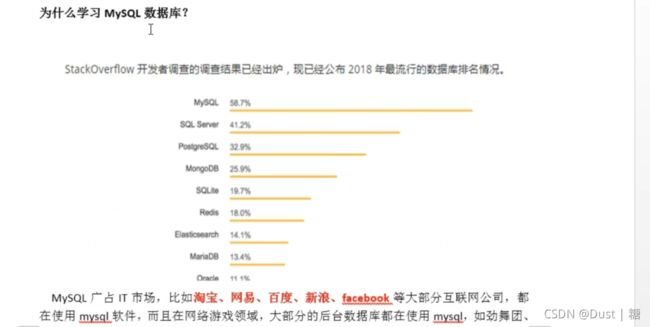
MySQL这一章就够了(一)
前言:呕心沥血5个月淦出本文,整理所有MySQL知识。我愿称之为地表最强MySQL。
MySql笔记
MySQL是关系型数据库,基于SQL查询的开源跨平台数据库管理系统。它最初是由瑞典MySQL AB公司开发的。现在它是Oracle Corporation的分支机构。
Mysql特点: 开源、兼容多个平台、扩展性强
数据库三大范式:
为避免数据冗余、操作异常和性能问题,需进行数据规范化。
数据库的三大范式:
第一范式:确保每列都是不可再分的最小数据单元
第二范式:确保每列都与主键相关
第三范式:确保表中各列必须和主键相关,不存在依赖关系。
一、SQL简述
1、SQL的概述
Structure Query Language(结构化查询语言)简称SQL,它被美国国家标准局(ANSI)确定为关系型数据库语言的美国标准,后被国际化标准组织(ISO)采纳为关系数据库语言的国际标准。数据库管理系统可以通过SQL管理数据库;定义和操作数据,维护数据的完整性和安全性。
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle公司。
MySQL是一种关联数据库管理系统,将数据保存在不同的表中,而不是将所有的数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
MySQL是开源的,所以你不需要支付额外的费用。
MySQL支持大型的数据库,可以处理拥有上千万条记录的大型数据库。
MySQL使用标准的SQL数据语言形式。
MySQL可以允许于多个系统上,并且支持多种语言。这些编程语言包括C、C++、Python、Java、Perl、PHP、Ruby和Tcl等。
MySQL对PHP有很好的支持,PHP是目前最流行的Web开发语言。
MySQL单表的上限,主要与操作系统支持的最大文件大小有关。MySQL支持大型数据库,支持5000万条记录的数据仓库,32位系统表文件最大可支持4GB,64位系统支持最大的表文件为8TB。 经过数据库的优化后5千万条记录(10G)下运行良好。
InnoDB 存储引擎将InnoDB 表保存在一个表空间内,该表空间可由数个文件创建。这样,表的大小就能超过单独文件的最大容量。表空间可包括原始磁盘分区,从而使得很大的表成为可能。表空间的最大容量为64TB。
mysql最大连接数是1000。
MySQL是可以定制的,采用lGPL协议,你可以修改源码来开发自己的MySQL系统。
GPL协议最主要的几个原则:
1、确保软件自始至终都以开放源代码形式发布,保护开发成果不被窃取用作商业发售。任何一套软件,只要其中使用了受 GPL 协议保护的第三方软件的源程序,并向非开发人员发布时,软件本身也就自动成为受 GPL 保护并且约束的实体。也就是说,此时它必须开放源代码。
2、GPL 大致就是一个左侧版权(Copyleft,或译为“反版权”、“版权属左”、“版权所无”、“版责”等)的体现。你可以去掉所有原作的版权 信息,只要你保持开源,并且随源代码、二进制版附上 GPL 的许可证就行,让后人可以很明确地得知此软件的授权信息。GPL 精髓就是,只要使软件在完整开源 的情况下,尽可能使使用者得到自由发挥的空间,使软件得到更快更好的发展。
3、无论软件以何种形式发布,都必须同时附上源代码。例如在 Web 上提供下载,就必须在二进制版本(如果有的话)下载的同一个页面,清楚地提供源代码下载的链接。如果以光盘形式发布,就必须同时附上源文件的光盘。
4、开发或维护遵循 GPL 协议开发的软件的公司或个人,可以对使用者收取一定的服务费用。但还是一句老话——必须无偿提供软件的完整源代码,不得将源代码与服务做捆绑或任何变相捆绑销售。
2、MySQL历史:
MySQL数据库隶属于MySQL AB公司,总部位于瑞典。
08年被sun公司收购。
09年sun被oracle公司收购。
1、MySQL的历史可以追溯到1979年,一个名为Monty Widenius的程序员在为TcX的小公司打工,并且用BASIC设计了一个报表工具,使其可以在4MHz主频和16KB内存的计算机上运行。当时,这只是一个很底层的且仅面向报表的存储引擎,名叫Unireg。
2、1990年,TcX公司的客户中开始有人要求为他的API提供SQL支持。Monty直接借助于mSQL的代码,将它集成到自己的存储引擎中。令人失望的是,效果并不太令人满意,决心自己重写一个SQL支持。
3、 1996年,MySQL 1.0发布,它只面向一小拨人,相当于内部发布。到了1996年10月,MySQL 3.11.1发布(MySQL没有2.x版本),最开始只提供Solaris下的二进制版本。一个月后,Linux版本出现了。在接下来的两年里,MySQL被依次移植到各个平台。
4、1999~2000年,MySQL AB公司在瑞典成立。Monty雇了几个人与Sleepycat合作,开发出了Berkeley DB引擎, 由于BDB支持事务处理,因此MySQL从此开始支持事务处理了。
5、2000,MySQL不仅公布自己的源代码,并采用GPL(GNU General Public License)许可协议,正式进入开源世界。同年4月,MySQL对旧的存储引擎ISAM进行了整理,将其命名为MyISAM。
6、2001年,集成Heikki Tuuri的存储引擎InnoDB,这个引擎不仅能持事务处理,并且支持行级锁。后来该引擎被证明是最为成功的MySQL事务存储引擎。MySQL与InnoDB的正式结合版本是4.0
7、2003年12月,MySQL 5.0版本发布,提供了视图、存储过程等功能。
8、2008年1月,MySQL AB公司被Sun公司以10亿美金收购,MySQL数据库进入Sun时代。在Sun时代,Sun公司对其进行了大量的推广、优化、Bug修复等工作。
9、2008年11月,MySQL 5.1发布,它提供了分区、事件管理,以及基于行的复制和基于磁盘的NDB集群系统,同时修复了大量的Bug。
10、2009年4月,Oracle公司以74亿美元收购Sun公司,自此MySQL数据库进入Oracle时代,而其第三方的存储引擎InnoDB早在2005年就被Oracle公司收购。
11、2010年12月,MySQL 5.5发布,其主要新特性包括半同步的复制及对SIGNAL/RESIGNAL的异常处理功能的支持,最重要的是InnoDB存储引擎终于变为当前MySQL的默认存储引擎。MySQL 5.5不是时隔两年后的一次简单的版本更新,而是加强了MySQL各个方面在企业级的特性。Oracle公司同时也承诺MySQL 5.5和未来版本仍是采用GPL授权的开源产品。
MySQL 其实是分为 server层 和 引擎层两部分。
- Server 层:它主要做的是 MySQL 功能层面的事情;
- 引擎层:负责存储相关的具体事宜。
3、SQL的优点
1) 功能强大
MySQL 中提供了多种数据库存储引擎,各引擎各有所长,适用于不同的应用场合,用户可以选择最合适的引擎以得到最高性能,可以处理每天访问量超过数亿的高强度的搜索 Web 站点。MySQL5 支持事务、视图、存储过程、触发器等。
2) 支持跨平台
MySQL 支持至少 20 种以上的开发平台,包括 Linux、Windows、FreeBSD 、IBMAIX、AIX、FreeBSD 等。这使得在任何平台下编写的程序都可以进行移植,而不需要对程序做任何的修改。
3) 运行速度快
高速是 MySQL 的显著特性。在 MySQL 中,使用了极快的 B 树磁盘表(MyISAM)和索引压缩;通过使用优化的单扫描多连接,能够极快地实现连接;SQL 函数使用高度优化的类库实现,运行速度极快。
4) 支持面向对象
PHP 支持混合编程方式。编程方式可分为纯粹面向对象、纯粹面向过程、面句对象与面向过程混合 3 种方式。
5) 安全性高
灵活和安全的权限与密码系统,允许基本主机的验证。连接到服务器时,所有的密码传输均采用加密形式,从而保证了密码的安全。
6) 成本低
MySQL 数据库是一种完全免费的产品,用户可以直接通过网络下载。
7) 支持各种开发语言
MySQL 为各种流行的程序设计语言提供支持,为它们提供了很多的 API 函数,包括 PHP、ASP.NET、Java、Eiffel、Python、Ruby、Tcl、C、C++、Perl 语言等。
8) 数据库存储容量大
MySQL 数据库的最大有效表尺寸通常是由操作系统对文件大小的限制决定的,而不是由 MySQL 内部限制决定的。InnoDB 存储引擎将 InnoDB 表保存在一个表空间内,该表空间可由数个文件创建,表空间的最大容量为 64TB,可以轻松处理拥有上千万条记录的大型数据库。
9) 支持强大的内置函数
PHP 中提供了大量内置函数,几乎涵盖了 Web 应用开发中的所有功能。它内置了数据库连接、文件上传等功能,MySQL 支持大量的扩展库,如 MySQLi 等,可以为快速开发 Web 应用提供便利。
4、SQL语言的分类
1、DDL(Data Definition Language) 数据定义语言,用来操作数据库、表、列等; 常用语句:create、alter、drop
2、DML(Data Manipulation Language) 数据操作语言,用来操作数据库中表里的数据;常用语句:insert、update、delete
3、DCL(Data Control Language) 数据控制语言,用来操作访问权限和安全级别; 常用语句:grant、deny
4、DQL(Data Query Language) 数据查询语言,用来查询数据 常用语句:select
5、TCL(Transaction Control Language)事务控制语言。
5、MySQL的语法规范
1、不区分大小写,但建议关键字大写,表名、列名小写
2、每条命令最好用分号结尾(DOS命令行必须,可视化工具最好加分号)。在一些场景下用\g,或者不加也行。
3、每条命令根据需要,可以进行缩进或换行
4、注释:
- 单行注释:#注释文字,
- 单行注释:-- 注释文字
- 多行注释:/* 注释文字*/
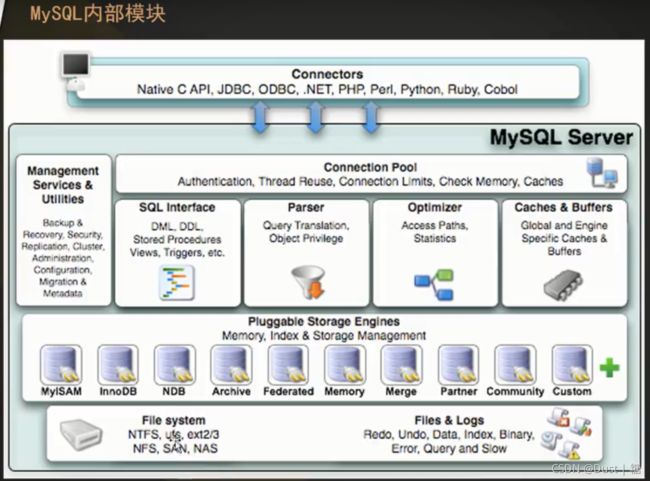
6、MySQL内部模块
和其他数据库相比,MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎的架构上。
插件式的存储引擎架构将查询处理和其它的系统任务以及数据的存储提起相分离 。这种架构可以根据业务的需求和实际需要选择合适的存储引擎。
-
连接层
最上层是一些客户端和连接服务,包含本地sock通信和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
-
服务层
第二层架构主要完成大多少的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化及部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化如确定查询表的顺序,是否利用索引等,最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存。如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
-
引擎层
存储引擎层,存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的时机需要进行选取。主要是MyISAM和InnoDB引擎。
-
存储层
数据存储层,主要是将数据存储在运行与裸设备的文件系统之上,并完成与存储引擎的交互。
7、DB、DBS、DBMS
数据库DB、数据库系统DBS、数据库管理系统DBMS三者关系:
DB:数据库(Database,简称DB)是指:长期储存在计算机内的、有组织的、可共享的大量数据集合。一个应用系统通常包含多个数据库。存取数据的容器。
DBMS:数据库管理系统(Database Management System,简称 DBMS )是位于用户(应用程序)与操作系统之间的一层数据库管理软件,DBMS是独立、开放的数据库管理软件(提供多种外部接口,管理的数据可以被其它外部应用程序调用),用于科学地组织和存储数据以及高效地获取和维护数据。又称为数据库软件(产品),用于管理DB中的数据。
- 基于共享文件系统的DBMS(Access)
- 基于客户机——服务器的DBMS。(MySQL、Oracle、SqlServer)
DBS:数据库系统(Database System,简称DBS)是指在计算机应用系统中引入数据库后的系统构成。数据库系统由数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员(和用户)构成。
SQL:结构化查询语言(Structure Query Language):专门用来与数据库通信的语言。用于和DBMS通信的语言。
所以DBS包含DB和DBMS,DBS的核心是DBMS,对于程序员来讲,DBMS提供了很大的便利,可以更加专注程序本身。DBS与普通软件系统的最大区别在于:普通软件自己管理数据及数据安全,DBS由DBMS帮我们管理数据和安全性。
8、MySQL存储数据时的特点:
- 数据存放到表中,然后表再放到库中。
- 一个库中可以有多张表,每张表具有唯一的表名来标识自己。
- 表中有一个或多个列,列有称为“字段”,相当于java中的“属性”。
- 表中的没一行数据,相当于java中的“对象”。
9、Mysql高手是怎么炼成的:

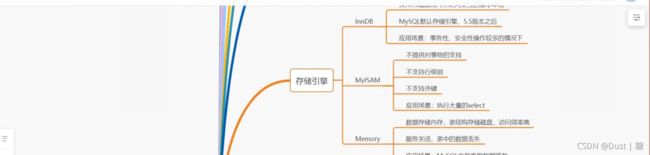
二、Mysql中的数据库引擎
数据库中的存储引擎其实是对使用了该引擎的表进行某种设置,数据库中的表设定了什么存储引擎,那么该表在数据存储方式、数据更新方式、数据查询性能以及是否支持索引等方面就会有不同的“效果”。
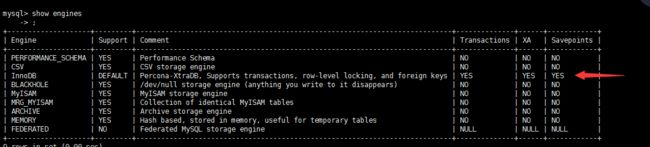
MySQL有以下几种引擎:InnoDB、ISAM、MyISAM、HEAP(也称为MEMORY)、CSV、BLACKHOLE、ARCHIVE、PERFORMANCE_SCHEMA、Berkeley、Merge、Federated和Cluster/NDB等。 除此以外我们也可以参照MySQL++ API创建自己的数据库引擎。

每一张表都可以指定自己的存储引擎,
InnoDB:
该存储引擎为MySQL表提供了ACID事务支持、系统崩溃修复能力和多版本并发控制(即MVCC Multi-Version Concurrency Control)的行级锁;该引擎支持自增长列(auto_increment),自增长列的值不能为空,如果在使用的时候为空则自动从现有值开始增值,如果有但是比现在的还大,则直接保存这个值; 该引擎存储引擎支持外键(foreign key) ,外键所在的表称为子表而所依赖的表称为父表。该引擎在5.5后的MySQL数据库中为默认存储引擎。
1.将数据存储在表空间中,表空间由一系列的数据文件组成,由InnoDB管理;2.支持每个表的数据和索引存放在单独文件中(innodb_file_per_table);3.支持事务,采用MVCC来控制并发,并实现标准的4个事务隔离级别,支持外键;4.索引基于聚簇索引建立,对于主键查询有较高性能;5.数据文件的平台无关性,支持数据在不同的架构平台移植;6.能够通过一些工具支持真正的热备。如XtraBackup等;7.内部进行自身优化如采取可预测性预读,能够自动在内存中创建hash索引等。
ISAM:
该引擎在读取数据方面速度很快,而且不占用大量的内存和存储资源;但是ISAM不支持事务处理、不支持外来键、不能够容错、也不支持索引。该引擎在包括MySQL 5.1及其以上版本的数据库中不再支持。
MyISAM:
该引擎基于ISAM数据库引擎,除了提供ISAM里所没有的索引和字段管理等大量功能,MyISAM还使用一种表格锁定的机制来优化多个并发的读写操作,但是需要经常运行OPTIMIZE TABLE命令,来恢复被更新机制所浪费的空间,否则碎片也会随之增加,最终影响数据访问性能
1.MySQL5.1中默认,不支持事务和行级锁;2.提供大量特性如全文索引、空间函数、压缩、延迟更新等;3.数据库故障后,安全恢复性差;4.对于只读数据可以忍受故障恢复,MyISAM依然非常适用;5.日志服务器的场景也比较适用,只需插入和数据读取操作;6.不支持单表一个文件,会将所有的数据和索引内容分别存在两个文件中;7.MyISAM对整张表加锁而不是对行,所以不适用写操作比较多的场景;8.支持索引缓存不支持数据缓存。
Mrg_MyISAM引擎:
将多个MYISAM表合并为一个。本身并不存储数据,数据存在MyISAM表中间。
Memory(也称HEAP):
该存储引擎通过在内存中创建临时表来存储数据。每个基于该存储引擎的表实际对应一个磁盘文件,该文件的文件名和表名是相同的,类型为.frm。该磁盘文件只存储表的结构,而其数据存储在内存中,所以使用该种引擎的表拥有极高的插入、更新和查询效率。这种存储引擎默认使用哈希(HASH)索引,其速度比使用B-+Tree型要快,但也可以使用B树型索引。由于这种存储引擎所存储的数据保存在内存中,所以其保存的数据具有不稳定性,比如如果mysqld进程发生异常、重启或计算机关机等等都会造成这些数据的消失,所以这种存储引擎中的表的生命周期很短,一般只使用一次。
将数据在内存中缓存,不消耗IO。存储数据速度较快但不会被保留,一般作为临时表的存储被使用。
如果需要快速地访问数据,并且这些数据不会被修改,重启以后丢失也没有关系,那么使用Menory表时非常有用。Memory表至少比MyISAM表至少比MyISAM表要快一个数量级。
CSV:
(Comma-Separated Values逗号分隔值)
使用该引擎的MySQL数据库表会在MySQL安装目录data文件夹中的和该表所在数据库名相同的目录中生成一个.CSV文件(所以,它可以将CSV类型的文件当做表进行处理),这种文件是一种普通文本文件,每个数据行占用一个文本行。该种类型的存储引擎不支持索引,即使用该种类型的表没有主键列;另外也不允许表中的字段为null。
可以打开CSV文件存储的数据,可以将存储的数据导出,并利用excel打开。可以作为一种数据交换的机制使用。
CSV引擎可以将普通的CSV文件作为MySQL的表来处理,但不支持索引。
CSV引擎可以作为一种数据交换的机制,非常有用。
CSV存储的数据直接可以在操作系统里,用文本编辑器,或者execl读取。
CSV文件格式:
![]()
BLACKHOLE(黑洞引擎):
该存储引擎支持事务,而且支持mvcc的行级锁,写入这种引擎表中的任何数据都会消失,主要用于做日志记录(二进制日志)或同步归档的中继存储,会在一些特殊需要的复制架构的环境中使用。
Blackhole引擎没有实现任何存储机制,它会丢弃所有插入的数据,不做任何保存。但服务器会记录Blackhole表的记录,所以可以用于复制数据到备库,或者简单地记录到日志。但这种应用会碰到很多问题,因此并不推荐。
Archive:
该存储引擎适合存储大量独立的、作为历史记录的数据。
1.只支持insert和select操作;
2.缓存所有的写数据并进行压缩存储,支持行级锁但不支持事务;
3.适合高速插入和数据压缩,减少IO操作,适用于日志记录和归档服务器。
4.不支持索引,所以查询性能较差一些。
在MySQL5.1之前不支持索引。Archive表适合日志和数据采集类应用。
根据英文的结论来看,Archive表比MyISAM表要小大学75%,比支持事务处理的InnoDB表小大约83%。
PERFORMANCE_SCHEMA:
performance_schema
该引擎主要用于收集数据库服务器性能参数。这种引擎提供以下功能:提供进程等待的详细信息,包括锁、互斥变量、文件信息;保存历史的事件汇总信息,为提供MySQL服务器性能做出详细的判断;对于新增和删除监控事件点都非常容易,并可以随意改变mysql服务器的监控周期,例如(CYCLE、MICROSECOND)。
Berkeley(BDB):
该存储引擎支持COMMIT和ROLLBACK等其他事务特性。该引擎在包括MySQL 5.1及其以上版本的数据库中不再支持。
Merge:
该引擎将一定数量的MyISAM表联合而成一个整体。
Merge存储引擎允许将一组使用MyISAM存储引擎的并且表结构相同(即每张表的字段顺序、字段名称、字段类型、索引定义的顺序及其定义的方式必须相同)的数据表合并为一个表,方便了数据的查询。
Federated:
该存储引擎可以不同的Mysql服务器联合起来,逻辑上组成一个完整的数据库。这种存储引擎非常适合数据库分布式应用。
比如:跨库的连表查询。
Federated引擎是访问其他MySQL服务器的一个代理,尽管改引擎看起来提供了一种很好的跨服务器的灵活性,但也经常带来问题,因此默认是禁用的。
Cluster/NDB:
该存储引擎用于多台数据机器联合提供服务以提高整体性能和安全性。适合数据量大、安全和性能要求高的场景。
MySQL Cluster专用。
阿里巴巴和淘宝的引擎:
| 产品 | 价格 | 目标 | 主要功能 | 是否可投入生产? |
|---|---|---|---|---|
| Percona Server | 免费 | 提供XtraDB存储引擎的包装器和其他分析工具 | XtraDB | 是 |
| MariaDB | 免费 | 扩展MySQL以包含XtraDB和其他性能改进 | MariaDB | 是 |
| Drizzle | 免费 | 提供MySQL更强大的可扩展性和性能改进 | 高可用性 | 是 |
Percona为MySQL数据库服务器进行了改进,在功能和性能上较MySQL有着很显著的提升。该版本提升了在高负载情况下的InnoDB的性能、为DBA提供一些非常有用的性能诊断工具:另外有更多的参数和命令来控制服务器行为。
该公司新建了一款存储引擎叫xtradb完全可以替代innodb,并且在性能和并发上做的更好。
阿里巴巴大部分mysql数据库其实使用的percona的原型加以修改。
AliSql+AliRedis。
Percona 数据库
Percona 数据库
Percona介绍
Percona Server由领先的MySQL咨询公司Percona发布。 Percona Server是一款独立的数据库产品,其可以完全与MySQL兼容,可以在不更改代码的情况了下将存储引擎更换成XtraDB 。
Percona团队的最终声明是“Percona Server是由Oracle发布的最接近官方MySQL Enterprise发行版的版本”,因此与其他更改了大量基本核心MySQL代码的分支有所区别。 Percona Server的一个缺点是他们自己管理代码,不接受外部开发人员的贡献,以这种方式确保他们对产品中所包含功能的控制。
Percona提供了高性能XtraDB引擎,还提供PXC高可用解决方案,并且附带了perconatoolkit等DBA管理工具箱
Percona 安装
#首先安装yum源
yum -y install https://www.percona.com/redir/downloads/percona-release/redhat/latest/percona-release-0.1-6.noarch.rpm
#安装percona server
yum install -y Percona-Server-server-57
#查看/etc/my.cnf的配置信息:
!includedir /etc/my.cnf.d/
!includedir /etc/percona-server.conf.d/
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
#初始化数据库:
mysqld --initialize --user=mysql
#启动数据库
service mysqld start
#查看mysql进程
ps –ef|grep mysql
#获取root初始化密码:
在/var/log/mysqld.log中所有password关键词,获取初始化密码:
![]()
#修改root 密码
Percona 操作跟mysql 一模一样 命令也是一样
Percona存储引擎
Percona XtraDB 是 InnoDB 存储引擎的增强版,被设计用来更好的使用更新计算机硬件系统的性能,同时还包含有一些在高性能环境下的新特性。 XtraDB 存储引擎是完全的向下兼容,在 MariaDB 中, XtraDB 存储引擎被标识为”ENGINE=InnoDB”,这个与 InnoDB 是一样的,所以你可以直接用XtraDB 替换掉 InnoDB而不会产生任何问题。 Percona XtraDB 包含有所有 InnoDB’s 健壮性,可依赖的 ACID 兼容设计和高级MVCC 架构。 XtraDB 在InnoDB 的坚实基础上构建,使 XtraDB 具有更多的特性,更好调用,更多的参数指标和更多的扩展。从实践的角度来看, XtraDB 被设计用来在多核心的条件下更有效的使用内存和更加方便,更加可用。新的特性被用来降低 InnoDB 的局限性。性能层面, XtraDB与内置的MySQL 5.1 InnoDB引擎相比,它每分钟可处理2.7倍的事务。
这是以前的数据对比, 现在新版mysql 5.7.x 或者 mysql 8.x 的 Innodb 对比 ,处理已近差不多了。
Percona高可用架构
• MHA
• MMM
• ATLAS
• MyCAT
其配置方法也和MySQL一样
Percona XtraDB Cluster (PXC)架构
Percona XtraDB Cluster是MySQL高可用性和可扩展性的解决方案.
Percona XtraDB Cluster提供的特性有
1.同步复制,事务要么在所有节点提交或不提交。`
2.多主复制,可以在任意节点进行写操作。`
3.在从服务器上并行应用事件,真正意义上的并行复制。`
4.节点自动配置。`
5.数据一致性,不再是异步复制。
Percona XtraDB Cluster完全兼容MySQL和Percona Server,表现在:
- 数据的兼容性
- 应用程序的兼容性:无需更改应用程序 。
集群是有节点组成的,推荐配置至少3个节点,但是也可以运行在2个节点上。 每个节点都是普通的mysql/percona服务器,可以将现有的数据库服务器组成集群,
从PXC机器群可以拆分成单独的服务器。 - 每个节点都包含完整的数据副本。
PXC 优缺点
优点如下:
1.当执行一个查询时,在本地节点上执行。因为所有数据都在本地,无需远程访问。
2.无需集中管理。可以在任何时间点失去任何节点,但是集群将照常工作。
3.良好的读负载扩展,任意节点都可以查询。
缺点如下:
1.加入新节点,开销大。需要复制完整的数据
2.不能有效的解决写缩放问题,所有的写操作都将发生在所有节点上。
3.有多少个节点就有多少重复的数据
Percona XtraDB Cluster基于XtraDB的Percona Server以及包含写复制集补丁。 使用Galera 2.x library,事务型应用下的通用的多主同步复制插件。
Percona XtraDB Cluster 搭建
3个节点环境
| 主机名 | ip | 数据库版本 |
|---|---|---|
| percona1 | 10.0.0.130 | percona 5.7.23 |
| percona2 | 10.0.0.131 | percona 5.7.23 |
| percona3 | 10.0.0.132 | percona 5.7.23 |
#关闭了selinux ,防火墙
#各节点做好host解析
/etc/hosts 中添加
10.0.0.130 percona1
10.0.0.131 percona2
10.0.0.132 percona3
#每个节点删除原本安装的percona server软件:
yum erase -y Percona-Server-server-57
yum erase -y Percona-Server-client-57
#每个节点安装软件:
yum install -y Percona-XtraDB-Cluster-57
在log文件中找到root的临时密码:
每个节点修改root密码:我这省略
配置各个节点的/etc/percona-xtradb-cluster.conf.d/wsrep.cnf文件:
第一个节点percona1

[mysqld]
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
wsrep_cluster_address=gcomm://10.0.0.130,10.0.0.131,10.0.0.132
binlog_format=ROW
default_storage_engine=InnoDB
wsrep_slave_threads= 8
wsrep_log_conflicts
innodb_autoinc_lock_mode=2
wsrep_node_address=10.0.0.130
wsrep_cluster_name=pxc-cluster
wsrep_node_name=percona1
pxc_strict_mode=ENFORCING
wsrep_sst_method=rsync
#第一个节点启动必须用下面这种方式:
systemctl start mysql@bootstrap.service
第二个节点
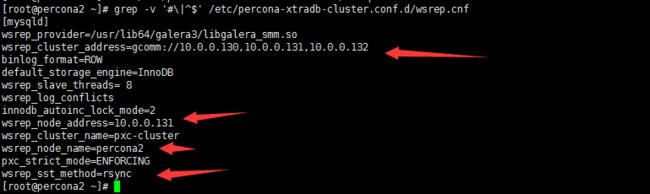
[mysqld]
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
wsrep_cluster_address=gcomm://10.0.0.130,10.0.0.131,10.0.0.132
binlog_format=ROW
default_storage_engine=InnoDB
wsrep_slave_threads= 8
wsrep_log_conflicts
innodb_autoinc_lock_mode=2
wsrep_node_address=10.0.0.131
wsrep_cluster_name=pxc-cluster
wsrep_node_name=percona2
pxc_strict_mode=ENFORCING
wsrep_sst_method=rsync
#其他节点启动percona
service mysql start
第三个节点

[mysqld]
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
wsrep_cluster_address=gcomm://10.0.0.130,10.0.0.131,10.0.0.132
binlog_format=ROW
default_storage_engine=InnoDB
wsrep_slave_threads= 8
wsrep_log_conflicts
innodb_autoinc_lock_mode=2
wsrep_node_address=10.0.0.132
wsrep_cluster_name=pxc-cluster
wsrep_node_name=percona3
pxc_strict_mode=ENFORCING
wsrep_sst_method=rsync
#第三个节点启动
service mysql start
#查看所有的的pxc的状态
show status like 'wsrep_%';

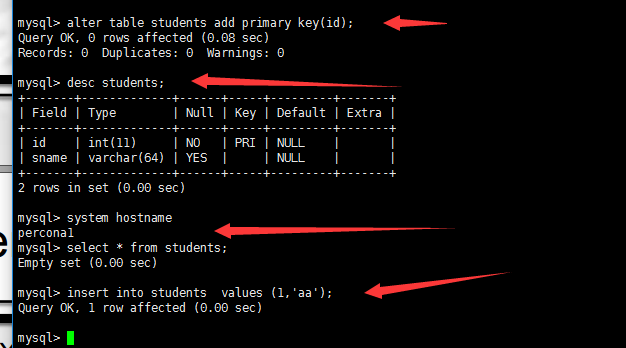
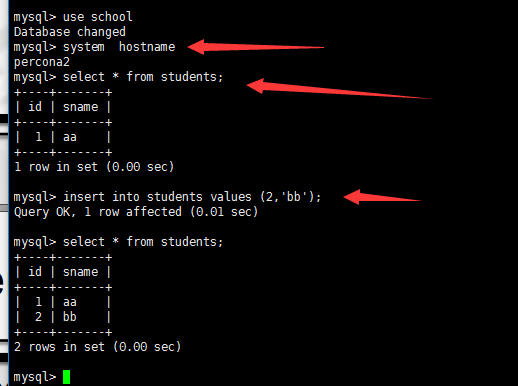
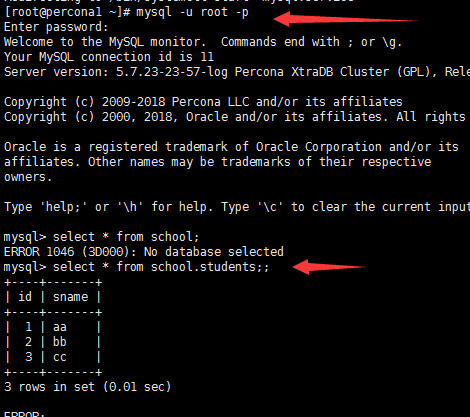
两个节点上分别插入数据测试:
第一个节点:
第二个节点:
关闭第一个节点,对外操作的也没影响 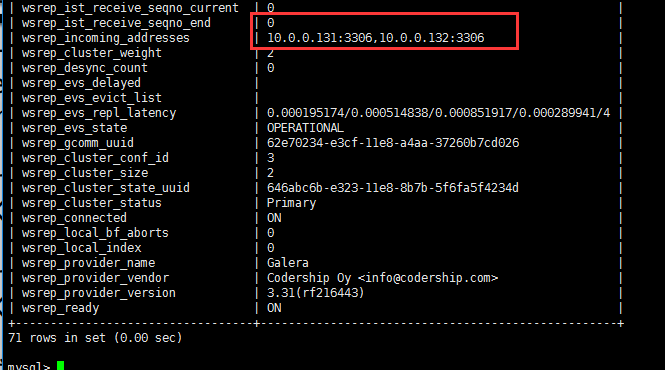
恢复第一节点
其他节点插入数据,

第一节点恢复启动,数据也是同步的
MyISAM与InnoDB 的区别:
MyISAM:只支持表级锁(table-level locking);
InnoDB:既支持行级锁(row-level locking),也支持表级锁;默认行级锁。
InnoDB和MyISAM的最大不用有两点:一是支持事务、二是innodb采用行级锁 MyISAM采用表级锁。
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 主外键 | 不支持 | 不支持 |
| 事务 | 不支持 | 不支持 |
| 行表锁 | 表锁,即使操作一条记录也会锁住整个表,不适合高并发的操作 | 行锁,操作时只锁某一行,不对其他行有影响,适合高并发的操作。 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引还要缓存真实数据,对内存要求较高,而且内存大小对性能有决定性的影响。 |
| 关注点 | 性能 | 事务 |
| 默认安装 | Y | Y |
-
InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
-
InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
-
InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。
MyISAM是非聚集索引,也是使用B+Tree作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
也就是说:InnoDB的B+树主键索引的叶子节点就是数据文件,辅助索引的叶子节点是主键的值;而MyISAM的B+树主键索引和辅助索引的叶子节点都是数据文件的地址指针。


4. InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快(注意不能加有任何WHERE条件);
那么为什么InnoDB没有了这个变量呢?
因为InnoDB的事务特性,在同一时刻表中的行数对于不同的事务而言是不一样的,因此count统计会计算对于当前事务而言可以统计到的行数,而不是将总行数储存起来方便快速查询。InnoDB会尝试遍历一个尽可能小的索引除非优化器提示使用别的索引。如果二级索引不存在,InnoDB还会尝试去遍历其他聚簇索引。
如果索引并没有完全处于InnoDB维护的缓冲区(Buffer Pool)中,count操作会比较费时。可以建立一个记录总行数的表并让你的程序在INSERT/DELETE时更新对应的数据。和上面提到的问题一样,如果此时存在多个事务的话这种方案也不太好用。如果得到大致的行数值已经足够满足需求可以尝试SHOW TABLE STATUS
-
Innodb不支持全文索引,而MyISAM支持全文索引,在涉及全文索引领域的查询效率上MyISAM速度更快高;PS:5.7以后的InnoDB支持全文索引了
-
MyISAM表格可以被压缩后进行查询操作
-
InnoDB支持表、行(默认)级锁,而MyISAM支持表级锁
InnoDB的行锁是实现在索引上的,而不是锁在物理行记录上。潜台词是,如果访问没有命中索引,也无法使用行锁,将要退化为表锁。
例如:
t_user(uid, uname, age, sex) innodb;
uid PK
无其他索引
update t_user set age=10 where uid=1; 命中索引,行锁。
update t_user set age=10 where uid != 1; 未命中索引,表锁。
update t_user set age=10 where name='chackca'; 无索引,表锁。
-
InnoDB表必须有唯一索引(如主键)(用户没有指定的话会自己找/生产一个隐藏列Row_id来充当默认主键),而Myisam可以没有
-
Innodb存储文件有frm、ibd,而Myisam是frm、MYD、MYI
Innodb:frm是表定义文件,ibd是数据文件
Myisam:frm是表定义文件,myd是数据文件,myi是索引文件
两者如何选择:
1、是否要支持事务,如果要请选择innodb,如果不需要可以考虑MyISAM;
2、如果表中绝大多数都只是读查询,可以考虑MyISAM,如果既有读也有写,请使用InnoDB。
3、系统奔溃后,MyISAM恢复起来更困难,能否接受;
4、 MySQL5.5版本开始Innodb已经成为Mysql的默认引擎(之前是MyISAM),说明其优势是有目共睹的,如果你不知道用什么,那就用InnoDB,至少不会差。
InnoDB为什么推荐使用自增ID作为主键?
答:自增ID可以保证每次插入时B+索引是从右边扩展的,可以避免B+树和频繁合并和分裂(对比使用UUID)。如果使用字符串主键和随机主键,会使得数据随机插入,效率比较差。
InnoDB的索引实现,InnoDB使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)。
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。如下图所示:
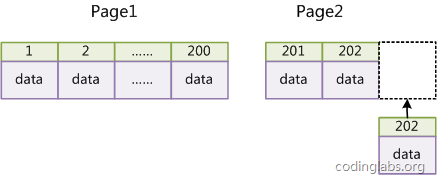
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置:

