troch.nn.functional.grid_sample()详解
官方文档解释点击此处
1. 简介
这个函数的作用在于将一个 ( N , C , H i n , W i n ) (N,C,H_{in},W_{in}) (N,C,Hin,Win)的特征图的每个特征图“像素”及其通道根据某个我们指定的网格坐标 ( N , H o u t , W o u t , 2 ) (N,H_{out},W_{out},2) (N,Hout,Wout,2)提取出来形成一个新的特征图 ( N , C , H o u t , W o u t ) (N,C,H_{out},W_{out}) (N,C,Hout,Wout),当然也可以处理5D输入的情况,详见官方文档,这里仅拿4D输入举例子
2. 举例
首先我们新建一个大小为 ( 2 , 3 , 4 , 5 ) (2,3,4,5) (2,3,4,5)的特征图,显然这个特征图有4行5列,通道数为3,batchsize为2
feature = torch.arange(120.).view(2, 3, 4, 5)
print(feature[0][0])
## output:
tensor([[ 0., 1., 2., 3., 4.],
[ 5., 6., 7., 8., 9.],
[10., 11., 12., 13., 14.],
[15., 16., 17., 18., 19.]])
其中第一个batch的第一个通道里面元素如上所示,画在坐标系里就是这样:
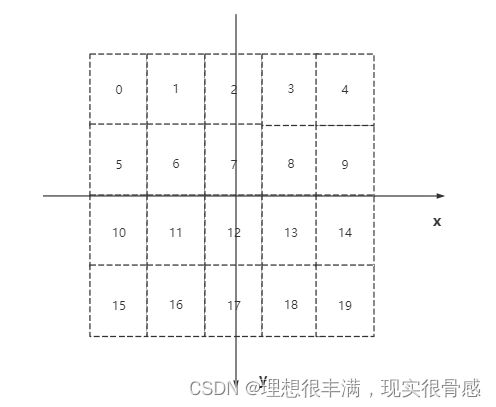
至于坐标系为啥是这样,这是官方规定的,并且我们想象一下这个特征图正好是归一化了在 [ − 1 , 1 ] [-1,1] [−1,1]这一片正方形坐标系区域,因为长宽不一样,所以图中特征图像素也呈现矩形的样子,每个像素上面的值和上面的输入一一对应。
我们建立的这样一个feature张量就当做了grid_sample函数的第一个参数,作为待提取的特征图,接下来我们再创建一个网格张量(比如5行6列),网格张量其实就相当于想要查询的坐标:
h = torch.linspace(-1, 1, 5)+1e-6
w = torch.linspace(-1, 1, 6)+1e-6
h_c, w_c = torch.meshgrid(h, w)
coord = torch.stack([h_c, w_c]) # 2,5,6 坐标通道,行数,列数
coord_grid = coord.permute(1, 2, 0).unsqueeze(0).expand(2, h.shape[0], w.shape[0], 2).flip(-1) # 变成batch,行数,列数,坐标通道
coord_grid[:,:,:,0]=coord_grid[:,:,:,0]+0.1 # 让x分量都+0.1,即让所有的采样点都往右偏移一下下
print(coord_grid[0])
## output:
tensor([[[-1.0000e+00, -1.0000e+00],
[-6.0000e-01, -1.0000e+00],
[-2.0000e-01, -1.0000e+00],
[ 2.0000e-01, -1.0000e+00],
[ 6.0000e-01, -1.0000e+00],
[ 1.0000e+00, -1.0000e+00]],
[[-1.0000e+00, -5.0000e-01],
[-6.0000e-01, -5.0000e-01],
[-2.0000e-01, -5.0000e-01],
[ 2.0000e-01, -5.0000e-01],
[ 6.0000e-01, -5.0000e-01],
[ 1.0000e+00, -5.0000e-01]],
[[-1.0000e+00, 1.0000e-06],
[-6.0000e-01, 1.0000e-06],
[-2.0000e-01, 1.0000e-06],
[ 2.0000e-01, 1.0000e-06],
[ 6.0000e-01, 1.0000e-06],
[ 1.0000e+00, 1.0000e-06]],
[[-1.0000e+00, 5.0000e-01],
[-6.0000e-01, 5.0000e-01],
[-2.0000e-01, 5.0000e-01],
[ 2.0000e-01, 5.0000e-01],
[ 6.0000e-01, 5.0000e-01],
[ 1.0000e+00, 5.0000e-01]],
[[-1.0000e+00, 1.0000e+00],
[-6.0000e-01, 1.0000e+00],
[-2.0000e-01, 1.0000e+00],
[ 2.0000e-01, 1.0000e+00],
[ 6.0000e-01, 1.0000e+00],
[ 1.0000e+00, 1.0000e+00]]])
上面我们输出了网格张量的第一个batch,可以看到网格张量共有3个维度,第一个维度代表行(5),第二个维度代表列(6),第三个维度代表坐标(也就是x,y的坐标,为2),画在坐标系里如图所示:

其中橙色点代表偏离出 [ − 1 , 1 ] [-1,1] [−1,1]的采样点,注意右边一列的橙色点很显然是因为我们代码里设置了偏移0.1导致的,下面一行的橙色点我们明明在边缘,为啥也是橙色的呢?是因为我们在代码里开始定义网格的时候就已经偏移了1e-6这个极小值,为了保证查询的稳定性,最好要加这么一个偏移,不然函数也不知道在边缘的时候该咋办呀~
至于要怎么处理橙色点,需要看传入函数的padding_mode参数决定是填充0还是其它。下面我们就可以进行采样并查看最终结果了:
res = torch.nn.functional.grid_sample(feature, coord_grid, mode='nearest', align_corners=False, padding_mode='zeros') # 得到N,C,H,W
print(res[0][0])
# output:
tensor([[ 0., 1., 2., 3., 4., 0.],
[ 5., 6., 7., 8., 9., 0.],
[10., 11., 12., 13., 14., 0.],
[15., 16., 17., 18., 19., 0.],
[ 0., 0., 0., 0., 0., 0.]])
如果把mode换成bilinear,会输出这样的结果,对于每个查询坐标,计算的都是针对周围4个特征图像素中心点的双线性插值:
tensor([[ 0.0000, 0.3750, 0.8750, 1.3750, 1.8750, 0.5000],
[ 1.8750, 3.2500, 4.2500, 5.2500, 6.2500, 1.6250],
[ 5.6250, 8.2500, 9.2500, 10.2500, 11.2500, 2.8750],
[ 9.3750, 13.2500, 14.2500, 15.2500, 16.2500, 4.1250],
[ 5.6250, 7.8750, 8.3750, 8.8750, 9.3750, 2.3750]])
3. 小结
通过上面的例子可以看出,grid_sample的作用便是将一个特征图的像素与其对应的通道“绑定”之后,进行一个像素的抽取或者是排列组合,获得一个新的特征图,这个规则得由第二个参数来决定,一般来说,用的都是生成的有规律的平面网格坐标。