StarRocks 优化器代码导读
导读:欢迎来到 StarRocks 源码解析系列文章,我们将为你全方位揭晓 StarRocks 背后的技术原理和实践细节,助你逐步了解这款明星开源数据库产品。本期 StarRocks 技术内幕将主要介绍 StarRocks 优化器的原理及代码设计。
整体流程
优化器是数据库的核心组件,它从所有可能的计划中选择代价最优的 Plan 提供给执行引擎,是数据库大脑般的存在。业界的数据库优化器种类繁多,StarRocks 的优化器主要参考了 COLUMBIA、ORCA 的论文实现(文末有参考资料),如下图所示,StarRocks 优化器主要覆盖图中以下两个阶段:
-
Tree Rewriter
-
Optimizer


关于 Parser/Analyze 阶段可以分别参考: StarRocks Parser 源码解析,StarRocks Analyzer 源码解析
在完成 Analyze 阶段后,我们可以拿到逻辑执行计划(如下图):
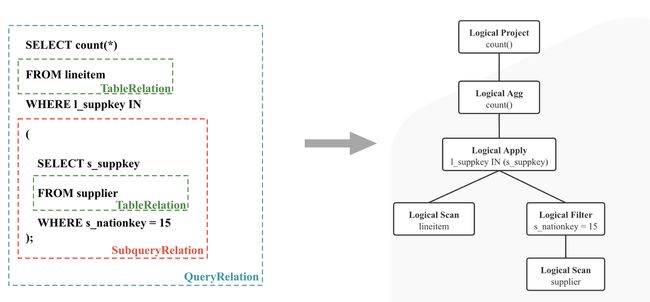
至此,我们开始进入 StarRocks 优化器的代码中,其入口只有一个:
/*
com/StarRocks/sql/optimizer/Optimizer.java:optimize
*/
public OptExpression optimize(ConnectContext connectContext,
OptExpression logicOperatorTree,
PhysicalPropertySet requiredProperty,
ColumnRefSet requiredColumns,
ColumnRefFactory columnRefFactory);optimizer 的主要流程包括:
-
memo.init:优化器搜索空间初始化;
-
logicalRuleRewrite:基于逻辑计划的启发式规则的优化,对应图中的Tree Rewriter阶段;
-
memoOptimize:基于Cost优化,核心规则是JoinReorder/AggregateSplit,对应图中的Optimizer阶段;
-
extractBestPlan:提取最优的物理执行计划;
-
physicalRuleRewrite:基于物理计划的启发式规则优化。 下文我们会按照以上流程介绍 StarRocks 的优化器,但在这之前,会先给大家介绍一下代码结构,以及必要的背景概念。
代码结构
# src/main/java/com/StarRocks/sql/optimizer
optimizer/
├── base # plan的基础类,主要和property相关
├── cost # cost 模型
├── dump # query dump接口使用
├── operator
│ ├── logical # 逻辑计划operator
│ ├── pattern # Rule pattern
│ ├── physical # 物理计划operator
│ └── scalar # 表达式operator
├── rewrite # 物理重写rule
│ └── scalar # 表达式重写rule
├── rule
│ ├── implementation # 物理实现rule
│ ├── join # join reorder相关
│ ├── mv # 物化视图相关
