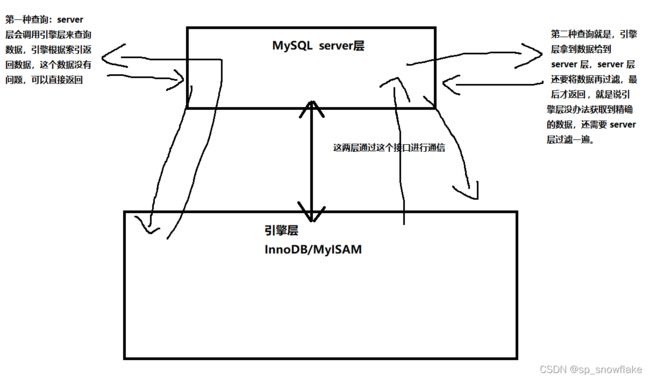
此时再看上面的结果,如果有 Using where 意味着还要在 server 层进行二次过滤。
当我们按照 age 去搜索的时候,因为 age 在 username 索引中是无序的,所以只能遍历 username 索引,而执行计划中的 type 为 index,恰恰就表示需要扫描全部的索引记录。以第一条查询 SQL 为例,扫描全部的索引记录,然后过滤出 age 等于 99 的记录(过滤这一步是在 server 层完成的),rows 表示预估的扫描行数,从最后的 Extra 的 Using where;Using index 也能看出这一点,即用到了索引,但是也对数据进行了过滤。
如果这里是使用这个语句:

查询的是所有字段,那么此时就没有必要使用索引了。
来个反证:假设现在还是使用 username 复合索引,那么就需要把 username 索引整个读一遍,然后过滤出满足条件的数据,由于索引中没有保存 address 字段的值,所以还需要回表操作,再去主键索引中找到对应的记录。。。这一路操作下来太麻烦了,光B+Tree 都读了两棵(而且第一颗 B+Tree还是遍历),那我们还不如直接遍历主键索引呢!主键索引里要啥有啥,遍历完了想要的数据都有了,遍历主键索引其实就是我们常说的全表扫描。
此时再看结果:

5、索引独立原则
当我们将带有索引的列作为搜索的条件的时候,需要确保索引不在表达式中,索引中也不包含各种运算。
假设所有字段都建立了索引。现在看下面两句查询:
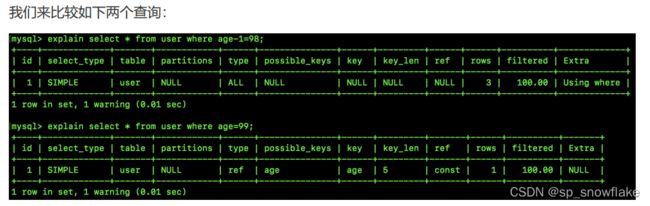
可以看到:
- 第一个 type 为 ALL 表示全表扫描(没用上索引);第二个 type 为 ref 表示通过索引查找数据,一般出现等值匹配的时候,type 会为 ref。
- 第二个的 key 指明了 MySQL 使用哪个索引来优化查询;rows 则显示了 MySQL 为了找到所需的值而要读取的行数.
- 第一个的 Extra 为 Using where 表示这个搜索需要在 server 层进行判断(过滤),即存储引擎层无法返回满足条件的数据(当然这里也不需要回表,因为压根都没有用啥索引)
从上面的分析中可以看到,虽然 age-1=98 与 age=99 虽然在逻辑上并无二致,但是 MySQL 却无法自动解析第一个表达式,进而导致第一个无法使用索引。所以,我们不要在 where 条件中写表达式,不仅仅是上面这种表达式,一些使用了自带函数的表达式也不能使用,我们要尽量简化 where 条件。
不过上面的例子比较牵强,感觉正常人都不会这么写的,但是还有其他例子,大多数人都会犯的一个错误:
现在的需求是查询最近一年出生的人,其中 birthday 已经建立索引,两种查询思路:
- 对 birthday 做计算,如果 birthday 加上一年,得到的时间大于当前时间,那么说明该用户出生日期在最近一年之内。
- 对当前日期进行计算,如果当前日期减去一年得到的时间小于 birthday,说明 birthday 在一年之内。
那么现在先看第一种:
补充: date_add() 是 mysql 自带的日期函数;curdate()是取当前时间
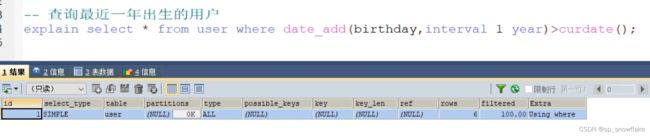
可以看到还是全表扫描。原因就是索引的字段上用了表达式,用了表达式索引就会失效。
所以应该采用第二种:

小结:根据上面 explain 的结果,很明显第一种方案没有用上索引,进行了全表扫描;而第二种方案则用上了索引,只读取了两行数据就可以了。究其原因,就是因为第一种方案在索引列上进行了函数运算,导致MySQL 没法使用索引了。
再来个例子:
补充:year()取的是时间的年份。

可以看到还是没用上索引。
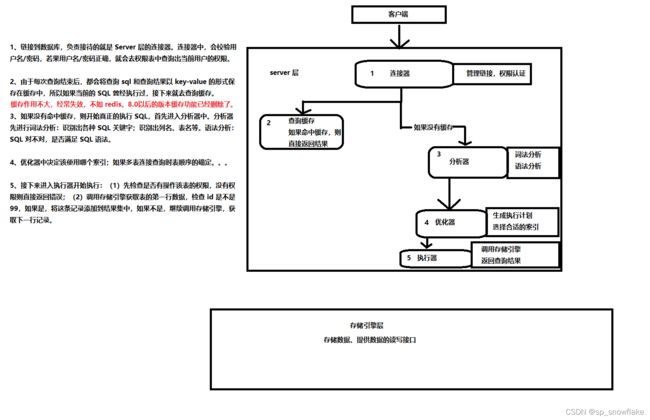
三、MySQL 查询执行流程