此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
因此,只要可以,请尽量在InnoDB上采用自增字段做主键。
UUID:
UUID是Universally Unique Identifier的缩写,它是在一定的范围内(从特定的名字空间到全球)唯一的机器生成的标识符。
由于 UUID 是全局唯一的,重复 UUID 的概率接近零,可以忽略不计。所以 Java 的 UUID 通常可用于以下地方:
- 随机生成的文件名;
- Java Web 应用程序的 sessionID;
- 数据库表的主键;
- 事务 ID(UUID 生成算法非常高效,每台计算机每秒高达 1000 万次)。
M 表示 UUID 的版本,N 为 UUID 的变体(Variants)。
M 的值有 5 个可选项:
-
版本 1:UUID 是根据时间和 MAC 地址生成的;
-
版本 2:UUID 是根据标识符(通常是组或用户 ID)、时间和节点 ID生成的;
-
版本 3:UUID 是通过散列(MD5 作为散列算法)名字空间(namespace)标识符和名称生成的;
-
版本 4 - UUID 使用随机性或伪随机性生成;
-
版本 5 类似于版本 3(SHA1 作为散列算法)。
为了能兼容过去的 UUID,以及应对未来的变化,因此有了变体(Variants)这一概念。
目前已知的变体有下面 4 种:
-
变体 0:格式为 0xxx,为了向后兼容预留。
-
变体 1:格式为 10xx,当前正在使用的。
-
变体 2:格式为 11xx,为早期微软的 GUID 预留。
-
变体 3:格式为 111x,为将来的扩展预留,目前暂未使用。
在 Java 中,就有一个叫 UUID 的类,在java.util包下。
package java.util;
public final class UUID implements java.io.Serializable, Comparable<UUID> {
}
该类只有一个构造方法:
public UUID(long mostSigBits, long leastSigBits) {
this.mostSigBits = mostSigBits;
this.leastSigBits = leastSigBits;
}
要使用构造方法创建 UUID 对象的话,就需要传递两个参数,long 型的最高位 UUID 和最低位的 UUID。
long msb = System.currentTimeMillis();
long lsb = System.currentTimeMillis();
UUID uuidConstructor = new UUID(msb, lsb);
System.out.println("UUID : "+uuidConstructor);
输出结果如下所示:
UUID : 00000173-8efd-1b7c-0000-01738efd1b7c
UUID 类提供了一个静态方法 randomUUID() :
public static UUID randomUUID() {
SecureRandom ng = UUID.Holder.numberGenerator;
byte[] randomBytes = new byte[16];
ng.nextBytes(randomBytes);
randomBytes[6] &= 0x0f; /* clear version */
randomBytes[6] |= 0x40; /* set to version 4 */
randomBytes[8] &= 0x3f; /* clear variant */
randomBytes[8] |= 0x80; /* set to IETF variant */
return new UUID(randomBytes);
}
randomUUID() 方法生成了一个版本 4 的 UUID,这也是生成 UUID 最方便的方法。如果只使用原生 JDK 的话,基本上都用的这种方式。 示例如下:
UUID uuid4 = UUID.randomUUID();
int version4 = uuid4.version();
System.out.println("UUID:"+ uuid4+" 版本 " + version4);
程序输出结果如下所示:
UUID:8c943921-d83e-424a-a627-a12d3cb474db 版本 4
除此之外,UUID 类还提供了另外两个静态方法,其一是nameUUIDFromBytes():
public static UUID nameUUIDFromBytes(byte[] name) {
MessageDigest md;
try {
md = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException nsae) {
throw new InternalError("MD5 not supported", nsae);
}
byte[] md5Bytes = md.digest(name);
md5Bytes[6] &= 0x0f; /* clear version */
md5Bytes[6] |= 0x30; /* set to version 3 */
md5Bytes[8] &= 0x3f; /* clear variant */
md5Bytes[8] |= 0x80; /* set to IETF variant */
return new UUID(md5Bytes);
}
nameUUIDFromBytes()会生成一个版本 3 的 UUID,不过需要传递一个名称的字节数组作为参数。
示例如下:
UUID uuid3 = UUID.nameUUIDFromBytes("test".getBytes());
int version3 = uuid3.version();
System.out.println("UUID:"+ uuid3+" 版本 " + version3);
程序输出结果如下所示:
UUID:098f6bcd-4621-3373-8ade-4e832627b4f6 版本 3
其二是 fromString() :
public static UUID fromString(String name) {
int len = name.length();
if (len > 36) {
throw new IllegalArgumentException("UUID string too large");
}
int dash1 = name.indexOf('-', 0);
int dash2 = name.indexOf('-', dash1 + 1);
int dash3 = name.indexOf('-', dash2 + 1);
int dash4 = name.indexOf('-', dash3 + 1);
int dash5 = name.indexOf('-', dash4 + 1);
// For any valid input, dash1 through dash4 will be positive and dash5
// negative, but it's enough to check dash4 and dash5:
// - if dash1 is -1, dash4 will be -1
// - if dash1 is positive but dash2 is -1, dash4 will be -1
// - if dash1 and dash2 is positive, dash3 will be -1, dash4 will be
// positive, but so will dash5
if (dash4 < 0 || dash5 >= 0) {
throw new IllegalArgumentException("Invalid UUID string: " + name);
}
long mostSigBits = Long.parseLong(name, 0, dash1, 16) & 0xffffffffL;
mostSigBits <<= 16;
mostSigBits |= Long.parseLong(name, dash1 + 1, dash2, 16) & 0xffffL;
mostSigBits <<= 16;
mostSigBits |= Long.parseLong(name, dash2 + 1, dash3, 16) & 0xffffL;
long leastSigBits = Long.parseLong(name, dash3 + 1, dash4, 16) & 0xffffL;
leastSigBits <<= 48;
leastSigBits |= Long.parseLong(name, dash4 + 1, len, 16) & 0xffffffffffffL;
return new UUID(mostSigBits, leastSigBits);
}
fromString() 方法会生成一个基于指定 UUID 字符串的 UUID 对象,如果指定的 UUID 字符串不符合 UUID 的格式,将抛出 IllegalArgumentException 异常。
示例如下:
UUID uuid = UUID.fromString("38400000-8cf0-11bd-b23e-10b96e4ef00d");
int version = uuid.version();
System.out.println("UUID:"+ uuid+" 版本 " + version);
程序输出结果如下所示:
UUID:38400000-8cf0-11bd-b23e-10b96e4ef00d 版本 1
除了使用 JDK 原生的 API 之外,还可以使用com.fasterxml.uuid.Generators,需要先在项目中加入该类的 Maven 依赖。
<dependency>
<groupId>com.fasterxml.uuid</groupId>
<artifactId>java-uuid-generator</artifactId>
<version>3.1.4</version>
</dependency>
然后我们来看一下如何使用它:
/**
* @author 沉默王二,一枚有趣的程序员
*/
public class UUIDVersionExample {
public static void main(String[] args) {
UUID uuid1 = Generators.timeBasedGenerator().generate();
System.out.println("UUID : "+uuid1);
System.out.println("UUID 版本 : "+uuid1.version());
UUID uuid2 = Generators.randomBasedGenerator().generate();
System.out.println("UUID : "+uuid2);
System.out.println("UUID 版本 : "+uuid2.version());
}
}
Generators.timeBasedGenerator().generate()可用于生成版本 1 的 UUID,Generators.randomBasedGenerator().generate()可用于生成版本 4 的 UUID。
来看一下输出结果:
UUID : ebee82f5-cfd2-11ea-82a7-8536e13d4951
UUID 版本 : 1
UUID : d2ccc752-c824-4bbc-8cc7-52c8246bbc6a
UUID 版本 : 4
UUID具有以下涵义:
- 经由一定的算法机器生成
为了保证UUID的唯一性,规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,以及从这些元素生成UUID的算法。UUID的复杂特性在保证了其唯一性的同时,意味着只能由计算机生成。
- 非人工指定,非人工识别
UUID是不能人工指定的,除非你冒着UUID重复的风险。UUID的复杂性决定了“一般人“不能直接从一个UUID知道哪个对象和它关联。
- 在特定的范围内重复的可能性极小
UUID的生成规范定义的算法主要目的就是要保证其唯一性。但这个唯一性是有限的,只在特定的范围内才能得到保证,这和UUID的类型有关(参见UUID的版本)。
UUID是16字节128位长的数字,通常以36字节的字符串表示,示例如下:
3F2504E0-4F89-11D3-9A0C-0305E82C3301
其中的字母是16进制表示,大小写无关。
Universally Unique IDentifier(UUID),有着正儿八经的[RFC规范](http://www.ietf.org/rfc/rfc4122.txt),是一个128bit的数字,也可以表现为32个16进制的字符,中间用”-”分割。
\- 时间戳+UUID版本号,分三段占16个字符(60bit+4bit),
\- Clock Sequence号与保留字段,占4个字符(13bit+3bit),
\- 节点标识占12个字符(48bit),
GUID(Globally Unique Identifier)是UUID的别名;但在实际应用中,GUID通常是指微软实现的UUID。
UUID Version 1:基于时间的UUID
因为时间戳有满满的60bit,所以可以尽情花,以100纳秒为1,从1582年10月15日算起(能撑3655年,真是位数多给烧的,1582年有意思么)
节点标识也有48bit,一般用MAC地址表达,如果有多块网卡就随便用一块。如果没网卡,就用随机数凑数,或者拿一堆尽量多的其他的信息,比如主机名什么的,拼在一起再hash一把。
顺序号这16bit则仅用于避免前面的节点标示改变(如网卡改了),时钟系统出问题(如重启后时钟快了慢了),让它随机一下避免重复。
但好像Version 1就没考虑过一台机器上起了两个进程这类的问题,也没考虑相同时间戳的并发问题,所以严格的Version1没人实现,接着往下看各个变种吧。
Version1变种 – Hibernate
Hibernate的CustomVersionOneStrategy.java,解决了之前version 1的两个问题
- 时间戳(6bytes, 48bit):毫秒级别的,从1970年算起,能撑8925年….
- 顺序号(2bytes, 16bit, 最大值65535): 没有时间戳过了一秒要归零的事,各搞各的,short溢出到了负数就归0。
- 机器标识(4bytes 32bit): 拿localHost的IP地址,IPV4呢正好4个byte,但如果是IPV6要16个bytes,就只拿前4个byte。
- 进程标识(4bytes 32bit): 用当前时间戳右移8位再取整数应付,不信两条线程会同时启动。
值得留意就是,机器进程和进程标识组成的64bit Long几乎不变,只变动另一个Long就够了。
Version1变种 – MongoDB
MongoDB的ObjectId.java- 时间戳(4 bytes 32bit): 是秒级别的,从1970年算起,能撑136年。
- 自增序列(3bytes 24bit, 最大值一千六百万): 是一个从随机数开始(机智)的Int不断加一,也没有时间戳过了一秒要归零的事,各搞各的。因为只有3bytes,所以一个4bytes的Int还要截一下后3bytes。
- 机器标识(3bytes 24bit): 将所有网卡的Mac地址拼在一起做个HashCode,同样一个int还要截一下后3bytes。搞不到网卡就用随机数混过去。
- 进程标识(2bytes 16bits):从JMX里搞回来到进程号,搞不到就用进程名的hash或者随机数混过去。
可见,MongoDB的每一个字段设计都比Hibernate的更合理一点,比如时间戳是秒级别的。总长度也降到了12 bytes 96bit,但如果果用64bit长的Long来保存有点不上不下的,只能表达成byte数组或16进制字符串。
另外对Java版的driver在自增序列那里好像有bug。
Twitter的snowflake派号器
snowflake也是一个派号器,基于Thrift的服务,不过不是用redis简单自增,而是类似UUID version1,
只有一个Long 64bit的长度,所以IdWorker紧巴巴的分配成:- 时间戳(42bit) 自从2012年以来(比那些从1970年算起的会过日子)的毫秒数,能撑139年。
- 自增序列(12bit,最大值4096), 毫秒之内的自增,过了一毫秒会重新置0。
- DataCenter ID (5 bit, 最大值32),配置值。
- Worker ID ( 5 bit, 最大值32),配置值,因为是派号器的id,所以一个数据中心里最多32个派号器就够了,还会在ZK里做下注册。
可见,因为是派号器,把机器标识和进程标识都省出来了,所以能够只用一个Long表达。
另外,这种派号器,client每次只能一个ID,不能批量取,所以额外增加的延时是问题。
UUID Version 2:DCE安全的UUID
DCE(Distributed Computing Environment)安全的UUID和基于时间的UUID算法相同,但会把时间戳的前4位置换为POSIX的UID或GID。这个版本的UUID在实际中较少用到。
UUID Version 3:基于名字的UUID(MD5)
基于名字的UUID通过计算名字和名字空间的MD5散列值得到。这个版本的UUID保证了:相同名字空间中不同名字生成的UUID的唯一性;不同名字空间中的UUID的唯一性;相同名字空间中相同名字的UUID重复生成是相同的。
UUID Version 4:随机UUID
根据随机数,或者伪随机数生成UUID。这种UUID产生重复的概率是可以计算出来的,但随机的东西就像是买彩票:你指望它发财是不可能的,但狗屎运通常会在不经意中到来。
UUID Version 5:基于名字的UUID(SHA1)
和版本3的UUID算法类似,只是散列值计算使用SHA1(Secure Hash Algorithm 1)算法。
UUID的应用
从UUID的不同版本可以看出,Version 1/2适合应用于分布式计算环境下,具有高度的唯一性;Version 3/5适合于一定范围内名字唯一,且需要或可能会重复生成UUID的环境下;至于Version 4,我个人的建议是最好不用(虽然它是最简单最方便的)。
通常我们建议使用UUID来标识对象或持久化数据,但以下情况最好不使用UUID:
- 映射类型的对象。比如只有代码及名称的代码表。
- 人工维护的非系统生成对象。比如系统中的部分基础数据。
对于具有名称不可重复的自然特性的对象,最好使用Version 3/5的UUID。比如系统中的用户。如果用户的UUID是Version 1的,如果你不小心删除了再重建用户,你会发现人还是那个人,用户已经不是那个用户了。(虽然标记为删除状态也是一种解决方案,但会带来实现上的复杂性。)
UUID生成器
我没想着有人看完了这篇文章就去自己实现一个UUID生成器,所以前面的内容并不涉及算法的细节。下面是一些可用的Java UUID生成器:
- Java UUID Generator (JUG):开源UUID生成器,LGPL协议,支持MAC地址。
- UUID:特殊的License,有源码。
- Java 5以上版本中自带的UUID生成器:好像只能生成Version 3/4的UUID。
此外,Hibernate中也有一个UUID生成器,但是,生成的不是任何一个(规范)版本的UUID,强烈不建议使用。
UUID生成方法:
Shell、libuuid、boost uuid、Qt QUuid、CoCreateGuid、
Shell:
- Unix/Linux环境中大都有一个名为uuidgen的小工具,运行即可生成一个UUID到标准输出
- 读取文件
/proc/sys/kernel/random/uuid即得UUID,例如:
cat /proc/sys/kernel/random/uuid
libuuid:
libuuid是一个用于生成UUID的C库,具体用法参考http://linux.die.net/man/3/libuuid,示例如下:
#include <stdio.h>
#include <uuid/uuid.h>
int main(int argc, char **argv)
{
uuid_t uuid;
char str[36];
uuid_generate(uuid);
uuid_unparse(uuid, str);
printf("%s\n", str);
return 0;
}
```sql
在Linux下编译时需要链接uuid库
```sql
gcc -o uuid uuid.c -luuid
在Ubuntu中,可以用下面的命令安装libuuid:
sudo apt-get install uuid-dev
boost uuid:
Boost库是一个可移植的开源C++库,它提供了UUID的实现。
下面的代码可以生成一个UUID
#include Qt QUuid:
Qt是一个跨平台的C++编程框架,QUuid类实现了UUID的生成、比较、转换等功能。
函数QUuid createUuid();可用于生成一个随即UUID。示例如下
#include
#include
#include
int main()
{
QUuid uuid = QUuid::createUuid();
std::cout << qPrintable(uuid.toString()) << std::endl;
return 0;
}
CoCreateGuid:
Windows下提供了函数CoCreateGuid用于生成GUID。需要使用的头文件是”objbase.h”,需要链接的库是ole32.lib,函数原型为:
HRESULT CoCreateGuid(GUID *pguid);
GUID的原型为 :
typedef struct _GUID
{
DWORD Data1;
WORD Data2;
WORD Data3;
BYTE Data4[8];
} GUID;
Java
JDK 1.5以上支持UUID,用法如下:
import java.util.UUID;
String uuid = UUID.randomUUID().toString();
innodb引擎的4大特性:
插入缓冲(insert buffer),
二次写(double write),
自适应哈希索引(ahi),
预读(read ahead)
插入缓冲:(insert buffer)
Insert Buffer
Insert Buffer 可能是 InnoDB 存储引擎关键特性中最令人激动与兴奋的一个功能。不过这个名字可能会让人认为插入缓冲是缓冲池中的一个组成部分。其实不然, InnoDB 缓冲池中有 Insert Buffer 信息固然不错,但是 Insert Buffer和数据页一样,也是物理页的一个组成部分。
在 InnoDB 存储引擎中,主键是行唯一的标识符。通常应用程序中行记录的插入顺序是按照主键递增的顺序进行插入的。因此,插入聚集索引( Primary Key )一般是顺序的,不需要磁盘的随机读取。比如按下列 SQL 定义表:
CREATE TABLE t (
a INT AUTO INCREMENT ,
b VARCHAR(30) ,
PRIMARY KEY ( a )
);
其中 a 列是自增长的,若对 a 列插入 NULL 值,则由于其具有 AUTO INCREMENT 属性,其值会自动增长。同时页中的行记录按 a 的值进行顺序存放。在一般情况下,不需要随机读取另一个页中的记录。因此,对于这类情况下的插入操作,速度是非常快的。注意并不是所有的主键插入都是顺序的。若主键类是 UUID 这样的类,那么插入和辅助索引一样,同样是随机的。即使主键是自增类型,但是插入的是指定的值,而不是 NULL 值,那么同样可能导致插入并非连续的情况。
但是不可能每张表上只有一个聚集索引,更多情况下,一张表上有多个非聚集的辅助索引( secondary index )。比如,用户需要按照 b 这个字段进行查找,并且 b 这个字段不是唯一的,即表是按如下的 SQL 语句定义的:
CREATE TABLE t (
a INT AUTO INCREMENT ,
b VARCHAR ( 30 ) ,
PRIMARY KEY ( a ) ,
key ( b )
);
在这样的情况下产生了一个非聚集的且不是唯一的索引。在进行插入操作时,数据页的存放还是按主键 a 进行顺序存放的,但是对于非聚集索引叶子节点的插入不再是顺序的了,这时就需要离散地访问非聚集索引页,由于随机读取的存在而导致了插入操作性能下降。当然这并不是这个 b 字段上索引的错误,而是因为 B+树的特性决定了非聚集索引插入的离散性。
需要注意的是,在某些情况下,辅助索引的插入依然是顺序的,或者说是比较顺序的,比如用户购买表中的时间字段。在通常情况下,用户购买时间是一个辅助索引,用来根据时间条件进行查询。但是在插入时却是根据时间的递增而插入的,因此插入也是“较为”顺序的。
InnoDB 存储引擎开创性地设计了 Insert Buffer ,对于非聚集索引的插入或更新操作,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,若在,则直接插入;若不在,则先放入到一个 Insert Buffer 对象中,好似欺骗。数据库这个非聚集的索引已经插到叶子节点,而实际并没有,只是存放在另一个位置。然后再以一定的频率和情况进行 Insert Buffer 和辅助索引页子节点的 merge(合并)操作,这时通常能将多个插入合并到一个操作中(因为在一个索引页中),这就大大提高了对于非聚集索引插入的性能。
然而 Insert Buffer 的使用需要同时满足以下两个条件:
- 索引是辅助索引( secondary index ) ;
- 索引不是唯一( unique )的。
当满足以上两个条件时, InnoDB 存储引擎会使用 Insert Buffer ,这样就能提高插入操作的性能了。不过考虑这样一种情况:应用程序进行大量的插入操作,这些都涉及了不唯一的非聚集索引,也就是使用了 Insert Buffer。若此时 MySQL数据库发生了宕机这时势必有大量的 Insert Buffer并没有合并到实际的非聚集索引中去。因此这时恢复可能需要很长的时间,在极端情况下甚至需要几个小时。
辅助索引不能是唯一的,因为在插入缓冲时,数据库并不去查找索引页来判断插入的记录的唯一性。如果去查找肯定又会有离散读取的情况发生,从而导致 Insert Buffer失去了意义。
用户可以通过命令 SHOW ENGINE INNODB STATUS来查看插入缓冲的信息:

seg size显示了当前 Insert Buffer的大小为11336×16KB,大约为177MB; free list len代表了空闲列表的长度;size代表了已经合并记录页的数量。而黑体部分的第2行可能是用户真正关心的,因为它显示了插入性能的提高。 Inserts代表了插入的记录数;merged recs代表了合并的插入记录数量; merges代表合并的次数,也就是实际读取页的次数。 merges: merged recs大约为1:3,代表了插入缓冲将对于非聚集索引页的离散IO逻辑请求大约降低了2/3。
正如前面所说的,目前 Insert Buffer存在一个问题是:在写密集的情况下,插入缓冲会占用过多的缓冲池内存( innodb buffer pool),默认最大可以占用到1/2的缓冲池内存。以下是 InnoDB存储引擎源代码中对于 insert buffer的初始化操作:

这对于其他的操作可能会带来一定的影响。 Percona上发布一些 patch来修正插入缓冲占用太多缓冲池内存的情况,具体可以到 Percona官网进行查找。简单来说,修改IBUF_POOL_SIZE_PER_MAX_SIZE就可以对插入缓冲的大小进行控制。比如将IBUF_POOL_SIZE_PER_MAX_SIZE改为3,则最大只能使用1/3的缓冲池内存。
Insert Buffer的内部实现
通过前一个小节读者应该已经知道了 Insert Buffer的使用场景,即非唯一辅助索引的插入操作。但是对于 Insert Buffer具体是什么,以及内部怎么实现可能依然模糊,这正是本节所要阐述的内容。
可能令绝大部分用户感到吃惊的是, Insert Buffer的数据结构是一棵B+树。在MySQL4.1之前的版本中每张表有一棵 Insert Buffer B+树。而在现在的版本中,全局只有一棵 Insert Buffer B+树,负责对所有的表的辅助索引进行 Insert Buffer。而这棵B+树存放在共享表空间中,默认也就是 ibdata1中。因此,试图通过独立表空间ibd文件恢复表中数据时,往往会导致 CHECK TABLE失败。这是因为表的辅助索引中的数据可能还在 Insert Buffer中,也就是共享表空间中,所以通过ibd文件进行恢复后,还需要进行REPAIR TABLE操作来重建表上所有的辅助索引。
Insert Buffer是一棵B+树,因此其也由叶节点和非叶节点组成。非叶节点存放的是查询的 search key(键值),其构造如图所示:

search key一共占用9个字节,其中 space表示待插入记录所在表的表空间id,在InnodB存储引擎中,每个表有一个唯一的 space id,可以通过 space id查询得知是哪张表。 space占用4字节。 marker占用1字节,它是用来兼容老版本的 Insert Buffer, offset表示页所在的偏移量,占用4字节。
当一个辅助索引要插入到页(space,offset)时,如果这个页不在缓冲池中,那么InnoDB存储引擎首先根据上述规则构造一个 search key,接下来查询 Insert Buffer这棵B+树,然后再将这条记录插入到 Insert Buffer b+树的叶子节点中。
对于插入到 Insert Buffer B+树叶子节点的记录,并不是直接将待插入的记录插入,而是需要根据如下的规则进行构造:

space、 marker、 page no字段和之前非叶节点中的含义相同,一共占用9字节。第4个字段 metadata占用4字节,其存储的内容如下表所示:

IBUF_REC_OFFSET_COUNT是保存两个字节的整数,用来排序每个记录进入Insert Buffer的顺序。因为从 InnodB1.0.x开始支持 Change Buffer,所以这个值同样记录进人 Insert Buffer的顺序。通过这个顺序回放( replay)才能得到记录的正确值。
从 Insert Buffer叶子节点的第5列开始,就是实际插入记录的各个字段了。因此较之原插入记录, Insert Buffer B+树的叶子节点记录需要额外13字节的开销。
因为启用 Insert Buffer索引后,辅助索引页( space, page no)中的记录可能被插入到 Insert Buffer b+树中,所以为了保证每次 Merge Insert Buffer页必须成功,还需要有一个特殊的页用来标记每个辅助索引页(space, page_no)的可用空间。这个页的类型为 Insert Buffer Bitmap每个 Insert Buffer Bitmap页用来追踪16384个辅助索引页,也就是256个区(Extent)。每个 Insert Buffer Bitmap页都在16384个页的第二个页中。
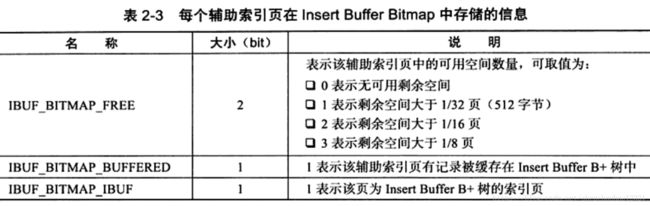
每个辅助索引页在 Insert Buffer Bitmap页中占用4位(bit),由下表中的三个部分组成:
Change Buffer
InnoDB从1.0.x版本开始引入了 Change Buffer,可将其视为 Insert Buffer的升级从这个版本开始, InnodB存储引擎可以对DML操作— INSERT、 DELETE、 UPDATE都进行缓冲,他们分别是: Insert Buffer、 Delete Buffer、 Purge buffer当然和之前 Insert Buffer一样, Change Buffer适用的对象依然是非唯一的辅助索引。
对一条记录进行 UPDATE操作可能分为两个过程:
- 将记录标记为已删除;
- 真正将记录删除
InnoDB从1.0.x版本开始引入了 Change Buffer,可将其视为 Insert Buffer的升级从这个版本开始, InnodB存储引擎可以对DML操作— INSERT、 DELETE、 UPDATE都进行缓冲,他们分别是: Insert Buffer、 Delete Buffer、 Purge buffer当然和之前 Insert Buffer一样, Change Buffer适用的对象依然是非唯一的辅助索引。
从 InnoDB1.2.x版本开始,可以通过参数 innodb_change_buffer_max_size来控制Change Buffer最大使用内存的数量:
mysql> show variables like 'innodb_change_buffer_max_size';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| innodb_change_buffer_max_size | 25 |
+-------------------------------+-------+
1 row in set (0.05 sec)
innodb_change_buffer_max_size值默认为25,表示最多使用1/4的缓冲池内存空间。
而需要注意的是,该参数的最大有效值为50在 MySQL5.5版本中通过命令 SHOW ENGINE INNODB STATUS,可以观察到类似如下的内容:

Merge Insert Buffer
通过前面的小节读者应该已经知道了 Insert/Change Buffer是一棵B+树。若需要实现插入记录的辅助索引页不在缓冲池中,那么需要将辅助索引记录首先插入到这棵B+树中。但是 Insert Buffer中的记录何时合并( merge)到真正的辅助索引中呢?这是本小节需要关注的重点。
概括地说, Merge Insert Buffer的操作可能发生在以下几种情况下:
- 辅助索引页被读取到缓冲池时;
- Insert Buffer Bitmap页追踪到该辅助索引页已无可用空间时;
- Master Thread。
第一种情况为当辅助索引页被读取到缓冲池中时,例如这在执行正常的 SELECT査询操作,这时需要检查 Insert Buffer Bitmap页,然后确认该辅助索引页是否有记录存放于 Insert Buffer b+树中。若有,则将 Insert Buffer B+树中该页的记录插入到该辅助索引页中。可以看到对该页多次的记录操作通过一次操作合并到了原有的辅助索引页中,因此性能会有大幅提高。
Insert Buffer Bitmap页用来追踪每个辅助索引页的可用空间,并至少有1/32页的空间。若插入辅助索引记录时检测到插入记录后可用空间会小于1/32页,则会强制进行一个合并操作,即强制读取辅助索引页,将 Insert Buffer B+树中该页的记录及待插入的记录插入到辅助索引页中。这就是上述所说的第二种情况。
还有一种情况,之前在分析 Master Thread时曾讲到,在 Master Thread线程中每秒或每10秒会进行一次 Merge Insert Buffer的操作,不同之处在于每次进行 merge操作的页的数量不同。
在 Master Thread中,执行 merge操作的不止是一个页,而是根据 srv_innodb_io_capactiy的百分比来决定真正要合并多少个辅助索引页。但 InnoDB存储引擎又是根据怎样的算法来得知需要合并的辅助索引页呢?
在 Insert Buffer B+树中,辅助索引页根据(space, offset)都已排序好,故可以根据(space, offset)的排序顺序进行页的选择。然而,对于 Insert Buffer页的选择,InnoDB存储引擎并非采用这个方式,它随机地选择 Insert Buffer B+树的一个页,读取该页中的 space及之后所需要数量的页。该算法在复杂情况下应有更好的公平性。同时,若进行 merge时,要进行 merge的表已经被删除,此时可以直接丢弃已经被 Insert/Change Buffer的数据记录。
二次写:(double write)
二次写的目的:缓冲池的数据不是直接写入硬盘,而是先写入表空间中的一个地方,之后在写入硬盘,是为了防止出现坏页。
两次写包括两种方法,一种是对单独一个页面刷盘时的两次写,另一种是批量刷盘时的两次写。单一页面刷盘实际上是MySQL5.5版本的实现方式。
什么是两次写:
两次写提出的背景或要解决的问题
两次写(InnoDB Double Write)是Innodb中很独特的一个功能点。因为Innodb中的日志是逻辑的,所谓逻辑就是比如插入一条记录时,它可能会在某一个页面(这条记录最终被插入的位置)的多个偏移位置写入某个长度的值,例如页头的记录数、槽数、页尾槽数据、页中的记录值等。这些本是一些物理操作,而Innodb为了节省日志量及其它原因,设计为逻辑处理的方式,即在一个页面上插入一条记录时,对应的日志内容包括表空间号、页面号、将被记录的各个列的值等内容,在真正物理插入的时候,才会将日志逻辑操作转换为前面的物理操作。
先有逻辑日志,再有物理操作,但是这样需要有一个前提,就是物理操作的页面是正确的。如果那个数据页面本身是错误的,这种错误可能是上次的操作导致的写断裂(1个页面为16KB,分多次写入,后面的可能没有写成功,导致这个页面不完整)或者其它原因,那么这个逻辑操作就没办法完成了。因为如果这个页面不正确的话,里面的数据是无效的,就可能会产生各种不可预料的问题。
因此首先要保证这个页面是正确的,方法就是两次写。
两次写是什么
为了解决partial page write问题,InnoDB实现了double write buffer,简单来说,就是在写数据页之前,先把这个数据页写到一块独立的物理文件位置(ibdata),然后再写到数据页。这样在宕机重启时,如果出现数据页损坏,那么在应用redo log之前,需要通过该页的副本来还原该页,然后再进行redo log重做,这就是double write。
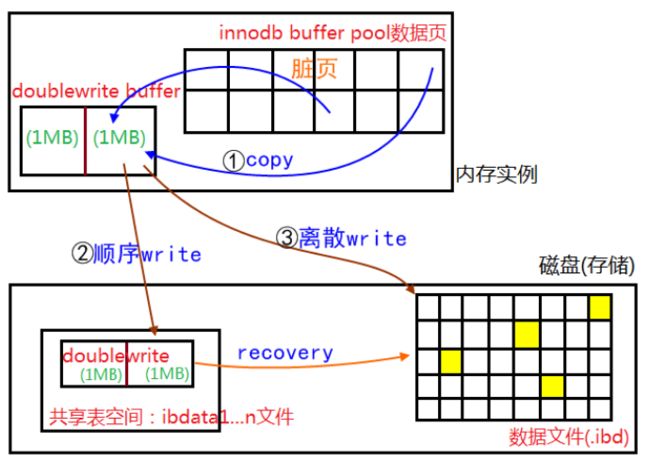
doublewrite由两部分组成,一部分为内存中的doublewrite buffer,其大小为2MB,另一部分是磁盘上共享表空间(ibdata x)中连续的128个页,即2个区(extent),大小也是2M。
1、当一系列机制触发数据缓冲池中的脏页刷新时,并不直接写入磁盘数据文件中,而是先拷贝至内存中的doublewrite buffer中;
2、接着从两次写缓冲区分两次写入磁盘共享表空间中(连续存储,顺序写,性能很高),每次写1MB;
3、待第二步完成后,再将doublewrite buffer中的脏页数据写入实际的各个表空间文件(离散写);(脏页数据固化后,即进行标记对应doublewrite数据可覆盖)
其工作流程如下:
再看redo log 写入关系,可以用下图演示

结构设计及原理
MySQL在系统页面上记录关于两次写的信息如要如下:
| 参数变量 | 信息描述 | 说明 |
|---|---|---|
| TRX_SYS_DOUBLEWRITE_FSEG | 两次写页面所在段的地址信息。 | 存储两次写页面所在段的地址信息,每次使用两次写机制写数据时,都会从这个位置读取到段的位置,找到段的首地址。 |
| TRX_SYS_DOUBLEWRITE_MAGIC | 用来判断是不是已经初始化过两次写页面。 | 存储的是用来验证当前两次写是不是正常或是不是已经申请的标志。 |
| TRX_SYS_DOUBLEWRITE_BLOCK1 | 两次写页面第一个簇的首地址,两次写页面总共两个簇,一个簇为64个页面。 | 存储的是两次写空间的位置,他们在ibdata文件中属于同一个段,在初始化数据库时会确定具体问题,是用来真正存储两次写页面数据的空间,它们对应的空间大小都是一个簇,占用磁盘空间分别为1M。(一个簇为64*16KB=1M;2个簇,就是2M) |
| TRX_SYS_DOUBLEWRITE_BLOCK2 | 第二个簇的首地址。 | 存储的是两次写空间的位置,他们在ibdata文件中属于同一个段,在初始化数据库时会确定具体问题,是用来真正存储两次写页面数据的空间,它们对应的空间大小都是一个簇,占用磁盘空间分别为1M。(一个簇为64*16KB=1M;2个簇,就是2M) |
| RX_SYS_DOUBLEWRITE_REPEAT | 将上面的MAGIC、BLOCK1、BLOCK2重复存储,防止页面自己的不完整。 |
刷盘的过程:
每次刷盘前,都会将要刷盘的页面信息临时保存到内存的数组中,这个空间大小也是128个页面,这个缓存称为两次写缓存数组。有了这些信息,单个页面刷盘的两次写就可以正常运转了。
step 1 先在两次写缓存数组中,找到一个空闲位置,并将这个位置标记为已使用,然后,再把要刷新的页面数据复制到标记的缓存空间中。
step 2 将页面的数据刷到两次写文件中,即ibdata文件中。此时页面是持久化。
复制的数据量是一个页面的大小,偏移位置是这个页面在两次写缓存空间中的位置,对应着TRX_SYS_DOUBLEWRITE_BLOCK1或TRX_SYS_DOUBLEWRITE_BLOCK2的位置。因为内存中的两次写缓存数组是128个元素,而对应的TRX_SYS_DOUBLEWRITE_BLOCK1及TRX_SYS_DOUBLEWRITE_BLOCK2也是128个页面,它们是一一对应的,所以具体刷到什么位置,可以计算出来。
step 3 页面刷盘,即数据刷到真实的位置,也许刷到的是ibdata文件,也许是某一个表的ibd文件中的某一个位置。
需要注意的是,因为Buffer Pool中的页面,刷到真实文件时是异步IO的,那么只有当刷到自己表空间的刷盘操作完成后,两次写缓存数组的数据才可以被覆盖,或者说,这个页面对应的两次写文件中的页面才可以被覆盖,不然有可能造成这个两次写位置的页面被新的页面覆盖的问题。如果此时上次的真实表空间的刷盘没有完成,同时产生了页面断裂的问题,这样就出现了该页面不可恢复的问题,两次写的意义也就没有了。
批量页面刷盘
很明显,单一刷盘情况下开启了两次写,IO次数的增加会导致性能差很多,在新版本MySQL 5.7中,新增加入了针对Buffer Pool 批量刷盘的两次写实现方式。
实现原理
MySQL 5.7的实现方式新增了一个文件,文件路径及名称可以通过参数innodb_parallel_doublewrite_path来控制。启动数据库时,如果两次写文件不存在,那么这个参数可以指定绝对路径的两次写文件,也可以只指定文件名使文件被默认创建到datadir目录下。
批量刷盘包括两种方式,分别是LRU(Least Recently Used,最近最少使用)方式和LIST方式。当Buffer Pool空间不足时,再载入新的页面就必须要将一些不怎么用到的、旧的页面淘汰出去,此时系统就会从LRU链表中找到最老的页面,进行批量刷盘,将释放的空间加入到空闲空间中去,这种情况就是LRU刷盘。当日志空间不足,或者是后台MASTER线程在定时刷盘时,不需要区分页面的新旧状态,只需要选择LSN最小的那些页面,从前到后刷一批页面到文件中,此时所用的策略就是LIST方式。
在批量刷盘的两次写中,这两种刷盘方法对应的两次写空间互不干涉。
InnoDB自身的整个Buffer Pool分为多个Instance,每个Instance管理自身的一套两次写空间,而针对每一个Instance的每一个刷盘方法的批量缓存空间大小,是通过参数innodb_doublewrite_batch_size来控制的,默认值为120(为什么是120?在单一页面刷盘时不是128吗? 答案参照说明部分的6.1)。这样算下来,innodb_parallel_doublewrite_path所指的文件大小的计算方法如下:
两次写文件页面个数=innodb_buffer_pool_instances*2(LIST+LRU)*innodb_doublewrite_batch_size.

从图中可以看出落到最终的每一个shard,其实就是一个batch,对应的参数就是innodb_doublewrite_batch_size。一个shard,有一个数组,长度为innodb_doublewrite_batch_size,与单一页面刷盘的两次写是一样的,只是这个数组只属于一个shard而已。
批量刷盘的过程
假设由于页面淘汰,系统要做一次批量刷盘,这次就是LRU方式的,那么此时系统就需要将当前页面加入到两次写缓存中,首先根据当前页面所在的Instance号及刷盘类型就可以找到对应的shard缓存,找到缓存后,判断当前shard是否已经满了,即是否已经达到innodb_doublewrite_batch_size的大小,如果没有达到,则将当前页面内容追加复制到当前的shard缓存中,这样当前页面的刷盘操作就完成了。这里并不像单一页面那样,先写入缓存空间中,然后写入ibdata文件的两次写空间,最后还需要立即将页面的真实内容刷入表空间,对于批量刷盘来说,只需要写入到shard缓存即可。
如果当前shard中缓存的页面个数已经达到了innodb_doublewrite_batch_size,则说明当前缓存空间已经满了,此时不得不将当前shard缓存的页面写入两次写文件中,写完之后再将两次写文件FLUSH到磁盘,最后将对应的真实页面刷盘,此时可能是随机写入了,因为对应的两次写缓存中虽然是连续的,但对应的真实页面就不会这样了。这里需要注意的一点就是,表空间页面的刷盘,是异步IO操作,此时需要等待异步IO完成,且整个shard中的页面都刷盘后,刷盘操作才可以继续向后执行,而这个shard也可以再次重新使用了,缓存中的数据也都会被清空。
需要注意的是,上面过程中写入是连续innodb_doublewrite_batch_size 个页面,所以性能会比写入多次而每次写入一个页面的情况好很多。批量刷盘的情况下,有可能每隔innodb_doublewrite_batch_size个页面的刷盘操作,就会出现一次等待操作,且等待时间长短不一定,但这也是在单一页面刷盘的基础上优化过的,做了改进。
两次写的作用:
在数据库启动时(异常关闭的情况下),都会做数据库恢复(redo)操作。在恢复的过程中,数据库会检查页面是否合法(校验),如果发现一个页面的校验结果不一致,则此时就会用到两次写机制,用两次写空间中的数据来恢复异常页面的数据,这也正是为处理这样的错误而设计的。此时的处理机制就是,将两次写的两个簇都读出来,再将innodb_parallel_doublewrite_path文件的内容读出来,然后将所有这些页面写回到对应的页面中去,这样就可以保证这些页面是正确的,并且是在写入前已经更新过的(最新数据)。在写回对应页面中去之后,就可以在此基础上继续做数据库恢复了,且不会遇到这样的问题了,因为最后有可能产生写断裂的数据页面都恢复了。
上面所讲的都是数据页面有问题的情况下可以通过两次写页面来恢复,但是如果两次写页面本身发生写断裂怎么办呢? 对于这个问题,大家不必担心。因为如果两次写有问题,则数据页面本身就不会做写操作(一定是先逻辑后物理嘛,逻辑挂了,就没有后面的物理了。),此时系统挂了,发生错误的是两次写页面,而数据页面在挂之前都是在Buffer里面,文件中依然是当前事务操作前的值,并没有变化,还是一致状态,这意味着两次写页面根本就不会被使用到。
说明
批量刷盘中批量缓存空间大小由参数innodb_doublewrite_batch_size来控制的,默认值为120,而单一页面刷盘时是128。
一个double write buffer 有2MB, 共128个page,在MySQL 5.6中, 默认有120个page用于批量刷新(如 LRU Flush 或者 LIST FLUSH),剩下的8个Page用于单个page的flush。120是可以通过参数innodb_doublewrite_batch_size来配置。
doublewrite的崩溃恢复 与 Redo log 恢复
如果操作系统在将页写入磁盘的过程中发生崩溃,在恢复过程中,innodb存储引擎可以从共享表空间的doublewrite中找到该页的一个最近的副本,将其复制到表空间文件,再应用redo log,就完成了恢复过程。因为有副本所以也不担心表空间中数据页是否损坏。
Partial page write问题
介绍double write之前我们有必要了解partial page write(部分页失效)问题。
InnoDB的Page Size一般是16KB,其数据校验也是针对这16KB来计算的,将数据写入到磁盘是以Page为单位进行操作的。我们知道,由于文件系统对一次大数据页(例如InnoDB的16KB)大多数情况下不是原子操作,这意味着如果服务器宕机了,可能只做了部分写入。16K的数据,写入4K时,发生了系统断电/os crash ,只有一部分写是成功的,这种情况下就是partial page write问题。
有经验的DBA可能会想到,如果发生写失效,MySQL可以根据redo log进行恢复。这是一个办法,但是必须清楚地认识到,redo log中记录的是对页的物理修改,如偏移量800,写’aaaa’记录。如果这个页本身已经发生了损坏,再对其进行重做是没有意义的。MySQL在恢复的过程中检查page的checksum,checksum就是检查page的最后事务号,发生partial page write问题时,page已经损坏,找不到该page中的事务号。在InnoDB看来,这样的数据页是无法通过checksum验证的,就无法恢复。即时我们强制让其通过验证,也无法从崩溃中恢复,因为当前InnoDB存在的一些日志类型,有些是逻辑操作,并不能做到幂等。
为了解决这个问题,InnoDB实现了double write buffer,简单来说,就是在写数据页之前,先把这个数据页写到一块独立的物理文件位置(ibdata),然后再写到数据页。这样在宕机重启时,如果出现数据页损坏,那么在应用redo log之前,需要通过该页的副本来还原该页,然后再进行redo log重做,这就是double write。double write技术带给innodb存储引擎的是数据页的可靠性,下面对doublewrite技术进行解析,让大家充分理解double write是如何做到保障数据页的可靠性。
double write体系结构及工作流程
double write由两部分组成,一部分是InnoDB内存中的double write buffer,大小为2M,另一部分是物理磁盘上ibdata系统表空间中大小为2MB,共128个连续的Page,既2个分区。其中120个用于批量写脏,另外8个用于Single Page Flush。做区分的原因是批量刷脏是后台线程做的,不影响前台线程。而Single page flush是用户线程发起的,需要尽快的刷脏并替换出一个空闲页出来。
对于批量刷脏,每次找到一个可做flush的page,对其持有S lock,然后将该page拷贝到dblwr中,当dblwr满后者一次批量刷脏结束时,将dblwr中的page全部刷到ibdata中,注意这是同步写操作;然后再唤醒后台IO线程去写数据页。当后台IO线程完成写操作后,会去更新dblwr中的计数以腾出空间,释放block上的S锁,完成写入。
对于Single Page Flush,则做的是同步写操作,在挑出一个可以刷脏的page后,先加入到dblwr中,刷到ibdata,然后写到用户表空间,完成后,会对该用户表空间做一次fsync操作。
Single Page Flush在buffer pool中free page不够时触发,通常由前台线程发起,由于每次single page flush都会导致一次fsync操作,在大并发负载下,如果大量线程去做flush,很显然会产生严重的性能下降。Percona在5.6版本中做了优化,可以选择由后台线程lru manager来做预刷,避免用户线程陷入其中。
如果发生了极端情况(断电),InnoDB再次启动后,发现了一个Page数据已经损坏,那么此时就可以从double write buffer中进行数据恢复了。
double write工作流程如下 :
当一系列机制(main函数触发、checkpoint等)触发数据缓冲池中的脏页进行刷新到data file的时候,并不直接写磁盘,而是会通过memcpy函数将脏页先复制到内存中的double write buffer,之后通过double write buffer再分两次、每次1MB顺序写入共享表空间的物理磁盘上。然后马上调用fsync函数,同步脏页进磁盘上。由于在这个过程中,double write页的存储时连续的,因此写入磁盘为顺序写,性能很高;完成double write后,再将脏页写入实际的各个表空间文件,这时写入就是离散的了。各模块协作情况如下图(第一步应为脏页产生的redo记录log buffer,然后log buffer写入redo log file,为简化次要步骤直接连线表示):
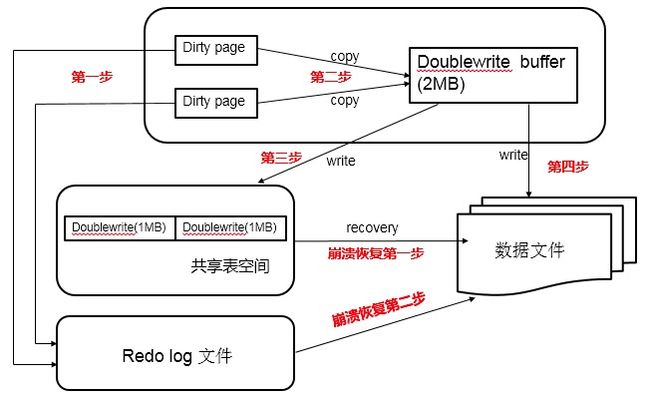
查看doublewrite工作情况,可以执行命令:
mysql > show status like "%InnoDB_dblwr%" ;
+ -- -- -- -- -- -- -- -- -- -- -- -- -- -- + -- -- -- -- -- -- +
| Variable_name | Value |
+ -- -- -- -- -- -- -- -- -- -- -- -- -- -- + -- -- -- -- -- -- +
| Innodb_dblwr_pages_written | 61932183 |
| Innodb_dblwr_writes | 15237891 |
+ -- -- -- -- -- -- -- -- -- -- -- -- -- -- + -- -- -- -- -- -- +
2 rows in set ( 0.01 sec )
以上数据显示,double write一共写了 61932183个页,一共写了15237891次,从这组数据我们可以分析,之前讲过在开启double write后,每次脏页刷新必须要先写double write,而double write存在于磁盘上的是两个连续的区,每个区由连续的页组成,一般情况下一个区最多有64个页,所以一次IO写入应该可以最多写64个页。而根据以上我这个系统Innodb_dblwr_pages_written与Innodb_dblwr_writes的比例来看,一次大概在4个页左右,远远还没到64,所以从这个角度也可以看出,系统写入压力并不高。
如果操作系统在将页写入磁盘的过程中发送了崩溃,在恢复过程中,InnoDB存储引擎可以从工序表空间中的double write中找到该页的副本,将其复制到表空间文件,再应用redo log。下面显示了一个由double write进行恢复的过程:
090924 11 : 36 : 32 mysqld restarted
090924 11 : 26 : 33 InnoDB : Database was not shut down normally !
InnoDB : Starting crash recovery .
InnoDB : Reading tablespace information from the .ibd files . . .
InnoDB : Crash recovery may have faild for some .ibd files !
InnoDB : Restoring possible half - written data pages from the doublewrite .
InnoDB : buffer . . .
double write的缺点
dblwr位于共享表空间上的double write buffer实际上也是一个文件,引入了一次额外写的开销,每个数据页都被要求写两次。由于需要大量的fsync操作,所以它会降低MySQL的整体性能,但是并不会降低到原来的50%。这主要是因为:
- double write是一个连接的存储空间,所以硬盘在写数据的时候是顺序写,而不是随机写,这样性能更高。
- 将数据从double write buffer写到真正的segment中的时候,系统会自动合并连接空间刷新的方式,每次可以刷新多个pages。
double write默认开启,参数skip_innodb_doublewrite虽然可以禁止使用double write功能,但还是强烈建议大家使用double write。避免部分写失效问题,当然,如果你的数据表空间放在本身就提供了部分写失效防范机制的文件系统上,如ZFS/FusionIO/DirectFS文件系统,在这种情况下,就可以不开启doublewrite了。
double write在恢复的时候是如何工作的
如果是写double write buffer本身失败,那么这些数据不会被写到磁盘,InnoDB此时会从磁盘载入原始的数据,然后通过InnoDB的事务日志来计算出正确的数据,重新写入到double write buffer。
如果double write buffer写成功的话,但是写磁盘失败,InnoDB就不用通过事务日志来计算了,而是直接用buffer的数据再写一遍。如上图中显示,在恢复的时候,InnoDB直接比较页面的checksum,如果不对的话,Innodb存储引擎可以从共享表空间的double write中找到该页的一个最近的副本,将其复制到表空间文件,再应用redo log,就完成了恢复过程。因为有副本所以也不担心表空间中数据页是否损坏,但InnoDB的恢复通常需要较长的时间。
MariaDB/MySQL/Facebook/Percona 5.7的改进
MariaDB/MySQL改进:
MariaDB使用参数innodb_use_atomic_writes来控制原子写行为,当打开该选项时,会使用O_DIRECT模式打表空间,通过posix_fallocate来扩展文件(而不是写0扩展),当在启动时检查到支持atomic write时,即使开启了innodb_doublewrite,也会关闭掉。
Oracle MySQL同样支持FusionIO的Atomic Write特性(Fusion-io Non-Volatile Memory (NVM) file system),对于支持原子写的文件系统,也会自动关闭double write buffer。
Facebook改进:
实际上这不能算是改进,只是提供了一个新的选项。在现实场景中,宕机是非常低概率的事件。大部分情况下dblwr都是用不上的。但如果我们直接关闭dblwr,如果真的发生例如掉电宕机了,我们需要知道哪些page可能损坏了。
因此Facebook MySQL提供了一个选项,可以写page之前,只将对应的page number写到dblwr中(而不是写全page),在崩溃恢复时,先读出记录在dblwr中的page号,检查对应的数据页是否损坏,如果损坏了,那就需要从备库重新恢复该实例。
Percona 5.7改进:
Percona Server的每个版本都对InnoDB的刷脏逻辑做了不少的优化,进入5.7版本也不例外。在官方5.7中已经实现了多个Page Cleaner,我们可以把Page Cleaner配置成和buffer pool instance的个数相同,可以更好的实现并行刷脏。
但是官方版本中,Page cleaner既要负责刷FLUSH LIST,同时也要做LRU FLUSH(但每个bp instance不超过innodb_lru_scan_depth)。而这两部分任务是可以独立进行的。
因此Percona Server增加了多个LRU FLUSH线程,可以更高效的进行lru flush,避免用户线程陷入single page flush状态。每个buffer pool instance拥有自己的lru flush线程和page cleaner线程。lru flush基于当前free list的长度进行自适应计算。 每个lru线程负责自己的那个Buffer pool。因此不同lru flush线程的繁忙程度可能是不一样的。
在解决上述问题后,bp flush的并行效率大大的提升了。但是对于所有的刷脏操作,都需要走到double write buffer。这意味着dblwr成为了新的瓶颈。为了解决这个问题,dblwr进行了拆分,每个bp instance都有自己的dblwr区域。这样各个Lru flush线程及Page cleaner线程在做page flush时就不会相互间产生锁冲突,从而提升了系统的扩展性。
你可以通过参数来配置一个独立于ibdata之外的文件来存储dblwr,文件被划分成多个区域,分区数为bp instance的个数,每个分区的大小为2 * srv_doublewrite_batch_size,每个batch size默认配置为120个page,其中一个用于刷FLUSH LIST,一个用于刷LRU。
如果fast shutdown设置为2,dblwr文件在正常shutdown时会被删除掉,并在重启后重建。
自适应哈希索引:(ahi)
InnoDB存储引擎会监控对表上各索引页的查询,如果监控到某个索引页被频繁查询,并诊断后发现如果为这一页的数据创建Hash索引会带来更大的性能提升,则会自动为这一页的数据创建Hash索引,并称之为自适应Hash索引。自适应Hash是通过缓冲池中B+树的页进行构建的,建立速度很快,不需要对整张表的数据都构建Hash索引,所以我们又可以把自适应Hash索引看成是索引的索引,。注意一点就是InnoDB只会对热点页构建自适应索引,且是由InnoDB自动创建和删除的,所以不能人为干预是否在一张InnoDB的表中创建Hash索引。
根据InnoDB的官方文档显示,启用自适应哈希索引后,读取和写入速度可以提高2倍;对于辅助索引的连接操作,性能可以提高5倍。在我看来,自适应哈希索引是非常好的优化模式,其设计思想是数据库自优化(self-tuning),即无需DBA对数据库进行调整。
| 名称 | 自适应哈希索引 |
|---|---|
| 适合使用场景 | 适合使用 = 和 IN 操作符的等值查询 |
| 不合适场景 | 不适合使用 like 和 % 的范围查询和高并发的joins |
| 优点 | 提高了Innodb的内存使用率和一些情况下二级索引的查询效率 |
| 缺点 | 占用Innodb的内存缓存,使用了 lacth 锁保护内存中的hash结构 |
开启和关闭
默认情况下自适应索引是开启状态,毕竟是可以提升性能的嘛,我们也可以通过命令开启和关闭,并可以查看自适应索引的
开启
默认就是开启的,可以通过命令show variables like ‘innodb_adaptive_hash_index’;查看自适应哈希索引的状态,并可以在命令行通过show engine innodb status\G查看自适应Hash索引的使用信息(AHI的大小,使用情况,每秒使用AHI搜索的情况等等)
关闭
负载较重的情况下,就不太适合开启自适应Hash索引了,因为这样可以避免额外的索引维护带来的开销,可以在启动的时候通过参数
–skip-innodb-adaptive-hash-index关闭
自适应哈希索引的解释
mysql 术语列表中对自适应哈希索引的解释
AHI 自适应哈希索引
AHI有一个要求,对这个页的连续访问模式必须是一样的。例如对于(a,b)这样的联合索引页,其访问模式可以是下面情况:
1)where a=xxx
2)where a =xxx and b=xxx
访问模式一样是指查询的条件是一样的,若交替进行上述两种查询,那么InnoDB存储引擎不会对该页构造AHI。
AHI还有下面几个要求:
1)以该模式访问了100次
2)页通过该模式访问了N次,其中N=页中记录*1/16
InnoDB存储引擎官方文档显示,启用AHI后,读取和写入速度可以提高2倍,辅助索引的连接操作性能可以提高5倍。AHI的设计思想是数据库自优化,不需要DBA对数据库进行手动调整。
mysql> show engine innodb status\G
下面是部分输出:
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 276671, node heap has 0 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
可以看到AHI的使用信息,包括AHI的大小,使用情况,每秒使用AHI搜索的情况。
哈希索引只能用来搜索等值的查询,如select * from table where index_col=’xxx’;
对于其它类型的查找,比如范围查找,是不能使用哈希索引的,因此这里出现了non-hash searches/s的情况。通过hash searches/s和non-hash searches/s可以大概了解使用哈希索引后的效率。
可以通过参数innodb_adaptive_hash_index来考虑禁用或启动此特性,默认是开启状态。
mysql> show variables like 'innodb_adaptive_hash_index';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| innodb_adaptive_hash_index | ON |
+----------------------------+-------+
1 row in set (0.00 sec)
————————————————
-
nnoDB 通过在内存中构造哈希索引,对使用 = 和 IN 运算符 加速查找的表进行优化。MySQL监视表的索引搜索,如果查询可以从哈希索引中受益,它会自动为经常访问的索引页构建一个。从某种意义上说,MySQL在运行时配置自适应哈希索引以利用充足主内存,更接近主内存数据库的体系结构。InnoDB 此功能由 innodb_adaptive_hash_index 配置选项。由于此功能有利于一些工作负载而非所有的工作负载,并且会占用缓冲池中的内存,因此通常您应该使用此功能进行基准测试,无论是启用还是禁用。
-
哈希索引始终基于现有的 InnoDB 二级索引构建 ,该索引被组织为B+树结构。MySQL可以在为B+树定义的任意长度的密钥的前缀上构建哈希索引,具体取决于针对索引的搜索模式。哈希索引可以是部分的; 整个B树索引不需要缓存在缓冲池中。
-
在MySQL 5.6及更高版本中,InnoDB 利用表的快速单值查找的另一种方法是使用InnoDB memcached插件。
自适应哈希索引的描述
mysql 5.7 官方手册对自适应哈希索引的描述
-
所述自适应散列索引(AHI)允许InnoDB执行更喜欢与工作量和用于充足存储器的适当组合,系统内存中的数据库 缓冲池,在不牺牲任何事务特性或可靠性。此功能由配置innodb_adaptive_hash_index 选项启用 ,或使用命令 --skip-innodb_adaptive_hash_index 在服务器启动时关闭 。
-
根据观察到的搜索模式,MySQL使用索引键的前缀构建哈希索引。密钥的前缀可以是任意长度,并且可能只有B树中的某些值出现在哈希索引中。哈希索引是根据需要经常访问的索引页面构建的。
-
如果表几乎完全适合主内存,则哈希索引可以通过启用任何元素的直接查找来加速查询,将索引值转换为一种指针。InnoDB 有一个监视索引搜索的机制。如果 InnoDB通知查询可以从构建哈希索引中受益,则会自动执行此操作。
-
对于某些工作负载,监视索引查找和维护哈希索引结构的额外开销远远超过了自适应哈希索引带来的性能提升。有时,访问时保护自适应哈希索引的 read/write lock 1会带来非常严重的性能消耗,例如高并发的joins。查询使用LIKE操作和% 通配符也往往不会受益于AHI。对于不需要自适应哈希索引的工作负载,将其关闭可减少不必要的性能开销。由于很难预先预测此功能是否适用于特定系统,因此请考虑使用实际工作负载运行启用和禁用的基准测试。对比早期版本,MySQL 5.6及更高版本中的体系结构更改使得更多工作负载适合于禁用自适应哈希索引,尽管默认情况下仍然启用它。
-
在MySQL 5.7中,自适应哈希索引搜索系统被分区。每个索引都绑定到一个特定的分区,每个分区都由一个单独的 latch 锁2保护。分区由 innodb_adaptive_hash_index_parts 配置选项控制 。在早期版本中,自适应哈希索引搜索系统受到单个 latch 锁的保护,这可能成为繁重工作负载下的争用点。innodb_adaptive_hash_index_parts 默认情况下,该 选项设置为8。最大设置为512。
-
哈希索引始终基于表上的现有B树索引构建 。 InnoDB可以在为B树定义的任意长度的键的前缀上构建哈希索引,具体取决于InnoDB为B树索引观察的搜索模式。哈希索引可以是部分的,仅覆盖经常访问的索引的那些页面。
-
您可以使用 SEMAPHORES 查看 SHOW ENGINE INNODB STATUS输出部分中,监视自适应哈希索引的使用及其使用的争用。如果您看到许多线程在创建的RW锁存器上等待 btr0sea.c,那么禁用自适应哈希索引可能会有用。
预读:(read ahead)
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K),如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。
预读失效:
- 提前把页放入了缓冲池,但最终MySql并没有从页中读取数据,称为预读失效。
预读机制
InnoDB在I/O的优化上有个比较重要的特性为预读,预读请求是一个i/o请求,它会异步地在缓冲池中预先回迁多个页面,预计很快就会需要这些页面,这些请求在一个范围内引入所有页面。
InnoDB以64个page为一个extent,那么InnoDB的预读是以page为单位还是以extent?(根据预读的两种方式不同而不同)