│ └── transformation # 逻辑优化rule
├── statistics # 统计信息相关
├── task # 优化器的驱动任务
└── transformer # 转换Ast相关背景概念
以下介绍的概念均可在src/main/java/com/StarRocks/sql/optimizer/路径下找到对应的类。
OptExpression
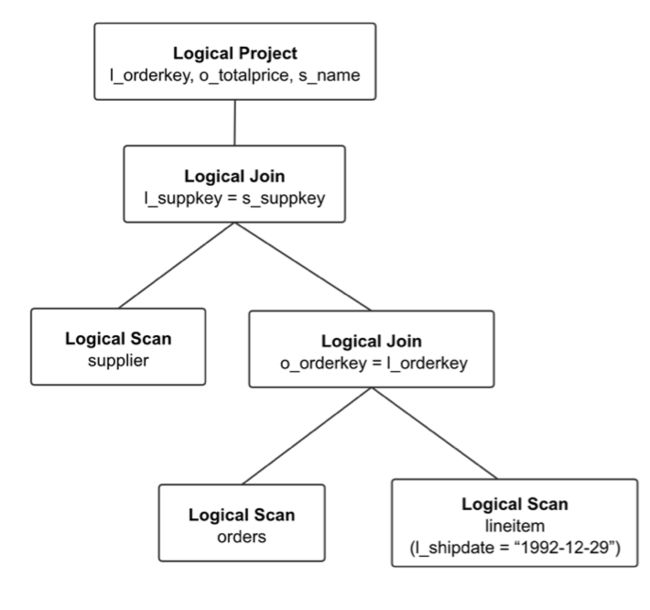
OptExpression 是逻辑执行树的基本节点单位,每个 OptExpression 中包含 Operator,表示一个操作节点。如上图,Logical Project 是一个 Operator,为 Logical Project 的 OptExpression。在逻辑计划树上,SQL执行的顺序为自底向上。
需要注意的是 OptExpression 只用于描述树结构,主要是用在传递计划树的接口上,在Memo/Group/GroupExpression 中都不会存在该结构。
Memo
Memo 用于记录优化器搜索过程中产生的各种备选的 Plan,其数据结构如下图所示。
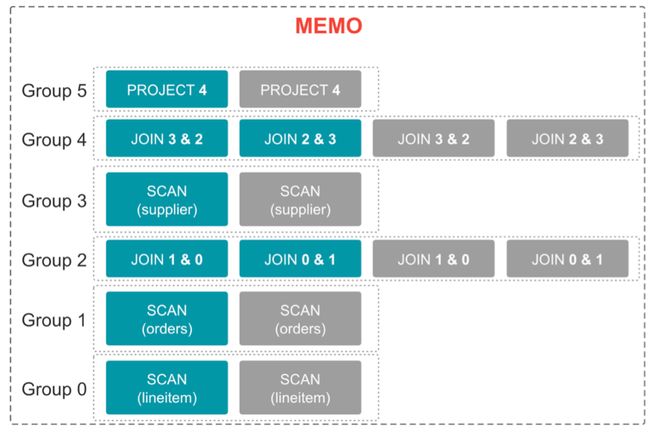
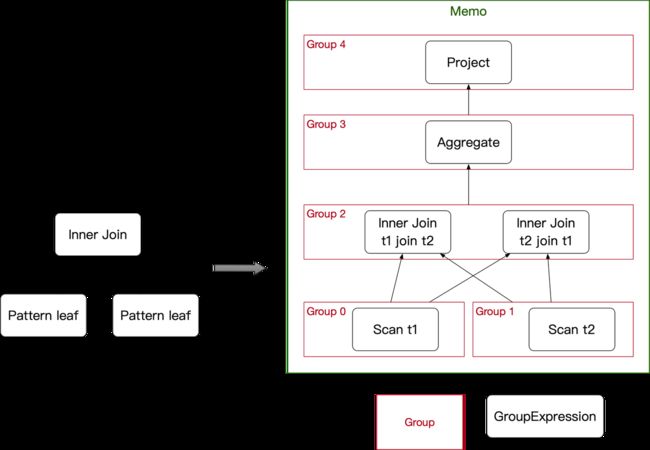
Memo 中的基本单位为 Group,每当我们 Copy 一个新的计划到 Memo 中,会根据逻辑计划的节点,生成新的 Group 或者加入到已有的 Group 中。而在 Memo 中,Group 和 Group 之间通过 GroupExpression 建立引用关系,可以进一步表述出一棵执行计划树。 Group在 Memo 中最大的作用是避免生成重复节点,从而减少搜索空间。
Group
如 Memo 图,一个 Group 中会包含多个 GroupExpression,这些 GroupExpression 可以是一个逻辑节点,也可以是一个已经“翻译”成实际执行操作的物理节点。
一个 Group 中的 GroupExpression 是逻辑等价的,这里的逻辑等价是指:该 Group 中所有的GroupExpression 节点的输出数据都是相同的。因此,我们也可以这样认为,Group 表示了一组特定的数据,而 Group 中的 GroupExpression,表示了这一组特定数据是通过什么方式生成,而生成数据的方式可以有很多种。 除了 GroupExpression 以外,Group 中还会存储一些统计信息和 Property。由于其中的 GroupExpression 都是逻辑等价的,所以同一个 Group 中的 GroupExpression 会共用一份统计信息。
GroupExpression
GroupExpression 和 OptExpression 类似,包含了一个具体的 Operator,用来表示 GroupExpression 的具体行为,和 OptExpression 的区别在于:
-
GroupExpression 需要存储和物理计划相关的 Property,而 OptExpression 不需要,OptExpression只用于表述一个计划树;
-
GroupExpression 的输入(孩子节点)是一个 Group,这意味着 GroupExpression 的输入可以是 Group 中的任意一个 GroupExpression(因为执行结果都是等价的),而 OptExpression 的输入还是一个 OptExpression,是一个已经确定的 Operator。 基于以上几个基本概念的解释:
-
Memo 中包括多个 Group,每个 Group 在 Copy 执行计划时生成;
-
Group 中包括多个 GroupExpression,每个 GroupExpression 的输入为 Group;
-
对于 GroupExpression 而言,其孩子(Group)提供特定的数据输入,而具体产生这些数据的方式可能有多种(Group 中可以有多个表示不同实现的 GroupExpression,但他们都是等价的)。 如下图所示,Memo 中 Group 和 Group 之间可以组成左边的逻辑执行计划。

Memo Init
Memo 空间初始化,将原始的 OptExpression 逻辑计划树 Copy 进 Memo 空间,代码按图索骥即可。
Logical Rule Rewrite
Logical Rule Rewrite 阶段,主要是对逻辑计划进行重写,StarRocks 里包含了非常多的启发式规则,这些规则可以在src/main/java/com/StarRocks/sql/optimizer/transformer下找到。
以下简单举例有:
-
列裁剪(Prune,Column)
-
谓词下推(Pushdown,Predicate)
-
Limit Merge, Limit 下推(Limit)
-
聚合 Merge(Agg,Merge)
-
等价谓词推导(Equivalence)
-
Join类型转化(Pushdown,Join)
-
常量折叠(FoldConstant)
-
公共表达式复用(Common)
-
子查询重写(Apply)
-
CTE重写(CTE)
-
分区分桶裁剪(Prune)
-
.......
每个规则可以按照括号中的关键词搜索,或者直接从 RuleSet 中查找,具体每个 Rule 规则这里不再详细描述。
需要注意的是,Logical Rule 重写的顺序是很讲究的,并不能随意更换重写的顺序,具体缘故和实现 Rule 的功能相关,在添加 Rule 的时候需要仔细思考。
Logical Rule Rewrite 阶段通过 TopDownRewriteTask 调度重写,主要分为两种:
-
TopDownRewriteOnceTask:新生成的节点不会再进行匹配重写;
-
TopDownRewriteIterativeTask:新生成的节点会重新进行匹配,循环重写。
大部分 Rule 会循环重写,直到逻辑树不能匹配上 Rule 为止,比如谓词下推,会将谓词尽可能下推到底层节点,直到最终逻辑树不会再改变。 RewriteTask 的核心流程:
-
使用 Rule 的 Pattern,在 Memo 中 Binder 到一棵局部的逻辑树;
-
使用 Rule 重写这棵局部的逻辑树;
-
将重写后的逻辑树 Copy 回 Memo,直接替换掉原有的逻辑树。
Rule Rewrite 有两个核心概念,接下来会一一介绍:
-
Pattern
-
Binder
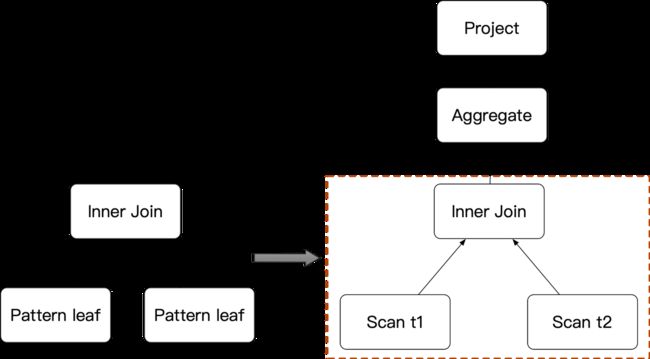
Pattern
Pattern 主要用于描述 Rule 的匹配规则,用户可以按照想要匹配的 Operator 类型创建Pattern。除了常规的 Operator 类型以外,StarRocks 还提供两种特殊的 Operator:
-
