tensorflow 歌曲题材分类
librosa音频处理
Librosa是一个用于音频、音乐分析、处理的python工具包,一些常见的时频处理、特征提取、绘制声音图形等功能应有尽有,功能十分强大.
加载音频
import librosa
x , sr = librosa.load('music.au')
#歌曲的时长
d = librosa.get_duration(y=x, sr=22050, S=None, n_fft=2048, hop_length=512, center=True)
print('数据的维度',x.shape)
print('歌曲的频率',sr)
print('歌曲的时间',d)

可以看到音频信号是一维信号。
音频文件的保存
import numpy as np
import librosa
import matplotlib.pyplot as plt
import librosa.display
sr = 400 # sample rate 一秒采样400个点
T = 1.0 # seconds
t = np.linspace(0, T, int(T*sr), endpoint=False) # time variable
x = 0.5*np.sin(2*np.pi*24*t)# pure sine wave at 24 Hz
#保存音频文件
librosa.output.write_wav('aa.wav', x, sr)
plt.figure(figsize=(14, 5))
librosa.display.waveplot(x,sr=sr)
plt.show()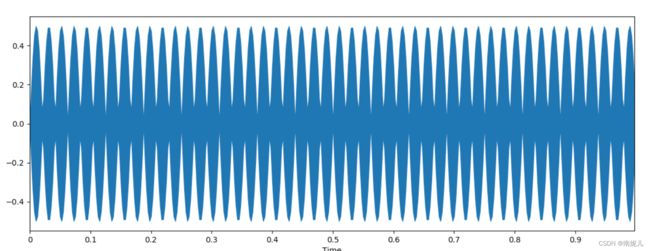
音频信号的可视化
波形
import librosa
import matplotlib.pyplot as plt
import librosa.display
x , sr = librosa.load('music.au')
plt.figure(figsize=(14, 5))
librosa.display.waveplot(x, sr=sr)
plt.show()
频谱图
频谱图(Spectogram)是声音频率随时间变化的频谱的可视化表示,是给定音频信号的频率随时间变化的表示。'.stft' 将数据转换为短期傅里叶变换。STFT转换信号,以便我们可以知道给定时间给定频率的幅度。使用 STFT,我们可以确定音频信号在给定时间播放的各种频率的幅度。
Spectrogram特征是目前在语音识别和环境声音识别中很常用的一个特征,由于CNN在处理图像上展现了强大的能力,使得音频信号的频谱图特征的使用愈加广泛,甚至比MFCC使用的更多。
import librosa
import matplotlib.pyplot as plt
import librosa.display
x , sr = librosa.load('music.au')
print('x shape',x.shape)
X = librosa.stft(x)
print('X shape',X.shape)
Xdb = librosa.amplitude_to_db(abs(X))
print('Xdb shape',Xdb.shape)
plt.figure(figsize=(14, 5))
librosa.display.specshow(Xdb, sr=sr, x_axis='time', y_axis='hz')
plt.colorbar()
plt.show()
音频信号特征提取
过零率 Zero Crossing Rate
过零率(zero crossing rate)是一个信号符号变化的比率,即,在每帧中,语音信号从正变为负或从负变为正的次数。 这个特征已在语音识别和音乐信息检索领域得到广泛使用,通常对类似金属、摇滚等高冲击性的声音的具有更高的价值。
import librosa
import matplotlib.pyplot as plt
import librosa.display
x , sr = librosa.load('music.au',sr=8000)
n0 = 9000
n1 = 9100
# plt.figure(figsize=(14, 5))
# plt.plot(x[n0:n1])
# plt.grid()
# plt.show()
zero_crossings=librosa.zero_crossings(x[n0:n1],pad=False)
print('在n0-n1之间过零率',sum(zero_crossings)/100)![]()
光谱质心 Spectral Centroid
频谱质心(Spectral Centroid)指示声音的“质心”位于何处,并按照声音的频率的加权平均值来加以计算。 假设现有两首歌曲,一首是蓝调歌曲,另一首是金属歌曲。现在,与同等长度的蓝调歌曲相比,金属歌曲在接近尾声位置的频率更高。所以蓝调歌曲的频谱质心会在频谱偏中间的位置,而金属歌曲的频谱质心则靠近频谱末端。
梅尔频率倒谱系数 MFCC
信号的Mel频率倒谱系数(MFCC)是一小组特征(通常约10-20),其简明地描述了频谱包络的整体形状,它模拟了人声的特征。
import librosa
import matplotlib.pyplot as plt
import librosa.display
x , sr = librosa.load('music.au',sr=8000)
mfccs = librosa.feature.mfcc(x, sr=sr)
print(mfccs.shape)
librosa.display.specshow(mfccs, sr=sr, x_axis='time')
plt.show()

歌曲题材分类
特征提取
import librosa
import numpy as np
import os
import glob
genres = 'blues classical country disco hiphop jazz metal pop reggae rock'.split()
data_set = []
label_set = []