数据库请求数据的时候,会将读请求交给文件系统,放入请求队列中;相关进程从请求队列中将读请求取出,根据需求到相关数据区(内存、磁盘)读取数据;取出的数据,放入响应队列中,最后数据库就会从响应队列中将数据取走,完成一次数据读操作过程。
接着进程继续处理请求队列,(如果数据库是全表扫描的话,数据读请求将会占满请求队列),判断后面几个数据读请求的数据是否相邻,再根据自身系统IO带宽处理量,进行预读,进行读请求的合并处理,一次性读取多块数据放入响应队列中,再被数据库取走。(如此,一次物理读操作,实现多页数据读取,rrqm>0(# iostat -x),假设是4个读请求合并,则rrqm参数显示的就是4)
两种预读算法
InnoDB使用两种预读算法来提高I/O性能:线性预读(linear read-ahead)和随机预读(randomread-ahead)
为了区分这两种预读的方式,我们可以把线性预读放到以extent为单位,而随机预读放到以extent中的page为单位。线性预读着眼于将下一个extent提前读取到buffer pool中,而随机预读着眼于将当前extent中的剩余的page提前读取到buffer pool中。
线性预读(linear read-ahead)
线性预读方式有一个很重要的变量控制是否将下一个extent预读到buffer pool中,通过使用配置参数innodb_read_ahead_threshold,控制触发innodb执行预读操作的时间。
如果一个extent中的被顺序读取的page超过或者等于该参数变量时,Innodb将会异步的将下一个extent读取到buffer pool中,innodb_read_ahead_threshold可以设置为0-64的任何值(因为一个extent中也就只有64页),默认值为56,值越高,访问模式检查越严格。
mysql> show variables like 'innodb_read_ahead_threshold';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| innodb_read_ahead_threshold | 56 |
+-----------------------------+-------+
例如,如果将值设置为48,则InnoDB只有在顺序访问当前extent中的48个pages时才触发线性预读请求,将下一个extent读到内存中。如果值为8,InnoDB触发异步预读,即使程序段中只有8页被顺序访问。
可以在MySQL配置文件中设置此参数的值,或者使用SET GLOBAL需要该SUPER权限的命令动态更改该参数。
在没有该变量之前,当访问到extent的最后一个page的时候,innodb会决定是否将下一个extent放入到buffer pool中。
随机预读(randomread-ahead)
随机预读通过buffer pool中存中的也来预测哪些页可能很快会被访问,而不考虑这些页的读取顺序。
随机预读方式则是表示当同一个extent中的一些page在buffer pool中发现时,Innodb会将该extent中的剩余page一并读到buffer pool中。如果发现buffer pool中存中一个区段的13个连续的页,InnoDB会异步发起预读请求这个区段剩余的页。
mysql> show variables like 'innodb_random_read_ahead';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_random_read_ahead | OFF |
+--------------------------+-------+
由于随机预读方式给innodb code带来了一些不必要的复杂性,同时在性能也存在不稳定性,在5.5中已经将这种预读方式废弃,默认是OFF。若要启用此功能,即将配置变量设置innodb_random_read_ahead为ON。
通过 SHOW INNODB ENGINE STATUS 命令输出的统计信息可以帮助你评估预读算法的效果,统计信息包含了下面几个值:
1.innodb_buffer_pool_read_ahead 通过预读异步读取到buffer pool的页数
2.innodb_buffer_pool_read_ahead_evicted 预读的页没被使用就被驱逐出buffer pool的页数,这个值与上面预读的页数的比值可以反应出预读算法的优劣。
3.innodb_buffer_pool_read_ahead_rnd 由InnoDB触发的随机预读次数。
监控Innodb的预读
可以通过show engine innodb status\G显示统计信息
mysql> show engine innodb status\G
----------------------
BUFFER POOL AND MEMORY
----------------------
……
Pages read ahead 0.00/s,
evicted without access 0.00/s, Random read ahead 0.00/s
……
1、Pages read ahead:表示每秒读入的pages;
2、evicted without access:表示每秒读出的pages;
3、一般随机预读都是关闭的,也就是0。
通过两个状态值,评估预读算法的有效性
mysql> show global status like '%read_ahead%';
+---------------------------------------+-------+
| Variable_name | Value |
+---------------------------------------+-------+
| Innodb_buffer_pool_read_ahead_rnd | 0 |
| Innodb_buffer_pool_read_ahead | 2303 |
| Innodb_buffer_pool_read_ahead_evicted | 0 |
+---------------------------------------+-------+
3 rows in set (0.01 sec)
1、Innodb_buffer_pool_read_ahead:
通过预读(后台线程)读入innodb buffer pool中数据页数
2、Innodb_buffer_pool_read_ahead_evicted:
通过预读来的数据页没有被查询访问就被清理的pages,无效预读页数
缓冲池
应用系统分层架构,为了加速数据访问,会把最常访问的数据,放在缓存(cache)里,避免每次都去访问数据库。操作系统,会有缓冲池(buffer pool)机制,避免每次访问磁盘,以加速数据的访问。MySQL作为一个存储系统,同样具有缓冲池(buffer pool)机制,以避免每次查询数据都进行磁盘IO。
缓冲池的作用:
缓存表数据和索引数据,把磁盘上的数据加载到缓冲池中,避免每次都进行磁盘IO,起到加速访问的效果.
LRU算法(Least recently used):
把入缓存池的页放在LRU的头部,作为最近访问的元素
- 页在缓冲池中的数据,把它放在队列的前面(情景一)
- 页不在缓冲池中的数据,把它放在队列的前面,同时淘汰队列后面的数据(情景二)
情景一
情景二
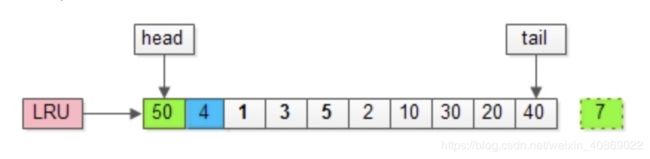
MySQL不用LRU算法原因:
- 预读失效
- 提前把页放入了缓冲池,但最终MySQL并没有从页中读取数据,称为预读失效。
- 缓冲池污染
- 当某一个SQL语句,要批量扫描大量数据时,可能导致把缓冲池的所有页都替换出去,导致大量热数据被换出,MySQL性能急剧下降,这种情况叫缓冲池污染。
缓冲池认为是内存上的cache,用来避免频繁磁盘IO的,但是这个cache不会被100%命中 。如果未命中就预读失败。
命中了叫预读成功。
所以说缓冲池不等于查询缓存,他们两个存在的共同的特点就是都是通过缓存的机制来提升效率。而缓冲池是服务于数据库整体的IO操作,通过建立缓冲池机制来弥补存储引擎的磁盘文件与内存访问之间的效率鸿沟,同时缓冲池会采用“预读”的机器提前加载一些马上会用到的数据,以提升整体的数据库性能。而查询缓存是服务于SQL查询和查询结果集的,因为命中条件苛刻,而且只要当数据表发生了变化,查询缓存就会失效,因此命中率低,在MySQL版本中已经弃用了该功能。
InnoDB的缓冲池缓存什么?有什么用?
缓存表数据与索引数据,把磁盘上的数据加载到缓冲池,避免每次访问都进行磁盘IO,起到加速访问的作用。
速度快,那为啥不把所有数据都放到缓冲池里?
凡事都具备两面性,抛开数据易失性不说,访问快速的反面是存储容量小:
(1)缓存访问快,但容量小,数据库存储了200G数据,缓存容量可能只有64G;
(2)内存访问快,但容量小,买一台笔记本磁盘有2T,内存可能只有16G;
因此,只能把“最热”的数据放到“最近”的地方,以“最大限度”的降低磁盘访问。
什么是预读?
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K),如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。
预读为什么有效 :
数据访问,通常都遵循“集中读写”的原则,使用一些数据,大概率会使用附近的数据,这就是所谓的“局部性原理”,它表明提前加载是有效的,确实能够减少磁盘IO。
按页(4K)读取,和InnoDB的缓冲池设计有啥关系?
(1)磁盘访问按页读取能够提高性能,所以缓冲池一般也是按页缓存数据;
(2)预读机制启示了我们,能把一些“可能要访问”的页提前加入缓冲池,避免未来的磁盘IO操作;
InnoDB是以什么算法,来管理这些缓冲页呢?
-
最容易想到的,就是LRU(Least recently used)。
-
画外音:memcache,OS都会用LRU来进行页置换管理,但MySQL的玩法并不一样。
传统的LRU是如何进行缓冲页管理?
最常见的玩法是,把入缓冲池的页放到LRU的头部,作为最近访问的元素,从而最晚被淘汰。这里又分两种情况:
(1)页已经在缓冲池里,那就只做“移至”LRU头部的动作,而没有页被淘汰;
(2)页不在缓冲池里,除了做“放入”LRU头部的动作,还要做“淘汰”LRU尾部页的动作;
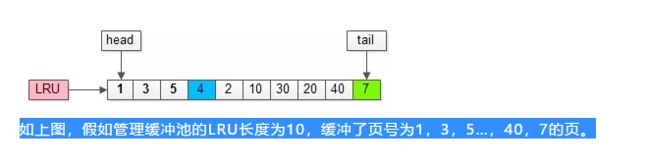
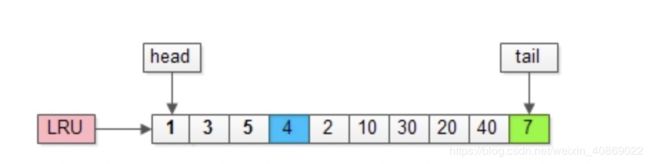
假如,接下来要访问的数据在页号为4的页中:
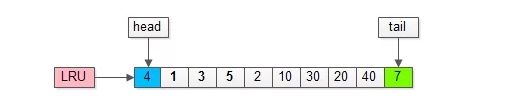
1.页号为4的页,本来就在缓冲池里;
2.把页号为4的页,放到LRU的头部即可,没有页被淘汰;
画外音:为了减少数据移动,LRU一般用链表实现。
假如,再接下来要访问的数据在页号为50的页中:

1.页号为50的页,原来不在缓冲池里;
2.把页号为50的页,放到LRU头部,同时淘汰尾部页号为7的页;
传统的LRU缓冲池算法十分直观,OS,memcache等很多软件都在用,MySQL为啥这么矫情,不能直接用呢?
这里有两个问题:
(1)预读失效;
(2)缓冲池污染;
什么是预读失效?
由于预读(Read-Ahead),提前把页放入了缓冲池,但最终MySQL并没有从页中读取数据,称为预读失效。
如何对预读失效进行优化?
要优化预读失效,思路是:
(1)让预读失败的页,停留在缓冲池LRU里的时间尽可能短;
(2)让真正被读取的页,才挪到缓冲池LRU的头部;
以保证,真正被读取的热数据留在缓冲池里的时间尽可能长。
具体方法是:
-
将LRU分为两个部分:
- 新生代(new sublist)
- 老生代(old sublist)
-
新老生代收尾相连,即:新生代的尾(tail)连接着老生代的头(head);
-
新页(例如被预读的页)加入缓冲池时,只加入到老生代头部:
-
如果数据真正被读取(预读成功),才会加入到新生代的头部
-
如果数据没有被读取,则会比新生代里的“热数据页”更早被淘汰出缓冲池
-
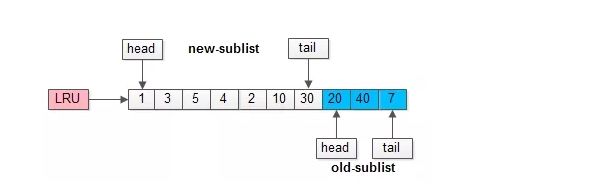
举个例子,整个缓冲池LRU如上图:
(1)整个LRU长度是10;
(2)前70%是新生代;
(3)后30%是老生代;
(4)新老生代首尾相连;

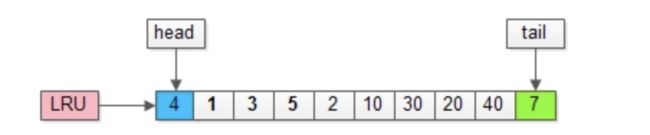
假如有一个页号为50的新页被预读加入缓冲池:
(1)50只会从老生代头部插入,老生代尾部(也是整体尾部)的页会被淘汰掉;
(2)假设50这一页不会被真正读取,即预读失败,它将比新生代的数据更早淘汰出缓冲池;

假如50这一页立刻被读取到,例如SQL访问了页内的行row数据:
(1)它会被立刻加入到新生代的头部;
(2)新生代的页会被挤到老生代,此时并不会有页面被真正淘汰;
改进版缓冲池LRU能够很好的解决“预读失败”的问题。
画外音:但也不要因噎废食,因为害怕预读失败而取消预读策略,大部分情况下,局部性原理是成立的,预读是有效的。
新老生代改进版LRU仍然解决不了缓冲池污染的问题
什么是MySQL缓冲池污染?
当某一个SQL语句,要批量扫描大量数据时,可能导致把缓冲池的所有页都替换出去,导致大量热数据被换出,MySQL性能急剧下降,这种情况叫缓冲池污染。
解决MySQL缓冲池污染:
缓冲池污染案例:
有一个数据量较大的用户表,当执行:
select * from user where name like "%shenjian%";
虽然结果集可能只有少量数据,但这类like不能命中索引,必须全表扫描,就需要访问大量的页:
(1)把页加到缓冲池(插入老生代头部);
(2)从页里读出相关的row(插入新生代头部);
(3)row里的name字段和字符串shenjian进行比较,如果符合条件,加入到结果集中;
(4)…直到扫描完所有页中的所有row…
如此一来,所有的数据页都会被加载到新生代的头部,但只会访问一次,真正的热数据被大量换出
怎么这类扫码大量数据导致的缓冲池污染问题呢?
MySQL缓冲池加入了一个“老生代停留时间窗口”的机制:
(1)假设T=老生代停留时间窗口;
(2)插入老生代头部的页,即使立刻被访问,并不会立刻放入新生代头部;
(3)只有满足“被访问”并且“在老生代停留时间”大于T,才会被放入新生代头部;
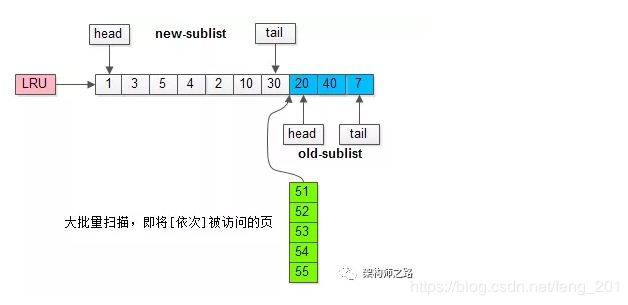
继续举例,假如批量数据扫描,有51,52,53,54,55等五个页面将要依次被访问。
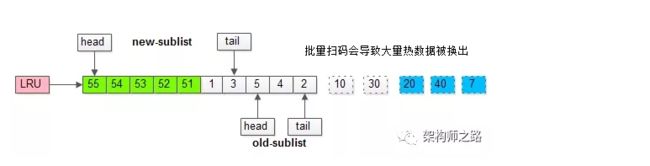
如果没有“老生代停留时间窗口”的策略,这些批量被访问的页面,会换出大量热数据。
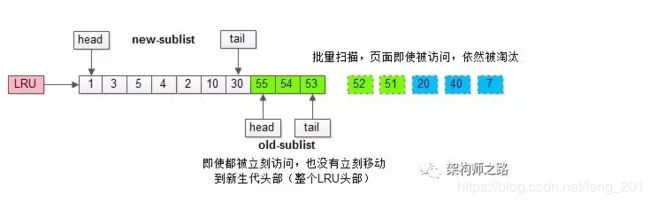
加入“老生代停留时间窗口”策略后,短时间内被大量加载的页,并不会立刻插入新生代头部,而是优先淘汰那些,短期内仅仅访问了一次的页。