PATTERN_LEAF:用于匹配任意单个节点,几乎每个 Rule 里都会以 PATTERN_LEFF 作为叶子节点;
-
PATTERN_MULTI_LEAF:用于匹配N个(>=0)任意节点,在 UNION、INTERSECT、EXCEPT 这类多输入节点相关的Rule中比较常见。 如下图,左边的 Pattern 可以匹配到右边逻辑计划树的一部分。
Binder
Binder 主要作用是利用 Rule的 Pattern 去匹配 Memo 中的逻辑计划树。在实际执行过程中,逻辑树的链接关系是由 Group 和 GroupExpression 构成,Group 中每一个 GroupExpression 都需要参与匹配。如下图所示,左边的 Pattern 需要既能匹配出 t1 Join t2,也要匹配出 t2 Join t1。所以 Binder 的核心是一个带记忆化的多叉树搜索。
Memo Optimize
Memo Optimize 阶段是 StarRocks 优化器中最核心,同时也最复杂的部分,其工作主要有:
-
Transform:探索各种不同的逻辑计划;
-
Implement:将逻辑节点实现为物理节点;
-
计算各个节点统计信息:收集&计算各个节点的统计信息;
-
规划最优计划:根据Cost和数据分布信息,规划最优的分布式计划。
调度流程
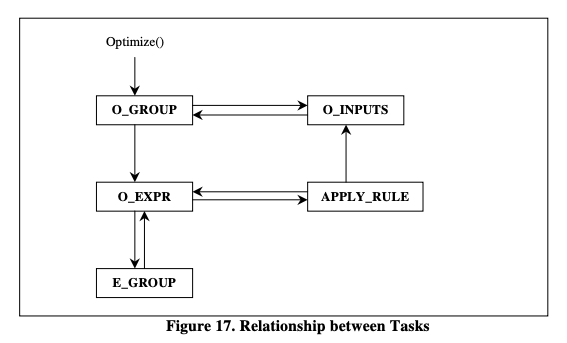
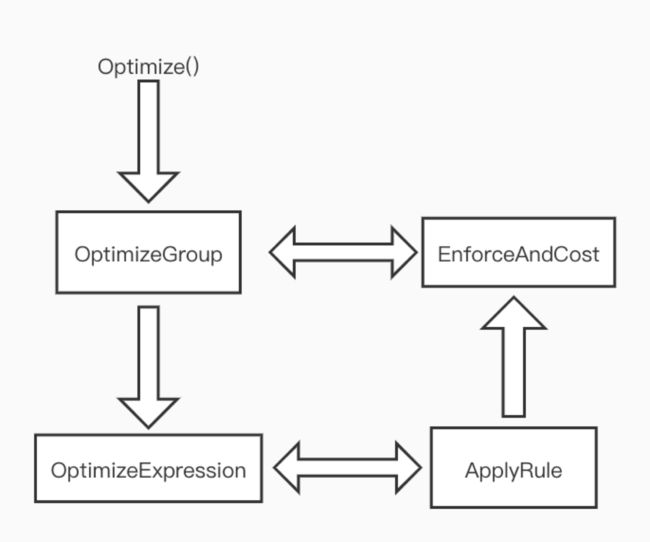
Memo Optimize 主要流程由 Stack 压栈出栈驱动,整体逻辑和 COLUMBIA 中的流程几乎一致。左图为COLUMBIA 论文中的调度流程,右图为 StarRocks 中的调度流程,最大的区别是 StarRocks 中没有ExploreGroup 这一步。COLUMBIA 中会先推导出所有的逻辑计划,StarRocks 则是先推导出一个物理计划,再探索其他计划。
每个 Task 中的实际代码并不复杂,这里不再赘述,总结下来 Optimize 的执行流程包括以下几个步骤:
-
收集&计算所有节点的统计信息;
-
检查 Group 是否已经有最佳(cost 最低)物理计划?如果有则直接返回,如果没有,则进入步骤3,计算该 Group 的最佳物理计划;
-
Group 计算最佳物理计划会要求孩子也有最佳物理计划,如果有,则直接计算;没有,则以孩子Group 作为输入重复步骤 2,依次往下层节点递归,完成后得到 Group 的最佳物理计划;
-
探索该Group中其他可能的计划,探索分为两类:
-
由逻辑计划生成新的逻辑计划,对于新生成的逻辑计划,会重复步骤 4,以新的逻辑计划为基准,生成更多新的逻辑/物理计划
-
由逻辑计划生成对应的物理计划,对于新生成的物理计划,会重复步骤 3,计算该物理计划的 Cost
-
直到最终找到最佳的物理计划。
下面以一个简单的 SQL 为例,帮助读者理解。其在 Memo 中仅有一个 Scan 节点,一个 Group:
select * from t1;
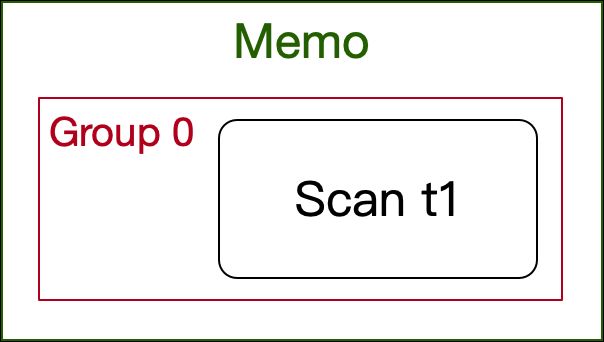
Stack 栈中的任务出入记录:
1 PUSH: OptimizeGroupTask(LogicalScanOperator)
2 PUSH: DeriveStatsTask(LogicalScanOperator)
3 POP: DeriveStatsTask(LogicalScanOperator)
