2022最新!视觉SLAM综述(多传感器/姿态估计/动态环境/视觉里程计)
目录
摘要
视觉SLAM算法的发展
相关综述
VSLAM 设置标准
传感器和数据采集
目标环境
视觉特征处理
系统评估
语义等级
基于主要目标的VSLAM方法
目标一:多传感器处理
目标二:姿态估计
目标三:现实世界可行性
目标四:资源限制
目标五:弹性化(Versatility)
目标六:视觉里程计(Visual Odometry)
确定当前趋势
统计数字
分析当前趋势
结论
参考
摘要
近年来,基于视觉的传感器在SLAM系统中显示出显著的性能、精度和效率提升。在这方面,视觉SLAM(VSLAM)方法是指使用相机进行姿态估计和地图生成的SLAM方法。许多研究工作表明,VSLAM优于传统方法,传统方法仅依赖于特定传感器,例如激光雷达,即使成本较低。VSLAM利用不同的摄像机类型(例如单目、双目和RGB-D),在不同的数据集(例如KITTI、TUM RGB-D和EuRoC)和不同的环境(例如,室内和室外)中进行测试,并采用了多种算法和方法论,以更好地解析环境。上述变化使这一主题受到研究人员的广泛关注,并产出了许多经典VSLAM算法。在这方面,论文调查的主要目的是介绍VSLAM系统的最新进展,并讨论现有的挑战和未来趋势。论文对在VSLAM领域发表的45篇有影响力的论文进行了深入的调查,并根据不同的特点对这些方法进行了分类,包括novelty domain、目标、采用的算法和语义水平。最后论文讨论了当前的趋势和未来的方向,有助于研究人员进行研究。
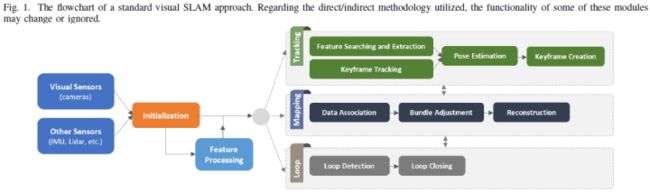
总结来说,图1显示了标准VSLAM方法的整体架构。系统的输入可以与其他传感器数据集成以提供更多信息,例如惯性测量单元(IMU)和激光雷达,而不是只有视觉数据。此外,对于VSLAM 范式中使用的直接或间接方法,视觉特征处理模块的功能可能会被更改或忽略。例如,“特征处理”阶段仅用于间接方法。另一个因素是利用一些特定模块,如回环检测和光束法平差,以改进执行。
视觉SLAM算法的发展
VSLAM系统在过去的几年中已经成熟,一些框架在这个开发过程中发挥了重要作用。图2展示了视觉SLAM发展过程中的里程碑算法。
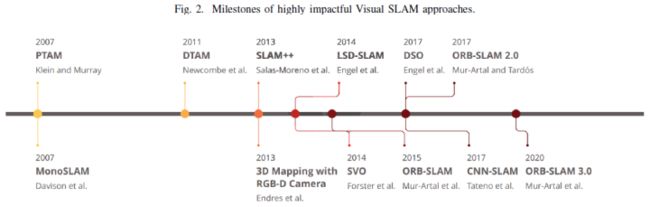
首篇实时单目VSLAM于2007年由Davison提出,名为Mono SLAM的框架[17]。他们的间接框架可以使用扩展卡尔曼滤波(EKF)算法估计现实世界中的相机运动和3D元素[18]。尽管缺乏全局优化和回环检测模块,Mono SLAM开始在VSLAM域中发挥主要作用。然而用这种方法重建的地图只包括地标,没有提供关于该区域的进一步详细信息。Klein等人[14]在同一年提出了Parallel Tracking and Mapping(PTAM),他们将整个VSLAM系统分为两个主要线程:tracking和mapping。PTAM为后续很多工作奠定了基石。PTAM方法的主要思想是降低计算成本,并使用并行处理来实现实时性能。当tracking实时估计摄像机运动时,mapping预测特征点的3D位置。PTAM也是第一个利用光束法平差(BA)联合优化相机姿态和3D地图创建的方法。其使用Features from Accelerated Segment Test(FAST)[19]的角点检测器算法进行关键点匹配和跟踪。尽管该算法的性能优于Mono SLAM,但其设计复杂,在第一阶段需要用户输入。Newcombe等人于2011年提出了一种用于测量深度值和运动参数来构建地图的直接方法,即密集跟踪和映射(DTAM)。DTAM是一种密集建图和密集跟踪模块的实时框架,可通过将整个帧与给定深度图对齐来确定相机姿态。为了构建环境地图,上述阶段分别估计场景的深度和运动参数。虽然DTAM可以提供地图的详细信息,但实时执行需要较高的计算成本。作为3D 建图和基于像素的优化领域中的另一种间接方法,Endres等人在2013年提出了一种可用于RGB-D相机的方法。他们的方法是实时的,专注于低成本嵌入式系统和小型机器人,但在无特征或具有挑战性的场景中无法产生准确的结果。同年,Salas Moreno等人[22]提出了SLAM++,是实时SLAM框架中利用语义信息的开山之作。SLAM++采用RGB-D传感器输出,并进行3D相机姿态估计和跟踪以形成姿态图。然后通过合并从场景中的语义目标获得的相对3D姿态来优化预测姿态。