而只有在老生代呆的时间足够久,停留时间大于T,才会被插入新生代头部。
上述原理,对应InnoDB里哪些参数?
有三个比较重要的参数。
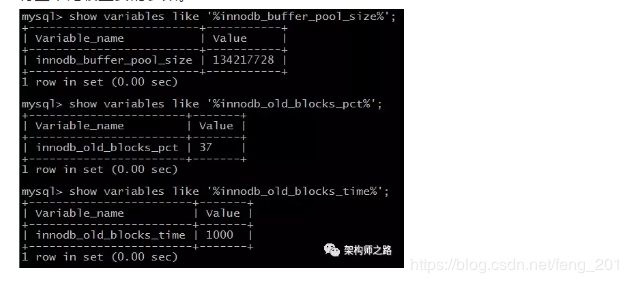
参数:innodb_buffer_pool_size
介绍:配置缓冲池的大小,在内存允许的情况下,DBA往往会建议调大这个参数,越多数据和索引放到内存里,数据库的性能会越好。
参数:innodb_old_blocks_pct
介绍:老生代占整个LRU链长度的比例,默认是37,即整个LRU中新生代与老生代长度比例是63:37。
画外音:如果把这个参数设为100,就退化为普通LRU了。
参数:innodb_old_blocks_time
介绍:老生代停留时间窗口,单位是毫秒,默认是1000,即同时满足“被访问”与“在老生代停留时间超过1秒”两个条件,才会被插入到新生代头部。
总结:happy:
(1)缓冲池(buffer pool)是一种常见的降低磁盘访问的机制;
(2)缓冲池通常以页(page)为单位缓存数据;
(3)缓冲池的常见管理算法是LRU,memcache,OS,InnoDB都使用了这种算法;
(4)InnoDB对普通LRU进行了优化:
- 将缓冲池分为老生代和新生代,入缓冲池的页,优先进入老生代,页被访问,才进入新生代,以解决预读失效的问题
- 页被访问,且在老生代停留时间超过配置阈值的,才进入新生代,以解决批量数据访问,大量热数据淘汰的问题
缓存:
Mysql缓存机制就是缓存sql 文本及缓存结果,用KV形式保存再服务器内存中,如果运行相同的sql,服务器直接从缓存中去获取结果,不需要在再去解析、优化、执行sql。 如果这个表修改了,那么使用这个表中的所有缓存将不再有效,查询缓存值得相关条目将被清空。表中得任何改变是值表中任何数据或者是结构的改变,包括insert,update,delete,truncate,alter table,drop table或者是drop database 包括那些映射到改变了的表的使用merge表的查询,显然,者对于频繁更新的表,查询缓存不合适,对于一些不变的数据且有大量相同sql查询的表,查询缓存会节省很大的性能。
命中条件
缓存存在一个hash表中,通过查询SQL,查询数据库,客户端协议等作为key,在判断命中前,mysql不会解析SQL,而是使用SQL去查询缓存,SQL上的任何字符的不同,如空格,注释,都会导致缓存不命中。如果查询有不确定的数据like now(),current_date(),那么查询完成后结果者不会被缓存,包含不确定的数的是不会放置到缓存中。
工作流程
1.服务器接收SQL,以SQL和一些其他条件为key查找缓存表
2.如果找到了缓存,则直接返回缓存
3.如果没有找到缓存,则执行SQL查询,包括原来的SQL解析,优化等。
4.执行完SQL查询结果以后,将SQL查询结果缓存入缓存表
缓存失败
当某个表正在写入数据,则这个表的缓存(命中缓存,缓存写入等)将会处于失效状态,在Innodb中,如果某个事务修改了这张表,则这个表的缓存在事务提交前都会处于失效状态,在这个事务提交前,这个表的相关查询都无法被缓存。
缓存的内存管理
缓存会在内存中开辟一块内存(query_cache_size)来维护缓存数据,其中大概有40K的空间是用来维护缓存数据的元数据的,例如空间内存,例如空间内存,数据表和查询结果映射,SQL和查询结果映射的。
mysql将这个大内存块分为小内存块(query_cache_min_res_unit),每个小块中存储自身的类型、大小和查询结果数据,还有前后内存块的指针。
mysql需要设置单个小存储块大小,在SQL查询开始(还未得到结果)时就去申请一块内存空间,所以即使你的缓存数据没有达到这个大小也需要这个大小的数据块去保存(like linux filesystem’s block)。如果超出这个内存块的大小,则需要再申请一个内存块。当查询完成发现申请的内存有富余,则会将富余的内存空间是放点,这就会造成内存碎片的问题,见下图
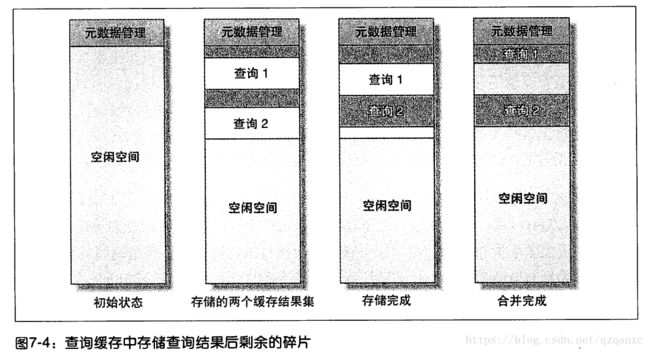
缓存的使用时机
衡量打开缓存是否对系统有性能提升是一个很难的话题
-
通过缓存命中率判断, 缓存命中率 = 缓存命中次数 (Qcache_hits) / 查询次数 (Com_select)
-
通过缓存写入率, 写入率 = 缓存写入次数 (Qcache_inserts) / 查询次数 (Qcache_inserts)
-
通过 命中-写入率 判断, 比率 = 命中次数 (Qcache_hits) / 写入次数 (Qcache_inserts), 高性能MySQL中称之为比较能反映性能提升的指数,一般来说达到3:1则算是查询缓存有效,而最好能够达到10:1
缓存参数配置
- query_cache_type: 是否打开缓存
可选项- OFF: 关闭
- ON: 总是打开
- DEMAND: 只有明确写了SQL_CACHE的查询才会吸入缓存
- query_cache_size: 缓存使用的总内存空间大小,单位是字节,这个值必须是1024的整数倍,否则MySQL实际分配可能跟这个数值不同(感觉这个应该跟文件系统的blcok大小有关)
- query_cache_min_res_unit: 分配内存块时的最小单位大小
- query_cache_limit: MySQL能够缓存的最大结果,如果超出,则增加 Qcache_not_cached的值,并删除查询结果
- query_cache_wlock_invalidate: 如果某个数据表被锁住,是否仍然从缓存中返回数据,默认是OFF,表示仍然可以返回
GLOBAL STAUS 中 关于 缓存的参数解释:
Qcache_free_blocks: 缓存池中空闲块的个数
Qcache_free_memory: 缓存中空闲内存量
Qcache_hits: 缓存命中次数
Qcache_inserts: 缓存写入次数
Qcache_lowmen_prunes: 因内存不足删除缓存次数
Qcache_not_cached: 查询未被缓存次数,例如查询结果超出缓存块大小,查询中包含可变函数等
Qcache_queries_in_cache: 当前缓存中缓存的SQL数量
Qcache_total_blocks: 缓存总block数
减少碎片策略
- 选择合适的block大小
- 使用 FLUSH QUERY CACHE 命令整理碎片.这个命令在整理缓存期间,会导致其他连接无法使用查询缓存
PS: 清空缓存的命令式 RESET QUERY CACHE
InnoDB与查询缓存
Innodb会对每个表设置一个事务计数器,里面存储当前最大的事务ID.当一个事务提交时,InnoDB会使用MVCC中系统事务ID最大的事务ID跟新当前表的计数器.
只有比这个最大ID大的事务能使用查询缓存,其他比这个ID小的事务则不能使用查询缓存.
另外,在InnoDB中,所有有加锁操作的事务都不使用任何查询缓存
查询必须是完全相同的(逐字节相同)才能够被认为是相同的。另外,同样的查询字符串由于其它原因可能认为是不同的。使用不同的数据库、不同的协议版本或者不同 默认字符集的查询被认为是不同的查询并且分别进行缓存。
一级缓存:
一级缓存也称本地缓存,sqlSession级别的缓存。一级缓存是一直开启的;与数据库同一次回话期间查询到的数据会放在本地缓存中。
二级缓存
全局缓存;基于namespace级别的缓存。一个namespace对应一个二级缓存。
一级缓存失效的四种情况:
-
sqlSession不同。
-
sqlSession相同,查询条件不同。因为缓存条件不同,缓存中还没有数据。
-
sqlSession相同,在两次相同查询条件中间执行过增删改操作。(因为中间的增删改可能对缓存中数据进行修改,所以不能用)
-
sqlSession相同,手动清空了一级缓存。(如果sqlSession去执行commit操作(执行插入、更新、删除),清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。)
二级缓存:全局缓存;基于namespace级别的缓存。一个namespace对应一个二级缓存。
工作机制:
-
一个会话,查询一条数据,这个数据会被放在当前会话的一级缓存中。
-
如果会话被关闭了,一级缓存中的数据会被保存带二级缓存。新的会话查询信息就会参照二级缓存。
-
sqlSession ====> Employee====>employee sqlSession ====>DepartmentMapper=====>Department 不同的namespace查出的数据会放在自己对应的缓存中
效果:查出的数据首先放在一级缓存中,只有一级缓存被关闭或者提交以后,一级缓存数据才会转移到二级缓存
使用步骤:
1.开启全局缓存配置。
2.因为是namespace级别,需要搭配每个xxxMapper.xml中配置二级缓存
eviction:缓存的回收策略:
LRU– 最近最少使用的:移除最长时间不被使用的对象。
FIFO– 先进先出:按对象进入缓存的顺序来移除它们。
SOFT– 软引用:移除基于垃圾回收器状态和软引用规则的对象。
WEAK– 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
flushInterval:缓存刷新间隔。缓存多久清空一次,默认不清空。设置一个毫秒值。
readOnly:是否只读。
true:mybatis认为所有从缓存中获取数据的操作都是只读操作,不会修改数据。mybatis为了加快获取速度,直接就会将 数据在缓存中的引用交给用户。不安全,速度快。
false:mybatis觉得获取的数据可能被修改。mybatis会利用序列化和反序列化的技术克隆一份新的数据给用户。安全, 速度快。
size:缓存放多少元素。
type:指定自定义缓存全类名。实现cache接口即可。
3.pojo需要实现序列换接口。
和缓存相关的配置/属性:
-
cacheEnabled:如果是false,关闭二级缓存,不关闭一级缓存。
-
每个select标签都有userCache="true"属性:对一级缓存没有影响。设置为false,二级缓存失效。
-
每个增删改标签都有flushCache="true"属性:一级缓存和二级缓存都会被清空。
-
在查询标签中flushCache="false"属性:如果设置为true,查完会清空,一级二级缓存都会被清空,都不会用缓存。
-
sqlSession.clearn():跟session有关,只会清除一级缓存。
-
localCacheScope:本地缓存作用域。
一级缓存SESSION:当前会话的所有数据保存到回话缓存中。STATEMENT:禁用一级缓存。
缓存首先一进来去查二级缓存,二级缓存没有去找一级缓存,一级缓存没有去找数据库。二级缓存----->一级缓存-------->数据库。
自定义缓存 implements Cache,重写接口中的保存等方法,比如说保存到redis.
Mybatis的一级缓存:
Mybatis的一级缓存是指Session缓存。一级缓存的作用域默认是一个SqlSession。Mybatis默认开启一级缓存。
也就是在同一个SqlSession中,执行相同的查询SQL,第一次会去数据库进行查询,并写到缓存中;
第二次以后是直接去缓存中取。
当执行SQL查询中间发生了增删改的操作,MyBatis会把SqlSession的缓存清空。
一级缓存的范围有session和statement两种,默认是session,如果不想使用一级缓存,可以把一级缓存的范围指定为statement,这样每次执行完一个Mapper中的语句后都会将一级缓存清除。
如果需要更改一级缓存的范围,可以在Mybatis的配置文件中,在下通过localCacheScope指定。
<setting name="localCacheScope" value="STATEMENT"/>
建议不需要修改
需要注意的是:
当Mybatis整合Spring后,直接通过Spring注入Mapper的形式,如果不是在同一个事务中每个Mapper的每次查询操作都对应一个全新的SqlSession实例,这个时候就不会有一级缓存的命中,但是在同一个事务中时共用的是同一个SqlSession。
如有需要可以启用二级缓存。
Mybatis的二级缓存:
Mybatis的二级缓存是指mapper映射文件。二级缓存的作用域是同一个namespace下的mapper映射文件内容,多个SqlSession共享。Mybatis需要手动设置启动二级缓存。
二级缓存是默认启用的(要生效需要对每个Mapper进行配置),如想取消,则可以通过Mybatis配置文件中的元素下的子元素来指定cacheEnabled为false。
<settings>
<setting name="cacheEnabled" value="false" />
</settings>
cacheEnabled默认是启用的,只有在该值为true的时候,底层使用的Executor才是支持二级缓存的CachingExecutor。具体可参考Mybatis的核心配置类org.apache.ibatis.session.Configuration的newExecutor方法实现。
可以通过源码看看
...
public Executor newExecutor(Transaction transaction) {
return this.newExecutor(transaction, this.defaultExecutorType);
}
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? this.defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Object executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (this.cacheEnabled) {//设置为true才执行的
executor = new CachingExecutor((Executor)executor);
}
Executor executor = (Executor)this.interceptorChain.pluginAll(executor);
return executor;
}
...
要使用二级缓存除了上面一个配置外,我们还需要在我们每个DAO对应的Mapper.xml文件中定义需要使用的cache
...
<mapper namespace="...UserMapper">
<cache/><!-- 加上该句即可,使用默认配置、还有另外一种方式,在后面写出 -->
...
</mapper>
具体可以看org.apache.ibatis.executor.CachingExecutor类的以下实现
其中使用的cache就是我们在对应的Mapper.xml中定义的cache。
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = this.createCacheKey(ms, parameterObject, rowBounds, boundSql);
return this.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {//第一个条件 定义需要使用的cache
this.flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {//第二个条件 需要当前的查询语句是配置了使用cache的,即下面源码的useCache()是返回true的 默认是true
this.ensureNoOutParams(ms, parameterObject, boundSql);
List<E> list = (List)this.tcm.getObject(cache, key);
if (list == null) {
list = this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
this.tcm.putObject(cache, key, list);
}
return list;
}
}
return this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
还有一个条件就是需要当前的查询语句是配置了使用cache的,即上面源码的useCache()是返回true的,默认情况下所有select语句的useCache都是true,如果我们在启用了二级缓存后,有某个查询语句是我们不想缓存的,则可以通过指定其useCache为false来达到对应的效果。
如果我们不想该语句缓存,可使用useCache=”false
<select id="selectByPrimaryKey" resultMap="BaseResultMap" parameterType="java.lang.String" useCache="false">
select
<include refid="Base_Column_List"/>
from tuser
where id = #{id,jdbcType=VARCHAR}
</select>
cache定义的两种使用方式
上面说了要想使用二级缓存,需要在每个DAO对应的Mapper.xml文件中定义其中的查询语句需要使用cache来缓存数据的。
这有两种方式可以定义,一种是通过cache元素定义,一种是通过cache-ref元素来定义。
需要注意的是
对于同一个Mapper来讲,只能使用一个Cache,当同时使用了和时,定义的优先级更高(后面的代码会给出原因)。
Mapper使用的Cache是与我们的Mapper对应的namespace绑定的,一个namespace最多只会有一个Cache与其绑定。
cache元素定义
使用cache元素来定义使用的Cache时,最简单的做法是直接在对应的Mapper.xml文件中指定一个空的元素(看前面的代码),这个时候Mybatis会按照默认配置创建一个Cache对象,准备的说是PerpetualCache对象,更准确的说是LruCache对象(底层用了装饰器模式)。
具体的可看org.apache.ibatis.builder.xml.XMLMapperBuilder中的cacheElement()方法解析cache元素的逻辑。
...
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
} else {
this.builderAssistant.setCurrentNamespace(namespace);
this.cacheRefElement(context.evalNode("cache-ref"));
this.cacheElement(context.evalNode("cache"));//执行在后面
this.parameterMapElement(context.evalNodes("/mapper/parameterMap"));
this.resultMapElements(context.evalNodes("/mapper/resultMap"));
this.sqlElement(context.evalNodes("/mapper/sql"));
this.buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
}
} catch (Exception var3) {
throw new BuilderException("Error parsing Mapper XML. Cause: " + var3, var3);
}
}
...
private void cacheRefElement(XNode context) {
if (context != null) {
this.configuration.addCacheRef(this.builderAssistant.getCurrentNamespace(), context.getStringAttribute("namespace"));
CacheRefResolver cacheRefResolver = new CacheRefResolver(this.builderAssistant, context.getStringAttribute("namespace"));
try {
cacheRefResolver.resolveCacheRef();
} catch (IncompleteElementException var4) {
this.configuration.addIncompleteCacheRef(cacheRefResolver);
}
}
}
private void cacheElement(XNode context) throws Exception {
if (context != null) {
String type = context.getStringAttribute("type", "PERPETUAL");
Class<? extends Cache> typeClass = this.typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = this.typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false).booleanValue();
Properties props = context.getChildrenAsProperties();
this.builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, props);
//如果同时存在和,这里的设置会覆盖前面的cache-ref的缓存
}
}
空cache元素定义会生成一个采用最近最少使用算法最多只能存储1024个元素的缓存,而且是可读写的缓存,即该缓存是全局共享的,任何一个线程在拿到缓存结果后对数据的修改都将影响其它线程获取的缓存结果,因为它们是共享的,同一个对象。
cache元素可指定如下属性,每种属性的指定都是针对都是针对底层Cache的一种装饰,采用的是装饰器的模式。
- blocking:默认为false,当指定为true时将采用BlockingCache进行封装,blocking,阻塞的意思,使用BlockingCache会在查询缓存时锁住对应的Key,如果缓存命中了则会释放对应的锁,否则会在查询数据库以后再释放锁,这样可以阻止并发情况下多个线程同时查询数据,详情可参考BlockingCache的源码。
简单理解,也就是设置true时,在进行增删改之后的并发查询,只会有一条去数据库查询,而不会并发- eviction:eviction,驱逐的意思。也就是元素驱逐算法,默认是LRU,对应的就是LruCache,其默认只保存1024个Key,超出时按照最近最少使用算法进行驱逐,详情请参考LruCache的源码。如果想使用自己的算法,则可以将该值指定为自己的驱逐算法实现类,只需要自己的类实现Mybatis的Cache接口即可。除了LRU以外,系统还提供了FIFO(先进先出,对应FifoCache)、SOFT(采用软引用存储Value,便于垃圾回收,对应SoftCache)和WEAK(采用弱引用存储Value,便于垃圾回收,对应WeakCache)这三种策略。
这里,根据个人需求选择了,没什么要求的话,默认的LRU即可- flushInterval:清空缓存的时间间隔,单位是毫秒,默认是不会清空的。当指定了该值时会再用ScheduleCache包装一次,其会在每次对缓存进行操作时判断距离最近一次清空缓存的时间是否超过了flushInterval指定的时间,如果超出了,则清空当前的缓存,详情可参考ScheduleCache的实现。
- readOnly:是否只读
默认为false。当指定为false时,底层会用SerializedCache包装一次,其会在写缓存的时候将缓存对象进行序列化,然后在读缓存的时候进行反序列化,这样每次读到的都将是一个新的对象,即使你更改了读取到的结果,也不会影响原来缓存的对象,即非只读,你每次拿到这个缓存结果都可以进行修改,而不会影响原来的缓存结果;
当指定为true时那就是每次获取的都是同一个引用,对其修改会影响后续的缓存数据获取,这种情况下是不建议对获取到的缓存结果进行更改,意为只读(不建议设置为true)。
这是Mybatis二级缓存读写和只读的定义,可能与我们通常情况下的只读和读写意义有点不同。每次都进行序列化和反序列化无疑会影响性能,但是这样的缓存结果更安全,不会被随意更改,具体可根据实际情况进行选择。详情可参考SerializedCache的源码。- size:用来指定缓存中最多保存的Key的数量。其是针对LruCache而言的,LruCache默认只存储最多1024个Key,可通过该属性来改变默认值,当然,如果你通过eviction指定了自己的驱逐算法,同时自己的实现里面也有setSize方法,那么也可以通过cache的size属性给自定义的驱逐算法里面的size赋值。
- type:type属性用来指定当前底层缓存实现类,默认是PerpetualCache,如果我们想使用自定义的Cache,则可以通过该属性来指定,对应的值是我们自定义的Cache的全路径名称。
cache-ref元素定义
cache-ref元素可以用来指定其它Mapper.xml中定义的Cache,有的时候可能我们多个不同的Mapper需要共享同一个缓存的
是希望在MapperA中缓存的内容在MapperB中可以直接命中的,这个时候我们就可以考虑使用cache-ref,这种场景只需要保证它们的缓存的Key是一致的即可命中,二级缓存的Key是通过Executor接口的createCacheKey()方法生成的,其实现基本都是BaseExecutor,源码如下。
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (this.closed) {
throw new ExecutorException("Executor was closed.");
} else {
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
for(int i = 0; i < parameterMappings.size(); ++i) {
ParameterMapping parameterMapping = (ParameterMapping)parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
String propertyName = parameterMapping.getProperty();
Object value;
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = this.configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
return cacheKey;
}
}
打个比方我想在MenuMapper.xml中的查询都使用在UserMapper.xml中定义的Cache,则可以通过cache-ref元素的namespace属性指定需要引用的Cache所在的namespace,即UserMapper.xml中的定义的namespace,假设在UserMapper.xml中定义的namespace是cn.chenhaoxiang.dao.UserMapper,则在MenuMapper.xml的cache-ref应该定义如下。
<cache-ref namespace="cn.chenhaoxiang.dao.UserMapper"/>
二级缓存的使用原则
-
只能在一个命名空间下使用二级缓存
由于二级缓存中的数据是基于namespace的,即不同namespace中的数据互不干扰。在多个namespace中若均存在对同一个表的操作,那么这多个namespace中的数据可能就会出现不一致现象。 -
在单表上使用二级缓存
如果一个表与其它表有关联关系,那么久非常有可能存在多个namespace对同一数据的操作。而不同namespace中的数据互补干扰,所以就有可能出现多个namespace中的数据不一致现象。 -
查询多于修改时使用二级缓存
在查询操作远远多于增删改操作的情况下可以使用二级缓存。因为任何增删改操作都将刷新二级缓存,对二级缓存的频繁刷新将降低系统性能。
表缓存:
表缓存是将表对象的字典信息(定义的内容)缓存到内存中,提高访问效率。
相关结构
在mysql server层有两个与table相关的结构,分别为TABLE、TABLE_SHARE
TABLE_SHARE
TABLE_SHARE是表定义缓存,是一个静态表缓存,唯一对应一张表,所有用户都共享这个表对象;其内容从系统表获取(frm),它保存在table_def_cache(hash表,key为表名(含库名))中。
参数: table_definition_cache
TABLE
相对于TABLE_SHARE而言,Table可以看成是动态的,其内容会改变,会记录表操作状态;每个线程都会有TABLE对象,对应于同一个TABLE_SHARE.
当表实例不用时会对表进行缓存,再次使用直接取出即可,在缓存时可能需要调用ha_reset恢复实例状态。(其中会调用handler::reset(),用来重置引擎表状态),handler有可能被复用,如果不定义reset,可能出错。
缓存在表实例缓存空间,同时由TABLE_SHARE的free_table和used_table对表实例的使用情况进行管理。
参数: table_open_cache
实现过程
1、表被访问的时候,MySQL先从缓存中查找这个表,缓存中有这个表的TABLE ,直接读取,没有TABLE,会去系统表中获取TABLE SHARE,表字典对象的缓存是通过hash表来存储管理的,它保存在table_def_cache(hash表,key为表名(含库名))中,
如果这个表在之前访问过,就不需要构建结构体了,直接通过table_def_cache表找到对应的结构体。
2、表打开时,先从系统表中将表的所以信息读入内存,包括表名,库名,列,字符集等信息。读取的信息通过结构体table_share存储,这个表可以让所有用户访问,且不能被修改的,其大小由table_definition_cache控制
3、当用户得到table_share后,系统会**重新构造一个新的对象(名字叫table)**交给当前的操作,从table_share 到table实例的过程叫表结构实例化,当两个用户同时对同一个表进行操作时,就会实例化为两个TABLE,TABLE表的数量由table_open_cache参数。
相关的状态值
Open_table_definitions :代表当前缓存了多少.frm文件。
Opened_table_definitions:代表自从MySQL启动后,缓存了.frm文件的数量。 需要注意的是.frm文件是MySQL用于存放表结构的文件,对应myisam和innodb存储引擎都必须有的,可以通过show open tables 查看 这2个变量的值
Opened_tables :已打开的表的数量。如果opened_tables很大,那么使用table_open_cache价值可能太小了
Open_tables:打开的表的数量
写缓存:
首先的一点,数据库需要保证安全性,所以每一次写入数据库的时候,都会产生redo log,用来在数据库崩溃的时候进行回滚,同时,如果开启了binlog,那么数据库也会在每一条sql语句执行之后记录一条binlog,binlog是直接写入磁盘的,但是binlog是有自己的机制去管理的,与写操作的效率无关,这里可以排除其影响
这里探究的是数据落盘的原理:
我们知道,数据库拥有读缓存的功能,部分页会被从磁盘读到内存中来,那么当一个页在内存中时,发生了写操作,这个时候应该如何处理呢?
当要修改的数据页在内存中时,数据库采用的方式是将数据写入内存中,而不是直接写入磁盘中,然后再将redo log写入到磁盘。那么当这个数据页被从缓存中淘汰的时候,这些“脏数据页”就会被同步地写入磁盘,等于是将这期间发生的n次的落盘合并成了一次落盘。因为redo log是落盘的,所以即使数据库崩溃,缓存中的数据页全部丢失,也可以通过redo log将这些数据页找回来
(redo log是数据库用来在崩溃的时候进行数据恢复的日志,redo log的写入策略可以通过参数控制,并不一定是每一次写操作之后立即落盘redo log,在部分参数下,redo log可能是每秒集中写入一次,也有可能采取其他落盘策略,但是无论采用什么方式,redo log的量都是不会减少的,与数据写入的覆盖性不同,后一条redo log是不会覆盖前一条的,而是增量形式的,因此写redo log的操作,等同于是对磁盘某一小块区域的顺序I/O,而不像数据落盘一样随机在磁盘里写入,需要磁盘在多个地方移动磁头。所以redo log的落盘是IO操作当中消耗较少的一种,比数据直接刷回磁盘要优很多)
那么当一个页不在内存中时,发生了写操作,这个时候应该如何处理呢?
正常思路是将这个页读到内存中,然后对其进行写操作,然后再进行一次正常的内存写操作和redo log的磁盘写操作。但是对于写多读少的业务,每一次写操作不命中内存就需要一次磁盘读操作,这显然会影响性能。
innodb对这里的写入操作进行了优化:写操作并不会立即写入到磁盘,而是只记录缓冲变更,等未来数据从磁盘真正被读出来的时候,才会将缓冲变更合并到缓冲池里,这种做法可以有效减少写操作时候的磁盘读取,提高数据库性能,这里对于数据变更的缓存区,就是写缓冲
写缓冲等于是将写操作没有命中缓存的情况转化为了命中缓存的情况,由于redo log依然是按策略落盘的,可以理解为数据是安全的,而写缓存的数据也不是长期保留在缓存里的,数据库有策略定期将写缓存中的数据写入磁盘的操作,这里的写缓冲写入策略可以由数据库参数控制(有的采取定时写入,有的采取满则写入,也有的采取闲时写入)
注意:当数据库全都是唯一索引的时候,写缓冲是没有办法工作的,因为不将所有数据都读出来,没有办法判断这次写操作是否合法,是否符合唯一索引的条件
相关参数:innodb_change_buffer_max_size:写缓冲占整个缓冲池的大小比例,默认25%,对于写多读少的业务,才需要调大这个参数,对于读多写少的业务,可以调小该数值
innodb_change_buffering:配置使用写缓冲的操作类型,可选all、none、update、deletes等
Sqlsession:
每个线程都应该有它自己的SqlSession实例。SqlSession的实例不能被共享,也是线程不安全的。因此最佳的范围是请求或方法范围。绝对不能将SqlSession实例的引用放在一个类的静态字段甚至是实例字段中。
如果说SqlSessionFactory相当于数据库连接池,那么SqlSession就相当于一个数据库连接(Connection对象),
你可以在一个事务里面执行多条SQL,然后通过它的commit、rollback等方法,提交或者回滚事务。所以它应该存活在一个业务请求中,
处理完整个请求后,应该关闭这条连接,让它归还给SqlSessionFactory,否则数据库资源就很快被消耗精光,系统应付瘫痪,所以用try…catch…fanally语句来保证其正确关闭。
SqlSessionFactoryBuilder:
SqlSessionFactoryBuilder的作用就是在于创建SqlSessionFactory,创建成功后,SqlSessionFactoryBuilder就失去了作用,
所以它只能存在于创建SqlSessionFactory的方法中,而不要让其长期存在
SqlSessionFactory:
SqlSessionFactory可以被认为是一个数据库连接池,它的作用是创建SqlSession接口对象。因为MyBatis的本质就是Java对数据库的操作,
所以SqlSessionFactory的生命周期在于于整个MyBatis的应用之中,所以一旦创建了SqlSessionFactory的生命周期就等同于MyBatis的应用周期。
由于SqlSessionFactory是一个对数据库的连接池,所以它占据着数据库的连接资源。如果创建多个SqlSessionFactory,那么就存在多个数据库连接池,
这样不利于对数据资源的控制,也会导致连接资源被消耗光,出现系统宕机等情况,所以尽量避免发生这样的情况。因此在一般的应用中我们往往希望SqlSessionfactory作为一个单例,让它在应用中不共享。
Mapper:
Mapper是一个接口,它由SqlSession所创建,所以它的最大生命周期至多和SqlSession保持一致,尽管它很好用,
但是由于SqlSession关闭,它的数据库连接资源也会消失,所以它的生命周期应该小于等于SqlSession的生命周期。
Mapper代表是一个请求中的业务处理,所以它应该在一个请求中,一旦处理完了相关的业务,就应该废弃它。
三、MySQL中的数据类型
常见的数据类型:
整数型:
- 整形
- 小数
字符型:
- 字符串:char、varchar
- 文本:text、blob(较长的二进制数据
日期型:
1、整型
根据数值取值范围的不同MySQL 中的整数类型可分为5种,分别是TINYINT、SMALUNT、MEDIUMINT、INT和 BIGINT。 MySQL不同整数类型所对应的字节大小和取值范围而最常用的为INT类型
有无符号代表:是否可存储负数
特点:
- 如果不设置无符号还是有符号,默认是有符号,如果想设置无符号,需要添加 unsigned关键字
- 如果插入的数值超出了整形的范围,会报out of range异常,并且插入临界值。
- 如果不设置长度,会有默认的长度。int有符号默认长度为11,int无符号默认长度为10。
- 长度代表了显示的最大宽度,如果不够会用0在左边填充,但必须搭配zerofill使用,并且默认变为无符号整形。
| 数据类型 | 字节数 | 说明 | 无符号数的取值范围 | 有符号数的取值范围 |
|---|---|---|---|---|
| tinyint | 1 | 非常小的数据 | 0~255 | -128~127 |
| smallint | 2 | 较小的数据 | 0~65535 | -32768~32768 |
| mediumint | 3 | 中等大小的数据 | 0~16777215 | -8388608~8388608 |
| int|integer | 4 | 标准整数 | 0~4294967295 | -2147483648~ 2147483648 |
| bigint | 5 | 大型整数 | 0~ | -9223372036854775808~ 9223372036854775808 |
如何设置有符号和无符号:
drop table if exists tab_int;
create table tab_int(
t1 int(7) zerofill【0填充】,
t2 int(7) zerofill【0填充】 unsigned【设置无符号】
)
desc tab_int;
insert into tab_int values(123,123);
insert into tab_int values(-123,-123);
insert into tab_int values(2147483648,485623962);
#结果
t1=0000123,-123,2147483648
t2=0000123,0,2147483648
int类型的绝对值不一定是整数:
这个极特殊情况下就是当hashCode是Integer.MIN_VALUE,即整数能表达的最小值的时候,可以代码验证下:
public static void main(String[] args) {
System.out.println(Math.abs(Integer.MIN_VALUE));
}
执行以上代码,得到的结果是:
-2147483648
为什么会这样呢?
这要从Integer的取值范围说起,int的取值范围是-2^31 —— (2^31) - 1,即-2147483648 至 2147483647
那么,当我们使用abs取绝对值时候,想要取得-2147483648的绝对值,
那应该是2147483648。
但是,2147483648大于了2147483647,即超过了int的取值范围。
这时候就会发生越界。
2147483647用二进制的补码表示是:
01111111 11111111 11111111 11111111
这个数 +1 得到:
10000000 00000000 00000000 00000000
这个二进制就是-2147483648的补码。
虽然,这种情况发生的概率很低,只有当要取绝对值的数字是-2147483648的时候,得到的数字还是个负数。
那么,如何解决这个问题呢?
既然是以为越界了导致最终结果变成负数,那就解决越界的问题就行了,那就是在取绝对值之前,把这个int类型转成long类型,这样就不会出现越界了。
如,前面我们的分表逻辑修改为
Math.abs((long)orderId.hashCode()) % 1024;
public static void main(String[] args) {
System.out.println(Math.abs((long)Integer.MIN_VALUE));
}
得到的结果就是:
2147483648
2、小数
小数分为:浮点数、定点数
在MySQL数据库中使用浮点数和定点数来存储小数。
浮点数的类型:有两种:单精度浮点数类型(float)和双精度浮点数类型(double)。
定点数类型:只有一种即decimal类型。
请注意:decimal类型的有效取值范围是由M和D决定的。其中,M表示的是数据的长度,D表示的是小数点后的长度。比如,将数据类型为DECIMAL(6,2)的数据6.5243 插人数据库后显示的结果为6.52
| 数据类型 | 字节数 | 说明 | 有符号的取值范围 | 无符号的取值范围 |
|---|---|---|---|---|
| float | 4 | 单精度浮点数 | -3.402823466E+38~-1.175494351E-38 | 0和1.175494351E-38~3.402823466E+38 |
| double | 8 | 双精度浮点数 | -1.7976931348623157E+308~2.2250738585072014E-308 | 0和2.2250738585072014E-308~1.7976931348623157E+308 |
| dec(M,D)或decimal(M,D) | M+2 | 字符串形式的浮点数 | 最大取值范围与double相同,给定decimal的有效取值范围由M和D决定。M表示的是数据的长度。 |
原则:
-
M代表整数部位+小数部位的个数,D表示的是小数点后的长度
-
decimal(M,D):M和D都可以省略,M默认为10,D默认为0
-
如果超出范围,则报out or range异常,并且插入临界值
-
如果精度要求较高,则优先考虑使用定点数
-
float和double:会根据插入的数值的精度来决定精度
-
定点数decimal:定点数的精确度较高,如果要求插入数值的精度较高如货币运算等则考虑使用。
-
所选择的类型越简单越好,满足业务情况下保存数值的类型越小越好
3、字符串
在MySQL中常用char和 varchar表示字符串。两者不同的是:varchar存储可变长度的字符串。
当数据为char(M)类型时,不管插入值的长度是实际是多少它所占用的存储空间都是M个字节;而varchar(M)所对应的数据所占用的字节数为实际长度加1。
| 插入值 | CHAR(3) | 存储需求 | VARCHAR(3) | 存储需求 |
|---|---|---|---|---|
| ‘’ | ‘’ | 3个字节 | ‘’ | 1个字节 |
| ‘a’ | ‘a’ | 3个字节 | ‘a’’ | 2个字节 |
| ‘ab’ | ‘ab’ | 3个字节 | ‘ab’ | 3个字节 |
| ‘abc’ | ‘ab’ | 3个字节 | ‘abc’ | 4个字节 |
| ‘abcd’ | ‘ab’ | 3个字节 | ‘abc’ | 4字节 |
char和varchar类型用来保存mysql中较短的字符串
| 字符串类型 | 最多字符串 | M的意思 | 描述及存储需求 | 特点 | 空间的消耗 | 效率 |
|---|---|---|---|---|---|---|
| char(M) | M | 最大的字符数,可以省略,默认为1 | M为0~255之间的整数 | 固定长度的字符 | 比较耗费 | 高 |
| varchar(M) | M | 最大的字符数,不可以省略 | M为0~65535之间的整数 | 可变长度的字符 | 比较节省 | 低 |
4、文本
文本类型用于表示大文本数据,例如,文章内容、评论、详情等,
| 数据类 | 储存范围 |
|---|---|
| tinytext | 0~255字节 |
| text | 0~65535字节 |
| mediumtext | 0~16777215字节 |
| longtext | 0~4294967295字节 |
5、日期与时间
MySQL提供的表示日期和时间的数据类型分别是 :YEAR、DATE、TIME、DATETIME 和 TIMESTAMP。
| 数据类型 | 字节数 | 取值范围 | 日期格式 | 零值 | 零值 |
|---|---|---|---|---|---|
| YEAR | 1 | 1901~2155 | YYYY | 0000 | |
| DATE | 4 | 1000-01-01~9999-12-31 | YYYY-MM-DD | 0000-00-00 | |
| TIME | 3 | -838:59:59~ 838:59:59 | HH:MM:SS | 00:00:00 | |
| DATETIME | 8 | 1000-01-01 00:00:00~9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 0000-00-00 00:00:00 | 不受 |
| TIMESTAMP | 4 | 1970-01-01 00:00:01~2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 0000-00-00 00:00:00 | 受 |
create table tab(
t1 datetime,
t2 timestamp
);
insert into tab values(now(),now());
select * from tab;
show variables like 'time_zone';
set time_zone='+9:00';
1.timestamp和实际时区有关,更能反映实际的日期,而datetime则只能反映出插入时的当地时区
2.timestamp的属性受mysql版本和sqlMode的影响很大
YEAR类型
YEAR类型用于表示年份,在MySQL中,可以使用以下三种格式指定YEAR类型 的值。
1、使用4位字符串或数字表示,范围为’1901’—'2155’或1901—2155。例如,输人 ‘2019’或2019插人到数据库中的值均为2019。
2、使用两位字符串表示,范围为’00’—‘99’。其中,‘00’—'69’范围的值会被转换为 2000—2069范围的YEAR值,‘70’—'99’范围的值会被转换为1970—1999范围的YEAR 值。例如,输人’19’插人到数据库中的值为2019。
3、使用两位数字表示,范围为1—99。其中,1—69范围的值会被转换为2001— 2069范围的YEAR值,70—99范围的值会被转换为1970—1999范围的YEAR值。例 如,输人19插入到数据库中的值为2019。
请注意:当使用YEAR类型时,一定要区分’0’和0。因为字符串格式的’0’表示的YEAR值是2000而数字格式的0表示的YEAR值是0000。
TIME类型
TIME类型用于表示时间值,它的显示形式一般为HH:MM:SS,其中,HH表示小时, MM表示分,SS表示秒。在MySQL中,可以使用以下3种格式指定TIME类型的值。
1、以’D HH:MM:SS’字符串格式表示。其中,D表示日可取0—34之间的值, 插人数据时,小时的值等于(DX24+HH)。例如,输入’2 11:30:50’插人数据库中的日期为59:30:50。
2、以’HHMMSS’字符串格式或者HHMMSS数字格式表示。 例如,输人’115454’或115454,插入数据库中的日期为11:54:54
3、使用CURRENT_TIME或NOW()输人当前系统时间。
datetime类型
DATETIME类型用于表示日期和时间,它的显示形式为’YYYY-MM-DD HH: MM:SS’,其中,YYYY表示年,MM表示月,DD表示日,HH表示小时,MM表示分,SS 表示秒。在MySQL中,可以使用以下4种格式指定DATETIME类型的值。
以’YYYY-MM-DD HH:MM:SS’或者’YYYYMMDDHHMMSS’字符串格式表示的日期和时间,取值范围为’1000-01-01 00:00:00’—‘9999-12-3 23:59:59’。例如,输人’2019-01-22 09:01:23’或 ‘20140122_0_90123’插人数据库中的 DATETIME 值都为 2019-01-22 09:01:23。
1、以’YY-MM-DD HH:MM:SS’或者’YYMMDDHHMMSS’字符串格式表示的日期和时间,其中YY表示年,取值范围为’00’—‘99’。与DATE类型中的YY相同,‘00’— '69’范围的值会被转换为2000—2069范围的值,‘70’—'99’范围的值会被转换为1970—1999范围的值。
2、以YYYYMMDDHHMMSS或者YYMMDDHHMMSS数字格式表示的日期 和时间。例如,插入20190122090123或者190122090123,插人数据库中的DATETIME值都 为 2019-01-22 09:01:23。
3、使用NOW来输人当前系统的日期和时间。
timestamp类型
TIMESTAMP类型用于表示日期和时间,它的显示形式与DATETIME相同但取值范围比DATETIME小。在此,介绍几种TIMESTAMP类型与DATATIME类型不同的形式:
1、使用CURRENT_TIMESTAMP输人系统当前日期和时间。
2、输人NULL时系统会输人系统当前日期和时间。
3、无任何输人时系统会输入系统当前日期和时间。
在MySQL上述三个大版本中,默认时间戳(Timestamp)类型的取值范围为’1970-01-01 00:00:01’ UTC 至’2038-01-19 03:14:07’ UTC,数据精确到秒级别,该取值范围包含约22亿个数值,因此在MySQL内部使用4个字节INT类型来存放时间戳数据:
1、在存储时间戳数据时,先将本地时区时间转换为UTC时区时间,再将UTC时区时间转换为INT格式的毫秒值(使用UNIX_TIMESTAMP函数),然后存放到数据库中。
2、在读取时间戳数据时,先将INT格式的毫秒值转换为UTC时区时间(使用FROM_UNIXTIME函数),然后再转换为本地时区时间,最后返回给客户端。
在MySQL 5.6.4及之后版本,可以将时间戳类型数据最高精确微秒(百万分之一秒),数据类型定义为timestamp(N),N取值范围为0-6,默认为0,如需要精确到毫秒则设置为Timestamp(3),如需要精确到微秒则设置为timestamp(6),数据精度提高的代价是其内部存储空间的变大,但仍未改变时间戳类型的最小和最大取值范围。
时间戳字段定义主要影响两类操作:
1、插入记录时,时间戳字段包含DEFAULT CURRENT_TIMESTAMP,如插入记录时未指定具体时间数据则将该时间戳字段值设置为当前时间
2、更新记录时,时间戳字段包含ON UPDATE CURRENT_TIMESTAMP,如更新记录时未指定具体时间数据则将该时间戳字段值设置为当前时间。
PS1:CURRENT_TIMESTAMP表示使用CURRENT_TIMESTAMP()函数来获取当前时间,类似于NOW()函数
根据上面两类操作,时间戳列可以有四张组合定义,其含义分别为:
1、当字段定义为timestamp,表示该字段在插入和更新时都不会自动设置为当前时间。
2、当字段定义为timestamp DEFAULT CURRENT_TIMESTAMP,表示该字段仅在插入且未指定值时被赋予当前时间,再更新时且未指定值时不做修改。
3、当字段定义为timestamp ON UPDATE CURRENT_TIMESTAMP,表示该字段在插入且未指定值时被赋值为"0000-00-00 00:00:00",在更新且未指定值时更新为当前时间。
4、当字段定义为timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,表示该字段在插入或更新时未指定值,则被赋值为当前时间。
PS1:在MySQL中执行的建表语句和最终表创建语句会存在差异,建议使用SHOW CREATE TABLE TB_XXX获取已创建表的建表语句。
时间戳字段在MySQL各版本的使用差异:
1、在MySQL 5.5及之前版本中,仅能对一个时间戳字段定义DEFUALT CURRENT_TIMESTAMP或ON UPDATE CURRENT_TIMESTAMP,但在MySQL 5.6和MySQL 5.7版本中取消了该限制;
2、在MySQL 5.6版本中参数explicit_defaults_for_timestamp默认值为1,在MySQL 5.7版本中参数explicit_defaults_for_timestamp默认值为0;
3、在MySQL 5.5和MySQL 5.7版本中timestamp类型默认为NOT NULL,在在MySQL 5.6版本中timestamp类型默认为NULL;
4、当建表语句中定于c1 timestamp 时,
在MySQL 5.5中等价于c1 timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP;
在MySQL 5.6中等价于c1 timestamp NULL DEFAULT NULL;
在MySQL 5.7中等价于c1 timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP;
5、当建表语句中c1 timestamp default 0时,
在MySQL 5.5中等价于c1 timestamp NOT NULL DEFAULT ‘0000-00-00 00:00:00’;
在MySQL 5.6中等价于c1 timestamp NULL DEFAULT ‘0000-00-00 00:00:00’;
在MySQL 5.7中等价于c1 timestamp NOT NULL DEFAULT ‘0000-00-00 00:00:00’;
PS1: MySQL 5.6版本和MySQL 5.7版本中主要差异受参数explicit_defaults_for_timestamp的默认值影响。
PS2:当时间戳列的默认值为’0000-00-00 00:00:00’时,使用“不在时间戳取值范围内”的该默认值并不会产生警告。
时间戳类型引发的异常:
当MySQL参数time_zone=system时,查询timestamp字段会调用系统时区做时区转换,而由于系统时区存在全局锁问题,在多并发大数据量访问时会导致线程上下文频繁切换,CPU使用率暴涨,系统响应变慢设置假死。
时间戳类型和时间类型选择:
在部分"数据库指导"文档中,会推荐使用timestamp类型代替datetime字段,其理由是timestamp类型使用4字节,而datetime字段使用8字节,但随着磁盘性能提升和内存成本降低,在实际生产环境中,使用timestamp类型并不会带来太多性能提升,反而可能因timestamp类型的定义和取值范围限制和影响业务使用。
在MySQL 5.6.4及之后版本,可以将时间戳类型(timestamp)数据最高精确微秒,也同样可以将时间类型(datetime)数据最高精确微秒,时间类型(datetime)同样可以获得timestamp类型相同的效果,如将字段定义为 dt1 DATETIME(3) NOT NULL DEFAULT NOW(3) ON UPDATE NOW(3); 时间类型(datetime)的存取范围’1000-01-01 00:00:00.000000’ 至 ‘9999-12-31 23:59:59.999999’,能更好地存放各时间段的数据。
时间戳类型使用建议:
1、在只关心数据最后更新时间的情况下,建议将时间戳列定义为TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP;
2、在关心创建时间和更新时间的情况下,建议将更新时间设置为时间戳字段,将创建时间定义为DAETIME 或 TIMESTAMP DEFAULT ‘0000-00-00 00:00:00’,并在插入记录时显式指定创建时间;
3、建议在表中只定义单个时间戳列,并显式定义DEFAULT 和 ON UPDATE属性;
4、虽然在MySQL中可以对时间戳字段赋值或更新,但建议仅在必要的情况下对时间戳列进行显式插入和更新;
5、建议将time_zone参数设置为system外的值,如中国地区服务器设置为’+8:00’;
6、建议将MySQL线下测试版本和线上生产版本保持一致。
6、二进制类型
在MySQL中常用BLOB存储二进制类型的数据,例如:图片、PDF文档等
| 数据类型 | 储存范围 |
|---|---|
| tinyblob | 0~255字节 |
| blob | 0~65535字节 |
| mediumblob | 0~16777215字节 |
| longblob | 0~4294967295字节 |
7、Enum类型
说明:又称为枚举类型,要求插入的值必须属于列表中指定的值之一。
如果列表成员为1~255,则需要1个字节存储
如果列表成员为255~65535,则需要2个字节存储,最多需要65535个成员!
create table tab_char(
c1 enum('a','b','c')
);
isnert into tab_char values('a');
isnert into tab_char values('b');
isnert into tab_char values('c');
isnert into tab_char values('A');
isnert into tab_char values('B');
isnert into tab_char values('C');
#都可以添加成功
8、Set类型
说明:和Enum类型类似,里面可以保存0~64个成员。和Enum类型最大的区别是:Set类型一次可以选取多个成员,而Enum只能选一个根据成员个数不同,存储所占的字节也不同。
| 成员数 | 字节数 |
|---|---|
| 1~8 | 1 |
| 9~16 | 2 |
| 17~24 | 3 |
| 25~32 | 4 |
| 33~64 | 8 |
create table tab(
s1 set('a','b','c','d')
);
insert into tab values('a');
insert into tab values('A','B');
insert into tab values('a','c','d');
#都可以添加成功
四、数据库操作
操作数据库
#启动mysql服务:
net start mysql(我的电脑中mysql服务名称)。
#关闭mysql服务:
net stop mysql(我的电脑中mysql服务名称)。
#服务的登录和退出:
1.通过mysql自带的客户端,只限于root用户。
2.通过windows自带的客户端
登录:mysql 【-h主机名 -端口号】 -u用户名 -p密码 //如果连接本地localhost【】中内容可以省略
退出:exit或ctrl+c
#创建数据库:
create database 【if not exists】 数据库名称 【character set 字符集名】;
#修改表
alter database 库名 character set 字符集名;
#删除库
drop database 【if exists】 库名;
#查看表结构:
desc 表名;
#查看服务的的版本:
1.登录到mysql服务端。
select version();
2.没有登录到mysql服务端。
mysql --version
或
mysql --V
#创建一个叫db1的数据库:
create database 【if not exists】 db1;
#创建数据库后查看该数据库基本信息:
show create database db1;
#删除数据库:
drop database 【if exists】 db1;
#查询出MySQL中所有的数据库:
show databases;
#查看当前库中的所有表:
show tables
#查看其他库的所有表:
show tables from 库名;
#将数据库的字符集修改为gbk:
alter database db1 character set gbk;
#切换数据库 MySQL命令:
use db1;
#查看当前使用的数据库:
select database();
#查看MySQL服务器配置信息
查看MySQL服务器配置信息
#查看MySQL服务器运行的各种状态值
show global status;
#慢查询
show variables like '%slow%';
show global status like '%slow%';
#连接数
show variables like 'max_connections';
show global status like 'max_used_connections';
#key_buffer_size
key_buffer_size是对MyISAM表性能影响最大的一个参数, 不过数据库中多为Innodb。
为了最小化磁盘的 I/O , MyISAM 存储引擎的表使用键高速缓存来缓存索引,这个键高速缓存的大小则通过 key-buffer-size 参数来设置。如果应用系统中使用的表以 MyISAM 存储引擎为主,则应该适当增加该参数的值,以便尽可能的缓存索引,提高访问的速度。
默认情况下,所有的索引都使用相同的键高速缓存,当访问的索引不在缓存中时,使用 LRU ( Least Recently Used 最近最少使用)算法来替换缓存中最近最少使用的索引块。为了进一步避免对键高速缓存的争用,从 MySQL5.1 开始,可以设置多个键高速缓存,并为不同的索引键指定使用的键高速缓存。
show variables like 'key_buffer_size';
show global status like 'key_read%';
show global status like 'key_blocks_u%';
#临时表
show global status like 'created_tmp%';
#open table 的情况
show global status like 'open%tables%';
#进程使用情况
show global status like 'Thread%';
#查询服务器 thread_cache_size配置:
show variables like 'thread_cache_size';
#查询缓存(query cache)
show global status like 'qcache%';
Qcache_free_blocks:缓存中相邻内存块的个数。数目大说明可能有碎片。FLUSH QUERY CACHE会对缓存中的碎片进行整理,从而得到一个空闲块。
Qcache_free_memory:缓存中的空闲内存。
Qcache_hits:每次查询在缓存中命中时就增大
Qcache_inserts:每次插入一个查询时就增大。命中次数除以插入次数就是不中比率。
Qcache_lowmem_prunes:缓存出现内存不足并且必须要进行清理以便为更多查询提供空间的次数。这个数字最好长时间来看;如果这个数字在不断增长,就表示可能碎片非常严重,或者内存很少。(上面的 free_blocks和free_memory可以告诉您属于哪种情况)
Qcache_not_cached:不适合进行缓存的查询的数量,通常是由于这些查询不是 SELECT 语句或者用了now()之类的函数。
Qcache_queries_in_cache:当前缓存的查询(和响应)的数量。
Qcache_total_blocks:缓存中块的数量。
#query_cache的配置:
show variables like 'query_cache%';
query_cache_limit:超过此大小的查询将不缓存
query_cache_min_res_unit:缓存块的最小大小
query_cache_size:查询缓存大小
query_cache_type:缓存类型,决定缓存什么样的查询,示例中表示不缓存 select sql_no_cache 查询
query_cache_wlock_invalidate:当有其他客户端正在对MyISAM表进行写操作时,如果查询在query cache中,是否返回cache结果还是等写操作完成再读表获取结果。
query_cache_min_res_unit的配置是一柄”双刃剑”,默认是4KB,设置值大对大数据查询有好处,但如果你的查询都是小数据查询,就容易造成内存碎片和浪费。
查询缓存碎片率 = Qcache_free_blocks / Qcache_total_blocks * 100%
如果查询缓存碎片率超过20%,可以用FLUSH QUERY CACHE整理缓存碎片,或者试试减小query_cache_min_res_unit,如果你的查询都是小数据量的话。
查询缓存利用率 = (query_cache_size – Qcache_free_memory) / query_cache_size * 100%
查询缓存利用率在25%以下的话说明query_cache_size设置的过大,可适当减小;查询缓存利用率在80%以上而且Qcache_lowmem_prunes > 50的话说明query_cache_size可能有点小,要不就是碎片太多。
查询缓存命中率 = (Qcache_hits – Qcache_inserts) / Qcache_hits * 100%
示例服务器 查询缓存碎片率 = 20.46%,查询缓存利用率 = 62.26%,查询缓存命中率 = 1.94%,命中率很差,可能写操作比较频繁吧,而且可能有些碎片。
#排序使用情况
show global status like 'sort%';
Sort_merge_passes 包括两步。MySQL 首先会尝试在内存中做排序,使用的内存大小由系统变量 Sort_buffer_size 决定,如果它的大小不够把所有的记录都读到内存中,MySQL 就会把每次在内存中排序的结果存到临时文件中,等 MySQL 找到所有记录之后,再把临时文件中的记录做一次排序。这再次排序就会增加 Sort_merge_passes。实际上,MySQL 会用另一个临时文件来存再次排序的结果,所以通常会看到 Sort_merge_passes 增加的数值是建临时文件数的两倍。因为用到了临时文件,所以速度可能会比较慢,增加 Sort_buffer_size 会减少 Sort_merge_passes 和 创建临时文件的次数。但盲目的增加 Sort_buffer_size 并不一定能提高速度,另外,增加read_rnd_buffer_size(3.2.3是record_rnd_buffer_size)的值对排序的操作也有一点的好处
#文件打开数(open_files)
show global status like 'open_files';
show variables like 'open_files_limit';
#表锁情况
show global status like 'table_locks%'
Table_locks_immediate 表示立即释放表锁数,Table_locks_waited表示需要等待的表锁数,如果 Table_locks_immediate / Table_locks_waited > 5000,最好采用InnoDB引擎,因为InnoDB是行锁而MyISAM是表锁,对于高并发写入的应用InnoDB效果会好些.
#表扫描情况
show global status like 'handler_read%';
#调出服务器完成的查询请求次数:
show global status like 'com_select';
#查看字符编码:
1.MySQL数据库服务器和数据库MySQL字符集。
show variables like '%char%';
2.MySQL数据表(table)的MySQL字符集。
show table status from sqlstudy_db like '%countries%';
3.MySQL数据列(column)的MySQL字符集。
show full columns from countries;
#创建库Books
create database if not exists books;
#库的修改
rename database books to 新库名;
#linux下修改字符编码,
只对修改完字符编码后创建的表有效,之前的创建的无效。最好的方法就是创建完库之后马上修改字符编码。
#查看你Mysql已提供什么存储引擎
show engines;

RPM下操作MySQL:
![]()
#官网下载地址
http://dev.mysql.com/downloads/mysql/
#检查当前系统是否安装过MySQL:
查询命令:rpm -qa|grep -i mydql
删除命令:rpm -e RPM软件包名 (该名字是上一个命令查询来的名字)
#安装
rpm -ivh MySQL-server-5.5.48-1.linux2.6.i386.rpm
#查看MySQL安装时创建的MySQL用户和MySQL组
cat/etc/passwd|grep mysql
cat/etc/group/grep mysql
#或
mysqladmin --version
#在linux下查看安装目录
ps -ef|grep mysql
备注:/bin/sh/usr/bin/mysql_safe --datadir=/var/lib/mysql --pid-file=/var/lib/mysql
#第一次安装MySQL,设置root用户的密码
/user/bin/mysqladmin -u root password 123456
#mysql数据库文件的存放路径
/var/lib/mysql/
备注:/var/lib/mysql/atguigu.cloud.pid
#配置文件目录
/usr/share/mysql
备注:mysql.server命令及配置文件
#相关命令目录
/usr/bin
备注:mysqladmin mysqldump等命令
#启停相关脚本
/etc/init.d/mysql
#重启MySQL
service mysql stop;
service mysql start;
#启动mysql服务
service mysql start
#windows中的配置文件
my.ini文件
#Linux中的配置文件
/etc/my.cnf文件
#windows下:
D:\devSoft\MySQLService5.5\data目录下可以挑选很多库
#Linux下:
看看当前系统中的全部库后再进去,默认路径:/var/lib/mysql
frm文件 --存放表结构
myd文件 --存放表数据
myi文件 --存放表索引
#查看mysql现在已提供什么存储引擎
mysql>show engines;
#查看mysql当前默认的存储引擎
mysql>show variables like '%storage_engine%';
#mysql主从时,查看master日志
show master status;
#mysql主从时,查看slave日志
show slave status
#查询数据库当前设置的最大连接数
mysql> show variables like ‘%max_connections%’;
#可以在/etc/my.cnf里面设置数据库的最大连接数
max_connections = 1000
#查看表上加过的锁
show open tables;
#显示表中的索引
show index from 表名;
#解锁master表
unlock tables;
安装MySQL前的检查工作:
检查当前系统是否安装过mysql
检查当前mysql依赖环境
检查/tmp文件夹权限



Mysql参数的设置:



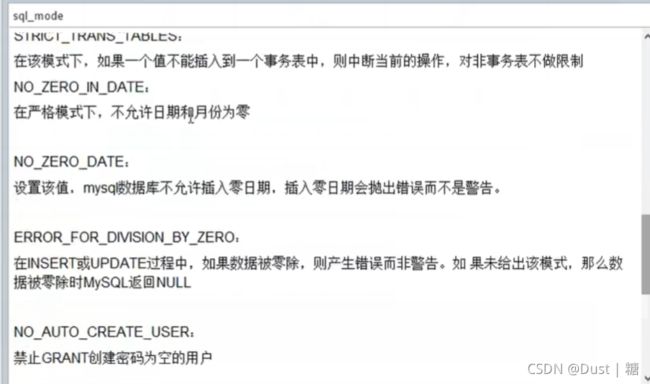






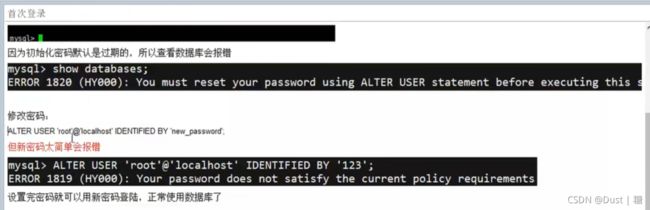
没装过MySQL:

已装过MySQL:

修改MySQL配置:








将竖行显示修改为横行显示:sql语句后加\G

操作表
在操作数据表之前应先指定操作是在哪个数据库中进行的 。
#表的管理:
创建:create
修改:alter
删除:drop
alter table 表名 add|drop|modify|change column
#创建表语法:
create table [if not exists] 表名(
字段名 字段类型(长度) 【约束】,
字段名 字段类型(长度) 【约束】,
。。。
字段名 字段类型(长度) 【约束】
)
#示例:创建学生表 MySQL命令:
create table student(
id int,
name varchar(20),
gender varchar(10),
birthday date
);
#查看当前数据库中所有表 MySQL命令:
show tables;
#查表的基本信息 MySQL命令:
show create table student;
#查看表的字段信息,直接转到修改表页面:
desc student;
#修改表名:
#语法:alter table 表名 rename【to】新表名;
alter table student rename to stu;
#修改字段名
#语法:alter table 表名 change colunm 旧列名 新列明 类型;
alter table book change column publishdata pubDate datetime;
alter table stu change name sname varchar(10);
#修改列的类型或约束
#语法:alter table 表名 modify 列名 新类型【新约束】;
alter table book modify column pubdate timestamp;
#修改字段数据类型:
alter table stu modify sname int;
#添加字段
#语法:alter table 表名 add column 列名 类型 【first|after字段名】;
alter table author add column annual double;
alter table author add annual double;
#添加新列并且排在第一
alter table test_add add column newT int first;
#添加newT1字段在t2字段后面
alter table test_add add column newT1 int after t2;
#删除字段:
#语法:alter table 表名 drop column 列名;
alter table stu drop column 【if exists】 address;
alter table stu drop 【if exists】 address;
#删除数据表:
drop table【if exists】表名;
drop table 表名;
#仅仅复制表的结构
#语法:create table 表名 like 旧表;
create table copy like author;
#复制表的机构+数据
#语法:create table 表名 select 查询列表 from 旧表 【where 筛选】
create table copy2 select * from author;
#只复制部分数据
create table copy3
select id,au_name form author where nation='中国';
#仅仅复制某些字段
create table copy4
select id,au_name from author where 1=2;
#where后面加恒不等于或0,1代表恒等于。
#通用的写法
drop database if exists 旧库名;
create database 新库名;
drop table if exists 旧表名;
create table 表名;
#将表departments中的数据插入新表dept2中
create table dept2
select department_id,department_name from departments;
#将列Last_name的长度增加到50
alter table emp5 modify column last_name varchar(50);
#根据表employees创建employees2
create table employees2 like myemployees.employees;
#将表名employee是2重命名为emp5
alter table employees2 rename to emp5;
#在表dept和emp5中添加新列test_column,并检查所做的操作
alter table emp5 add column test_column int;
#直接删除表emp5中的列dept_id
alter table emp5 drop column dept_id;
#查看表中所有的索引
show index from 表名;
#设置字符编码
set name gbk
添加数据(insert):
每个字段与其值是严格一一对应的。也就是说:每个值、值的顺序、值的类型必须与对应的字段相匹配。
方式一:
语法:insert into 表名(字段名,…) values(值,…);
特点:
- 要求值得类型和字段的类型要一致或兼容
- 字段的个数和顺序不一定与原始表中的字段个数和顺序一致,但必须保证值和字段一一对应
- 假如表中有可以为null的字段,注意可以通过以下两种方式插入null值
- 字段和值都省略
- 字段写上,值使用null
- 字段和值得个数必须一致
- 字段名可以省略,默认所有列
方式二:
语法:insert into 表名 set 字段=值,字段=值,…;
两种方式的区别:
1.方式一支持一次插入多行,方式二不支持
2.方式一支持子查询,方式二种不支持
#第一种:为表中字段插入数据
INSERT INTO 表名(字段名1,字段名2,...) VALUES (值 1,值 2,...);
#第二种:添加的方法
insert into beauty set id=19,name='刘涛',phone='999';
#示例:向学生表中插入一条学生信息 MySQL命令:
insert into student (id,name,age,gender) values (1,'bob',16,'male');
#插入多条记录:
INSERT INTO 表名 [(字段名1,字段名2,...)]VALUES (值 1,值 2,…),(值 1,值 2,…),...;
#第一种:向学生表中插入多条学生信息 MySQL命令:
insert into student (id,name,age,gender) values (2,'lucy',17,'female'),(3,'jack',19,'male'),(4,'tom',18,'male');
#第二种:向学生表中插入多条学生信息 MySQL命令:
insert into student
select 2,'lucy',17,'female' union
select 3,'jack',19,'male' union
select 4,'tom',18,'male'
#为null列插入值得两种方法
1.添加的时候不添加该字段
2.添加的时候为该字段添加null值、
#添加子查询
insert into beauty(id,name,phone) select 26,'宋茜','25564668';
insert into beauty(id,name,phone) select id,boyname,'21346' from boys where id<3;
select into stuinfo
select 1,'john1','女',null,null,1 union all
select 2,'john2','女',null,null,1 union all
select 3,'john3','女',null,null,1 union all
select 4,'john4','女',null,null,1 union all
select 5,'john5','女',null,null,1
修改数据(update):
在语法中:字段名1、字段名2…用于指定要更新的字段名称;值1、值 2…用于表示字段的新数据;WHERE 条件表达式 是可选的,它用于指定更新数据需要满足的条件
#修改单表的基本语法:
UPDATE 表名 SET 字段名1=值1,字段名2 =值2,… WHERE 筛选条件;
#修改多表的语法:
#sql92语法:
update 表1 别名,表2 别名 set 列=值,... where 连接条件 and 筛选条件;
#sql99语法:
update 表1 别名 inner|left|right join 表2 别名 on 连接条件 set 列=值,... where 筛选条件;
#示例:
#将name为tom的记录的age设置为20并将其gender设置为female MySQL命令:
update student set age=20,gender='female' where name='tom';
#将学生记录的age设置为18 MySQL命令:
update student set age=18;
#修改boys表中id号为2的名称为张飞,魅力值10
update boys set boyname='张飞',usercp=10 where id=2;
#修改多表的记录
#修改张无忌的女朋友的手机号为114
update boys bo inner join beauty on bo.id = b.boyfriend_id set b.phone='114' where bo.boyName='张无忌';
#修改没有男朋友的女生的男朋友编号都为2号
update boys bo right join beauty b on bo.id=b.boyfrient_id set b.boyfrient_id=2 where bo.id is null;
#将3号员工的last_name修改为drelxer
update my_employees set last_name='drelxer' where id = 3;
#将所有工资少于900的员工的工资修改为1000
update my_employees set salary=1000 where salary<900;
#将userid为Bbiri的user表和my_employees表的记录全部删除
delete u,e from users u join my_employees e on u.userid=e.userid where u.u.userid='Bbiri';
删除数据(delete):
在该语法中:表名用于指定要执行删除操作的表;[WHERE 条件表达式]为可选参数用于指定删除的条件。
#方式一:delete
#单表删除的基本语法:
DELETE FROM 表名 [WHERE 筛选条件] [limit 条目数];
#多表删除的基本语法
#sql92语法:
delete 表1的别名,表2的别名 from 表1 别名,表2 别名 where 连接条件 and 筛选条件;
#sql99语法:
delete 表1的别名,表2的别名 from 表1 别名
inner|left|right join 表2 别名
on 连接条件 where 筛选条件;
#方式二:truncate
truncate table 表名;
#示例:
#删除age等于14的所有记录:
delete from student where age=14;
#删除age等于14的第一条记录:
delete from student where age=14 limit 1;
#删除student表中的所有记录 MySQL命令:
delete from student;
#多表的删除
#删除张无忌的女朋友信息
delete b from beauty b inner join boys bo on b.boyfriend_id = bo.id where bo.boyName='张无忌';
#删除黄晓明的信息以及他女朋友的信息
delete b,bo from beauty b inner join boys bo on b.boyfriend_id=bo.id where bo.boyName='黄晓明';
#delete VS truncate
1.delete可以加where条件,truncate不能加
2.truncate删除,效率高一点点
3.假如要删除的表中有自增长列。如果用delete删除后,在插入数据,自增长列的值从断电开始。而truncate删除后,再插入数据,自增长列的值从1开始。
4.truncate删除没有返回值,delete删除返回值
5.truncate删除不能回滚,delete删除可以回滚
truncate和delete的区别:
TRUNCATE和DETELE都能实现删除表中的所有数据的功能,但两者也是有区别的:
1、DELETE语句后可跟WHERE子句,可通过指定WHERE子句中的条件表达式只删除满足条件的部分记录;但是,TRUNCATE语句只能用于删除表中的所有记录。
2、使用TRUNCATE语句删除表中的数据后,再次向表中添加记录时自动增加字段的默认初始值重新由1开始;使用DELETE语句删除表中所有记录后,再次向表中添加记录时自动增加字段的值为删除时该字段的最大值加1
3、DELETE语句是DML语句,TRUNCATE语句通常被认为是DDL语句
drop和delete和truncate
一、 删除内容的不同:
drop:用于删除数据库(drop database 数据库名称)、删除数据表( use 数据库名称 drop table 数据表1名称,数据表2名)或删除数据表字段(use 数据库名称 alter table 数据表名称 drop column 字段名(列名称))。
delete:删除数据表中的行(某一行或所有行)
格式:delete from 表名称 where 列名称=值;
truncate:清空表数据,但不删除这个表,只是把里面存的数据内容清空掉了
二、语句类型的不同:
delete:是dml(数据库操作语言),这个操作会放到rollback segement(你在数据库中的一些存储空间,用来临时的保存当数据库数据发生改变时的先前值)中,事务提交之后才生效;如果有相应的trigger(触发器),执行的时候将被触发.
drop是ddl(数据库定义语言), 操作立即生效,原数据不放到rollback segment中,不能回滚. 操作不触发trigger.
truncate:删除表中的所有行,只删除数据,表的结构及其列约束依然保留。操作立即生效,不触发trigger;
三、删除速度的不同:
一般来说: drop>truncate>delete
查询数据(select):
语法: select 查询列表 from 表名;
特点:
- 查询列表可以是:表中的字段、常量值、表达式(运算符)、函数。
- 查询结果可以是一个虚拟的表。
- where后面不能使用别名,having和order by后能使用别名。
简单查询:不含where的select语句
查询所有字段 MySQL命令:
select * from student;
查询指定字段(sid、sname) MySQL命令:
select sid,sname from student;
在SELECT中除了书写列名,还可以书写常数。可以用于标记
常数的查询日期标记 MySQL命令:
select sid,sname,'2021-03-02' from student;
distinct关键字只能用在第一个所查列名之前
过滤重复数据:
select distinct gender from student;
在SELECT查询语句中还可以使用加减乘除运算符。
查询学生10年后的年龄 MySQL命令:
select sname,age+10 from student;
select top 1 * from user
distinct:
select distinct name, id from table
结果会是:
----------
id name
1 a
2 b
3 c
4 c
5 b
distinct怎么没起作用?作用是起了的,不过他同时作用了两个字段,也就是必须得id与name都相同的才会被排除
select id, distinct name from table
很遗憾,除了错误信息你什么也得不到,distinct必须放在开头。难到不能把distinct放到where条件里?能,照样报错
order by排序查询:
语法:
select 查询列表 from 表 where 筛选条件 order by 排序列表[asc|desc]
特点:
1.asc代表的是升序,desc代表的是降序。如果不写默认是升序。
2.order by子句中可以支持单个字段、多个字段、表达式、函数、别名。
3.order by子句一般是放在查询语句的最后面,limit子句除外。
示例:
#查询员工信息,要求先按工资升序,再按员工编号降序【按多个字段排序】
select * from employees order by salary asc,employee_id desc;
#按姓名的长度显示员工的姓名和工资【按函数排序】
select length(last_name) 字节长度,last_name,salary from employees
order by length(last_name) desc;
#按年薪的高低显示员工的信息和年薪【按表达式排序】
select * salary*12*(1+ifnull(commission_pct,0)) 年薪 from employees
order by salary*12*(1+ifnull(commission_pct,0)) desc;
#按年薪的高低显示员工的信息和年薪【按别名排序】
select * salary*12*(1+ifnull(commission_pct,0)) 年薪 from employees
order by 年薪 desc;
SQL语句 - 语法顺序:
1. SELECT
2. DISTINCT <select_list>
3. FROM <left_table>
4. <join_type> JOIN <right_table>
5. ON <join_condition>
6. WHERE <where_condition>
7. GROUP BY <group_by_list>
8. HAVING <having_condition>
9. ORDER BY <order_by_condition>
10. LIMIT <limit_number>
SQL语句 - 执行顺序:
1.from
<表名> # 选取表,将多个表数据通过笛卡尔积变成一个表。
2.join
<join, left join, right join...>
<join表> # 指定join,用于添加数据到on之后的虚表中,例如left join会将左表的剩余数据添加到虚表中
3.on
<筛选条件> # 对笛卡尔积的虚表进行筛选
4.where
<where条件> # 对上述虚表进行筛选
5.group by
<分组条件> # 分组
<SUM()等聚合函数> # 用于having子句进行判断,在书写上这类聚合函数是写在having判断里面的
6.having
<分组筛选> # 对分组后的结果进行聚合筛选
7.select
<返回数据列表> # 返回的单列必须在group by子句中,聚合函数除外
8.distinct
# 数据除重
9.order by
<排序条件> # 排序
10.limit
<行数限制>
分页查询:
应用场景:当要显示的数据,一页显示不全,需要分页提交sql请求
limit语句放在查询语句的最后
#语法:
select 查询列表 from 表
[join type join 表2
on 连接条件
where 筛选条件
group by 分组查询
having 分组后的筛选
order by 排序的字段]
limit offset,size;
offset要显示条目的起始索引(起始索引从0开始)
size要显示的条目个数
#limit分页公式
(1)limit分页公式:curPage是当前第几页;pageSize是一页多少条记录
limit (curPage-1)*pageSize,pageSize
(2))用的地方:sql语句中
select * from student limit(curPage-1)*pageSize,pageSize;
#总页数公式
(1)总页数公式:totalRecord是总记录数;pageSize是一页分多少条记录
int totalPageNum = (totalRecord +pageSize - 1) / pageSize;
(2)用的地方:前台UI分页插件显示分页码
(3)查询总条数:totalRecord是总记录数,SELECT COUNT(*) FROM tablename
#公式:
要显示的页数page,每页的条目数size
select 查询列表
from 表
limit (page-1)*size,size
size=10
page
1 0
2 10
3 20
#示例:
#查询前5条员工信息
select * from employees limit 0,5;
select * from employees limit 5;
#查询第11条--第25条
select * from employees limit 10,15;
#有奖金的员工信息,并且工资较高的前10名显示出来
select * from employees where commission_pct is not nul order by salary desc limit 10;
视图:
MySQL从5.0.1版本开始提供视图功能。一种虚拟存在的表,行和列的数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的,只保存了SQL逻辑,不保存查询结果。
mysql的视图中不允许有from后面的子查询,但oracle可以。
视图是什么:
- 将一段查询sql封装为一个虚拟的表
- 这个虚拟表只保存了sql逻辑,不会保存任何查询结果
视图的作用:
- 封装复杂sql语句,提高复用性
- 逻辑放在数据库上面,更新不需要发布程序,面对频繁的需求变更更灵活
应用场景:
1、多个地方用到同样的查询结果
2、该查询结果使用的sql语句较复杂
3、视图主要用于查看,很少增删改
4、报表
视图的好处:
- 重用SQL语句
- 简化复杂的SQL操作,不必知道它的查询细节
- 保护数据,提高安全性
视图在以下情况不能修改:
- 包含以下关键字的SQL语句:分组函数、distinct、group by、having、union或union all
- 常量视图
- select中包含子查询
- join
- from后一个不能更新的视图
- where 子询的子查询引用了from子句中的表
视图和表的区别:
| 创建语法的关键字 | 是否实际占用屋里空间 | 使用 | |
|---|---|---|---|
| 视图 | create view | 只是保存了sql逻辑 | 增删改查,一般用于查询 |
| 表 | create table | 只保存了数据 | 增删改查 |
更新视图的时候 视图中的表也跟着更新
#创建视图。
create view 视图名 as
查询语句;
#方式一:修改视图。
create 【or replace】 view 视图名 as
查询语句;
#方式二:修改视图
alter view 视图名 as
查询语句;
#删除视图
drop view 视图1、视图2;
#查看视图
desc 视图名;
show create view 视图名;
#创建视图
create or replace view myv1 as
select last_name,email from employees;
#插入
insert into myv1 valuse('张飞','[email protected]')
#修改
update myv1 set last_name='张无忌'where last_name='张飞';
#删除
delete from myv1 where last_name='张无忌';
#查看
select * from myv1;
#删除视图
#语法:drop view 视图名、视图名、、;
drop view myv1,myv2,myv3;
#查看视图
desc myv3;
show create view myv3;
#案例:
#查询姓张的学生名和专业名:
create view v1 as
select stuname,majorname from stuinfo s inner join major m on s.majorid=m.id;
使用视图查询
select * from v1 where stuname like '张%';
#查询姓名中包含a字符的员工名,部门名和工种信息
①创建
create view myv1 as
select last_name,department_name,job_title from employees e join departments d on e.department_id=d.department_id join jobs j on j.job_id = e.job_id;
②使用
select * from myv1 where last_name like '%a%';
#创建视图emp_v1,要求查询电话号码以‘001’开头的员工姓名和工资、邮箱
create or replace view emp_v1 as
select last_name,salary,email from employees where phone_number like '011%';
#创建视图emp_v2,要求查询部门的最高工资高于12000的部门信息
create or replace view emp_v2 as
select max(salary),department_id from employees group by department_id having max(salary)>12000
#查询邮箱中包含a字符的员工名、部门名和工种信息
create view myv1 as
select last_name,department_name,job_title from employees e join departments d on e.department_id = d.department_id join jobs j on j.job_id=e.job_id;
#查看各部门的平均工资级别
①创建视图查看每个部门的平均工资
create view myv2 as
select avg(salary) ag,department_id from employees group by department_id;
②使用
select myv2.ag,g.grade_level from myv2 join job_grades g on myv2.ag between g.lowest_sal and g.highest_sal;
#套用函数
create or replace view myv1 as
select last_name,email,salary*12*(1+ifnull(commission_pct,0)) "annual salary" from employees;
#函数加分组
create or replace view myv1 as
select max(salary) m,department_id from employees group by department_id;
#select中包含子查询
create or replace view myv3 as
select department_id,(select max(salary) from employees)最高工资 from departments;
#更新全部
update myv3 set 最高工资=100000;
#from一个不能更新的视图
create or replace view myv5 as
select * from myv3;
#where子句的子查询应用了from子句中的表
create or replace view myv6 as
select last_name,email,salary from employees where employees_id in(
select manager_id from employees where manager_id is not null
);
函数概念
类似于java中的方法,将一组逻辑语句封装在方法体中,对外暴露方法名。
好处:
-
隐藏了实现细节
-
提高代码的重用性
语法:select 函数名(实参列表) 【from表】;
分类:单行函数、分组函数
单行函数:
时间日期函数:
#当前时间,格式为YYYY-MM-DD HH:mm:ss
SELECT NOW(); --2015-09-28 13:42:00
#当前日期,格式为YYYY-MM-DD
SELECT CURDATE(); --2015-09-28
#当前时间,不包含日期
select CURTIME(); --11:13:355
#查询当天早上9点,格式为YYYY-MM-DDHH:mm:ss
SELECT DATE_ADD(CURDATE(),INTERVAL9 HOUR);-- 2015-09-2809:00:00
#查询昨天,格式为YYYY-MM-DD
SELECT DATE_SUB(CURDATE(),INTERVAL 1 DAY);-- 2015-09-27
#查询昨天早上9点
SELECT DATE_ADD(DATE_SUB(CURDATE(),INTERVAL1DAY),INTERVAL 9HOUR);--2015-09-2709:00:00
#查询昨天日期
select DATE_SUB(curdate(),INTERVAL 1 DAY) ;
#查询明天日期
select DATE_SUB(curdate(),INTERVAL -1 DAY) ;
#查询前一个小时
select date_sub(now(), interval 1 hour);
#查询后一个小时
select date_sub(now(), interval -1 hour);
#查询前30分钟
select date_add(now(),interval -30 minute)
#查询后30分钟
select date_add(now(),interval 30 minute)
#查询当天0点,格式为YYYY-MM-DD HH:mm:ss
SELECT DATE_FORMAT(CURDATE(),'%Y-%m-%d %H:%i:%s');--2015-09-2800:00:00
#date_sub()函数的例子:
date_sub('2012-05-25',interval 1 day) 表示 2012-05-24
date_sub('2012-05-25',interval 0 day) 表示 2012-05-25
date_sub('2012-05-25',interval -1 day) 表示 2012-05-26
date_sub('2012-05-31',interval -1 day) 表示 2012-06-01
date_sub(curdate(),interval 1 day) 表示 2013-05-19
date_sub(curdate(),interval -1 day) 表示 2013-05-21
date_sub(curdate(),interval 1 month) 表示 2013-04-20
date_sub(curdate(),interval -1 month) 表示 2013-06-20
date_sub(curdate(),interval 1 year) 表示 2012-05-20
date_sub(curdate(),interval -1 year) 表示 2014-05-20
#datediff(date1,date2)
两个日期相减 date1 - date2,返回天数。
select datediff('2008-08-08', '2008-08-01'); -- 7
select datediff('2008-08-01', '2008-08-08'); -- -7
#获得当前日期+时间(date + time)函数:now()、sysdate()
sysdate() 日期时间函数跟 now() 类似,不同之处在于:now() 在执行开始时值就得到了, sysdate() 在函数执行时动态得到值。
sysdate() 日期时间函数,一般情况下很少用到。
#获得当前 UTC 日期时间函数:utc_date(), utc_time(), utc_timestamp()
因为我国位于东八时区,所以本地时间 = UTC 时间 + 8 小时。UTC 时间在业务涉及多个国家和地区的时候,非常有用。
#选取日期时间的各个部分:日期、时间、年、季度、月、日、小时、分钟、秒、微秒:
set @dt = '2008-09-10 07:15:30.123456';
select date(@dt); -- 2008-09-10
select time(@dt); -- 07:15:30.123456
select year(@dt); -- 2008
select quarter(@dt); -- 3
select month(@dt); -- 9
select week(@dt); -- 36
select day(@dt); -- 10
select hour(@dt); -- 7
select minute(@dt); -- 15
select second(@dt); -- 30
select microsecond(@dt); -- 123456
#Extract() 函数,可以上面实现类似的功能:
set @dt = '2008-09-10 07:15:30.123456';
select extract(year from @dt); -- 2008
select extract(quarter from @dt); -- 3
select extract(month from @dt); -- 9
select extract(week from @dt); -- 36
select extract(day from @dt); -- 10
select extract(hour from @dt); -- 7
select extract(minute from @dt); -- 15
select extract(second from @dt); -- 30
select extract(microsecond from @dt); -- 123456
#函数:dayofweek(), dayofmonth(), dayofyear():
分别返回日期参数,在一周、一月、一年中的位置。
set @dt = '2008-08-08';
select dayofweek(@dt); -- 6
select dayofmonth(@dt); -- 8
select dayofyear(@dt); -- 221
#返回星期和月份名称函数:dayname(), monthname():
set @dt = '2008-08-08';
select dayname(@dt); -- Friday
select monthname(@dt); -- August
#last_day() 函数:返回月份中的最后一天:
select last_day('2008-02-01'); -- 2008-02-29
select last_day('2008-08-08'); -- 2008-08-31
#(时间、秒)转换函数:time_to_sec(time), sec_to_time(seconds):
select time_to_sec('01:00:05'); -- 3605
select sec_to_time(3605); -- '01:00:05'
#(日期、天数)转换函数:to_days(date), from_days(days):
select to_days('0000-00-00'); -- 0
select to_days('2008-08-08'); -- 733627
select from_days(0); -- '0000-00-00'
select from_days(733627); -- '2008-08-08'
#Str to Date (字符串转换为日期)函数:str_to_date(str, format):
select str_to_date('08/09/2008', '%m/%d/%Y'); -- 2008-08-09
select str_to_date('08/09/08' , '%m/%d/%y'); -- 2008-08-09
select str_to_date('08.09.2008', '%m.%d.%Y'); -- 2008-08-09
select str_to_date('08:09:30', '%h:%i:%s'); -- 08:09:30
select str_to_date('08.09.2008 08:09:30', '%m.%d.%Y %h:%i:%s'); -- 2008-08-09 08:09:30
#Date/Time to Str(日期/时间转换为字符串)函数:date_format(date,format), time_format(time,format):
date_format('2008-08-08 22:23:00', '%W %M %Y') | Friday August 2008
date_format('2008-08-08 22:23:01', '%Y%m%d%H%i%s') |20080808222301
time_format('22:23:01', '%H.%i.%s') | 22.23.01
#MySQL 获得当前时间戳函数:current_timestamp, current_timestamp():
select current_timestamp, current_timestamp();
2008-08-09 23:22:24 | 2008-08-09 23:22:24
#计算时间差函数
TIMESTAMPDIFF(interval,datetime1,datetime2)
说明:返回结果 datetime2-datetim1
返回日期或日期时间表达式datetime1 和 datetime2之间的整数差。
其结果的单位由interval 参数给出。interval 的法定值同TIMESTAMPADD()函数说明中所列出的相同。
interval可是:
SECOND 秒 SECONDS
MINUTE 分钟 MINUTES
HOUR 时间 HOURS
DAY 天 DAYS
MONTH 月 MONTHS
YEAR 年 YEARS
#以英文形式返回月
SELECT MONTHNAME('日期');
#计算日期相差天数:
datediff(now(),'1995-1-1')
datediff(max(字段),min(字段))
(字符串转换为日期)函数标识符:
| 序号 | 格式符 | 功能 |
|---|---|---|
| 1 | %Y | 4位的年份 |
| 2 | %y | 2位的年份 |
| 3 | %m | 月份(01,02,…11,12) |
| 4 | %c | 月份(1,2,…11,12) |
| 5 | %d | 日(01,02…) |
| 6 | %H | 小时(24小时制) |
| 7 | %h | 小时(12小时制) |
| 8 | %i | 分钟(00,01,…59) |
| 9 | %s | 秒 (00,01,…59) |
字符串函数:
| 函 数 | 功 能 |
|---|---|
| concat(str1,str2,…,strn) | 将str1,str2,…,strn连接为一个完整的字符串 |
| concat_ws(’_’, abc, def, gh) | abc_def_gh |
| insert(str,x,y,instr) | 将字符串str从第x开始,y个字符串长度的子串替换为字符串instr |
| lower(str) | 将字符串str中的所有字母变成小写 |
| upper(str) | 将字符串str中的所有字母变成大写 |
| left(str,x) | 返回字符串最左边的x个字符 |
| right(str,x) | 返回字符串最右边的x个字符 |
| lpad(str,n,pad) | 使用字符串pad对字符串str最左边进行填充,直到长度为n个字符长度 |
| rpad(str,n,pad) | 使用字符串pad对字符串str最右边进行填充,直到长度为n个字符长度 |
| ltrim(str) | 去掉str左边的空格 |
| rtrim(str) | 去掉str右边的空格 |
| repeat(str,x) | 返回字符串str重复x次的结果 |
| replace(str,a,b) | 使用字符串b替换字符串str中所有出现的字符串a |
| strcmp(str1,str2) | 比较字符串str1和str2 |
| trim(str) | 去掉字符串行头和行尾的空格 |
| sunstring(str,x,y) | 返回字符串str中从x位置起y个字符串长度的字符组付出 |
| length(字符串) | 获取字符串的长度 |
| ifnull(x,0) | 如果x为null,就返回0 |
| isnull(x) | 如果x为null返回1,如果x不为null返回0 |
| ESCAPE ‘$’ | 可以将$变成 转义符 |
| CAST(value as type); | CAST(xxx as 类型) |
| CONVERT(value, type); | CONVERT(xxx,类型) |
| Len(text): | 得到字符串的长度 |
ESCAPE '$' 可以将$变成 转义符
示例:
查询员工名中第二个字符为_的员工名
select last_name from employees where last_name'_\_';
使用'ESCAPE'函数:
select last_name from employees where last_name'_$_' ESCAPE '$';
length(字符串)获取字符串的长度
示例:
select length('hohn') 字符长度为4
select length('张三丰hahaha') 字符长度为15
show variables like '%char%' 查看当前字符集
GBK字符集一个字符占2个字节
UTF8字符集一个字符占3个字节
concat(str1,str2,...,strn) 字符串拼接
示例:
#将姓变大写,名变小写,然后拼接
select concat(upper(last_name),lower(first_name)) 姓名 from employees;
#姓名中首字符大写,其他字符小写然后用_拼接,,显示出来
select concat(upper(substr(last_name,1,1)),'_',lower(substr(last_name,2))) out_put from employees;
select concat(last_name,' earns ',salary,' month but wants ',salary-3) as "Dream Salary"
from employees where salary=24000;
substr、substring 字符串截取
注意:索引从1开始
#截取从指定索引处后面所有的字符
select substr('李莫愁爱上了陆展元',7) out_put; 结果为:陆展元
#截取从指定索引处指定字符长度的字符
select substr('李莫愁爱上了陆展元',1,3) out_put; 结果为:李莫愁
#将员工的姓名按首字母排序,并写出姓名的长度(length)
select length(last_name) 长度,substr(last_name,1,1) 首字符,last_name from employees
order by 首字符;
instr(x,y) 返回y第一次出现的索引,如果找不到返回0
示例:
select instr('杨不悔爱上了殷六侠','殷六侠') as out_put from employees; 结果为:7
select instr('杨不殷六侠悔爱上了殷六侠','殷六侠') as out_put from employees; 结果为:3
select instr('杨不殷六侠悔爱上了殷六侠','殷八侠') as out_put from employees; 结果为:0
trim(str) 去掉字符串行头和行尾的空格或字符
示例:
select trim(' 张翠山 ') as out_put; 结果为:张翠山
select trim('a' from 'aaaaa张aa翠山aaaa') as out_put; 结果为:张aa翠山
select trim('aa' from 'aaaaa张aa翠山aaaaa') as out_put; 结果为:a张aa翠山a
lpad(,,) 用指定的字符实现左填充指定长度
示例:
select lpad('殷素素',5,*) as out_put; 结果为:*****殷素素
左填充,从右截断
select lpad('殷素素',2,*) as out_put; 结果为:殷素
rpad(,,) 用指定的字符实现右填充指定长度
示例:
select rpad('殷素素',5,'*') as out_put; 结果为:殷素素*****
replace(str,a,b) 字符串替换,使用字符串b替换字符串str中所有出现的字符串a
示例:
select replace('张无忌爱上了周芷若','周芷若','赵敏') as out_put; 结果为:张无忌爱上了赵敏
select replace('周芷若周芷若张无忌爱上了周芷若','周芷若','赵敏') as out_put; 结果为:赵敏赵敏张无忌爱上了赵敏
数学函数:
1:整除DIV
mysql>select 5 div 2;
>2
2:绝对值 ABS
mysql>select abs(2)
>2
mysql>select abs(-32)
>32
3:余弦cos和反余弦acos
mysql>select acos(1)
>0
4:正弦sin和反正弦asin
mysql>select asin(0.2)
>0.20135792079033
5:正切tan和反正切atan
6:返回X 的自然对数,即, X 相对于基数e 的对数
mysql>select LN(2)
>0.69314718055995
7:模操作。返回N 被 M除后的余数。
mysql> SELECT MOD(234, 10);
-> 4
8:PI值
返回 ? (pi)的值。默认的显示小数位数是7位,然而 MySQL内部会使用完全双精度值。
mysql> SELECT PI();
-> 3.141593
mysql> SELECT PI()+0.000000000000000000;
-> 3.141592653589793116
9:返回X 的Y乘方的结果值
mysql> SELECT POW(2,-2);
-> 0.25
10:返回由度转化为弧度
mysql> SELECT RADIANS(90);
-> 1.5707963267949
11:由弧度转化为度 DEGREES(X)
mysql> SELECT DEGREES(PI());
-> 180
12:返回e的X乘方后的值(自然对数的底)。
mysql> SELECT EXP(2);
-> 7.3890560989307
13:返回非负数X 的二次方根 sqrt(x)
mysql> SELECT SQRT(4);
-> 2
14: 返回被舍去至小数点后D位的数字X TRUNCATE(X,D)
mysql> SELECT TRUNCATE(1.223,1);
-> 1.2
mysql> SELECT TRUNCATE(1.999,0);
-> 1
15.四舍五入 round()
select round(1.55); 结果为:2
select round(-1.45); 结果为:-1
select round(-1.55); 结果为:-2
select round(1.567,2); 结果为:1.57
16.向上取整,ceil,返回>=该参数的最小整数
select ceil(-1.02); 结果为:-1
select ceil(1.02); 结果为:2
17.向下取整,floor,返回<=该参数的最大整数
select floor(-9.99); 结果为:-10
select floor(9.99); 结果为:9
18.截断,truncate
select truncate(1.69999,1); 结果为:1.6
19.取余,mod
select mod(-10,-3); 结果为:-1
select mod(10,3); 结果为:1
20.获取随机数,返回0-1之间的小数
select rand();
21.截取需要保留的小数位
TRUNCATE(110.35,1); 结果为:110.3
22.四舍五入,保留d位小数,返回string类型
select FORMAT(110.35,1); 结果为:110.4
其他函数:
select version(); #查看当前数据库服务器的版本
select datebase(); #查看当前打开的数据库
select user(); #查看当前用户
select password('字符'); #返回该字符的密码形式
select MD5('字符'); #MD5加密
流程控制函数:
if函数:类似java中if else的效果
示例:
select if(10<5,'大','小');
select last_name,commission_pct,if(commission_cpt is null,'没奖金','有奖金') as 备注 from eomprees;
case函数:
注意:then后,语句加; 值后不加
#语法1:
case 要判断的字段或表达式
when 常量1 then 要显示的值1或语句1;
when 常量2 then 要显示的值2或语句2;
...
else 要显示的值n或语句n;
end
案例:查询员工的工资,要求
部门号=30,显示的工资为1.1倍
部门号=40,显示的工资为1.2倍
部门号=50,显示的工资为1.3倍
其他部门,显示的工资为原工资
select salary 原始工资,department_id,
case department_id
when 30 then salary*1.1
when 40 then salary*1.2
when 50 then salary*1.3
else salary
end as 新工资
from employees;
#语法2:
case
when 条件1 then 要显示的值1或语句1;
when 条件2 then 要显示的值2或语句2;
...
else 要显示的值n或语句n;
end
案例:查询员工的工资的情况
如果工资>20000,显示A级别
如果工资>15000,显示B级别
如果工资>1000,显示C级别
否则,显示D级别
select salary,
case
when salary>20000 then 'A'
when salary>15000 then 'B'
when salary>10000 then 'C'
else 'D'
end as 工资级别
from employees;
分组函数:
又称为统计函数、聚合函数、组函数。
功能:做统计使用。
聚合函数:
开发中常有类似的需求:统计某个字段的最大值、最小值、 平均值等等。为此,MySQL中提供了聚合函数来实现这些功能。
所谓聚合,就是将多行汇总成一行;其实,所有的聚合函数均如此——输入多行,输出一行。聚合函数具有自动滤空的功能,若某一个值为NULL,那么会自动将其过滤使其不参与运算。
注意:
1、sum、avg处理数值型,max、min、count可以处理任何类型。
2、以上分组函数都忽略null值
3、可以和distinct搭配实现去重的运算。
4、count(*)一般用作统计行数
5、和分组函数一同查询的字段要求是group by后的字段。
6、和分组函数一同查询的字段有限制,
select avg(salary),employee_id from employees; ×
聚合函数使用规则:
只有select子句和having子句、order by子句中能够使用聚合函数。例如,在where子句中使用聚合函数是错误的。
count():
count():统计表中数据的行数或者统计指定列其值不为NULL的数据个数。
count函数有几种形式:count(*),count(1),count(column), count(DISTINCT count)和count(expression)。
-
count(1):这个用法和count(*)的结果是一样的。
-
count(distinct column) :返回不包含NULL值的唯一行数。
-
count(column):返回不包含NULL值的所有行数。
-
count(expression):返回不包含NULL值的行数,返回类型为BIGINT。expression 是表达式。
-
count(“常量值”):count()里面可以随便放常量值,效果和count(1)相同。
原因:大概原因是,会在你每一行数据前添加一个常量值,最后统计常量值的个数。
效率:
MyISAM存储引擎下,count(*)的效率高。
INNODB存储引擎下,count(*)和count(1)的效率差不多,比count(字段)要高。
查询该表中有多少人:
select count(*) from student;
查询该表中有多少人:
SELECT COUNT(1) from student
查询该表中有多少name不为null:
SELECT COUNT(name) from student;
查询该表中有多少name不为null,且不重复的:
SELECT COUNT(DISTINCT name) from student;
查询该表中name=张强 的数量:
SELECT COUNT(IF(name='张强',1,NULL)) from student;
max():
计算指定列的最大值,如果指定列是字符串类型则使用字符串排序运算
MAX( )函数忽略NULL值。如果该列中,所有行的值都是NULL,则MAX( )函数将返回NULL值。
查询该学生表中年纪最大的学生:
select max(age) from student;
min():
计算指定列的最小值,如果指定列是字符串类型则使用字符串排序运算
MIN( )函数忽略NULL值。如果该列中,所有行的值都是NULL,则MIN( )函数将返回NULL值。
查询该学生表中年纪最小的学生 MySQL命令:
select sname,min(age) from student;
sum():
计算指定列的数值和,如果指定列类型不是数值类型则计算结果为0
查询该学生表中年纪的总和 MySQL命令:
select sum(age) from student;
avg():
计算指定列的平均值,如果指定列类型不是数值类型则计算结果为0。忽略null值。
查询该学生表中年纪的平均数 MySQL命令:
select avg(age) from student;
聚合函数使用:
select sum(salary) 和,AVG(salary) 平均,MAX(salary) 最高,MIN(salary) 最低,COUNT(salary) 个数 from employees;
select sum(salary) 和,ROUND(AVG(salary),2) 平均,MAX(salary) 最高,MIN(salary) 最低,COUNT(salary) 个数 from employees;
#和distinct搭配
select sum(distinct salary),sun(salary) from employees;
select count(distinct salary) from employess;
案例:
#查询邮箱中包含a字符的,每个部门的平均工资:
select avg(salary),department_id from employees where email like '%a%' group by department_id;
#查询有奖金的每个领导手下员工的最高工资
select max(salary),manager_id from employees where commission_pct is not null group by manager_id;
#查询哪个部门的员工个数>2
①查询每个部门的员工个数
select count(*),department_id from employees group by department_id;
②根据①的结果进行筛选,查询哪个部门的员工个数>2
select count(*),department_id from employees group by department_id having count(*)>2
#查询每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
①查询每个工种有奖金的员工的最高工资
select max(salary),job_id from employees where commission_pct is not null group by job_id
②根据①结果继续筛选,最高工资>12000
select max(salary),job_id from employees where commission_pct is not null group by job_id having max(salary)>12000;
#查询领导编号>102的每个领导手下的最低工资>5000的领导编号是哪个,以及其最低工资
①查询每个领导手下的最低固定工资
select min(salary),manager_id from employees group by manager_id;
②添加筛选条件:编号>102
select min(salary),manager_id from employees where manager_id>102 group by manager_id;
③添加筛选条件,最低工资>5000
select min(salary),manager_id from employees where manager_id>102 group by manager_id having min(salary)>5000;
分组查询:
分组数据:group by 子句语法。可以使用group by子句将表中的数据分成若干组。
group by基本上都需要进行排序,分组后会有临时表产生。
分组查询中的筛选条件分为两类:
| 筛选 | 数据源 | 位置 | 关键字 |
|---|---|---|---|
| 分组前筛选 | 原始表 | group by子句的前面 | where |
| 分组后筛选 | 分组后的结果集 | group by子句的后面 | having |
特点:
-
分组函数做条件肯定是放在having子句中
-
能用分组钱筛选的,就优先考虑使用分组前筛选
-
group by子句支持单个字段分组,多个字段分组(多个字段之间用逗号隔开没有顺序要求),
表达式或函数(用得较少)
-
也可以添加排序(排序放在整个分组查询的最后)
语法:
select 分组函数,列(要求出现在group by的后面)
from 表
[where 筛选条件]
group by 分组的字段
[having 分组后的筛选]
[order by 子句]
注意:查询列表必须特殊,要求是分组函数和group by后出现的字段。
group by使用原则: select后面只能放函数和group by后的字段。
示例:
#查询每个工种的最高工资
select max(salary),job_id from employees order by job_id;
#查询每个位置上的部门个数
select count(*),location_id from departments group by location_id;
#查询每个工种的最高工资
select max(salary),job_id from employees group by job_id;
#查询每个位置上的部门个数
select count(*),location_id from departments group by department_id;
#按员工姓名的长度分组,查询每一组的员工个数,筛选员工个数>5的有哪些
①查询每个长度的员工个数
select count(*) length(last_name) len_name from employees group by length(last_name);
②添加筛选条件
select count(*) length(last_name) len_name from employees group by length(last_name) haviong count(*)>5;
②添加筛选条件
select count(*) c length(last_name) len_name from employees group by length(last_name) haviong c >5;
#查询每个部门每个工种的员工的平均工资
select avg(salary),department_id,job_id from employees group by department_id,job_id;
#查询每个部门每个工种的员工的平均工资,并且按平均工资的最低显示
select avg(salary),department_id,job_id from employees where department_id is not null group by job_id,department_id group by avg(salary) desc;
#查询员工最高工资和最低工资的差距(difference)
select max(salary)-min(salary) difference from employees;
#查询每个管理员手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
select min(salary),manager_id from employees where manager_id is not null group by manager_id having min(salary)>=6000;
#查询所有部门的编号,员工数量和工资平均值,并按平均工资降序
select department_id,count(*),avg(salary) a from employees group by department_id order by a desc;
#选择具有各个job_id的员工人数
select count(*) 个数,job_id from employees group by job_id;
#查询每个机构年龄最大的人
select * from mytb12 m inner join(select dept,max(age)maxage from mytb12 group by dept)ab
on ab.dept=m.dept and m.age=ab.maxage
条件查询:
数据库中存有大量数据,我们可根据需求获取指定的数据。此时,我们可在查询语句中通过WHERE子句指定查询条件对查询结果进行过滤。
查询年龄等于或大于17的学生的信息 MySQL命令:
select * from student where age>=17;
IN关键字用于判断某个字段的值是否在指定集合中。如果字段的值恰好在指定的集合中,则将字段所在的记录将査询出来。
select * from student where sid in ('S_1002','S_1003');
查询sid为S_1001以外的学生的信息 MySQL命令:
select * from student where sid not in ('S_1001');
BETWEEN AND用于判断某个字段的值是否在指定的范围之内。如果字段的值在指定范围内,则将所在的记录将查询出来:
select * from student where age between 15 and 18;
查询不是15到18岁的学生信息 MySQL命令:
select * from student where age not between 15 and 18;
使用 IS NULL关键字判断字段的值是否为空值。请注意:空值NULL不同于0,也不同于空字符串。
查询sname不为空值的学生信息 MySQL命令:
select * from student where sname is not null;
使用AND关键字可以连接两个或者多个查询条件。
查询年纪大于15且性别为male的学生信息 MySQL命令:
select * from student where age>15 and gender='male';
使用OR关键字连接多个査询条件。在使用OR关键字时,只要记录满足其中任意一个条件就会被查询出来.
查询年纪大于15或者性别为male的学生信息 MySQL命令:
select * from student where age>15 or gender='male';
使用LIKE关键字可以判断两个字符串是否相匹配。
查询sname中与wang匹配的学生信息 MySQL命令:
select * from student where sname like 'wang';
%用于匹配任意长度的字符串。例如,字符串“a%”匹配以字符a开始任意长度的字符串。
查询学生姓名以li开始的记录 MySQL命令:
select * from student where sname like 'li%';
查询学生姓名以g结尾的记录 MySQL命令:
select * from student where sname like '%g';
查询学生姓名包含s的记录 MySQL命令:
select * from student where sname like '%s%';
下划线通配符只匹配'任意单个字符',如果要匹配多个字符,需要连续使用多个下划线通配符。例如,字符串“ab_”匹配以字符串“ab”开始长度为3的字符串,如abc、abp等等;字符串“a__d”匹配在字符“a”和“d”之间包含两个字符的字符串,如"abcd"、"atud"等等。
查询学生姓名以zx开头且长度为4的记录 MySQL命令:
select * from student where sname like 'zx__';
查询学生姓名以g结尾且长度为4的记录 MySQL命令:
select * from student where sname like '___g';
LIMIT限制查询结果的数量,当执行查询数据时可能会返回很多条记录,而用户需要的数据可能只是其中的一条或者几条。
查询学生表中年纪最小的3位同学 MySQL命令:
select * from student order by age asc limit 3;
GROUP BY 子句可像切蛋糕一样将表中的数据进行分组,再进行查询等操作。换言之,可通俗地理解为:通过GROUP BY将原来的表拆分成了几张小表。
统计各部门员工个数 MySQL命令:
select count(*), departmentnumber from employee group by departmentnumber;
统计部门编号大于1001的各部门员工个数 MySQL命令:
select count(*), departmentnumber from employee where departmentnumber>1001 group by departmentnumber;
GROUP BY和聚合函数以及HAVING一起使用。
统计工资总和大于8000的部门 MySQL命令:
select sum(salary),departmentnumber from employee group by departmentnumber having sum(salary)>8000;
在该语法中:字段名1、字段名2是查询结果排序的依据;参数 ASC表示按照升序排序,DESC表示按照降序排序;默认情况下,按照ASC方式排序。通常情况下,ORDER BY子句位于整个SELECT语句的末尾。
使用ORDER BY对查询结果进行排序:
SELECT 字段名1,字段名2,…
FROM 表名
ORDER BY 字段名1 [ASC 丨 DESC],字段名2 [ASC | DESC];
查询所有学生并按照年纪大小升序排列 MySQL命令:
select * from student order by age asc;
查询所有学生并按照年纪大小降序排列 MySQL命令:
select * from student order by age desc;
为表取一个別名,用该别名来代替表的名称。
SELECT * FROM 表名 [AS] 表的别名 WHERE .... ;
将student改为stu查询整表 MySQL命令:
select * from student as stu;
为字段取一个別名,用该别名来代替字段的名称。
SELECT 字段名1 [AS] 别名1 , 字段名2 [AS] 别名2 , ... FROM 表名 WHERE ... ;
将student中的name取别名为“姓名” 查询整表 MySQL命令:
select name as '姓名',id from student;
关系运算符:
| 关系运算符 | 说明 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| = | 只能判断普通的内容 |
|---|---|
| is | 只能判断null值 |
| <=> | 安全等于,既能判断普通内容,又能判断null值 |
<=> 安全等于:
示例:
查询没有奖金的员工名和奖金率
select last_name,commission_pct from employees where commission_pct <=> null;
查询工资为12000的员工信息
select last_name,salary from employees where salary<=> 12000;
<=> VS is null:
is null:仅仅可以判断null值,可读性较高,建议使用。
<=>:既可以判断null值,又可以判断普通的数值,可读性较低。
+ 运算符:
作用:做加法运算
select 数值+数值; 直接运算
select 字符+数值; 先试图将字符转换成数值,如果转换成功,则继续运算;否则转换成0,再做运算
select null+值; 结果都为null,一方为null结果肯定为null
Where和 Having:
where:
- where是一个约束声明,使用where来约束来自数据库的数据;
- where是在结果返回之前起作用的;
- where中不能使用聚合函数。
having:
- having是一个过滤声明;
- 在查询返回结果集以后,对查询结果进行的过滤操作;
- 在having中可以使用聚合函数。
where和having的执行顺序
- where 早于 group by 早于 having
- where子句在聚合前先筛选记录。也就是说作用在group by 子句和having子句前。而 having子句在聚合后对组记录进行筛选。
连表查询:
将多个表联合成一个临时表进行查询。
按年代分类:
- SQL92标准:仅仅支持内连接,也支持一部门外连接(用于oracle、sqlserver、mysql不支持)。
- SQL99标准【推荐】:支持内连接+外连接(左外和右外)+交叉连接
按功能分类:
- 内连接(inner)
- 等值连接
- 非等值连接
- 自连接
- 外连接
- 左外连接(left outer)
- 右外连接(right outer)
- 全外连接(full outer)(MySql不支持)
- 交叉连接(cross)