4 POP: OptimizeGroupTask(LogicalScanOperator)
5 PUSH: OptimizeExpressionTask(LogicalScanOperator)
6 POP: OptimizeExpressionTask(LogicalScanOperator)
7 PUSH: ApplyRuleTask(LogicalScanOperator)
8 POP: ApplyRuleTask(LogicalScanOperator)
9 PUSH: EnforceAndCostTask(PhysicalOlapScan)
10 POP: EnforceAndCostTask(PhysicalOlapScan)我们将依次介绍一些过程中比较重要的概念,帮助读者入门学习整个流程。
Transform
Memo Optimize 阶段,TansformRule 主要是用于探索新的逻辑计划,当前 StarRocks 在这个阶段只有以下几个 Rule:
-
JoinAssociativity:Inner/Cross Join 结合律;
-
JoinCommutativity:Join 交换律;
-
SemiReorder:Semi Join 结合律;
-
SplitAggregate:聚合拆分多阶段。
Implement
Memo Optimize 阶段,ImplementRule 主要是用于将 LogicalOperator “翻译”成 PhysicalOperator,几乎每一个 LogicalOperator 都有对应的一个或者多个 PhysicalOperator。 PhysicalOperator 表示在 BE 端某个操作的具体实现方式,比如Logical Join,对应的实现方式可以是Hash Join、Sort-Merge Join,那么就会有多种 PhysicalOperator,比如 PhysicalHashJoinOperator、PhysicalSortMergeJoinOperator。
Enforce
在介绍 Enforce 之前,先说明一下Property。
Property
在 StarRocks 中,每个 PhysicalOperator 都能提供一些 Property,用于表示该节点上能够提供的数据分布、排序等信息,当前支持的 Property 有:
-
Sort Property:主要用于表述数据是按照哪一列排序,是逆序还是顺序
-
Distribute Property:主要是用于表述数据是按何种方式分布
-
Any:没有特定分布规则,随机
-
Hash:数据在多个节点/机器上按照 Hash 分布,可以指定具体 Hash 列
-
Gather:数据聚集在一个节点/机器上
-
Replicate:数据在每个节点/机器上都有完整的副本
Property 相关的代码可以在 src/main/java/com/StarRocks/sql/optimizer/base找到。
Enforce 操作位于 EnforceAndCostTask 中,其主要目的是:在探索分布式计划时,计划中某些特殊的执行节点需要特定的数据分布/顺序,我们需要将这些有特殊需求的节点标识出来,并增加 exchange/sort 节点,让数据在分布式环境中能够满足上层节点的要求。 以下图为例,在分布式多机环境下,t1 和 t2 的分布不同,需要完成 Inner Join 操作,需要将 t1、t2的数据按照相同的计算规则分发到同一台机器上,Enforce 就是为此而生。