随着VSLAM基线的成熟,研究人员专注于提高这些系统的性能和精度。Forster等人在2014年提出了一种混合VO方法,称为Semi-direct Visual Odometry(SVO)[24]。SVO可以结合基于特征的方法和直接方法来实现传感器的运动估计和建图任务。SVO可以与单目和双目相机一起工作,并配备了一个姿态细化模块,以最小化重投影误差。然而,SVO的主要缺点是采用短期数据关联,并且无法进行回环检测和全局优化。LSD-SLAM[25]是Engel等人于2014年提出的另一种有影响力的VSLAM方法,包含跟踪、深度估计和地图优化。该方法可以使用其姿态图估计模块重建大规模地图,并具有全局优化和回环检测功能。LSD-SLAM的弱点在于其初始化阶段,需要平面中的所有点,这使其成为一种计算密集型方法。Mur Artal等人介绍了两种精确的间接VSLAM方法,迄今为止广受关注:ORB-SLAM[26]和ORBSLAM 2.0[27]。这些方法可以在纹理良好的序列中完成定位和建图,并使用Oriented FAST and Rotated BRIEF(ORB)特征实现高性能的位置识别。ORB-SLAM的第一个版本能够使用从相机位置收集的关键帧来计算相机位置和环境结构。第二个版本是对ORB-SLAM的扩展,有三个并行线程,包括查找特征对应的跟踪、地图管理操作的局部建图,以及用于检测新环路和纠正漂移错误的回环。尽管ORB-SLAM 2.0可以与单目和立体相机一起使用,但由于重建具有未知比例的地图,因此不能用于自主导航。这种方法的另一个缺点是其无法在没有纹理的区域或具有重复模式的环境中工作。该框架的最新版本名为ORB-SLAM 3.0,于2021提出[28]。它适用于各种相机类型,如单目、RGB-D和双目视觉,并提供改进的姿态估计输出。
近年来,随着深度学习的快速发展,基于CNN的方法可以通过提供更高的识别和匹配率来解决许多问题。类似地,用学习特征替换人工设计的特征是许多最近基于深度学习的方法提出的解决方案之一。在这方面,Tateno等人提出了一种基于CNN的方法,该方法处理相机姿态估计的输入帧,并使用关键帧进行深度预测,命名为CNN-SLAM[29]。CNN-SLAM实现并行处理和实时性能的核心思想之一是,将相机帧分割成较小的部分以更好地理解环境。Engel等人还引入了Direct Sparse Odometry(DSO)[30],其将直接方法和稀疏重建相结合,以提取图像块中的最高强度点。
综上所述,VSLAM系统演进过程中的里程碑表明,最近的方法侧重于多个专用模块的并行执行。这些模块形成了与广泛的传感器和环境兼容的通用技术和框架。上述特性使它们能够实时执行,并且在性能改进方面更加灵活。
相关综述
VSLAM领域已有不少综述,对不同的现有方法进行了全面调查。每一篇论文都回顾了使用VSLAM方法的主要优点和缺点。Macario Barros等人[31]将方法分为三个不同类别:仅视觉(单目)、视觉惯性(立体)和RGB-D。他们还提出了简化分析VSLAM算法的各种标准。然而[31]并没有包括其他视觉传感器,比如基于事件的传感器。Chen等人[32]调查了广泛的传统和语义VSLAM。他们将SLAM开发时代分为经典、算法分析和鲁棒感知阶段。并总结了采用直接/间接方法的经典框架,研究了深度学习算法在语义分割中的影响。尽管他们的工作提供了该领域高级解决方案的全面研究,但方法的分类仅限于基于特征的VSLAM中使用的特征类型。Jia等人[33]调查了大量文献,并对基于图优化的方法和配备深度学习的方法进行了简要比较。在另一项工作中,Abaspur Kazerouni等人[34]涵盖了各种VSLAM方法,利用了感官设备、数据集和模块,并模拟了几种间接方法进行比较和分析。它们只对基于特征的算法进行分析,例如HOG、尺度不变特征变换(SIFT)、加速鲁棒特征(SURF)和基于深度学习的解决方案。Bavle等人[35]分析了各种SLAM和VSLAM应用中的态势感知方面,并讨论了它们的缺失点。还有一些其他综述如[15]、[36]、[37]、[32]、[37]在此不再赘述。
与上述综述不同,本文对不同场景的VSLAM系统进行全面调查,主要贡献如下:
-