等值连接:
#语法:
select 查询列表
from 表1 别名,表2 别名
where 表1.key=表2.key
[and 筛选条件]
[group by 分组字段]
[having 分组后的筛选]
[order by排序字段]
- 多表等值连接的结果为多表的交集部分
- n表连接,至少需要n-1个连接条件
- 多表的顺序没有要求
- 一般需要为表起别名
- 可以搭配前面介绍的所有子句使用,比如排序、分组、筛选
非等值连接:
#语法:
select 查询列表
from 表1 别名,表2 别名
where 非等值的连接条件
[and 筛选条件]
[group by 分组字段]
[having 分组后的筛选]
[order by排序字段]
自连接:
#语法:
select 查询列表
from 表 别名1,表 别名2
where 等值的连接条件
[and 筛选条件]
[group by 分组字段]
[having 分组后的筛选]
[order by 排序字段]
为表起别名的作用:
1、提高语句的简介度
2、区别多个重名的字段
#注意:如果为表起了别名,则查询的字段就不能使用原来的表名去限定
注意:
from 表1,表2 where 表1.id=表2.id ===== from 表1 join 表2 on 表1.id=表2.id ===== from 表1 inner join 表2 on 表1.id=表2.id
join前不加关键字,默认是inner join查询。
笛卡尔乘积:
当查询多个表时,没有添加有效的连接条件,导致多个表所有行实现完全连接。
如何解决: 添加有效的连接条件。
笛卡尔集的错误情况:
select count(*) from beauty; #假设输出12行
select count(*) from boys; #假设输出4行
#最终结果:12*4=48行
MySQL中数据表的三种关联关系:
多对一:
多对一(亦称为一对多)是数据表中最常见的一种关系。例如:员工与部门之间的关系,一个部门可以有多个员工;而一个员工不能属于多个部门只属于某个部门。在多对一的表关系 中,应将外键建在多的一方否则会造成数据的冗余。
多对多:
多对多是数据表中常见的一种关系。例如:学生与老师之间的关系,一个学生可以有多个老师而且一个老师有多个学生。通常情况下,为了实现这种关系需要定义一张中间表(亦称为连接表)该表会存在两个外键分别参照老师表和学生表。
一对一:
在开发过程中,一对一的关联关系在数据库中并不常见;因为以这种方式存储的信息通常会放在同一张表中。
接下来,我们来学习在一对多的关联关系中如果添加和删除数据。
查询Java班的所有学生 MySQL命令:
select * from student where classid=(select cid from class where cname='Java');
#关联关系删除数据。
请注意:班级表和学生表之间存在关联关系;要删除Java班级,应该先删除学生表中与该班相关联的学生。否则,假若先删除Java班那么学生表中的cid就失去了关联。
删除Java班 MySQL命令:
delete from student where classid=(select cid from class where cname='Java');
delete from class where cname='Java';
普通连表查:
#查询员工名、工种号、工种名
select e.last_name,e.job_id,j.job_title from employees e,jobs j where e.job_id=j.job_id;
#查询城市名中第二个字符为o的部门名和城市名
select department_name,city from department d,lacations 1 where d.localhost_id=l.localhost_id and city like '_o%';
#查询每个城市的部门个数
select count(*) 个数,city from departments d,localhost 1 group by city;
#查询有奖金的每个部门的部门名和部门的领导编号和该部门的最低工资
select department_name,d.manager_id,min(salary) from departments d,employees e where d.department_id=e.department_id and commission_pct is not null group by department_name,d.manager_id;
#查询每个工种的工种名和员工的个数,并且按员工个数降序
select job_title,count(*) from employees e,jobs j where e.job_id=j.job_id group by job_title order by count(*) desc;
#三表联查;
#查询员工名、部门名和所在的城市
select last_name,department_name,city from employees e,departments d,localhost l where e.department_id=d.department_id and d.localhost_id=l.localhost_id and city like 's%' order by department_name desc;
#查询员工的工资和工资级别
select salary,grade_level from employees e,job_grades g where salary between g.lowest_Sal and g.highest_sal;
#查询90号部门员工的job_id和90号部门的localhost_id
select job_id,localhost_id from employees e,departments d where e.department_id=d.department_id and e.department_id=90;
#选择所有有奖金的员工
select last_name,department_name,l.location_id,city from employees e,departments d,locations l where e.department_id=d.department_id and d.location_id=l.location_id and e.commission_pct is not null;
#选择city在Toronto工作的员工的
select last_name,job_id,d.department_id,department_name from employees e,departments d,locations l where e.department_id=d.department_id and d.location_id=l.location_id and city='Toronto';
#查询每个工种、每个部门的部门名、工种名和最低工资
select department_name,job_title,min(salary) 最低工资 from employees e,departments d,jobs j where e.department_id=d.department_id and e.job_id=j.job_id group by department_name,job_title;
#选择指定员工的姓名,员工名,以及他的管理者的姓名和员工号,结果类型于下面的格式
select e.last_name employees,e.employee_id 'Emp',m.last_name manager,m.employee_id 'Mgr' from employes e,employees m where e.manager_id = m.employee_id and e.last_name='Kochhar';
#自连接
#查询员工名和上级的名称
select e.employee_id,e.last_name,m.employee_id,m.last_name from employees e,employees m
where e.manager_id=m.employee_id;
#查询每个专业的男生人数和女生人数分别是多少
select count(*) 个数,sex,magorid from student group by sex,majorid;
交叉连接查询:
交叉连接返回的结果是被连接的两个表中所有数据行的笛卡儿积;比如:集合A={a,b},集合B={0,1,2},则集合A和B的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}。
#其语法格式如下:
SELECT * FROM 表1 CROSS JOIN 表2;
#交叉连接也被称为笛卡尔连接
示例:
select b.*,bo.* from beauty b cross join boys bo;
内连接查询:
#语法:
内连接(inner join):取出两张表中匹配到的数据,匹配不到的不保留。又称简单连接或自然连接,其语法格式如下:
select 查询字段1,查询字段2, ... from 表1 [inner] join 表2 on 表1.关系字段=表2.关系字段
在该语法中:inner join用于连接两个表,on来指定连接条件;其中inner可以省略。
#分类:
等值、非等值、自连接
#特点:
1.添加排序、分组、筛序
2.inner可以省略
3.筛选条件放在where后面,连接条件放在on后面,提高分离性,便于阅读。
4.inner join连接和sql92语法中的等值连接效果是一样的,都是查询多表的交集。
#查询员工姓名及其所属部门名称 MySQL命令:
select employee.ename,department.dname from department inner join employee on department.did=employee.departmentid;
#查询员工名、部门名
select last_name,department_name from departments d inner join employees e on e.department_id=d.department_id;
#查询名字中包含e的员工名和工种名(添加筛选)
select last_name,job_title form employees e inner join jobs j on e.job_id = j.job_id where e.last_name like '%e%';
#查询部门个数>3的城市名和部门个数(添加分组+筛选)
select city,count(*) 部门个数 from departments d inner join locations 1 on d.location_id=l.location_id group by city having count(*)>3;
#查询哪个部门的员工个数>3的部门名和员工个数,并按个数降序(添加排序)
①查询每个部门的员工个数
select count(*),department_name from employees e inner join departments d on e.department_id=d.department_id group by department_name
②在①结果上筛选员工个数>3的记录,并排序
select count(*) 个数,department_name from employees e inner join department_id d on e.department_id=d.department_id group by department_name having count(*)>3 order by count(*) desc;
#查询员工名、部门名、工种名,并按部门名降序()
select last_name,department_name,job_title from employees e inner join departments d on e.department_id=d.department_id inner join jobs j on e.job_id=j.job_id order by department_name desc;
#查询员工的工资级别
select salary,grade_level from employess e join job_grades g on e.salary between g.lowest_sal and g.hoghest_sal;
#查询工资级别的个数>20的个数,并且按工资级别降序
select count(*),grade_level from employees e join job_grades g on e.salary between g.lowest_sal and g.hightest_sal group by grade_level having count(*)>20 order by grade_level desc;
#自连接
#查询员工的名字、上级的名字
select e.last_name,m.last_name from employees e join employees m on e.manager_id=m.employee_id;
#查询姓名中包含字符K的员工的名字、上级的名字
select e.last_name,m.last_name from employees e join employees m on e.manager_id=m.employee_id where e.last_name like '%k%';
#查询生日在'1999-1-1'后的学生姓名、专业名称
select studentname,majorname from student s join major m on s.majorid=m.majorid
where datediff(borndate,'1999-1-1')>0
外连接查询:
#外连接(outer join):取出连接表中匹配到的数据,匹配不到的也会保留,其值为NULL。外连接又分为左(外)连接和右(外)连接。其语法格式如下:
SELECT 查询字段1,查询字段2, ... FROM 表1 LEFT | RIGHT [OUTER] JOIN 表2 ON 表1.关系字段=表2.关系字段 WHERE 条件
应用场景:用于查询一个表中有,另一个表没有的记录
#特点:
1.外连接的查询结果为主表中的左右记录
2.如果从表中有和它匹配的,则显示匹配的值
3.如果从表中没有和它匹配的,则显示null
4.外连接查询结果=内连接结果
#连表查:
1.
①外连接的查询结果为主表中的所有记录
②如果从表中有和它匹配的,则显示匹配的值
③如果从表中没有和它匹配的,则显示null
④外连接查询结果=内连接结果+主表中有而从表没有的记录
2.
①左外连接,left join左边的是主表
②右外连接,right join右边的是主表
3.
左外和右外交换两个表的顺序,可以实现同样的效果
4.
全外连接=内连接的结果+表1中有但表2没有的+表2中有但表1没有的
#左(外)连接,
结果包括left [outer] join 子句中指定的左表的所有记录,以及所有满足连接条件的记录。如果左表的某条记录在右表中不存在则在右表中显示为空。
#查询每个班的班级ID、班级名称及该班的所有学生的名字 MySQL命令:
select class.cid,class.cname,student.sname from class left outer join student on class.cid=student.classid;
#查询哪个部门没有员工
select d.*,e.employee_id form departments d left outer join eployees e on d.department_id=e.department_id where e.employee_id is null
#查询编号>3的女神的男朋友的信息,如果有则列出详情,如果没有,用null填充
select b.id,b.name,bo.* from beauty b left outer join boys bo on b.boyfriend_id = bo.id where b.id>3;
#查询部门名为SAL或TT的员工信息
select e.*,d.department_name,d.department_id from departments d left join employees e on d.department_id=e.department_id where d.department_name in('SAL','IT');
#右(外)连接,
结果包括right [outer] join子句中指定的右表的所有记录,以及所有满足连接条件的记录。如果右表的某条记录在左表中没有匹配,则左表将返回空值。
#查询每个班的班级ID、班级名称及该班的所有学生的名字 MySQL命令:
select class.cid,class.cname,student.sname from class right outer join student on class.cid=student.classid;
#查询哪个部门没有员工
select d.*,e.employee_id form eployees e right outer join departments d on d.department_id=e.department_id where e.employee_id is null
#查询哪个城市没有部门
select city,d.* from departments d right outer join localions l on d.loaction_id = l.loaction_id where d.department_id is null;
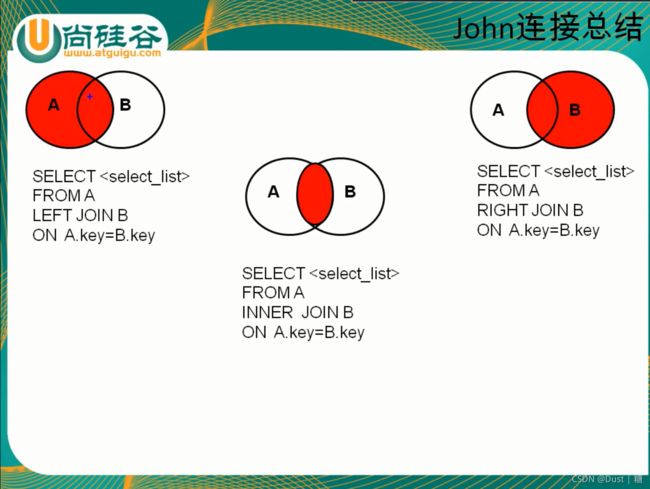
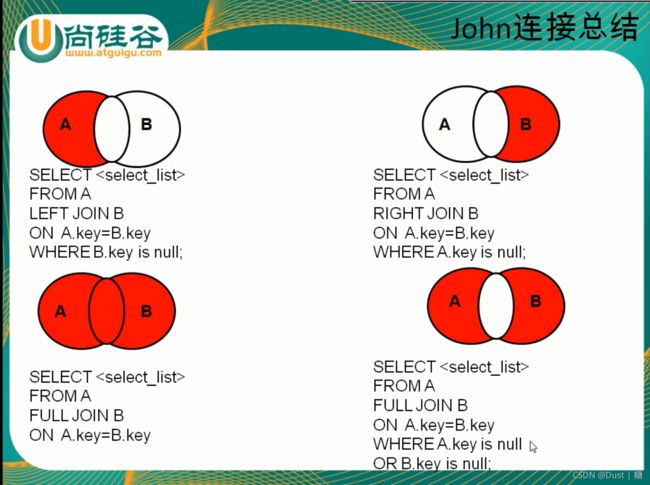
子查询:
子查询是指一个查询语句嵌套在另一个查询语句内部的查询;该查询语句可以嵌套在一个 SELECT、SELECT…INTO、INSERT…INTO等语句中。在执行查询时,首先会执行子查询中的语句,再将返回的结果作为外层查询的过滤条件。在子査询中通常可以使用比较运算符和IN、EXISTS、ANY、ALL等关键字。
概念:
出现在其他语句内部的select语句,称为子查询或内查询。内部嵌套其他select语句的查询,称为外查询或主查询。
按子查询出现的位置分类:
-
select后面:
- 仅仅支持标量子查询
-
from后面:(将子查询结果充当一张表,要求必须起别名)
- 支持表子查询
-
where或having后面:
-
标量子查询(单行)
-
列子查询(多行)
-
行子查询
-
-
exists后面(相关子查询)
- 标量子查询
- 列子查询
- 行子查询
- 表子查询
按结果集的行列数不同分类:
- 标量子查询(结果集只有一行一列)
- 列子查询(结果集只有一列多行)
- 行子查询(结果集有一行多列)
- 表子查询(结果集一般为多行多列)
特点:
- 子查询放在小括号内
- 子查询一般放在条件的右侧
- 标量子查询,一般搭配着单行操作符使用>、<、>=、<=、<>
- 列子查询,一般搭配着多行操作符使用 in、any/some、all
- 子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果。
#EXISTS关键字的子查询。
EXISTS关键字后面的参数可以是任意一个子查询, 它不产生任何数据只返回TRUE或FALSE。当返回值为TRUE时外层查询才会执行。
假如王五同学在学生表中则从班级表查询所有班级信息 MySQL命令:
select * from class where exists (select * from student where sname='王五');
#ANY关键字的子查询
ANY关键字表示满足其中任意一个条件就返回一个结果作为外层查询条件。
查询比任一学生所属班级号还大的班级编号 MySQL命令:
select * from class where cid > any (select classid from student);
#ALL关键字的子查询。
ALL关键字与ANY有点类似,只不过带ALL关键字的子査询返回的结果需同时满足所有内层査询条件。
查询比所有学生所属班级号还大的班级编号 MySQL命令:
select * from class where cid > all (select classid from student);
示例:
#查询张三同学所在班级的信息 MySQL命令:
select * from class where cid=(select classid from student where sname='张三');
#查询比张三同学所在班级编号还大的班级的信息 MySQL命令:
select * from class where cid>(select classid from student where sname='张三');
#谁的工资比Abel高?
①查询Abel的工资
select salary from employees where last_name = 'Abel'
②查询员工的信息,满足salary>①结果
select employees where salary>(select salary from employees where last_name = 'Abel');
#返回job_id与141号员工相同,salary比143号员工多的员工,姓名,job_id和工资
①查询141号员工的job_id
select job_id from employees where employee_id = 141
②查询143号员工的salary
select salary from employees where employee_id = 143
③查询员工的姓名,job_id和工资,要求job_id=①并且salary>②
select last_name,job_id,salary from employees where job_id=(select job_id from employees where employee_id = 141) and salary>(select salary from employees where employee_id = 143)
#查询有员工的部门名
select department_name from departments d where d.department_id in(select department_id from employees);
#查询没有女朋友的男神信息
select bo.* from boys where bo.id not in(select boyfriend_id from beauty);
#返回公司工资最少的员工last_name,job_id和salary
①查询公司的 最低工资
select min(salary) from employees
②查询last_name,job_id和salary,要求salary=①
select last_name,job_id,salary from employees where salary=(select min(salary) from employees);
#查询最低工资大于50号部门最低工资的部门id与其最低工资
①查询50号部门的最低工资
select min(salary) from employees where department_id = 50
②查询每个部门的最低工资
select min(salary),department_id from employees group by department_id
③在②基础上筛选,满足min(salary)>①
select min(salary),department_id from employees group by department_id having min(salary)>(select min(salary) from employees where department_id = 50);
#列子查询(多行子查询)
#返回location_id是1400或1700的部门中的所有原名姓名
①查询lacation_id是1400或1700的部门编号
select distinct department_id from departments where loacation_id in(1400,1700);
②查询员工姓名,要求部门号是①列表中的某一个
select last_name from employees where department_id in(select distinct department_id from departments where loacation_id in(1400,1700));
②查询员工姓名,要求部门号是①列表中的某一个
select last_name from employess where department_id=any(select distinct department_id from departments where loacation_id in(1400,1700));
②查询员工姓名,要求部门号是①列表中的某一个
select last_name from employess where department_id not in (select distinct department_id from departments where loacation_id in(1400,1700));
②查询员工姓名,要求部门号是①列表中的某一个
select last_name from employees where department_id<>all(select distinct department_id from departments where loacation_id in(1400,1700));
#返回其他工种中比job_id为’IT_PROG‘工种任一工资低的员工的员工号、姓名、job_id以及salary
①查询job_id为'IT_PROG'部门任一工资
select distinct salary from employees where job_id = 'IT_PROG';
②查询员工号、姓名、job_id以及salary,salary<(①)的任意一个
select last_name,employee_id,job_id,salary from employees where salary<any(select distinct salary from employees where job_id = 'IT_PROG') and job_id<>'IT_PROG';
②查询员工号、姓名、job_id以及salary,salary<(①)的任意一个
select last_name,employee_id,job_id,salary from employees where salary<(select max(salary) from employees where job_id = 'IT_PROG') and job_id<>'IT_PROG';
#返回其他部门中比job_id为'IT_PROG'部门所有工资都低的员工的员工号、姓名、job_id以及salary
select last_name,employee_id,job_id,salary from employees where salary< all(select distinct salary from employees where job_id='IT_PROG') and job_id<>'IT_PROG';
#或
selectlast_name,employee_id,job_id,salary from employees where salary<(select min(salary) from employess where job_id='IT_PROG') and job_id<>'IT_PROG';
#行子查询(结果集一行多列或多行多列)
#查询员工编号最小并且工资最高的员工信息
①查询最小的员工编号
select min(employee_id) from employees
②查询最高工资
select max(salary) from employess
③查询员工信息
select * from employess where employee_id=(select min(employee_id) from employees) and salary=(select max(salary) from employees);
#select后边(仅仅支持标量子查询)
#查询每个部门的员工个数
select d.*,(select count(*) from employees e where e.department_id=d.department_id)个数 from departments d;
#查询员工号=102的部门号
select(select department_name from departments d inner join employees e on d.department_id=e.department_id where e.employee_id=102)部门号;
#查询每个部门的平均工资的工资等级
①查询每个部门的平均工资
select avg(salary),department_id from employees group by department_id
②连接①的结果集合job_grade表,筛选条件平均工资between lowest_sal and highest_sal
select ag_dep.*,g.grade_level from (select avg(salary) ag,department_id from employees group by department_id) ag_dep inner join job_grades g on ag_dep.ag between lowest_sal and highest_sal;
#from后面(将子查询结果充当一张表,要求必须起别名)
#查询每个部门的平均工资的工资等级
①查询每个部门的平均工资
select avg(salary),department_id from employees group by department_id
#exists后面(相关子查询)
语法:
exists(完整的查询语句) #结果:1或0
select exists(select employee_id from employees where salary=300000);
#查询有员工的部门名
select department_name from departments d where exists(select * from employees e where d.department=e.department_id);
#查询和Zlotkey相同部门的员工姓名和工资
①查询Zlotkey的部门
select department_id from employees where last_name = 'Zlotkey'
②查询部门号=①的姓名和工资
selectlast_name,salary from employees where department_id = (select department_id from employees where last_name = 'Zlotkey');
#查询工资比公司平均工资高德员工的员工号,姓名和工资
①查询平均工资
select avg(salary) from employees
②查询工资>①的员工号,姓名和工资
select last_name,employee_id,salary from employees where salary>(select avg(salary) from employees);
#查询各部门中工资比本部门平均工资高德员工的员工号,姓名和工资
①查询各部门的平均工资
select avg(salary),department_id from employees group by department_id
②连接①结果集和employees表,进行筛选
select employees_id,last_name,salary,e.department_id from employees e inner join(select avg(salary) ag,department_id from employees group by department_id) ag_dep on e.department_id=ag_dep.department_id where salary>ag_dep.ag;
#查询和姓名中包含字母u的员工在相同部门的员工的员工号和姓名
①查询姓名中包含字母u的员工的部门
select distinct department_id from employees where last_name like '%u%'
②查询部门号=①中的任意一个的员工号和姓名
select last_name,employee_id from employees where department_id in(select distinct department_id from employees where last_name like '%u%');
#查询在部门的localhost_id为1700的部门工作的员工的员工号
①查询location_id为1700的部门
select distinct department_id from departments where location_id = 1700;
②查询部门号=①中的任意一个的员工号
select employee_id from employees where department_id =any(select distinct department_id from departments where location_id = 1700);
#查询管理者是king的员工姓名和工资
①查询姓名为king的员工编号
select employee_id form employees where last_name = 'K_ing';
②查询哪个员工的manager_id=①
select last_name,salary from employees where manager_id in(select employee_id from employees where last_name = 'K_ing');
#查询工资最高的员工的姓名,要求frist_name和last_name显示为一列,列名为姓.名
①查询最高的工资
select max(salary) from employees
②查询工资=①的姓.名
select concat(first_name,last_name) '姓.名' from employees where salary=(select max(salary) from employees);
#查询工资最低的员工信息:last_name,salary
①查询最低的工资
select min(salary) from employees
②查询last_name,salary,要求salary=①
select last_name,salary from employees where salary=(select min(salary) from employees);
#查询平均工资最低的部门信息
①各部门的平均工资
select avg(salary),department_id from employees group by department_id
②查询①结果上的最低平均工资
select min(ag) from(select avg(salary) ag,department_id from employees group by department_id)ag_dep
#where或having(标量子查询)
#查询最低工资的员工姓名和工资
①最低工资
select min(salary) from employees
②查询员工的姓名和工资,要求工资=①
select last_name,salary from employees where salary=(select min(salary) from employees);
③查询哪个部门的平均工资=②
select avg(salary),department_id from employees group by department_id having avg(salary)=(select min(ag) from (select avg(salary) ag,department_id from employees group by department_id)ag_dep);
④查询部门信息
select d.* from departments d where d.department_id = (
select department_id from employees group by department_id having avg(salary)=(
select min(ag) from(
select avg(salary) ag.department_id from employees group by department_id)ag_dep));
#方式二
①各部门的平均工资
select avg(salary),department_id from employees group by department_id
②求出最低平均工资的部门编号
select department_id from employees group by department_id order by avg(salary) limit 1;
③查询部门信息
select d.*,ag from department d join(
select avg(salary) ag,department_id from employees group by department_id order by avg(salary) limit 1
)ag_dep on d.department_id=ag_dep.department_id
#查询平均工资最高的job信息
①查询最高的job的平均工资
select avg(salary),job_id from employees group by job_id order by avg(salary) desc limit 1;
②查看jon信息
select * from jobs where job_id=(select job_id from employees group by job_id order by avg(salary) desc limit 1);
③查看部门信息
select * from departments where department_id(select department_id from employees group by department_id order by avg(salary) limit 1);
#查询平均工资高于公司平均工资的部门有哪些
①查询平均工资
select avg(salary) from employees
②查询每个部门的平均工资
select avg(salary) from employees group by department_id
③筛选②结果集,满足平均工资>①
select avg(salary) from employees group by department_id having avg(salary)>(select avg(salary) from employees)
#查询出公司中所有manager的详细信息
①查询所有manager的员工信息
select distinct manager_id from employees
②查询详情信息,满足employee_id=①
select * from employees where employee_id=any(select distinct manager_id from employees);
#各个部门中 最高工资中最低的那个部门的 最低工资是多少
①查询各部门的最高工资中最低的
select max(salary) from employees group by department_id order by max(salary) limit 1
#查询平均工资最高的部门的manager的详细信息:last_name,department_id,email,salary
①查询各部门的最高工资中最低的部门编号
select department_id from employees group by department_id order by max(salary) limit 1;
②查询①结果的那个部门的最低工资
select max(salary),department_id from employees where department_id=(select department_id from employees group by department_id order by max(salary) limit 1);
#或
①查询各部门的最高工资中最低的部门编号
select department_id from employees group by department_id order by avg(salary) desc limit 1;
②将employees和departments连接查询,筛选条件是①
select last_name,d.department_id,email,salary from employees e inner join departments d on d.manager_id = e.employee_id where d.department_id=(select department_id from employees group by department_id order by avg(salary) desc limit 1);
#查询每个专业的男生人数和女生人数分别是多少
select majorid,
(select count(*) from student where sex='男' and majorid=s.majorid) 男,
(select count(*) from student where sex='女' and majorid=s.majorid) 女
from student s group by majorid;
#查询专业和张翠山一样的学生的最低分
①查询张翠山的专业编号
select majorid from student where studentname = '张翠山'
②查询编号=①的所有学生编号
select min(score) from result where studentno in(
select studentno form student where majorid=(select majorid from student where studentname='张翠山')
)
#查询大于60分的学生的姓名、密码、专业名
select studentname,loginpwd,majorname from student s
join major m on s.majorid=m.majorid
join result r on s.studentno=r.studentno
where r.score>60;
#按邮箱位数分组,查询每组的学生个数
select count(*),length(email) form student group by length(email);
多行子查询:
-
返回多行
-
使用多行比较运算符
操作符 含义 in/not in 等于列表中的任意一个 any|some 和子查询返回的某一个值比较 all 和子查询返回的所有值比较
Exists
#语法:
select...from table where exists(子查询语句)
#EXISTS关键字的子查询。
EXISTS关键字后面的参数可以是任意一个子查询, 它不产生任何数据只返回TRUE或FALSE。当返回值为TRUE时外层查询才会执行。
#王五同学在学生表中则从班级表查询所有班级信息 MySQL命令:
select * from class where exists (select * from student where sname='王五');
该语法可以理解为:将主查询的数据,放到子查询中将条件验证,根据验证结果(true或false)来决定主查询的结果是否得以保留。
注意:
1.exists(子查询)只返回true或false,因此子查询中的select*也可以是select 1或selec 'X',官方说法是实际执行时会忽略select清单,因此没有区别。
2.exists子查询的实际执行过程可能经过了优化而不是我们理解上的逐条对比,如果担忧效率问题,可进行实际检验以确定是否有效率问题。
3.exists子查询往往也可以用条件表达式、其他子查询或者join来替代,任何最优需要具体问题具体分析。

联合查询:
union:联合的关键字。
合并:将多条查询语句的结果合并成一个结果
应用场景:要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时
意义:
- 将一条比较复杂的查询语句拆分成多条语句
- 适用于查询多个表的时候,查询的列基本是一致
特点:
- 要求多条查询语句的查询列表必须一致
- 要求多条查询语句的查询的各列类型,顺序最好一致
- union去重,union all包含重复项
#语法:
查询语句1
union
查询语句2
union
...
#示例:
#查询部门编号>90或邮箱包含a的员工信息
select * from employees where email like '%a%'
union
select * from employees where department_id>90;
#查询中国用户中男性的信息以及外国用户中年男性的用户信息
select id,cname,csex from t_ca where csex='男'
union
select t_id,tName,tGender form t_ua where tGender='male';
#order by只能加在最后语句后面
查询总结
重要(从关键字分析):
查询语句的书写顺序和执行顺序
select ===> from ===> where ===> group by ===> having ===> order by ===> limit
查询语句的执行顺序
from ===> where ===> group by ===> having ===> select ===> order by ===> limit
3、数据表的约束
一种限制,用于限制表中的数据,为了保证表中的数据的准确和可靠性。
| 关键字 | 名称 | 说明 |
|---|---|---|
| not null | 非空约束 | 字段不允许为空 |
| default | 默认约束 | 赋予某字段默认值 |
| unique key(UK) | 唯一约束 | 设置数值字段的值是唯一的,允许为空但只能有一个空值 |
| primary key(PK) | 主键约束 | 设置该字段为表的主键,可唯一标识该表记录 |
| foreign key(FK) | 外键约束 | 用于在两表之间建立关系,需要指定引用主表的哪一字段 |
| auto_increment | 自动增长 | 设置该列为自增字段,默认每条自增1,通常用于设置主键 |
| check | 检查约束(mysql不支持) | 检测和过滤不符合实际意义的数据 |
添加约束的时机:
- 创建表时
- 修改表时
约束的添加分类:
- 列级约束:除了外键约束都支持,不可以起约束名。可以在一个字段上追加多个约束,中间用空格隔开 没有顺序要求。
- 表级约束:除了非空、默认,其他的都支持,可以起约束 但对主键无效。
create table 表名(
字段名 字段类型 列级约束,
字段名 字段类型,
表级约束
);
#列级约束
#语法:
直接在字段名和类型后面追加约束类型即可
只支持:默认、非空、主键、唯一、自增
create table stuinfo(
id int primary key,#主键
stuName varchar(20) not null,#非空
gender char(1) check(gender='男' or gender='女'),#检查
seat int unique,#唯一
age int default 18,#默认约束
majorid int foreign key references major(id)#外键
);
#添加表级约束
#语法:在各个字段的最下面【constraint 约束名】约束类型(字段名)
create table stuinfo(
id int,
stuName varchar(20),
gender char(1),
seat int,
age int,
majorid int,
constraint pk primary key(id,stuname),#主键
constraint uq unique(seat,seat2),#唯一键
constraint ck check(gender='男' or gender='女'),#检查
constraint fk_stuinfo_major foreign key (majorid) references major(id)#外键
);
#通用的写法:
create table stuinfo(
id int primary key,#主键
stuName varchar(20) not null,#非空
gender char(1) check(gender='男' or gender='女'),#检查
seat int unique,#唯一
age int default 18,#默认约束
majorid int,
constraint fk_stuinfo_major foreign key (majorid) references major(id)#外键
);
主键和唯一的大对比:
| 保证唯一性 | 是否允许为空 | 一个表中可以有多少个 | 是否允许组合 | |
|---|---|---|---|---|
| 主键 | √ | x | 至多有1个 | √,但不推荐 |
| 唯一 | √ | √ | 可以有多个 | √,但不推荐 |
1、主键约束
主键约束即primary key用于唯一的标识表中的每一行。被标识为主键的数据在表中是唯一的并且值不能为空。
字段名 数据类型 primary key;
设置主键约束(primary key)的第一种方式:
create table student(
id int primary key,
name varchar(20)
);
设置主键约束(primary key)的第二种方式:
create table student01(
id int
name varchar(20),
primary key(id)
);
#添加主键
alter table 表名 add primary key(字段名);
alter table name add primary key(col);
#删除主键
alter table 表名 drop primary key;
alter table name drop primary key(col);
#组合主键
alter table name add primary key(col,col2);
只有当两个主键都重复 才叫重复。
2、非空约束
非空约束即 NOT NULL指的是字段的值不能为空
字段名 数据类型 NOT NULL;
示例:MySQL命令:
create table student02(
id int
name varchar(20) not null
);
#添加非空
alter table 表名 modify column 字段名 字段类型 not null;
#删除非空
alter table 表名 modify column 字段名 字段类型;
3、默认值约束
默认值约束即default用于给数据表中的字段指定默认值,即当在表中插入一条新记录时若未给该字段赋值,那么,数据库系统会自动为这个字段插人默认值;
字段名 数据类型 DEFAULT 默认值;
示例:MySQL命令:
create table student03(
id int,
name varchar(20),
gender varchar(10) default 'male'
);
#添加默认
alter table 表名 modify column 字段名 字段类型 default 值;
#删除默认
alter table 表名 modify column 字段名 字段类型;
4、唯一性约束
唯一性约束即UNIQUE用于保证数据表中字段的唯一性,即表中字段的值不能重复出现
字段名 数据类型 UNIQUE;
示例:MySQL命令:
create table student04(
id int,
name varchar(20) unique
);
#添加唯一
alter table 表名 add 【constraint 约束名】 unique(字段名);
#删除唯一
alter table 表名 drop index 索引名;
#组合唯一键
alter table name add UNIQUE(col,col2);
只有当两个唯一键都重复 才叫重复。
5、外键约束
外键约束即FOREIGN KEY常用于多张表之间的约束 :用于限制两个表的关系,用于保证该字段的值必须来自于主表的
- 要求在从表设置外键关系
- 从表的外键列的类型和主表的关联列的类型要求一致或兼容,名称无要求
- 主表的关联列必须是一个key(一般是主键或唯一)
- 插入数据时,先插入主表,再插入从表
- 删除数据时,先删除从表,再删除主表
-- 在创建数据表时语法如下:
constraint 外键名 FOREIGN KEY (从表外键字段) REFERENCES 主表 (主键字段)
constraint 约束名 foreign key(字段名) references 主表(被引用列)
-- 将创建数据表创号后语法如下:
ALTER TABLE 从表名 ADD CONSTRAINT 外键名 FOREIGN KEY (从表外键字段) REFERENCES 主表 (主键字段);
#示例:创建一个学生表 MySQL命令:
create table student05(
id int primary key,
name varchar(20)
);
#示例:创建一个班级表 MySQL命令:
create table class(
classid int primary key,
studentid int
);
#示例:学生表作为主表,班级表作为副表设置外键:
alter table class add constraint fk_class_studentid foreign key(studentid) references student05(id);
#删除外键:
alter table 从表名 drop foreign key 外键名;
alter table stuinfo drop foreign key fk;
#级联删除
alter table stuinfo add constraint fk_stu_major foreign key(majorid) references major(id) on delete cascade;
#级联置空
alter table stuinfo add constraint fk_stu_major foreign key(majorid) references major(id) on delete set null;
#传统的方式添加外键
alter table stuinfo add constraint fk_stu_major foreign key(majorid) references major(id);
#添加外键
alter table 表名 add【constraint 约束名】|foreign key(字段名) references 主表(被引用列);
#删除外键
altert table 表名 drop foreign key 约束名;
外键约束数据一致性概念&注意的细节:
建立外键是为了保证数据的完整和统一性。如果主表中的数据被删除或修改从表中对应的数据,从表中对应的数据也应该被删除或修改,否则数据库中会存在很多无意义的垃圾数据。
1、从表里的外键通常为主表的主键
2、从表里外键的数据类型必须与主表中主键的数据类型一致
3、主表发生变化时应注意主表与从表的数据一致性问题
6、检查约束
check:检查约束【mysql中不支持】
检查约束是一个规则,它确认一个SQL Server表中某条记录中的数据可接受的字段值。检查约束帮助执行域完整性。域完整性定义了一个数据库表中字段的有效值。检查约束可以验证一个单独字段或一些字段的域完整性。你对一个单独的字段可以有多个检查完整性。如果被插入或更新的数据违反了一个检查约束,那么数据库引擎将不允许这个插入或更新的操作发生。
检查约束包括一个逻辑表达式,用以确认什么是有效的表达式。逻辑表达式可能是一个单独的表达式比如“Salary < 200000.00”,或多个表达式,比如“RentalDate > GETDATE() and RentalDate < DATEADD(YY,1,GETDATE())”。如果一个逻辑表达式的一个检查约束返回了FALSE值,那么这个检查约束将限制这个表中数据插入或更新。对于逻辑表达式返回的是FALSE以外的值的所有记录将通过这个检查约束并允许记录被更新或插入。为了这个记录能够被插入或更新,与给定INSERT或UPDATE语句相关的所有数据都不能进行检查约束失败(返回一个FALSE值)。检查约束可以在字段级别或表级别被创建。
CREATE TABLE dbo.Payroll
(
ID int PRIMARY KEY,
PositionID INT,
SalaryType nvarchar(10),
Salary decimal(9,2)
CHECK (Salary < 150000.00)
);
7、自增长
又称标识列。
含义:可以不用手动的插入值,系统提供默认的序列值
特点:
-
标识列不一定和主键搭配,但必须是一个key,
-
一个表可以有至多一个自增长列
-
自增长的列只支持数值型,
-
默认从1开始,步长为1auto_increment_increment。
- 如果要更改起始值:手动插入值
- 如果要更改步长:更改系统变量
set auto_increment_increment=值;#设置步长
set auto_increment_increment=3;#设置步长
#创建表时设置标识列
create table tab(
id int primary key auto_increment,
name varchar(20)
);
#查看表中的标识列
show variables like '%auto_increment%';
#设置自增长列
alter table 表 modify column 字段名 字段类型 约束 auto_increment;
alter table tab modify column id int primary key auto_increment;
#删除自增长列
alter table 表 modify column 字段名 字段类型 约束;
alter table tab modify column id int;
约束总结:
#语法:
#添加列级约束
alter table 表名 modify column 字段名 字段类型 新约束;
#添加表级约束
alter table 表名 add 【constraint 约束名】约束类型(字段名) 【外键的引用】;
#添加非空约束
alter table stuinfo modify column stuname varchar(20) not null;
#添加默认约束
alter table stuinfo modify column age int default 18;
#添加主键
#1.列级约束
alter table stuinfo modify column id int primary key;
#2.表级约束
alter table stuinfo add primary key(id);
#唯一约束
#1.列级约束
alter table stuinfo modify column seat int unique;
#2.表级约束
alter table stuinfo add unique(seat);
#添加外键
alter table stuinfo add constraint fk_stuinfo_major foreign key(mahorid) references major(id);
#删除非空约束
alter table stuinfo modify column stuname varchar(20) null;
#删除默认约束
alter table stuinfo modify column age int;
#删除主键
alter table stuinfo drop primary key;
#删除唯一
alter table stuinfo drop index seat;
#删除外键
alter table stuinfo drop foreign key fk_stuinfo_magor;
#示例:
#向表emp2的id列中添加primary key约束(my_emp_id_pk)
alter table emp2 modify column id int primary key;
alter table emp2 add constraint my_emp_id_pk primary key(id);
#向表emp2中添加列dept_id,并在其中定义foreign key约束,与之相关联的列是dept2表中的id列
alter table emp2 add column dept_id int;
alter table emp2 add constraint fk_emp2_dept2 foreign key(dept_id) references dept2(id);
五、事务
事务:数据库的事务是指一组sql语句组成的数据库逻辑处理单元,在这组的sql操作中,要么全部执行成功,要么全部执行失败; 事务是一组不可再分割的操作集合。
事务是数据库管理系统的(DBMS)执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。主要用于执行DML语句。
事务由单独单元的一个或多个SQL语句组成,在这个单元中,每个M有SQL语句是相互依赖的。而整个单独单元作为一个不可分割的整体,如果单元中某条SQL语句一且执行失败或产生错误,这个单元都会回滚,这个事务中所有受到影响的数据将返回事务开始之前的状态;如果单元中所有SQL语句均执行成功,则事务被顺利执行。
TCL:Transaction Control Language事务控制语言。
逻辑处理单元 是数据库的最小工作单元,不可再分。
隐式(自动)事务:没有明显的开启和结束,本身就是一条事务可以自动提交,比如insert、update、delete
显示事务:具有明显的开启和结束,
#使用显示事务:
1.set autocommit=0;关闭自动提交
2.start transaction;开启事务,可以省略
3.编写一组逻辑SQL语句,
注意:SQL语句支持的是insert、update、delate。select语句没意义。
4.savepoint 回滚点名;设置回滚点
5.结束事务
- commit;提交
- rollback;回滚
- rollback to 回滚点名;回滚到设置回滚点的地方。
delete和truncate在事务使用时的区别:
#演示delete
set autocommit=0;
start transaction;
delete from account;
rollback;
#演示truncate
set autocommit=0;
start transaction;
truncate table account;
rollback;
#关闭自动提交事务:
set session autocommit=off;
#自动提交事务:
set session autocommit=on;
#开始事务:
begin/start transaction
#提交事务:
commit
#回滚事务:
rollback
#事务的创建
#隐式事务:事务没有明显的开启和结束的标记
比如insert、update、delete语句
#显示事务的语句:事务具有明显的开启和结束的标记
前提:必须先设置自动提交功能为禁用
set autocommit=0;
#开启事务
start transaction;
语句一;
语句二;
...
#结束事务的语句;
commit;#提交事务
或
rollback;#回滚事务
事务执行顺序:
1、先执行begin/start transaction,
2、再执行语句,
3、在执行提交/回滚事务。
执行开始事务后,不提交,关闭sql窗口,会自动回滚。

事务的四大特性(ACID):
原子性(Atomicity):
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency):
事务前后数据的完整性必须保持一致。事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
隔离性(Isolation):
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性(Durability):
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
事务并发的三大问题:
事务并发的三大问题其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制开解决。
并发事务就是:多个事务同时操作同一个数据库的相同数据时。
脏读
Dirty Reads
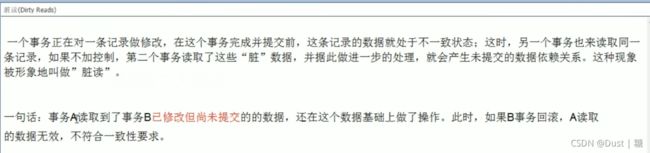
一个事务对数据进行了增删改查,但是未提交事务。另一个事物可以读取到未提交的数据,如果第一个事务进行了回滚,那么第二个事务就读到了脏数据。
例子:
领导给张三发工资,10000元已打到张三账户,但该事务还未提交,正好这时候张三去查询工资,发现10000元已到账。这时领导发现张三工资算多了5000元,于是回滚了事务,修改了金额后将事务提交。最后张三实际到账的只有5000元。
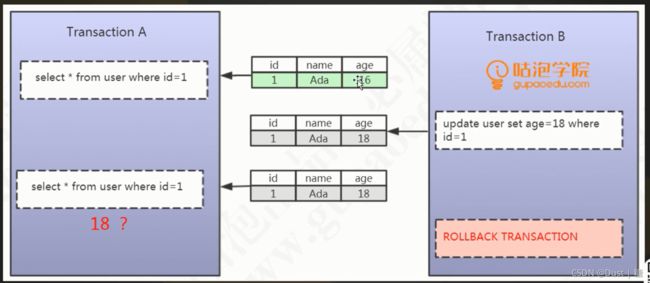
不可重复读
Non-Repeatable Reads

