SQL 大数据优化
SQL Server Profiler
SQL Server提供的监控工具,在运行命令中输入“profiler”,也可以打开。此工具重点是监控在指定服务器上执行的SQL语句,存储过程等一切数据库的操作。对于分析数据库语句执行,死锁,性能瓶颈具有很好的作用。
打开SQL Server Profiler后,是一个空框架,我们需要添加对应的跟踪(Trace),打开文件中的新建跟踪,则弹出服务器连接信息,此监控支持本地或服务器远程监控,输入对应的身份验证信息后,点击连接则打开“跟踪属性”设置界面,此处是本节要说的重点,好多都是直接点击"运行”,发现监控的内容忽忽闪,刚选定一行,一会又出来很多看不懂得东西,其实这就是缺少跟踪属性的有效设置,对于一个在服务器上运行的Trace,它监控的是好多数据库,好多连接,如果不有效的锁定要查看的对象,那几乎就是在刷屏。另外打开Trace会消耗服务器性能,建议慎重操作。
下边说跟踪属性设置的几个点吧,个人观点哦:
1、常规选项卡中,使用模块: Starndard(默认值),选择它就可以,无需更改
2、打开事件选择选项卡,一般来讲我们打开监控都是有原因的,可能是想查看一个存储过程的执行,可能是T-SQL等等,根据实际锁定目标即可,不用的都可以不选取,这样Trace对这类执行直接Pass,比如我们只看存储过程,则抓图如下:
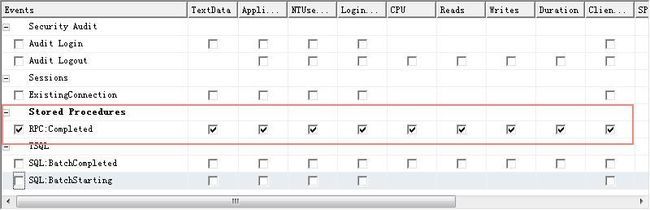
这样Trace值跟踪存储过程的执行了,这还是有些不太满足要求,此时可以考虑添加列筛选,点击“列筛选器”,进行设置,当然我一般只做如下筛选,你可以结合自己的实际进行设置筛选条件,设置LoginName根据你查询的登录名,比如sa,设置Duration持续时间,大于等于2000(单位毫秒),这样就可以把大数据量的查询和性能较慢的给罗列出来包括CPU使用情况,Read,Write等参数,然后再分析对应的语句,找出问题所在,使用此工具可以快速锁定目标进行分析。
性能计数器
监控数据库的性能此工具也是必不可少,可以有效的监控机器的使用情况。通过SQL Server Profiler工具中的性能监视器进行打开,或者在运行命令中,输入perfmon进行打开。此工具只能查看本机的性能情况,无法监控远程机器。通过性能监控器可以查看当前时间点机器的各项使用指标包括CPU,IO,内存等等分析相关参数,找到是硬件配置过差,还是机器性能没有得到充分的发挥,找到问题的确切原因,然后才能进行对应的优化。
在性能计数器中,默认机器上有很多计数器,此处重点需要添加如下几个进行观测:
1、添加计数器,在菜单上,或右键打开,如下图,选择添加计数器
2、选择你所关注的计数器:
a、SQLServer:Buffer Manager计数器 ,在里边的参数中重点关注Buffer cache hit ratio,page life expectancy选中后,点击添加,确定后就能看到实时的检测
b、Memory计数器,关注page reads/sec, pages/sec等
具体参数和对应数值代表什么意思,可以查看官方的解释,很全面。
通过计数器的实时检测,可以快捷的分析问题的所在,比如内存持续走高,cpu使用包含,缓存无效等等。找到问题对应的优化,该添加硬件添加硬件,该优化代码优化代码。
执行计划
这个很简单了,在SQL Server Studio中直接“查询”菜单下,选择显示执行计划即可,每次的执行就可以看出来,执行计划详细的罗列出来每次执行的cpu使用,消耗时间,逻辑读,物理读等参数,分析对应的数据记录进行优化即可,显示执行计划不难,难在如何对显示结果看明白,然后找到问题所在进行优化,相关的过程需要深入查看对应的内容。
SQL Prompt 4
Sql Server一个很不错的插件,值得推荐,通过它在2005及其之前的版本书写语句时会有自动提示,还可以检查语法,高亮显示对应关键字等,其中部分功能已经被集成在SQL Sersver2008及其以后的版本中,有兴趣的可以去下载,书写对应的sql语句方便不少呀。
抓个图看看效果吧: 特提供SQLPrompt4下载地址。
1、审核大数据表的索引、存储过程、sql语句
此方式是基础性的,重点通过数据表的逻辑分析和性能工具,执行计划查看是否缺少索引或sql语句书写的消耗性能进行优化,对于存在IO瓶颈的问题,可以尝试 使用翻页存储过程等方法,在底层上实现数据优化,之前也有文章说明了一些常用sql语句的性能对比,尽量修改之。
2、数据库日志文件压缩
一个数据库包含Data文件和Log文件,对于一个大库,细心的你有时候会发现,日志文件如此之大,我使用的日志文件达到18G,日志文件对于分析数据库操作和例外情况下的数据恢复具有关键的作用,但这么的文件最好的方法就是定期备份,然后清空日志。在不影响数据库正常使用的情况下清空日志方法如下:
a、执行如下语句:DUMP TRANSACTION DBName WITH NOLOG
b、右键数据库名,选择:任务-->收缩--->文件,选择文件类型:日志,在收缩操作中,选择释放...,输入0,点击确定,则日志文件则被清空
日志文件的太大一方面会大量占用文件磁盘,另外在对应的数据操作中,频繁的日志读写也一定程度上影响磁道的检索速度,影响性能。
注:如果需要备份日志的,实现应该先备份日志。

3、查看数据库对应元数据,分析索引碎片,整理索引碎片
索引就是一个字典目录,保存着快捷访问记录的方式。但由于数据是动态变化的,不停的修改,删除,插入可能导致索引动态变化,日积月累就会存在索引碎片,这将导致系统在执行对应查询检索过程中,要执行一些额外的操作能定位到指定的索引,最好的方法就是一次性定位到索引,因此动态的整理索引,清楚索引碎片也很关键。下文代码系统自动清理当前库中,索引碎片大于12%的索引,并重建对应索引。
先看如何查看索引碎片:
use DBName --对指定的整个数据库所有表进行重新组织索引 set nocount on--使用游标重新组织指定库中的索引,消除索引碎片--R_T层游标取出当前数据库所有表 declare R_T CURSOR for select name from sys.tables declare @T varchar(50) open r_t fetch NEXT from r_t into @t while @@fetch_status=0 begin--R_index游标判断指定表索引碎片情况并优化 declare R_Index CURSOR for select t.name,i.name,s.avg_fragmentation_in_percent from sys.tables t join sys.indexes i on i.object_id=t.object_id join sys.dm_db_index_physical_stats(db_id(),object_id(@T),null,null,'limited') s on s.object_id=i.object_id and s.index_id=i.index_id declare @TName varchar(50),@IName varchar(100),@avg int,@str varchar(500) open r_index fetch next from r_index into @TName,@Iname,@avg while @@fetch_status=0 begin if @avg>=12 --如果碎片大于12,重建索引 begin set @str='alter index '+rtrim(@Iname)+' on dbo.'+rtrim(@tname)+' rebuild' end else --如果碎片小于30,重新组织索引 begin set @STR='alter index '+rtrim(@Iname)+' on dbo.'+rtrim(@tname)+' reorganize' end print @str exec (@str) --执行 fetch next from r_index into @TName,@Iname,@avg end--结束r_index游标 close r_index deallocate r_index fetch next from r_t into @t end--结束R_T游标 close r_t deallocate r_t set nocount off
附带的清理统计信息,适情况也可以清理一下,如果统计信息有效则清理会自动跳过
USE DBName GO EXEC sp_MSforeachtable @command1="print '?' DBCC DBREINDEX ('?',' ',90)" GO EXEC sp_updatestats Go
注:上文中的Use DBName,是使用对应的数据库名,使用时注意修改。
完成如上操作后可以重启数据库服务,看看效果,以上优化可以一定程度上提升性能。
4、建立分区表和分区库
这个在强度和力度上都是效果显著的,之前老觉得建立分区表是不是需要很多复杂的操作,需要建立对程序业务熟悉等等,其实sql已经给出了完善的方案。
磁盘分区表就是实现表的水平分区,将一个数据分布在多个数据实体文件中,即.mdf 文件中,考虑到性能每个数据文件最好在不同的物理磁盘上。具体操作步骤罗列如下:
a、创建分区函数,主要使用CREATE PARTITION FUNCTION XXX(parms)
b、查看分区函数是否创建成功