label2id = {genre: i for i, genre in enumerate(genres)}
id2label = {i: genre for i, genre in enumerate(genres)}
print(label2id)
for g in os.listdir('./genres'):
print(g)
for filename in glob.glob('./genres/{}/*.au'.format(g)):
y, sr = librosa.load(filename, mono=True, duration=30)
##提取特征
chroma_stft = librosa.feature.chroma_stft(y=y, sr=sr)
rmse = librosa.feature.rms(y=y)
spec_cent = librosa.feature.spectral_centroid(y=y, sr=sr)
spec_bw = librosa.feature.spectral_bandwidth(y=y, sr=sr)
rolloff = librosa.feature.spectral_rolloff(y=y, sr=sr)
zcr = librosa.feature.zero_crossing_rate(y)
mfcc = librosa.feature.mfcc(y=y, sr=sr)
to_append = f'{np.mean(chroma_stft)} {np.mean(rmse)} {np.mean(spec_cent)} {np.mean(spec_bw)} {np.mean(rolloff)} {np.mean(zcr)}'
for e in mfcc:
to_append += f' {np.mean(e)}'
data_set.append([float(i) for i in to_append.split(" ")])
label_set.append(label2id[g])
data=np.array(data_set)
label=np.array(label_set)
print('数据的维度',data.shape)
print('标签',label.shape)
np.savez('data.npz',data,label)
模型的搭建
from tensorflow.keras import models
from tensorflow.keras.layers import Dense, Dropout,Conv1D
import tensorflow as tf
def creat_model():
model = models.Sequential([
])
model.add(Dense(26, activation='relu', input_shape=(26,)))
model.add(Dropout(0.3))
model.add(Dense(10, activation='softmax'))
return model
if __name__=='__main__':
model = creat_model()
model.summary()
input = tf.Variable(tf.random.normal([26]))
input=tf.reshape(input,(1,26))
output = model(input)
print('输出数据的维度',output.shape)
模型的训练
from sklearn.preprocessing import StandardScaler
import numpy as np
from sklearn.model_selection import train_test_split
from model import creat_model
import tensorflow as tf
import matplotlib.pyplot as plt
#导入数据
data=np.load('data.npz')['arr_0']
label=np.load('data.npz')['arr_1']
#归一化
scaler = StandardScaler()
X = scaler.fit_transform(np.array(data, dtype=float))
print('数据集的维度',X.shape)
#独热编码
label=tf.one_hot(label,10)
print('label shape',label.shape)
#划分训练集,测试集
X_train, X_test, label_train, label_test = train_test_split(X, np.array(label), test_size=0.2)
print('训练集',X_train.shape)
print('训练集标签',label_train.shape)
#模型的构建
model=creat_model()
print('打印模型')
model.summary()
#编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
#模型的训练
history=model.fit(X_train,label_train,epochs=500,batch_size=64,validation_data=(X_test,label_test))
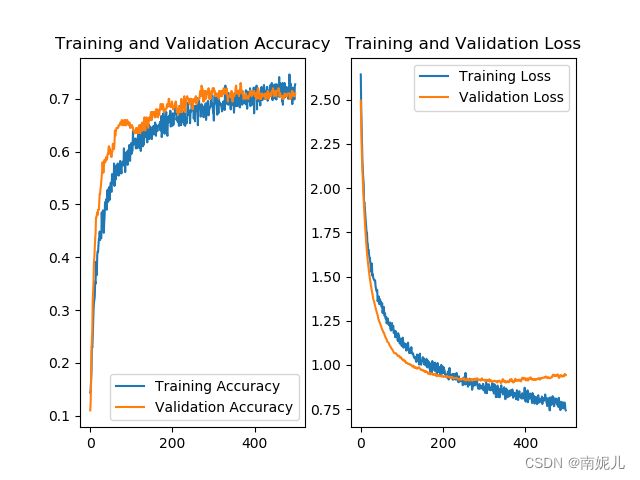
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.savefig('loss.png')
plt.show()
#模型的保存
model.save('model.h5')
#模型的评估
test_loss,test_acc=model.evaluate(X_test,label_test)
print('测试误差',test_loss)
print('测试准确率',test_acc)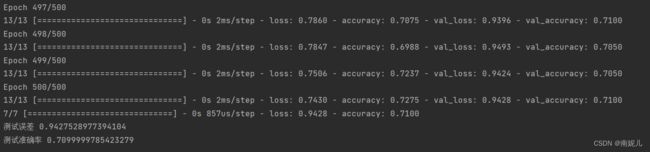
参考文献:
librosa处理音频信号_huailiang2010的博客-CSDN博客_librosa