不可重读,两次读到的数据不一样。
一次事务发生了两次读操作,两个读操作之间发生了另一个事务对数据修改操作,这时候第一次和第二次读到的数据不一致。
不可重复度关注点在数据更新和删除,通过行级锁可以实现可重复读的隔离级别。
例子:
张三需要转正1000元,系统读到卡余额有2000元,此时张三老婆正好需要转正2000元,并且在张三提交事务前把2000元转走了,当张三提交转账是系统提示余额不足。

幻读
Phantom Reads

幻读,数据库中有三条数据 将数据库中的所有数据都修改为name为aa,但是当我修改完还没提交的时候,另一个事务进来了 添加了一条数据 并提交了,然后,当我那天修改数据的事务提交的时候发现4行受到影响,哎 我里面明明只有3条数据 为什么会4条受到影响呢?这就是幻读
幻读,指的是当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录时,会产生幻行。
相对于不可重复读,幻读更关注其它事务的新增数据。通过行级锁可以避免不可重复读,但无法解决幻读的问题,想要解决幻读,只能通过Serializable隔离级别来实现。
例子:
张三老婆准备打印张三这个月的信用卡消费记录,经查询发现消费了两次共1000元,而这时张三刚按摩完准备结账,消费了1000元,这时银行记录新增了一条1000元的消费记录。当张三老婆将消费记录打印出来时,发现总额变为了2000元,这让张三老婆很诧异。

更新丢失
Lost Update
MySQL事务隔离级别
数据库事务的隔离性:数据库系统必须具有隔离并发运行各个事务的能力,使他们不会相互影响 避免各种并发问题。一个事务与其他事务隔离的程度称为隔离级别,数据库规定了多种事务隔离界别,不同隔离级别对应不同的干扰程度,隔离级别越高,数据一致性就越好,但并发性越弱。
READ UNCOMMITTED(读未提交):事务中的修改即使未提交也是对其它事务可见
READ COMMITTED(读提交):事务提交后所做的修改才会被另一个事务看见,可能产生一个事务中两次查询的结果不同。
REPEATABLE READ(可重读):只有当前事务提交才能看见另一个事务的修改结果。解决一个事务中两次查询的结果不同的问题。 MySQL默认的隔离级别。
SERIALIZABLE(串行化):只有一个事务提交之后才会执行另一个事务。解决事务并发所有问题!执行效率慢,使用时慎重。
| 隔离级别 | 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| Read-Uncommitted(未提交读) | 0 | 是 | 是 | 是 |
| Read-Committed(已提交) | 1 | 否 | 否 | 是 |
| Repeatable-Read(可重复读)Mysql默认 | 2 | 否 | 否 | 是 |
| Serializable(串行化) | 3 | 否 | 否 | 否 |
在InnoDB中Repeatable-Read(可重复读)可以解决脏读、不可重复读、幻读三大问题。
Read-Uncommitted 不加锁
Serializable 所有的select语句都会被隐式的转化为select… lock in share mode (共享锁),会和update、delete互斥。
Oracle支持的2种事务隔离级别:READ COMMITEN,SERIALIZABLE。默认的事务隔离级别为:READCOMMITED。

#查看事务隔离级别
select @@tx_isolation;
#设置隔离级别
#语法:set session|global transaction isolation level 隔离级别;
set session transaction isolation level read uncommittid;
set session transaction isolation level read committid;
set session transaction isolation level read repeatable read;
set session transaction isolation level read serializable;
#设置当前MySQL连接的隔离级别:
set transaction isolation level read committid;
#设置数据库系统的全局的隔离级别:
set global transaction isolation level read committed;
#savepoint的使用
set autocommit=0;
start transaction;
delete from account where id=25;
savepoint a;#设置保存点,a为保存点名(随便取)
delete from account where id=28;
rollback to a;#回滚到保存点
隔离级别的实现:
普通的select叫 快照读

MVCC:
MVCC,全称Multi-Version Concurrency Control,即多版本并发控制。MVCC是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。
这是百度百科给的标准的回答
多版本的意思就是数据库中同时存在多个版本的数据,并不是整个数据库的多个版本,而是某一条记录的多个版本同时存在,在某个事务对其进行操作的时候,需要查看这一条记录的隐藏列事务版本id,比对事务id并根据事物隔离级别去判断读取哪个版本的数据。
InnoDB三个隐藏字段:
在Mysql中MVCC是在Innodb存储引擎中得到支持的,Innodb为每行记录都实现了三个隐藏字段:
- 6字节的事务ID(DB_TRX_ID )
- 7字节的回滚指针(DB_ROLL_PTR)
- 隐藏的ID(rowid)
| (列名 | 是否必须 | 描述 |
|---|---|---|
| row_id | 否 | 行ID,唯一标识一条记录(如果定义主键,它就没有啦) |
| transaction_id | 是 | 事务ID |
| roll_pointer | 是 | DB_ROLL_PTR是一个回滚指针,用于配合undo日志,指向上一个旧版本 |
RR和RC是什么:
1、 RR 支持间隙锁gap lock和next-key lock临键锁,而RC则没有间隙锁gap lock。因为MySQL的RR需要间隙锁gap lock来解决幻读问题。而RC隔离级别则是允许存在不可重复读和幻读的。所以RC的并发一般要好于RR;
2、RC 隔离级别,通过 where 条件走非索引列过滤之后,不符合条件的记录上的行锁,会释放掉(虽然这里破坏了“两阶段加锁原则”);但是RR隔离级别,通过 where 条件走非索引列过滤之后,即使不符合where条件的记录,也是会加行锁。所以从锁方面来看, RC 的并发应该要好于RR;可以减少一部分锁竞争,减少死锁和锁超时的概率。
3、隔离级别不支持 statement 格式的bin log,因为该格式的复制,会导致主从数据的不一致;只能使用 mixed 或者 row 格式的bin log; 这也是为什么MySQL默认使用RR隔离级别的原因。复制时,我们最好使用:binlog_format=row
4、MySQL5.6 的早期版本, RC 隔离级别是可以设置成使用statement格式的bin log,后期版本则会直接报错;
5、简单而且,RC隔离级别时,事务中的每一条select语句会读取到他自己执行时已经提交了的记录,也就是每一条select都有自己的一致性读ReadView; 而RR隔离级别时,事务中的一致性读的ReadView是以第一条select语句的运行时,作为本事务的一致性读snapshot的建立时间点的。只能读取该时间点之前已经提交的数据。
Innodb的事务相关概念
为了支持事务,Innbodb引入了下面几个概念:
-
redo log
redo log就是保存执行的SQL语句到一个指定的Log文件,当Mysql执行recovery时重新执行redo log记录的SQL操作即可。当客户端执行每条SQL(更新语句)时,redo log会被首先写入log buffer;当客户端执行COMMIT命令时,log buffer中的内容会被视情况刷新到磁盘。redo log在磁盘上作为一个独立的文件存在,即Innodb的log文件。 -
undo log
与redo log相反,undo log是为回滚而用,具体内容就是copy事务前的数据库内容(行)到undo buffer,在适合的时间把undo buffer中的内容刷新到磁盘。undo buffer与redo buffer一样,也是环形缓冲,但当缓冲满的时候,undo buffer中的内容会也会被刷新到磁盘;与redo log不同的是,磁盘上不存在单独的undo log文件,所有的undo log均存放在主ibd数据文件中(表空间),即使客户端设置了每表一个数据文件也是如此。 -
rollback segment
回滚段这个概念来自Oracle的事物模型,在Innodb中,undo log被划分为多个段,具体某行的undo log就保存在某个段中,称为回滚段。可以认为undo log和回滚段是同一意思。 -
锁
Innodb提供了基于行的锁,如果行的数量非常大,则在高并发下锁的数量也可能会比较大,据Innodb文档说,Innodb对锁进行了空间有效优化,即使并发量高也不会导致内存耗尽。
对行的锁有分两种:排他锁、共享锁。共享锁针对对,排他锁针对写,完全等同读写锁的概念。如果某个事务在更新某行(排他锁),则其他事物无论是读还是写本行都必须等待;如果某个事物读某行(共享锁),则其他读的事物无需等待,而写事物则需等待。通过共享锁,保证了多读之间的无等待性,但是锁的应用又依赖Mysql的事务隔离级别。 -
隔离级别
隔离级别用来限制事务直接的交互程度,目前有几个工业标准:-
READ_UNCOMMITTED:脏读
-
READ_COMMITTED:读提交
-
REPEATABLE_READ:重复读
-
SERIALIZABLE:串行化
Innodb对四种类型都支持,脏读和串行化应用场景不多,读提交、重复读用的比较广泛。
-
事务隔离级别的解决方案:
两者可以协同使用
-
第一种:
在读取数据前,对其加锁,阻止其他事务对数据进行修改——Lock Based Concurrency Control(LBCC)。
-
第二种:
生成一个数据请求时间点的一致性数据快照(Snapshot),并用这个快照来提供一定级别的(语句级或事务级)的一致性读取——Multi Version Concurreny Control(MVCC)。
六、MySql锁
事务持有的锁,在事务结束的时候才会释放。要么回滚、要么提交。
事务和锁息息相关
锁是计算机协调多个进程或线程并发访问某一资源的机制。

在数据库中,除传统的计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一直性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。从这个角度来说,锁对数据库而言显得尤其重要,也更复杂。

锁的作用:
锁是计算机协调多个进程或线程并发访问某一资源的机制。锁保证数据并发访问的一致性、有效性;锁冲突也是影响数据库并发访问性能的一个重要因素。锁是Mysql在服务器层和存储引擎层的的并发控制。
加锁是消耗资源的,锁的各种操作,包括获得锁、检测锁是否是否已解除、释放锁等。
开销、加锁速度、死锁、粒度、并发性能只能就具体应用的特点来说那种锁更合适。
行锁会发生死锁,表锁不会发生死锁。
nolock 是 SQL Server 特有的功能。
例如:对于一个表 A,更新了一行,还没有commit,这时再select * from A 就会死锁。用select * from A(nolock)可以防止死锁,nolock可以忽略锁,直接从数据库读取数据。这意味着可以避开锁,从而提高性能和扩展性。但同时也意味着代码出错的可能性存在。你可能会读取到运行事务正在处理的无须验证的未递交数据。 这种风险可以量化。
mysql 没有这方面问题,对于一个表 A,更新了一行,还没有commit, SELECT * FROM A, 将查询到更新以前的原始数据记录,而不会出现死锁问题。
锁级别:
MySQL的锁级别有以下三种:行级、表级、页级。
| 类型 | 开销 | 加锁速度 | 是否会发生死锁 | 锁定粒度 | 锁冲突概率 | 并发度 |
|---|---|---|---|---|---|---|
| 行级锁 | 大 | 慢 | 会 | 最小 | 最低 | 最高 |
| 表级锁 | 小 | 快 | 不会 | 最大 | 最高 | 最低 |
| 页级锁 | 适中 | 适中 | 会 | 适中 | 适中 | 适中 |
三种锁的对比:
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
Innodb中的行锁与表锁选择
InnoDB行锁是通过给索引上的索引项加锁来实现的,只有通过索引(主键索引、唯一索引或普通索引)条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
行级锁,表锁又分为共享锁(lock in share mode)和 排他锁(for update):
默认:数据库的增删改操作都会加排他锁,而查询不会加任何锁。
共享锁(乐观锁|S锁):允许不同事务之前共享加锁读取,但不允许其它事务修改或者加入排他锁;
select ... from table where id = xxx lock in share mode;
排他锁(悲观锁|X锁):当一个事务加入排他锁后,不允许其他事务加共享锁或者排它锁读取,更加不允许其他事务修改加锁的行。
select ... from table where id = xxx for update;
InnoDB行锁实现方式
InnoDB行锁是通过给索引上的索引项加锁来实现的,这一点MySQL与Oracle不同,后者是通过在数据块中对相应数据行加锁来实现的。InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
锁调度和分析:
前面讲过,MyISAM存储引擎的读锁和写锁是互斥的,读写操作是串行的。那么,一个进程请求某个 MyISAM表的读锁,同时另一个进程也请求同一表的写锁,MySQL如何处理呢?答案是写进程先获得锁。不仅如此,即使读请求先到锁等待队列,写请求后到,写锁也会插到读锁请求之前!这是因为MySQL认为写请求一般比读请求要重要。这也正是MyISAM表不太适合于有大量更新操作和查询操作应用的原因,因为,大量的更新操作会造成查询操作很难获得读锁,从而可能永远阻塞。这种情况有时可能会变得非常糟糕!幸好我们可以通过一些设置来调节MyISAM 的调度行为。
-
通过指定启动参数low-priority-updates,使MyISAM引擎默认给予读请求以优先的权利。
-
通过执行命令SET LOW_PRIORITY_UPDATES=1,使该连接发出的更新请求优先级降低。
-
通过指定INSERT、UPDATE、DELETE语句的LOW_PRIORITY属性,降低该语句的优先级。
虽然上面3种方法都是要么更新优先,要么查询优先的方法,但还是可以用其来解决查询相对重要的应用(如用户登录系统)中,读锁等待严重的问题。
另外,MySQL也提供了一种折中的办法来调节读写冲突,即给系统参数max_write_lock_count设置一个合适的值,当一个表的读锁达到这个值后,MySQL就暂时将写请求的优先级降低,给读进程一定获得锁的机会。
上面已经讨论了写优先调度机制带来的问题和解决办法。这里还要强调一点:一些需要长时间运行的查询操作,也会使写进程“饿死”!因此,应用中应尽量避免出现长时间运行的查询操作,不要总想用一条SELECT语句来解决问题,因为这种看似巧妙的SQL语句,往往比较复杂,执行时间较长,在可能的情况下可以通过使用中间表等措施对SQL语句做一定的“分解”,使每一步查询都能在较短时间完成,从而减少锁冲突。如果复杂查询不可避免,应尽量安排在数据库空闲时段执行,比如一些定期统计可以安排在夜间执行
调度与锁定问题
前面各段主要将精力集中在使个别的查询更快上。mysql还允许影响语句的调度特性,这样会使来自几个客户机的查询更好地协作,从而单个客户机不会被锁定太长的时间。更改调度特性还能保证特定的查询处理得更快。我们先来看一下MySQL的缺省调度策略,然后
来看看为改变这个策略可使用什么样的选项。出于讨论的目的,假设执行检索( SELECT)的客户机程序为读取程序。执行修改表操作( DELETE,INSERT,REPLACE 或UP DATE)的另一个客户机程序为写入程序。
MySQL的基本调度策略可总结如下:
■ 写入请求应按其到达的次序进行处理。
■ 写入具有比读取更高的优先权。
在表锁的帮助下实现调度策略。客户机程序无论何时要访问表,都必须首先获得该表的锁。可以直接用LOCK TABLES 来完成这项工作,但一般服务器的锁管理器会在需要时自动获得锁。在客户机结束对表的处理时,可释放表上的锁。直接获得的锁可用UNLOCK TABLES 释放,但服务器也会自动释放它所获得的锁。
执行写操作的客户机必须对表具有独占访问的锁。在写操作进行中,由于正在对表进行数据记录的删除、增加或更改,所以该表处于不一致状态,而且该表上的索引也可能需要作相应的更新。如果表处于不断变化中,此时允许其他客户机访问该表会出问题。让两个客户
机同时写同一个表显然不好,因为这样会很快使该表不可用。允许客户机读不断变化的表也不是件好事,因为可能在读该表的那一刻正好正在对它进行更改,其结果是不正确的。执行读取操作的客户机必须有一把防止其他客户机写该表的锁,以保证读表的过程中表不出现变化。不过,该锁无需对读取操作提供独占访问。此锁还允许其他客户机同时对表进行读取。读取不会更改表,所有没必要阻止其它客户机对该表进行读取。
MySQL允许借助几个查询限修饰符对其调度策略施加影响。其中之一是DELETE、INSERT、LOAD DATA、REPLACE 和UP DATE 语句的LOW_PRIORITY 关键字。另一个是SELECT 语句的HIGH_PRIORITY 关键字。第三个是INSERT 和REPLACE 语句的DELAYED 关键字。
LOW_PRIORITY 关键字按如下影响调度。一般情况下,如果某个表的写入操作在表正被读取时到达,写入程序被阻塞,直到读取程序完成,因为一旦某个查询开始,就不能中断。如果另一读取请求在写入程序等待时到达,此读取程序也被阻塞,因为缺省的调度策略为写
入程序具有比读取程序高的优先级。在第一个读取程序结束时,写入程序继续,在此写入程序结束时,第二个读取程序开始。
如果写入请求为LOW_PRIORITY 的请求,则不将该写入操作视为具有比读取操作优先级高的操作。在此情形下,如果第二个读取请求在写入程序等待时到达,则让第二个读取操作排在等待的写入操作之前。仅当没有其他读取请求时,才允许写入程序执行。这种调度的
更改从理论上说,其含义为LOW_PRIORITY 写入可能会永远被阻塞。当正在处理前面的读取请求时,只要另一个读取请求到达,这个新的请求允许排在LOW_PRIORITY 写入之前。
SELECT 查询的HIGH_PRIORITY 关键字作用类似。它使SELECT 插在正在等待的写入操作之前,即使该写入操作具有正常的优先级。INSERT 的DELAYED 修饰符作用如下,在表的一个INSERT DELAYED 请求到达时,服务器将相应的行放入一个队列,并立即返回一个状态到客户机程序,以便该客户机程序可以继续执行,即使这些行尚未插入表中。如果读取程序正在对表进行读取,那么队列中的行
挂起。在没有读取时,服务器开始开始插入延迟行队列中的行。服务器不时地停下来看看是否有新的读取请求到达,并进行等待。如果是这样,延迟行队列将挂起,并允许读取程序继续。在没有其他的读取操作时,服务器再次开始插入延迟行。这个过程一直进行到延迟行队
列空为止。
此调度修饰符并非出现在所有MySQL版本中。下面的表列出了这些修饰符和支持这些修饰符的MySQL版本。可利用此表来判断所使用的MySQL版本具有什么样的功能:
INSERT DELAYED 在客户机方的作用:
如果其他客户机可能执行冗长的SELECT 语句,而且您不希望等待插入完成,此时INSERT DELAYED 很有用。发布INSERT DELAYED 的客户机可以更快地继续执行,因为服务器只是简单地将要插入的行插入。不过应该对正常的INSERT 和INSERT DELAYED 性能之间的差异有所认识。如果INSERT DELAYED 存在语法错误,则向客户机发出一个错误,如果正常,便不发出信息。例如,在此语句返回时,不能相信所取得的AUTO_INCREMENT 值。也得不到惟一索引上的重复数目的计数。之所以这样是因为此插入操作在实际的插入完成前返回了一个状
态。其他还表示,如果INSERT DELAYED 语句的行在等待插入中被排队,并且服务器崩溃或被终止(用kill -9),那么这些行将丢失。正常的TERM 终止不会这样,服务器会在退出前将这些行插入。


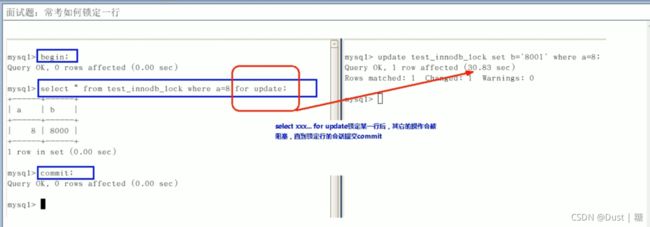
for update用法:
在高并发场景下对数据的准确行有很高的要求,用到了 for update。
Select …forupdate语句是我们经常使用手工加锁语句。通常情况下,select语句是不会对数据加锁,妨碍影响其他的DML和DDL操作。同时,在多版本一致读机制的支持下,select语句也不会被其他类型语句所阻碍。
借助for update子句,我们可以在应用程序的层面手工实现数据加锁保护操作。
-
for update的使用场景
一般这些操作都是很长一串并且是开启事务的。如果库存刚开始读的时候是1,而立马另一个进程进行了update将库存更新为0了,而事务还没有结束,会将错的数据一直执行下去,就会有问题。
需要
for upate进行数据加锁防止高并发时候数据出错 -
for update 如何使用
select * from t_table where xxx for update -
for update 怎么锁表
InnoDB默认是行级别的锁,当有明确指定的主键时候,是行级锁。否则是表级别。例如:假设表foods ,存在有id跟name、status三个字段,id是主键,status有索引。
1> 明确指定主键,并且有此记录,行级锁
SELECT * FROM foods WHERE id=1 FOR UPDATE; SELECT * FROM foods WHERE id=1 and name=’咖啡色的羊驼’ FOR UPDATE;2> 明确指定主键/索引,若查无此记录,无锁
SELECT * FROM foods WHERE id=-1 FOR UPDATE;3> 无主键/索引,表级锁
SELECT * FROM foods WHERE name=’咖啡色的羊驼’ FOR UPDATE;4> 主键/索引不明确,表级锁
SELECT * FROM foods WHERE id<>’3’ FOR UPDATE; SELECT * FROM foods WHERE id LIKE ‘3’ FOR UPDATE; -
for update的注意点
-
for update 仅适用于InnoDB,并且必须开启事务,在begin与commit之间才生效。
-
要测试for update的锁表情况,可以利用MySQL的Command Mode,开启二个视窗来做测试。
-
存储引擎与锁
MyIsam存储引擎:
特点:开销小、加锁快,无死锁,锁定粒度大,发生锁冲突的概率最高,并发度最低,支持表锁。
MyISAM在执行查询语句(select)前,会自动给涉及的所有表加读锁,在执行增删改操作前,会自动给涉及的表加写锁。
MySQL的表级锁有两种模式:
表共享读锁(Table Read Lock)
表独占写锁(Tbale Wirte Lock)
| 锁类型 | 可否兼容 | 读锁 | 写锁 |
|---|---|---|---|
| 读锁 | 是 | 是 | 否 |
| 写锁 | 是 | 否 | 否 |
结论:
结合上表,所以读MyISAM表进行操作,会有以下情况:
1、对MyISAM表的读操作(加读锁),不会阻塞其他进程对同一表的读请求,但会阻塞对同一表的写请求。只有当读锁释放后,才会执行其他进程的写操作。
2、对MyISAM表的写操作(加写锁),会阻塞其他进程对同一表的读和写操作,只有当写锁释放后,才会执行其他进程的读写操作。
简而言之,就是读锁会阻塞写,但不会阻塞度。而写锁则会把读和写都阻塞。
InnoDB存储引擎:
特点:开销大、加锁慢,会出现死锁,锁定粒度最小,发生锁冲突的概率最低,并发度也最高,支持行锁。

锁的粒度:
表锁与行锁的区别:
锁定粒度:表锁>行锁
加锁效率:表锁<行锁
冲突概率:表锁>行锁
并发性能:表锁<行锁
锁的模式:
-
共享锁(行锁):Shared Locks
-
排它锁(行锁):Exclusive Locks
-
意向共享锁(表锁):Intention Shared Locks
-
意向排它锁(表锁):Intention Exclusive Locks
行锁算法:
- 记录锁 Record Locks
- 间隙锁 Gap Locks
- 临键锁 Next-key Locks
全局锁:
全局锁就是对整个数据库实例加锁。MySQL 提供了一个加全局读锁的方法,命令是Flush tables with read lock (FTWRL)。
当你需要让整个库处于只读状态的时候,可以使用这个命令,之后其他线程的以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。
全局锁使用场景:
全局锁的典型使用场景是,做全库逻辑备份(mysqldump)。重新做主从时候。
也就是把整库每个表都 select 出来存成文本。
以前有一种做法,是通过 FTWRL 确保不会有其他线程对数据库做更新,然后对整个库做备份。注意,在备份过程中整个库完全处于只读状态。
数据库只读状态的危险性:
如果你在主库上备份,那么在备份期间都不能执行更新,业务基本上就能停止。
如果你在从库上备份,那么备份期间从库不能执行主库同步过来的binlog,会导致主从延迟。
注:上面逻辑备份,是不加–single-transaction参数
不加锁产生的问题
比如手机卡,购买套餐信息
这里分为两张表 u_acount (用于余额表),u_pricing (资费套餐表)
步骤:
1. u_account 表中数据 用户A 余额:300
u_pricing 表中数据 用户A 套餐:空
2. 发起备份,备份过程中先备份u_account表,备份完了这个表,这个时候u_account 用户余额是300
3. 这个时候套用户购买了一个资费套餐100,餐购买完成,写入到u_print套餐表购买成功,备份期间的数据。
4. 备份完成
可以看到备份的结果是,u_account 表中的数据没有变, u_pricing 表中的数据 已近购买了资费套餐100.
哪这时候用这个备份文件来恢复数据的话,用户A 赚了100 ,用户是不是很舒服啊。但是你的想想公司利益啊。
也就是说,不加锁的话,备份系统备份的得到的库不是一个逻辑时间点,这个数据是逻辑不一致的。
为什么需要全局读锁(FTWRL)
可能有的人在疑惑,官方自带的逻辑备份工具是 mysqldump。当 mysqldump 使用参数–single-transaction的时候,导数据之前就会启动一个事务,来确保拿到一致性快照视图。而由于 MVCC 的支持,这个过程中数据是可以正常更新的。
为什么还需要 FTWRL 呢?
一致性读是好,但前提是引擎要支持这个隔离级别。比如,对于 MyISAM 这种不支持事务的引擎,如果备份过程中有更新,总是只能取到最新的数据,那么就破坏了备份的一致性。这时,我们就需要使用FTWRL 命令了。
所以,single-transaction 方法只适用于所有的表使用事务引擎的库。如果有的表使用了不支持事务的引擎,那么备份就只能通过 FTWRL 方法。这往往是 DBA 要求业务开发人员使用 InnoDB 替代 MyISAM 的原因之一。
全局锁两种方法
一、FLUSH TABLES WRITE READ LOCK
二、set global readonly=true
既然要全库只读,为什么不使用 set global readonly=true 的方式呢?确实 readonly 方式也可以让全库进入只读状态,但我还是会建议你用 FTWRL 方式,主要有几个原因:
- 在有些系统中,readonly 的值会被用来做其他逻辑,比如用来判断一个库是主库还是备库。因此,修改 global 变量的方式影响面更大,我不建议你使用。
- 在异常处理机制上有差异。如果执行FTWRL 命令之后由于客户端发生异常断开,那么 MySQL 会自动释放这个全局锁,整个库回到可以正常更新的状态。而将整个库设置为 readonly 之后,如果客户端发生异常,则数据库就会一直保持 readonly 状态,这样会导致整个库长时间处于不可写状态,风险较高。
- readonly 对super用户权限无效
注 :业务的更新不只是增删改数据(DML),还有可能是加字段等修改表结构的操作(DDL)。不论是哪种方法,一个库被全局锁上以后,你要对里面任何一个表做加字段操作,都是会被锁住的。
即使没有被全局锁住,加字段也不是就能一帆风顺的,还有表级锁了
页面锁:
用于引擎 BDB。

表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录,可以设置记录值。
详情:页级锁是MySQL中比较独特的一种锁定级别,页级锁定的特点是锁定颗粒度介于行级锁定与表级锁之间,所以获取锁定所需要的资源开销,以及所能提供的并发处理能力也同样是介于上面二者之间。
另外,页级锁定和行级锁定一样,会发生死锁。
表级锁:
MySQL里面表级别的锁有两种:一种是表锁,一种是元数据锁(meta data lock,MDL)。
我们在编辑表,或者执行修改表的事情了语句的时候,一般都会给表加上表锁,可以避免一些不同步的事情出现,表锁分为两种,一种是读锁,一种是写锁。
表锁偏读,行锁偏写

特点:偏向MyISAM存储引擎,开销小,加锁快;无死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
#手动给表加上这两种锁,语句是:
lock table 表名 read(write);
lock tbale 表名字 read(write),表名字2read(write);
#加表锁
lock table mylock read,book write
#释放所有表的锁:
unlock tables;
#查看加锁的表:
show open tables;
表锁
lock tables 表名 read; #该表可以读,不能ddl 和 dml 中增删改,只能读取表数据
lock tables 表名 read; # 既不能读,也不能写
表锁的语法是 lock tables … read/write。与 FTWRL 类似,可以用 unlock tables 主动释放锁,也可以在客户端断开的时候自动释放。需要注意,lock tables 语法除了会限制别的线程的读写外,也限定了本线程接下来的操作对象。
举个例子, 如果在某个线程 A 中执行 lock tables t1 read, t2 write; 这个语句,则其他线程写 t1、读写 t2 的语句都会被阻塞。同时,线程 A 在执行 unlock tables 之前,也只能执行读 t1、读写 t2 的操作。连写 t1 都不允许,自然也不能访问其他表。
在还没有出现更细粒度的锁的时候,表锁是最常用的处理并发的方式。而对于 InnoDB 这种支持行锁的引擎,一般不使用 lock tables 命令来控制并发,毕竟锁住整个表的影响面还是太大
MDL 锁
另一类表级的锁是 MDL(metadata lock)。MDL 不需要显式使用,在访问一个表的时候会被自动加上。MDL 的作用是,保证读写的正确性。你可以想象一下,如果一个查询正在遍历一个表中的数据,而执行期间另一个线程对这个表结构做变更,删了一列,那么查询线程拿到的结果跟表结构对不上,肯定是不行的。
因此,在 MySQL 5.5 版本中引入了 MDL,当对一个表做增删改查操作的时候,加 MDL读锁;当要对表做结构变更操作的时候,加 MDL 写锁
读锁之间不互斥,因此你可以有多个线程同时对一张表增删改查。
读写锁之间、写锁之间是互斥的,用来保证变更表结构操作的安全性。因此,如果有两个线程要同时给一个表加字段,其中一个要等另一个执行完才能开始执行。
虽然 MDL 锁是系统默认会加的,但却是你不能忽略的一个机制。
比如下面这个例子,我经常看到有人掉到这个坑里:给一个小表加个字段,导致整个库挂了。
肯定知道,给一个表加字段,或者修改字段,或者加索引,需要扫描全表的数据。在对大表操作的时候,你肯定会特别小心,以免对线上服务造成影响。而实际上,即使是小表,操作不慎也会出问题。我们来看一下下面的操作序列,假设表 t 是一个小表。

注:表t 是 innodb 表,mysql版本是5.7.24 自动提交开启
1. sessionA:
begin;
select * from t limit 1;
2. sessionB:
select * from t limit 1;
3. sessionC:
alter table t add f int;
#会mdl锁住
4. sessionD:
select * from t limit 1;
show full processlist 查看mdl 锁详情

我们可以看到 session A 先启动,这时候会对表 t 加一个 MDL 读锁。由于 session B 需要的也是 MDL 读锁,因此可以正常执行。
之后 session C 会被 blocked,是因为 session A 的 MDL 读锁还没有释放,而 sessionC 需要MDL 写锁,因此只能被阻塞。
如果只有 session C 自己被阻塞还没什么关系,但是之后所有要在表 t 上新申请 MDL 读锁的请求也会被 session C 阻塞。前面说了,所有对表的增删改查操作都需要先申请MDL 读锁,就都被锁住,等于这个表现在完全不可读写了。
如果某个表上的查询语句频繁,而且客户端有重试机制,也就是说超时后会再起一个新session 再请求的话,这个库的线程很快就会爆满。
事务中的 MDL 锁,在语句执行开始时申请,但是语句结束后并不会马上释放,而会等到整个事务提交后再释放。
注 : 一般行锁都有锁超时时间。但是MDL锁没有超时时间的限制,只要事务没有提交就会一直锁注。
怎么解决了这个MDL锁
提交或者回滚这个事务。所以要找到这个事务
怎么找到这个事务, 通过information_schema.innodb_trx 查看事务的执行时间
# 查看事务超过60s的事务
mysql> select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60\G;
trx_started 表示什么时候执行的这个事务
#查看系统当前时间
mysql> select now();
事务开始时间和系统现在时间,一看事务执行了这么久。
查看这个线程id

怎么处理了这个长事务的线程id了
首先看show full processlist; 中host 哪个字段 ,到底是谁连接了数据库。例:我上面是localhost环境,进去commit或者/rollback ,哪如果不是localhost 环境了,是程序连接了这时候就要kill掉了
如何安全地给小表加字段
首先我们要解决长事务,事务不提交,就会一直占着 MDL 锁。在 MySQL 的information_schema 库的 innodb_trx 表中,你可以查到当前执行中的事务。如果你要做 DDL 变更的表刚好有长事务在执行,要考虑先暂停 DDL,或者 kill 掉这个长事务。这也是为什么需要在低峰期做ddl 变更,当然也要考虑具体做什么ddl,参考官方的online ddl。
online ddl 过程
1.拿MDL写锁
2.降级成MDL读锁
3.真正做DDL
4.升级成MDL写锁
5.释放MDL锁
1、2、4、5如果没有锁冲突,执行时间非常短。
第3步占用了DDL绝大部分时间,这期间这个个表可以正常读写数据,
是因此称为”online”
行级锁:
MySQL 的行锁是在引擎层由各个引擎自己实现的。但并不是所有的引擎都支持行锁,比如 MyISAM 引擎就不支持行锁。不支持行锁意味着并发控制只能使用表锁,对于这种引擎的表,同一张表上任何时刻只能有一个更新在执行,这就会影响到业务并发度。InnoDB 是支持行锁的,这也是 MyISAM 被 InnoDB 替代的重要原因之一。 行锁支持事务。
表锁偏读,行锁偏写

InnoDB 中的行锁的实现依赖于索引,一旦某个加锁操作没有使用到索引,那么该锁就会退化为表锁。
行锁就是针对数据表中行记录的锁, 这很好理解,比如事务 A 更新了一行,而这时候事务 B 也要更新同一行,则必须等事务 A 的操作完成后才能进行更新
行为:
1、当我们对一行进行更新但是不提交的时候,其他进程也对该行进行更新则需要进行等待,这就是行锁。
2、如果我们对一行进行更新,其他进程更新别的行是不会受影响的。
如何减少行锁持有时间
当然,数据库中还有一些没那么一目了然的概念和设计,这些概念如果理解和使用不当,容易导致程序出现非预期行为,比如两阶段锁。
我先给你举个例子。在下面的操作序列中,事务 B 的 update 语句执行时会是什么现象呢?假设字段 id 是表 t 的主键。

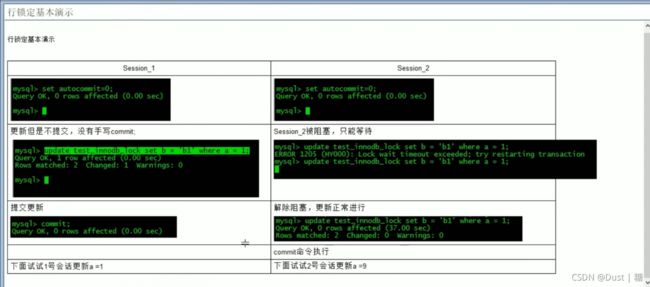

这个问题的结论取决于事务 A 在执行完两条 update 语句后,持有哪些锁,以及在什么时候释放。你可以验证一下:实际上事务 B 的 update 语句会被阻塞,直到事务 A 执行 commit 之后,事务 B 才能继续执行。
知道了这个答案,你一定知道了事务 A 持有的两个记录的行锁,都是在 commit 的时候才释放的。
也就是说,在 InnoDB 事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
知道了这个设定,对我们使用事务有什么帮助呢?那就是,如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放。
举个例子 :
假设你负责实现一个电影票在线交易业务,顾客 A 要在影院 B 购买电影票。我们简化一点,这个业务需要涉及到以下操作:
1.从顾客 A 账户余额中扣除电影票价;
2.给影院 B 的账户余额增加这张电影票价;
3.记录一条交易日志。
也就是说,要完成这个交易,我们需要 update 两条记录,并 insert 一条记录。当然,为了保证交易的原子性,我们要把这三个操作放在一个事务中。那么,你会怎样安排这三个语句在事务中的顺序呢?
试想如果同时有另外一个顾客 C 要在影院 B 买票,那么这两个事务冲突的部分就是语句 2 了。因为它们要更新同一个影院账户的余额,需要修改同一行数据。
根据两阶段锁协议,不论你怎样安排语句顺序,所有的操作需要的行锁都是在事务提交的时候才释放的。所以,如果你把语句 2 安排在最后,比如按照 3、1、2 这样的顺序,那么影院账户余额这一行的锁时间就最少。这就最大程度地减少了事务之间的锁等待,提升了并发度。
好了,现在由于你的正确设计,影院余额这一行的行锁在一个事务中不会停留很长时间。但是,这并没有完全解决你的困扰。
如果这个影院做活动,可以低价预售一年内所有的电影票,而且这个活动只做一天。于是在活动时间开始的时候,你的 MySQL 就挂了。你登上服务器一看,CPU 消耗接近 100%,但整个数据库每秒就执行不到 100 个事务。
这是什么原因呢?这里,我就要说到死锁和死锁检测了。
间隙锁:
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁; 对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)” ,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。
因为Query执行过程中通过过范围查找的话,他会锁定整个范围内所有的索引键值,即使这个键值并不存在。
间隙锁有一个比较致命的弱点,就是当锁定一个范围键值之后,即使某些不存在的键值也会被无辜的锁定,而造成在锁定的时候无法插入锁定键值范围内的任何数据。在某些场景下这可能会对性能造成很大的危害



优化建议:
- 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁。
- 合理设计索引,尽量缩小锁的范围
- 尽可能较少检索条件,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度
- 尽可能低级别事务隔离
说明:
- 行锁虽好,但是事务不能太大 太多
- 可以通过参数开启死锁检测
死锁:
死锁是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去.此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等的进程称为死锁进程.
死锁产生的四个必要条件
-
互斥条件:指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放
-
请求和保持条件:指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放
-
不剥夺条件:指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放
-
环路等待条件:指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
如何处理死锁
- 共享锁(S)
由读操作创建的锁,防止在读取数据的过程中,其它事务对数据进行更新;其它事务可以并发读取数据。共享锁可以加在表、页、索引键或者数据行上。在SQL SERVER默认隔离级别下数据读取完毕后就会释放共享锁,但可以通过锁提示或设置更高的事务隔离级别改变共享锁的释放时间。
- 独占锁(X)
对资源独占的锁,一个进程独占地锁定了请求的数据源,那么别的进程无法在此数据源上获得任何类型的锁。独占锁一致持有到事务结束。
- 更新锁(U)
更新锁实际上并不是一种独立的锁,而是共享锁与独占锁的混合。当SQL SERVER执行数据修改操作却首先需要搜索表以找到需要修改的资源时,会获得更新锁。
更新锁与共享锁兼容,但只有一个进程可以获取当前数据源上的更新锁,
其它进程无法获取该资源的更新锁或独占锁,更新锁的作用就好像一个序列化阀门(serialization gate),将后续申请独占锁的请求压入队列中。持有更新锁的进程能够将其转换成该资源上的独占锁。更新锁不足以用于更新数据—实际的数据修改仍需要用到独占锁。对于独占锁的序列化访问可以避免转换死锁的发生,更新锁会保留到事务结束或者当它们转换成独占锁时为止。
- 意向锁(IX,IU,IS)
意向锁并不是独立的锁定模式,而是一种指出哪些资源已经被锁定的机制。
如果一个表页上存在独占锁,那么另一个进程就无法获得该表上的共享表锁,这种层次关系是用意向锁来实现的。进程要获得独占页锁、更新页锁或意向独占页锁,首先必须获得该表上的意向独占锁。同理,进程要获得共享行锁,必须首先获得该表的意向共享锁,以防止别的进程获得独占表。
- 特殊锁模式(Sch_s,Sch_m,BU)
SQL SERVER提供3种额外的锁模式:架构稳定锁、架构修改锁、大容量更新锁。
- 转换锁(SIX,SIU,UIX)
转换锁不会由SQL SERVER 直接请求,而是从一种模式转换到另一种模式所造成的。SQL SERVER 2008支持3种类型的转换锁:SIX、SIU、UIX.其中最常见的是SIX锁,如果事务持有一个资源上的共享锁(S),然后又需要一个IX锁,此时就会出现SIX。
- 键范围锁
键范围锁是在可序列化隔离级别中锁定一定范围内数据的锁。保证在查询数据的键范围内不允许插入数据。
死锁和死锁检测:
当并发系统中不同线程出现循环资源依赖,涉及的线程都在等待别的线程释放资源时,就会导致这几个线程都进入无限等待的状态,称为死锁。这里我用数据库中的行锁举个例子。

这时候,事务 A 在等待事务 B 释放 id=2 的行锁,而事务 B 在等待事务 A 释放 id=1 的行锁。 事务 A 和事务 B 在互相等待对方的资源释放,就是进入了死锁状态。当出现死锁以后,有两种策略:
一种策略是,直接进入等待,直到超时。这个超时时间可以通过参数 innodb_lock_wait_timeout来设置。
另一种策略是,发起死锁检测,发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。将参数innodb_deadlock_detect 设置为 on,表示开启这个逻辑。
在 InnoDB 中,innodb_lock_wait_timeout 的默认值是 50s,意味着如果采用第一个策略,当出现死锁以后,第一个被锁住的线程要过 50s 才会超时退出,然后其他线程才有可能继续执行。对于在线服务来说,这个等待时间往往是无法接受的。
但是,我们又不可能直接把这个时间设置成一个很小的值,比如 1s。这样当出现死锁的时候,确实很快就可以解开,但如果不是死锁,而是简单的锁等待呢?所以,超时时间设置太短的话,会出现很多误伤。
所以,正常情况下我们还是要采用第二种策略,即:主动死锁检测,而且 innodb_deadlock_detect 的默认值本身就是 on。主动死锁检测在发生死锁的时候,是能够快速发现并进行处理的,但是它也是有额外负担的。
你可以想象一下这个过程:每当一个事务被锁的时候,就要看看它所依赖的线程有没有被别人锁住,如此循环,最后判断是否出现了循环等待,也就是死锁。
那如果是我们上面说到的所有事务都要更新同一行的场景呢?
每个新来的被堵住的线程,都要判断会不会由于自己的加入导致了死锁,这是一个时间复杂度是 O(n) 的操作。假设有 1000 个并发线程要同时更新同一行,那么死锁检测操作就是 100 万这个量级的。虽然最终检测的结果是没有死锁,但是这期间要消耗大量的 CPU 资源。因此,你就会看到 CPU 利用率很高,但是每秒却执行不了几个事务。
根据上面的分析,我们来讨论一下,怎么解决由这种热点行更新导致的性能问题呢?问题的症结在于,死锁检测要耗费大量的 CPU 资源。
一种头痛医头的方法,就是如果你能确保这个业务一定不会出现死锁,可以临时把死锁检测关掉。但是这种操作本身带有一定的风险,因为业务设计的时候一般不会把死锁当做一个严重错误,毕竟出现死锁了,就回滚,然后通过业务重试一般就没问题了,这是业务无损的。而关掉死锁检测意味着可能会出现大量的超时,这是业务有损的。
另一个思路是控制并发度。根据上面的分析,你会发现如果并发能够控制住,比如同一行同时最多只有 10 个线程在更新,那么死锁检测的成本很低,就不会出现这个问题。一个直接的想法就是,在客户端做并发控制。但是,你会很快发现这个方法不太可行,因为客户端很多。我见过一个应用,有 600 个客户端,这样即使每个客户端控制到只有 5 个并发线程,汇总到数据库服务端以后,峰值并发数也可能要达到 3000。
因此,这个并发控制要做在数据库服务端。如果你有中间件,可以考虑在中间件实现;如果你的团队有能修改 MySQL 源码的人,也可以做在 MySQL 里面。基本思路就是,对于相同行的更新,在进入引擎之前排队。这样在 InnoDB 内部就不会有大量的死锁检测工作了。
可能你会问,如果团队里暂时没有数据库方面的专家,不能实现这样的方案,能不能从设计上优化这个问题呢?你可以考虑通过将一行改成逻辑上的多行来减少锁冲突。还是以影院账户为例,可以考虑放在多条记录上,比如 10 个记录,影院的账户总额等于这 10 个记录的值的总和。这样每次要给影院账户加金额的时候,随机选其中一条记录来加。这样每次冲突概率变成原来的 1/10,可以减少锁等待个数,也就减少了死锁检测的 CPU 消耗。
这个方案看上去是无损的,但其实这类方案需要根据业务逻辑做详细设计。如果账户余额可能会减少,比如退票逻辑,那么这时候就需要考虑当一部分行记录变成 0 的时候,代码要有特殊处理。
避免死锁
阻止死锁的途径就是避免满足死锁条件的情况发生,为此我们在开发的过程中需要遵循如下原则:
-
不同程序并发存取多个表时,尽量约定以相同的顺序访问表。
-
同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
-
对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
-
尽量避免并发的执行涉及到修改数据的语句。
-
要求每一个事务一次就将所有要使用到的数据全部加锁,否则就不允许执行。
-
预先规定一个加锁顺序,所有的事务都必须按照这个顺序对数据执行封锁。如不同的过程在事务内部对对象的更新执行顺序应尽量保证一致。
-
每个事务的执行时间不可太长,对程序段的事务可考虑将其分割为几个事务。在事务中不要求输入,应该在事务之前得到输入,然后快速执行事务。
-
使用尽可能低的隔离级别。
-
数据存储空间离散法。该方法是指采用各种手段,将逻辑上在一个表中的数据分散的若干离散的空间上去,以便改善对表的访问性能。主要通过将大表按行或者列分解为若干小表,或者按照不同的用户群两种方法实现。
-
编写应用程序,让进程持有锁的时间尽可能短,这样其它进程就不必花太长的时间等待锁被释放。
插入意向锁:
Innodb中有插入意向锁,专门针对insert,如果插入前,该间隙已经由Gap锁,那么insert会申请插入意向锁,那么这个插入意向锁的作用是:
-
为了唤起等待。因为该间隙已经有锁,插入时必须阻塞。插入意向锁的作用具有阻塞功能。
-
插入意向锁是一种特殊的间隙锁,既然是一种间隙锁,为什么不直接使用间隙锁?
- 间隙锁之间不互斥,不能够阻塞即唤起等待,会造成幻读。
-
为什么不使用记录锁或next-key锁?
- 申请了记录锁或next-key锁,next-key锁之间可能互斥,即影响insert的性能。
自增锁:
如果存在自增字段,MySQL会维护一个自增锁,和自增锁相关的一个参数为(5.1.22版本之后加入)
innodb_autoinc_lock_mode:可以设定3个值,0,1,2
0:traditonal (每次都会产生表锁
1:consecutive (会产生一个轻量锁,simple insert会获得批量的锁,保证连续插入)
2:interleaved (不会锁表,来一个处理一个,并发最高)
ps:这个参数值控制InnoDB引擎的设置,所有Myisam均为traditonal,每次均会进行表锁。但是Innodb会视参数不通二产生不通的锁。目前MySQL默认的配置为1。
自增配置
通过如下建表语句就可以完成自增的配置 :
CREATE TABLE `test_inc` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
修改自增大小
通过如下sql可以自动生成数字:
insert into test_inc values();
当增加3行后表中数据如下:

CREATE TABLE `test_inc` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
使用 alter table test_inc auto_increment=10;将自增修改成10后再次插入的数据为10.