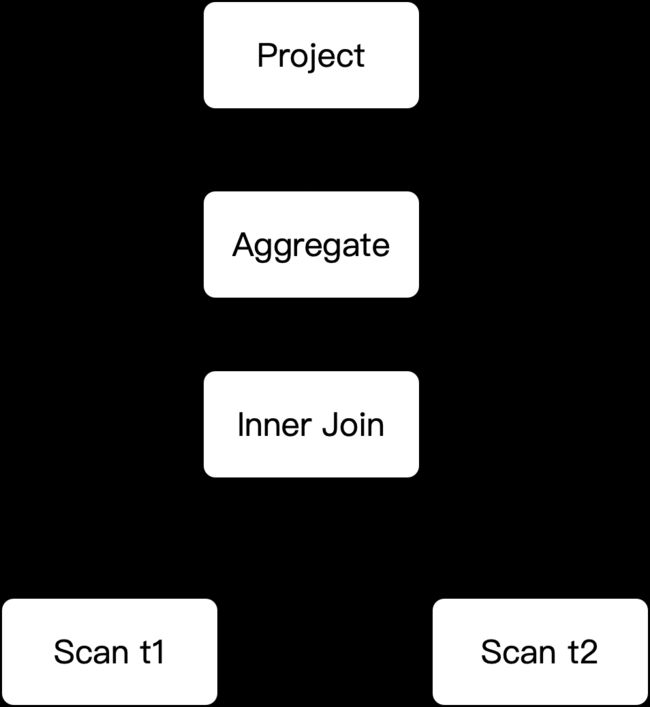
在 Enforce 流程中,StarRocks 会自顶向下地检查每个节点需要的 Property,以及能够提供的 Propery,根据这些信息决定数据是不是需要 Enforce。
编辑切换为全宽

- Enforce具体实现可以参阅 EnforceAndCostTask
-
节点提供Property的推导可以参阅 OutputPropertyDeriver
-
对孩子节点要求Property的推导可以参阅 RequiredPropertyDeriver
CostModel
CostModel 用于计算每个节点的成本,同样在 EnforceAndCostTask 中会调用到这个模块。目前 StarRocks 主要是从 CPU、内存、网络三个方面来评估每个节点、表达式的成本。具体计算规则以及原理后续在“StarRocks 统计信息和 Cost 估算“中会详细介绍。
Extract Best Plan
在 EnforceAndCostTask 中,可以计算得到每个 Plan 的 Cost、每个 Plan 要求的Property,并且将其存储在 Group 中。在这个阶段,我们只需要按照每个节点要求的 Property 自顶向下地抽取其中 Cost 最低的 Plan 即可。
Physical Rule Rewrite
在抽取完物理 Plan 以后,我们最后还会进行一个 Physical Rule Rewrite 阶段,这个阶段和 Logical Rule Rewrite 阶段相似,只是一些启发式规则的优化。之所以将这些规则放到最后,原因有两个方面:
-
物理阶段的优化,大多是局部性优化,原则上并不会影响分布式Plan的选择;
-
在前一个前提下,放在物理阶段优化,可以避免 Memo Optimize 阶段中搜索空间的膨胀,也可以减少一些冗余的code。
这个阶段,StarRocks 目前在做的事情有几个:
-
聚合模型检查是否需要打开Pre-Aggregation开关
-
三阶段/四阶段聚合调度优化
-
低基数字典优化
-
表达式复用优化 具体优化规则参阅代码即可。
参考资料
StarRocks的优化器主要参考 COLUMBIA、ORCA 的论文实现,两篇论文非常详尽的讲述了 CBO优 化器原理,非常值得大家阅读。附两篇论文的地址:
-
EFFICIENCY IN THE COLUMBIA DATABASE QUERY OPTIMIZER
-
Orca: A Modular Query Optimizer Architecture for Big Data
总结
本文介绍了优化器作为 StarRocks 的大脑是如何工作的:SQL 进入 StarRocks 后会生成对应的 AST 语法树,进一步转换为逻辑执行树;逻辑执行树在经过一系列的启发式规则优化(Logical Rule Rewrite)阶段后,执行计划得到大量优化,随后进入 Memo Optimize 阶段,利用统计信息评估各种 Plan 的 Cost,最终生成一个分布式的物理执行计划。
本期 StarRocks 源码解析到这就结束了,好学的你肯定学会了一些新东西,又产生了一些新困惑,不妨留言评论或者加入我们的社区一起交流)。下一篇 StarRocks 源码解析,我们将为你带来 StarRocks Join Reorder 源码解析。