自增幅度
自增幅度通过auto_increment_offset和auto_increment_increment这2个参数进行控制
set global auto_increment_increment=2;
set global auto_increment_offset=2;
set session auto_increment_increment=2;
set session auto_increment_offset=2;
生成偶数的自增
set global auto_increment_increment=2;
set global auto_increment_offset=1;
set session auto_increment_increment=2;
set session auto_increment_offset=1;
生成奇数的自增
auto_increment_offset表示起始数字
auto_increment_increment表示调动幅度(即每次增加n个数字,2就代表每次+2)
获得最后一个数字
通过使用last_insert_id()函数可以获得最后一个插入的数字
select last_insert_id();
自增的过程
第一种,插入空值的时候
当innodb_autoinc_lock_mode=0时
1、申请AUTO_INC锁
2、得到当前的AUTO_INCREMENT值n,并加1
3、执行插入操作,并将n写入新增的对应字段中。
4、释放AUTO_INC锁。
第二种,插入已经有值的自增
1、插入第一条数据
2、如果失败流程结束
3、如果成功,申请AUTO_INC锁
4、调用set_max函数,修改AUTO_INCREMENT
5、语句结束,释放AUTO_INC锁
存在的问题
1、复制的问题
在innodb_autoinc_lock_mode=2的时候,由于是来一个分配一个,故当replication模式为SBR的时候,如果发生Bulk inserts会在分配的时候向其他insert分配,就会出现主从不一致的情况,但是如果改为RBR就不会出现这种情况。
也就是说在RBR模式下,innodb_autoinc_lock_mode=2是安全的,其他情况还是建议设置为1.
2、load data的问题
当使用load data语句的时候,就算innodb_autoinc_lock_mode=1也会退化回0,这是因为为了保证数据的一致性。首先要说一下load data的执行过程,在主库上load data为原始SQL语句,而在从库上会先将文件传输过去在tmp下生成临时问题,然后在执行load data语句。为了保证主库和从库的自增ID的一致性,binlog中会有set insert_ID命令,标明这个load语句的第一行的自增ID值,这样在表锁的情况下,就可以保证一致性了。
insert的补充说明
1.“INSERT-like”:
INSERT, INSERT … SELECT, REPLACE, REPLACE … SELECT, and LOAD DATA, INSERT … VALUES(),VALUES()
2.“Simple inserts”
就是通过分析insert语句可以确定插入数量的insert语句, INSERT, INSERT … VALUES(),VALUES()
3.“Bulk inserts”
就是通过分析insert语句不能确定插入数量的insert语句, INSERT … SELECT, REPLACE … SELECT, LOAD DATA
4.“Mixed-mode inserts”
INSERT INTO t1 (c1,c2) VALUES (1,’a'), (NULL,’b'), (5,’c'), (NULL,’d');
INSERT … ON DUPLICATE UPDATE
乐观锁&悲观锁:
乐观锁:
1、如果有人在你之前更新了,你的更新应当是被拒绝的,可以让用户重新操作。
2、实现:大多数基于数据版本(Version)记录机制实现
具体可通过给表加一个版本号或时间戳字段实现,当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。当我们提交更新的时候,判断当前版本信息与第一次取出来的版本值大小,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据,拒绝更新,让用户重新操作。
乐观锁不是数据库自带的,需要我们自己去实现。乐观锁是指操作数据库时(更新操作),想法很乐观,认为这次的操作不会导致冲突,在操作数据时,并不进行任何其他的特殊处理(也就是不加锁),而在进行更新后,再去判断是否有冲突了。
乐观锁,简单地说,就是从应用系统层面上做并发控制,去加锁。
实现乐观锁常见的方式:版本号version
实现方式,在数据表中增加版本号字段,每次对一条数据做更新之前,先查出该条数据的版本号,每次更新数据都会对版本号进行更新。在更新时,把之前查出的版本号跟库中数据的版本号进行比对,如果相同,则说明该条数据没有被修改过,执行更新。如果比对的结果是不一致的,则说明该条数据已经被其他人修改过了,则不更新,客户端进行相应的操作提醒。
使用版本号实现乐观锁,使用版本号时,可以在数据初始化时指定一个版本号,每次对数据的更新操作都对版本号执行+1操作。并判断当前版本号是不是该数据的最新的版本号。
eg:
下单操作包括3步骤:
1.查询出商品信息
select (status,status,version) from t_goods where id=#{id}
2.根据商品信息生成订单
3.修改商品status为2
update t_goods
set status=2,version=version+1
where id=#{id} and version=#{version};

注意第二个事务执行update时,第一个事务已经提交了,所以第二个事务能够读取到第一个事务修改的version。
下面这种极端的情况:

我们知道MySQL数据库引擎InnoDB,事务的隔离级别是Repeatable Read,因此是不会出现脏读、不可重复读。
在这种极端情况下,第二个事务的update由于不能读取第一个事务未提交的数据(第一个事务已经对这一条数据加了排他锁,第二个事务需要等待获取锁),第二个事务获取了排他锁后,会发现version已经发生了改变从而提交失败。
悲观锁:
悲观锁,简单地说,就是从数据库层面上做并发控制,去加锁。
悲观锁的实现方式有两种:共享锁(读锁)和排它锁(写锁)
1、排它锁,当事务在操作数据时把这部分数据进行锁定,直到操作完毕后再解锁,其他事务操作才可操作该部分数据。这将防止其他进程读取或修改表中的数据。
2、实现:大多数情况下依靠数据库的锁机制实现
一般使用 select …for update 对所选择的数据进行加锁处理,例如select * from account where name=”Max” for update, 这条sql 语句锁定了account 表中所有符合检索条件(name=”Max”)的记录。本次事务提交之前(事务提交时会释放事务过程中的锁),外界无法修改这些记录。
共享锁(读锁):
又称为读锁,顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
针对同一份数据,多个读操作可以同时进行而不会互相影响。

加锁方式:加共享锁的时候要先加上意向共享锁。
手动:select * from student where id =1 Lock IN SHARE MODE(lock in share mode);
释放锁:commit/rollback;
#加读锁(表级)
lock table mylock read;
1、我们加读锁的这个进程可以读加读锁的表,但是不能读其他的表。
2、加读锁的这个进程不能update加读锁的表。
3、其他进程可以读加读锁的表(因为是共享锁),也可以读其他表
4、其他进程update加读锁的表会一直处于等待锁的状态,直到锁被释放后才会update成功。

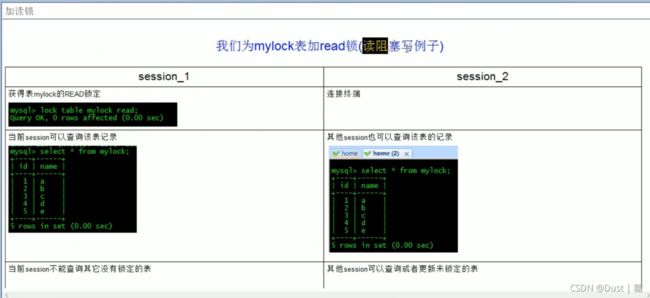


排它锁(写锁):
又称为写锁,排他锁不能与其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的锁(共享锁、排他锁),只有该获取了排他锁的事务是可以对数据行进行读取和修改。
当前写操作没有完成前,它会阻断其他写锁和读锁。

#加锁方式:加排他锁的时候要先加上意向排他锁。
自动:delete / update / insert 默认加上X锁
手动:select * form student where id=1 FOR UPDATE (for update);
释放锁:commit/rollback;
#加表锁(表级)
lock table book write;
1、加锁进程可以对加锁的表做任何操作(CURD)。
2、其他进程则不能查询加锁的表,需等待锁释放
共享锁和排他锁的区别:
-
排他锁不能与其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的锁(共享锁、排他锁),只有该获取了排他锁的事务是可以对数据行进行读取和修改
-
共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
总结:
读锁会阻塞写,但是不会堵塞读。而写锁则会把读和写都堵塞。(特别注意进程)
分析:
show status like 'table%';
输入上述命令,可得:

- Table_locks_immediate:产生表级锁定的次数,表示可以立即获取锁的查询次数,每立即获取锁值加1 。
- Table_locks_waited:出现表级锁定争用而发生等待的次数(不能立即获取锁的次数,每等待一次锁值加1),此值高则说明存在着较严重的表级锁争用情况。
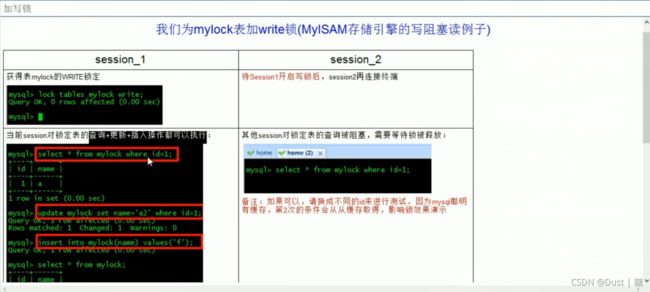
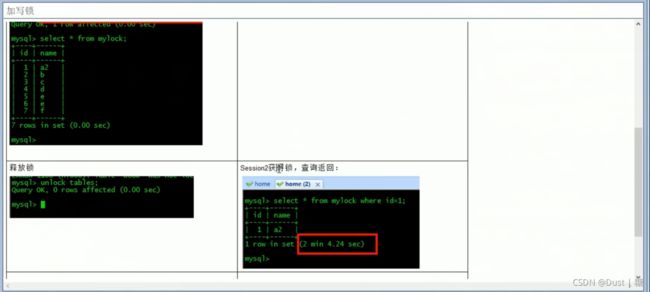
意向锁:
如果对一个结点加意向锁,则说明该结点的下层结点正在被加锁;对任一结点加锁时,必须先对它的上层结点加意向锁。意向锁是放置在资源层次结构的一个级别上的锁,以保护较低级别资源上的共享或排它锁。
-
表明“某个事务正在某些行持有了锁、或该事务准备去持有锁”
-
意向锁的存在是为了协调行锁和表锁的关系,支持多粒度(表锁与行锁)的锁并存,。
-
例子:事务A修改user表的记录r,会给记录r上一把行级的排他锁(X),同时会给user表上一把意向排他锁(IX),这时事务B要给user表上一个表级的排他锁就会被阻塞。意向锁通过这种方式实现了行锁和表锁共存且满足事务隔离性的要求。
意向锁是由数据引擎自己维护的,用户无法手动操作意向锁。
引进意向锁后,系统对某一数据对象加锁时不必逐个检查与下一级结点的封锁冲突了。例如,事务 T 要对关系 R 加 X 锁时,系统只要检查根结点数据库和 R 本身是否已加了不相容的锁(如发现已经加了 IX ,则与 X 冲突),而不再需要搜索和检查 R 中的每一个元组是否加了 X 锁或 S 锁。
为什么需要意向锁呢?
一个事务成功地给一张表加上表锁的前提是:没有其他任何事务已经锁定了这张表的任意一行数据。
意向锁的作用就是:提高加表锁的效率。直接看表中有没有意向排他锁和意向共享锁就行了,不用进行全表的扫描、检测了。
可以把意向锁当成一个标识(厕所里有人外面就亮灯)。

意向共享锁(IS锁):
Intention Shard Lock,简称IS锁
表示事务准备给数据行加入共享锁,也就是说一个数据行加共享锁前必须先取得该表的IS锁。
意向排他锁(IX锁):
Intention Exclusive Lock,简称IX锁
表示事务准备给数据行加入排他锁,说明事务在一个数据行加排他锁前必须先取得该表的IX锁。
区间的定义:

记录锁:
(Record Lock)
存在于包括主键索引在内的唯一索引中,锁定单条索引记录。

记录锁是锁住记录,锁住索引记录,而不是真正的数据记录
- 锁是非主键索引,会在索引记录上加锁后,在去主键索引上加锁
- 表上没有索引,会在隐藏的主键索引上加锁
- 如果要锁的列没有索引,进行全表记录加锁
锁定记录

间隙锁:
(Gap Lock)
间隙锁存在于非唯一索引中,锁定开区间范围内的一段间隔,它是基于临键锁实现的。
锁定范围


当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。
举例来说,假如emp表中只有101条记录,其empid的值分别是 1,2,…,100,101,下面的SQL:
Select * from emp where empid > 100 for update;
是一个范围条件的检索,InnoDB不仅会对符合条件的empid值为101的记录加锁,也会对empid大于101(这些记录并不存在)的“间隙”加锁。
InnoDB使用间隙锁的目的,一方面是为了防止幻读,以满足相关隔离级别的要求,对于上面的例子,要是不使用间隙锁,如果其它事务插入了empid大于100的任何记录,那么本事务如果再次执行上述语句,就会发生幻读;另外一方面,是为了满足其恢复和复制的需要。有关其恢复和复制对锁机制的影响,以及不同隔离级别下InnoDB使用间隙锁的情况,在后续的章节中会做进一步介绍。
很显然,在使用范围条件检索并锁定记录时,InnoDB这种加锁机制会阻塞符合条件范围内键值的并发插入,这往往会造成严重的锁等待。因此,在实际应用开发中,尤其是并发插入比较多的应用,我们要尽量优化业务逻辑,尽量使用相等条件来访问更新数据,避免使用范围条件。
还要特别说明的是,InnoDB除了通过范围条件加锁时使用间隙锁外,如果使用相等条件请求给一个不存在的记录加锁,InnoDB也会使用间隙锁!

临键锁:
(Next-key Lock)
临键锁存在于
非唯一索引中,该类型的每条记录的索引上都存在这种锁,它是一种特殊的间隙锁,锁定一段左开右闭的索引区间。

Next-Key 可以理解为一种特殊的间隙锁,也可以理解为一种特殊的算法。通过临建锁可以解决幻读的问题。 每个数据行上的非唯一索引列上都会存在一把临键锁,当某个事务持有该数据行的临键锁时,会锁住一段左开右闭区间的数据。需要强调的一点是,InnoDB 中行级锁是基于索引实现的,临键锁只与非唯一索引列有关,在唯一索引列(包括主键列)上不存在临键锁。
临键锁存在于非唯一索引中,该类型的每条记录的索引上都存在这种锁,它是一种特殊的间隙锁,锁定一段左开右闭的索引区间
假设有如下表:
MySql,InnoDB,Repeatable-Read:table(id PK, age KEY, name)
| id | age | name |
|---|---|---|
| 1 | 10 | Lee |
| 3 | 24 | Soraka |
| 5 | 32 | Zed |
| 7 | 45 | Talon |
该表中 age 列潜在的临键锁有:
(-∞, 10],
(10, 24],
(24, 32],
(32, 45],
(45, +∞],
在事务 A中执行如下命令:
-- 根据非唯一索引列 UPDATE 某条记录
UPDATE table SET name = Vladimir WHERE age = 24;
-- 或根据非唯一索引列 锁住某条记录
SELECT * FROM table WHERE age = 24 FOR UPDATE;
复制代码
不管执行了上述 SQL 中的哪一句,之后如果在事务 B中执行以下命令,则该命令会被阻塞:
INSERT INTO table VALUES(100, 26, 'Ezreal');
复制代码
很明显,事务 A 在对 age 为 24 的列进行 UPDATE 操作的同时,也获取了(24, 32]这个区间内的临键锁。
不仅如此,在执行以下 SQL 时,也会陷入阻塞等待:
INSERT INTO table VALUES(100, 30, 'Ezreal');
复制代码
那最终我们就可以得知,在根据非唯一索引 对记录行进行 UPDATE \ FOR UPDATE \ LOCK IN SHARE MODE 操作时,InnoDB 会获取该记录行的 临键锁 ,并同时获取该记录行下一个区间的间隙锁。
即事务 A在执行了上述的 SQL 后,最终被锁住的记录区间为 (10, 32)。
锁定范围加记录

SQL server锁模式:
| 缩写 | 锁模式 | 说明 |
|---|---|---|
| S | Shared | 允许其他进程读取但不能修改锁定的资源 |
| X | Exclusive | 防止别的进程读取或者修改锁定资源中的数据 |
| U | Update | 防止其它进程获取更新锁或独占锁;在搜索要修改的数据时使用 |
| IS | Intent shared | 表示该资源的一个组件被共享锁锁定了。只有在表或页级别才能获得这类锁 |
| IU | Intent update | 表示该资源的一个组件被更新锁锁定了。只有在表或页级别才能获得这类锁 |
| IX | Intent exclusive | 表示该资源的一个组件被独占锁锁定了。只有在表或页级别才能获得这类锁 |
| SIX | Shared with intent exclusive | 表示一个正持有共享锁的资源还有一个组件(一页或一行)被独占锁锁定了 |
| SIU | Shared with intent Update | 表示一个正持有共享锁的资源还有一个组件(一页或一行)被更新锁锁定了 |
| UIX | Update with intent exclusive | 表示一个正持有更新锁的资源还有一个组件(一页或一行)被独占锁锁定了 |
| Sch-S | Schema stability | 表示一个使用该表的查询正在被编译 |
| Sch-M | Schema modification | 表示表的结构正在被修改 |
| BU | Bulk Update | 在一个大容量复制操作将数据导入表中并且(手动或自动)应用了TABLOCK查询提示时使用 |
表没有索引,为什么会锁表:
一张表至少有一个索引,就是聚集索引。
- 有主键 主键就是聚集索引
- 带not null的字段,该字段就是聚集索引
- rowid隐藏的字段,它是聚集索引、
七、MySQL日志
日志的简介,做什么用的,怎么设置,怎么使用。
-
查询日志(log)
-
全局查询日志
-
错误日志(errorlog)
默认是关闭的,记录严重的警告和错误信息,每次启动和关闭的详细信息等。 -
慢查询日志(slow query log)
-
一般查询日志(general log)
-
中继日志(relay log)
数据文件:
- frm文件:存放表结构
- myd文件:存放表数据
- myi文件:存放表索引

MySQL日志文件系统的组成
a、错误日志:记录启动、运行或停止mysqld时出现的问题。
b、通用日志:记录建立的客户端连接和执行的语句。
d、二进制日志:记录所有更改数据的语句。还用于复制。
e、慢查询日志:记录所有执行时间超过long_query_time秒的所有查询或不使用索引的查询。
f、Innodb日志:innodb redo log
缺省情况下,所有日志创建于mysqld数据目录中。
可以通过刷新日志,来强制mysqld来关闭和重新打开日志文件(或者在某些情况下切换到一个新的日志)。
当你执行一个FLUSH LOGS语句或执行mysqladmin flush-logs或mysqladmin refresh时,则日志被老化。
对于存在MySQL复制的情形下,从复制服务器将维护更多日志文件,被称为接替日志。
WAL 的全称是 Write-Ahead Logging,它的关键点就是先写日志,再写磁盘,也就是先写小黑板,等不忙的时候再写账本。
发现的一篇绝好日志的博客:
https://blog.csdn.net/qq_39390545/article/details/115214802?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162685749116780255210878%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=162685749116780255210878&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_v2~rank_v29-2-115214802.pc_search_result_cache&utm_term=binlog&spm=1018.2226.3001.4187
crash-safe:
可以对照前面赊账记录的例子。只要赊账记录记在了小黑板上或写在了账本上,即使秀才突然被老邢抓走几天,回来后依然可以通过账本和小黑板上的数据明确赊账账目。就是维护数据的持久性。
本质上说,crash-safe 就是落盘处理,将数据存储到了磁盘上,断电重启也不会丢失。
事务日志
innodb事务日志包括redo log和undo log。
undo log指事务开始之前, 在操作任何数据之前,首先将需操作的数据备份到一个地方
redo log指事务中操作的任何数据,将最新的数据备份到一个地方
事务日志的目的:实例或者介质失败,事务日志文件就能派上用场。
日志分析工具
mysqldumpslow
在生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具mysqldumpslow
查看mysqldumpslow的帮助信息
mysqldumpslow --help


Show profile 是mysql 提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于sql 调优的测量。
默认情况下,参数处于关闭状态,并保存最近15次的运行结果。
Show Profile默认是关闭的,试用前需要开启:
#查看是否开启:
Show variables like 'profiling';
#设置开启:
set profiling = on;
#诊断sql ,
show profile cpu, block io for query 问题sql数字号码;
#语法:
Show profile type , block type for query 问题sql数字号码
#其中type:
ALL: 显示所有的开销信息
BLOCK IO : 显示块IO相关开销
CONTEXT SWITCHS: 上下文切换相关开销
CPU : 显示cpu 相关开销
IPC: 显示发送和接收相关开销
MEMORY: 显示内存相关开销
PAGE FAULTS:显示页面错误相关开销信息
SOURCE : 显示和Source_function ,Source_file,Source_line 相关的开销信息
SWAPS:显示交换次数相关的开销信息

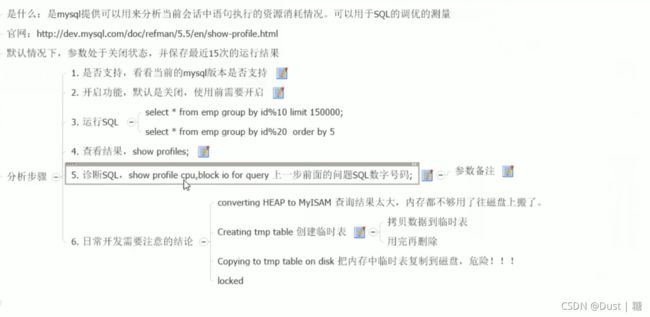
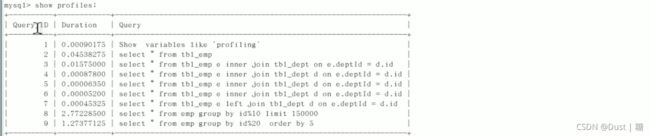
分析SQL,SQL运行步骤:

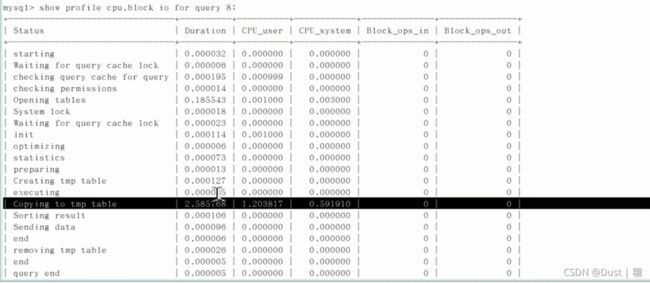

快照读和当前读
快照读:SQL读取的数据是快照版本,也就是历史版本,普通的SELECT就是快照读 innodb快照读,数据的读取将由 cache(原本数据) + undo(事务修改过的数据) 两部分组成
当前读:SQL读取的数据是最新版本。通过锁机制来保证读取的数据无法通过其他事务进行修改 UPDATE、DELETE、INSERT、SELECT … LOCK IN SHARE MODE、SELECT … FOR UPDATE都是 当前读
XA的概念
XA(分布式事务)规范主要定义了(全局)事务管理器(TM: Transaction Manager)和(局部)资源管理器(RM: Resource Manager)之间的接口。XA为了实现分布式事务,将事务的提交分成了两个阶段:也就是2PC (tow phase commit),XA协议就是通过将事务的提交分为两个阶段来实现分布式事务。
两阶段
1)prepare 阶段
事务管理器向所有涉及到的数据库服务器发出prepare"准备提交"请求,数据库收到请求后执行数据修改和日志记录等处理,处理完成后只是把事务的状态改成"可以提交",然后把结果返回给事务管理器。即:为prepare阶段,TM向RM发出prepare指令,RM进行操作,然后返回成功与否的信息给TM。
2)commit 阶段
事务管理器收到回应后进入第二阶段,如果在第一阶段内有任何一个数据库的操作发生了错误,或者事务管理器收不到某个数据库的回应,则认为事务失败,回撤所有数据库的事务。数据库服务器收不到第二阶段的确认提交请求,也会把"可以提交"的事务回撤。如果第一阶段中所有数据库都提交成功,那么事务管理器向数据库服务器发出"确认提交"请求,数据库服务器把事务的"可以提交"状态改为"提交完成"状态,然后返回应答。即:为事务提交或者回滚阶段,如果TM收到所有RM的成功消息,则TM向RM发出提交指令;不然则发出回滚指令。
外部与内部XA
MySQL中的XA实现分为:外部XA和内部XA。
前者是指我们通常意义上的分布式事务实现;后者是指单台MySQL服务器中,Server层作为TM(事务协调者,通常由binlog模块担当),而服务器中的多个数据库实例作为RM,而进行的一种分布式事务,也就是MySQL跨库事务;也就是一个事务涉及到同一个MySQL服务器中的两个innodb数据库(目前似乎只有innodb支持XA)。内部XA也可以用来保证redo和binlog的一致性问题。
binlog介绍
binlog,即
二进制日志(归档日志),它记录了数据库上的所有改变,并以二进制的形式保存在磁盘中;它可以用来查看数据库的变更历史、数据库增量备份和恢复、Mysql的复制(主从数据库的复制)。
二进制日志中,配置主从复制
binlog是记录所有数据库表结构变更(例如create、alter table…)以及表数据修改(insert、update、delete…)的二进制日志。
binlog不会记录SELECT和SHOW这类操作,因为这类操作对数据本身并没有修改,但你可以通过查询通用日志来查看MySQL执行过的所有语句。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
binlog三种格式:
binlog有三种格式:Statement、Row以及Mixed。
–基于SQL语句的复制(statement-based replication,SBR),
–基于行的复制(row-based replication,RBR),
–混合模式复制(mixed-based replication,MBR)。
Binlog常见格式
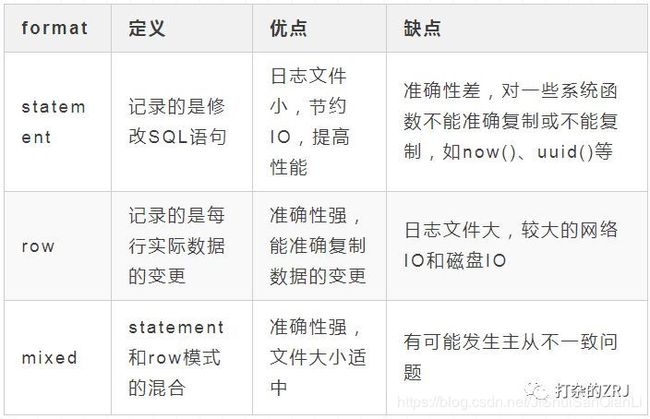
业内目前推荐使用的是row模式,准确性高,虽然说文件大,但是现在有SSD和万兆光纤网络,这些磁盘IO和网络IO都是可以接受的。
在innodb里其实又可以分为两部分,一部分在缓存中,一部分在磁盘上。这里业内有一个词叫做刷盘,就是指将缓存中的日志刷到磁盘上。跟刷盘有关的参数有两个个:sync_binlog和binlog_cache_size。这两个参数作用如下
binlog_cache_size: 二进制日志缓存部分的大小,默认值32k
sync_binlog=[N]: 表示每多少个事务写入缓冲,刷一次盘,默认值为0
注意两点:
(1)binlog_cache_size设过大,会造成内存浪费。binlog_cache_size设置过小,会频繁将缓冲日志写入临时文件。
(2)sync_binlog=0:表示刷新binlog时间点由操作系统自身来决定,操作系统自身会每隔一段时间就会刷新缓存数据到磁盘,这个性能最好。 sync_binlog=1,代表每次事务提交时就会刷新binlog到磁盘,对性能有一定的影响。 sync_binlog=N,代表每N个事务提交会进行一次binlog刷新。
另外,这里存在一个一致性问题,sync_binlog=N,数据库在操作系统宕机的时候,可能数据并没有同步到磁盘,于是再次重启数据库,会带来数据丢失问题。
mysql的binlog是多文件存储,定位一个LogEvent需要通过binlog filename + binlog position,进行定位。
Binlog日志的三种模式
Statement Level模式、 Row Level模式 、 Mixed模式(混合模式)
Statement Level模式:
每一条修改数据的sql都会记录到master的bin_log中,slave在复制的时候sql进程会解析成master端执行过的相同的sql在slave库上再次执行。
优点:statement level下的优点首先就是解决了row level下的缺点,不需要记录每一行的变化,较少bin-log日志量,节约IO,提高性能。因为它只需要记录在master上所执行的语句的细节,以及执行语句时候的上下文信息。
缺点:由于它是记录执行语句,所以,为了让这些语句在slave端也能正确执行,那么它还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,来保证所有语句在slave端能够得到和在master端相同的执行结果。由于mysql更新较快,使mysql的赋值遇到了不小的挑战,自然赋值的时候就会涉及到越复杂的内容,bug也就容易出现。在statement level下,目前就已经发现了不少情况会造成mysql的复制出现问题,主要是修改数据的时候使用了某些特定的函数或者功能的时候会出现。比如:sleep()函数在有些版本中就不能正确赋值,在存储过程中使用了last_insert_id()函数,可能会使slave和master上得到不一致的id等等。由于row level是基于每一行记录的裱花,所以不会出现类似的问题。
总结:
Statement level优点:
1、解决了row level的缺点,不需要记录每一行的变化。
2、日志量少,节约IO,从库应用日志块。
Statement level缺点:一些新功能同步可能会有障碍,比如函数、触发器等。
Row Level模式:
日志中会记录成每一行数据修改的形式,然后在slave端再对相同的数据进行修改。
5.1.5版本的MySQL才开始支持row level的复制,它不记录sql语句上下文相关信息,仅保存哪条记录被修改。
优点: binlog中可以不记录执行的sql语句的上下文相关的信息,仅需要记录那一条记录被修改成什么了。所以rowlevel的日志内容会非常清楚的记录下每一行数据修改的细节。而且不会出现某些特定情况下的存储过程,或function,以及trigger的调用和触发无法被正确复制的问题.
缺点:所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容。
ps:新版本的MySQL中对row level模式也被做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录,如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更。
Mixed模式(混合模式):
从5.1.8版本开始,MySQL提供了Mixed格式,实际上就是Statement与Row的结合。
在Mixed模式下,一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种。
binlog日志默认模式:
Server version: 5.6.17 Source distribution
mysql> show variables like "%binlog_format%";
+---------------+-----------+
| Variable_name | Value |
+---------------+-----------+
| binlog_format | STATEMENT |
+---------------+-----------+
1 row in set (0.00 sec)
方法一:在线修改立即生效
mysql> set global binlog_format='MIXED';
Query OK, 0 rows affected (0.00 sec)
退出mysql,查看当前mysql日志模式
mysql> show variables like "%binlog_format%";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | MIXED |
+---------------+-------+
1 row in set (0.00 sec)
方法二:在配置文件中参数如下:
[mysqld]
log-bin=/var/lib/mysql/mysql-bin
#binlog_format="ROW"
binlog_format="MIXED" #开启MIXED模式
#binlog_format="STATEMENT"
修改后重启mysql服务日志模式:
mysql> show variables like "%binlog_format%";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | MIXED |
+---------------+-------+
1 row in set (0.00 sec)
三、在日志模式当前为row的模式下,记录日志的形式内容。
mysql> show variables like "%binlog_format%";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
1 row in set (0.00 sec)
[root@i-3vsptbun mysql]# mysqlbinlog --base64-output=decode-rows -v mysql-bin.000011
小结:执行sql部分的sql显示为base64编码格式
#171126 17:35:53 server id 1 end_log_pos 458 Table_map: `boy`.`tomcat1` mapped to number 15
#171126 17:35:53 server id 1 end_log_pos 571 Delete_rows: table id 15 flags: STMT_END_F
### DELETE FROM `boy`.`tomcat1`
### WHERE
### @1=11
### @2='huang1'
### DELETE FROM `boy`.`tomcat1`
### WHERE
### @1=2
### @2='huang2'
### DELETE FROM `boy`.`tomcat1`
### WHERE
### @1=3
### @2='huang3'
### @2='zhang7'
# at 571
# End of log file
ROLLBACK /* added by mysqlbinlog */;
/*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/;
操作binlog
(1)查看binlog_format
show variables like 'binlog_format'
或者通过查看配置文件:
whereis my.ini
cat /etc/my.cnf

(2)修改binlog_format
直接修改
set globle binlog_format='MIXED'
或者修改配置文件
vi /etc/my.cnf
binlog开启与查看、删除
开启mysql的binlog
vi /etc/my.cnf
log-bin=mysql-bin #添加这一行就ok
binlog-format=ROW #选择row模式
server_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复
(1)查看是否开启binlog
show variables like 'log_bin'
如果binlog没有开启,可以通过set sql_log_bin=1命令来启用;如果想停用binlog,可以使用set sql_log_bin=0。
(2)获取binlog文件列表
show binary logs
(3)查看当前正在写入的binlog文件
show master status
(4) 查看master上的binlog
show master logs
(5)只查看第一个binlog文件的内容
show binlog events
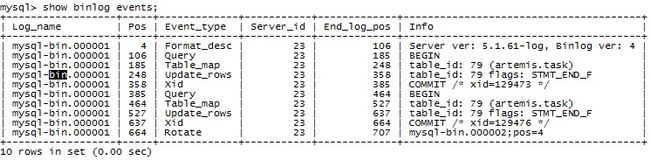
(6)查看指定binlog文件的内容
show binlog events in 'mysql-bin.000002'
(7) 删除binlog
设置binlog的过期时间
手动删除binlog
reset master;//删除master的binlog
reset slave; //删除slave的中继日志
purge master logs before '2012-03-30 17:20:00'; //删除指定日期以前的日志索引中binlog日志文件
purge master logs to 'mysql-bin.000002'; //删除指定日志文件的日志索引中binlog日志文件
binlog和事务日志的先后顺序及group commit
为了提高性能,通常会将有关联性的多个数据修改操作放在一个事务中,这样可以避免对每个修改操作都执行完整的持久化操作。这种方式,可以看作是人为的组提交(group commit)。
除了将多个操作组合在一个事务中,记录binlog的操作也可以按组的思想进行优化:将多个事务涉及到的binlog一次性flush,而不是每次flush一个binlog。
事务在提交的时候不仅会记录事务日志,还会记录二进制日志,但是它们谁先记录呢?二进制日志是MySQL的上层日志,先于存储引擎的事务日志被写入。
在MySQL5.6以前,当事务提交(即发出commit指令)后,MySQL接收到该信号进入commit prepare阶段;进入prepare阶段后,立即写内存中的二进制日志,写完内存中的二进制日志后就相当于确定了commit操作;然后开始写内存中的事务日志;最后将二进制日志和事务日志刷盘,它们如何刷盘,分别由变量 sync_binlog 和 innodb_flush_log_at_trx_commit 控制。
但因为要保证二进制日志和事务日志的一致性,在提交后的prepare阶段会启用一个prepare_commit_mutex锁来保证它们的顺序性和一致性。但这样会导致开启二进制日志后group commmit失效,特别是在主从复制结构中,几乎都会开启二进制日志。
在MySQL5.6中进行了改进。提交事务时,在存储引擎层的上一层结构中会将事务按序放入一个队列,队列中的第一个事务称为leader,其他事务称为follower,leader控制着follower的行为。虽然顺序还是一样先刷二进制,再刷事务日志,但是机制完全改变了:删除了原来的prepare_commit_mutex行为,也能保证即使开启了二进制日志,group commit也是有效的。
MySQL5.6中分为3个步骤:flush阶段、sync阶段、commit阶段。
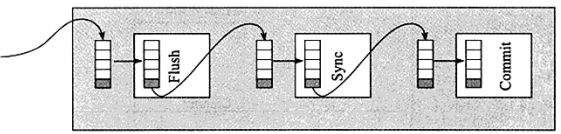
- flush阶段:向内存中写入每个事务的二进制日志。
- sync阶段:将内存中的二进制日志刷盘。若队列中有多个事务,那么仅一次fsync操作就完成了二进制日志的刷盘操作。这在MySQL5.6中称为BLGC(binary log group commit)。
- commit阶段:leader根据顺序调用存储引擎层事务的提交,由于innodb本就支持group commit,所以解决了因为锁 prepare_commit_mutex 而导致的group commit失效问题。
在flush阶段写入二进制日志到内存中,但是不是写完就进入sync阶段的,而是要等待一定的时间,多积累几个事务的binlog一起进入sync阶段,等待时间由变量 binlog_max_flush_queue_time 决定,默认值为0表示不等待直接进入sync,设置该变量为一个大于0的值的好处是group中的事务多了,性能会好一些,但是这样会导致事务的响应时间变慢,所以建议不要修改该变量的值,除非事务量非常多并且不断的在写入和更新。
进入到sync阶段,会将binlog从内存中刷入到磁盘,刷入的数量和单独的二进制日志刷盘一样,由变量 sync_binlog 控制。
当有一组事务在进行commit阶段时,其他新事务可以进行flush阶段,它们本就不会相互阻塞,所以group commit会不断生效。当然,group commit的性能和队列中的事务数量有关,如果每次队列中只有1个事务,那么group commit和单独的commit没什么区别,当队列中事务越来越多时,即提交事务越多越快时,group commit的效果越明显。
二进制日志处理事务和非事务性语句的区别
在事务性语句(update)执行过程中,服务器将会进行额外的处理,在服务器执行时多个事务是并行执行的,为了把他们的记录在一起,需要引入事务日志的概念。在事务完成被提交的时候一同刷新到二进制日志。对于非事务性语句(insert,delete)的处理。遵循以下3条规则:
1)如果非事务性语句被标记为事务性,那么将被写入重做日志。
2)如果没有标记为事务性语句,而且重做日志中没有,那么直接写入二进制日志。
3)如果没有标记为事务性的,但是重做日志中有,那么写入重做日志。
注意如果在一个事务中有非事务性语句,那么将会利用规则2,优先将该影响非事务表语句直接写入二进制日志。
事务日志与二进制日志的一致性问题
我们MySQL为了兼容其它非事务引擎的复制,在server层面引入了 binlog, 它可以记录所有引擎中的修改操作,因而可以对所有的引擎使用复制功能; 然而这种情况会导致redo log与binlog的一致性问题;MySQL通过内部XA机制解决这种一致性的问题。
第一阶段:
InnoDB prepare, write/sync redo log;binlog不作任何操作;
第二阶段:包含两步,
1> write/sync Binlog;
2> InnoDB commit (commit in memory);
当然在5.6之后引入了组提交的概念,可以在IO性能上进行一些提升,
但总体的执行顺序不会改变。
当第二阶段的第1步执行完成之后,binlog已经写入,MySQL会认为事务已经提交并持久化了(在这一步binlog就已经ready并且可以发送给订阅者了)。在这个时刻,就算数据库发生了崩溃,那么重启MySQL之后依然能正确恢复该事务。在这一步之前包含这一步任何操作的失败都会引起事务的rollback。
第二阶段的第2步大部分都是内存操作 (注意这里的InnoDB commit不是事务的commit) ,比如释放锁,释放mvcc相关的read view等等。MySQL认为这一步不会发生任何错误,一旦发生了错误那就是数据库的崩溃,MySQL自身无法处理。这个阶段没有任何导致事务rollback的逻辑。在程序运行层面,只有这一步完成之后,事务导致变更才能通过API或者客户端查询体现出来。
下面的一张图,说明了MySQL在何时会将binlog发送给订阅者。
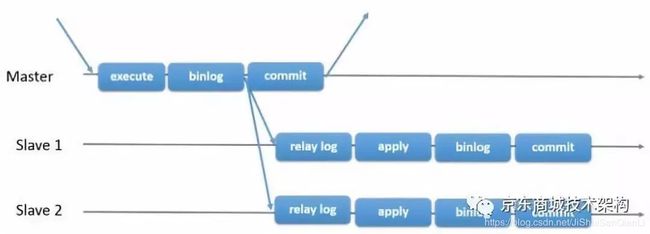
MySQL会在binlog落盘之后会立即将新增的binlog发送给订阅者以尽可能的降低主从延迟。
table_map event & write_rows event
这两个event是在binlog_format=row的时候使用,设置binlog_format=row,然后创建一个测试表
CREATE TABLE `trow` (
`i` int(11) NOT NULL,
`c` varchar(10) DEFAULT NULL,
PRIMARY KEY (`i`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1`
执行语句INSERT INTO trow VALUES(1, NULL), (2, 'a'),
这个语句会产生一个query event,
一个table_map event、
一个write_rows event
以及一个xid event。
Undo + Redo事务的简化过程
假设有A、B两个数据,值分别为1,2,开始一个事务,事务的操作内容为:把1修改为3,2修改为4,那么实际的记录如下(简化):
A.事务开始.
B.记录A=1到undo log.
C.修改A=3.
D.记录A=3到redo log.
E.记录B=2到undo log.
F.修改B=4.
G.记录B=4到redo log.
H.将redo log写入磁盘。
I.事务提交
binlog的扩展
当停止或重启服务器时,服务器会把日志文件记入下一个日志文件,Mysql会在重启时生成一个新的日志文件,文件序号递增;此外,如果日志文件超过max_binlog_size(默认值1G)系统变量配置的上限时,也会生成新的日志文件(在这里需要注意的是,如果你正使用大的事务,二进制日志还会超过max_binlog_size,不会生成新的日志文件,事务全写入一个二进制日志中,这种情况主要是为了保证事务的完整性);日志被刷新时,新生成一个日志文件。
如:
flush logs
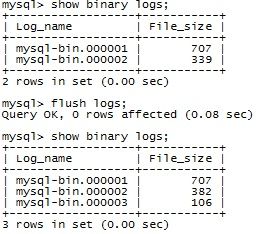
=========================================================
接下一章:MySQL这一章就够了(二)