对各种最近的VSLAM方法进行分类,这些方法涉及研究人员在提出新解决方案方面的主要贡献、标准和目标;
-
通过深入研究不同方法的不同方面,分析VSLAM系统的当前趋势;
-
介绍VSLAM对研究人员的潜在贡献。
VSLAM 设置标准
考虑到各种VSLAM方法,论文将可用的不同设置和配置分为以下类别:传感器和数据采集、目标环境、视觉特征处理、系统评估和语义类别,下面逐一介绍。
传感器和数据采集
Davison等人[17]引入的VSLAM算法的早期阶段配备了用于轨迹恢复的单目摄像机。单目相机是最常见的视觉传感器,用于各种任务,如物体检测和跟踪[39]。另一方面,立体相机包含两个或更多图像传感器,使其能够感知图像中的深度,从而在VSLAM应用中实现更准确的性能。相机设置具有成本效益,并为更高的精度要求提供信息感知。RGB-D相机也是VSLAM中使用的视觉传感器,其可以提供场景中的深度和颜色。上述视觉传感器可以提供丰富的环境信息,例如,适当的照明和运动速度,但它们通常难以应对照明度低或场景动态范围高的情况。
近年来,事件摄像机也被用于各种VSLAM应用中。当检测到运动时,这些低延迟仿生视觉传感器产生像素级亮度变化,而不是标准强度帧,从而实现高动态范围输出,而不会产生运动模糊影响[40]。与标准相机相比,事件传感器在高速运动和大范围动态场景中可以提供可靠的视觉信息,但在运动速度较低时无法提供足够的信息。另一方面,事件相机主要输出关于环境的不同步信息。这使得传统的视觉算法无法处理这些传感器的输出[41]。此外,使用事件的时空窗口以及从其他传感器获得的数据可以提供丰富的姿态估计和跟踪信息。
此外,一些方法使用多目相机设置来解决在真实环境中工作的常见问题,并提高定位精度。利用多目传感器有助于解决复杂问题,例如遮挡、伪装、传感器故障或可跟踪纹理稀疏等,为摄像机提供重叠视角。尽管多目相机可以解决一些数据采集问题,但纯视觉的VSLAM可能会面临各种挑战,例如遇到快速移动目标时的运动模糊、低照度或高照度下的特征不匹配、高速变化场景下的动态目标忽略等。因此,一些VSLAM应用程序可能会在摄像机旁边配备多个传感器。融合事件和标准帧[42]或将其他传感器(如激光雷达[43]和IMU)集成到VSLAM是一些现有的解决方案。
目标环境
作为许多传统VSLAM实践中的一个有力假设,机器人在静态世界中工作,没有突然或意外的变化。因此,尽管许多系统可以在特定环境中成功应用,但环境中的一些意外变化(例如,移动目标的存在)可能会导致系统复杂化,并在很大程度上降低状态估计质量。在动态环境中工作的系统通常使用诸如光流或随机采样一致性(RANSAC)[44]之类的算法来检测场景中的移动,将移动目标分类为异常值,并在重建地图时跳过它们。这样的系统利用几何/语义信息或试图通过组合这两个结果来改进定位方案[45]。
此外作为一般分类法,论文将环境分为室内和室外两类。室外环境可以是具有结构地标和大规模运动变化(如建筑物和道路纹理)的城市区域,或具有弱运动状态(如移动的云和植被、沙子纹理等)的越野区域,这增加了定位和回环检测失败的风险。另一方面,室内环境包含具有完全不同的全局空间属性的场景,例如走廊、墙和房间。论文认为,虽然VSLAM系统可能在上述区域中的一个工作良好,但在其他环境中可能表现不出相同的性能。
视觉特征处理
如前文所述,检测视觉特征并利用特征描述子信息进行姿态估计是间接VSLAM方法的一个必要阶段。这些方法使用各种特征提取算法来更好地理解环境并跟踪连续帧中的特征点。特征提取算法有很多,包括SIFT[46]、SURF[47]、FAST[19]、BRIEF[48]、ORB[49]等。其中,与SIFT和SURF[50]相比,ORB特征具有快速提取和匹配而不大幅损失准确度的优点。
上述一些方法的问题是它们不能有效地适应各种复杂和不可预见的情况。因此,许多研究人员使用CNN来提取图像特征,包括VO、姿态估计和回环检测。根据方法的功能,这些技术可以表示有监督或无监督的框架。
系统评估
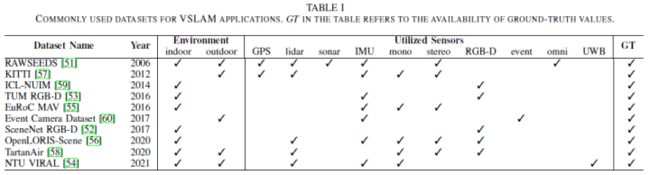
虽然一些VSLAM方法,特别是那些能够在动态和挑战性环境中工作的方法,在真实世界中进行测试。但许多研究工作都使用了公开的数据集来证明其适用性。在这方面,Bonarini等人[51]的RAWSEEDS数据集是一个著名的多传感器基准测试工具,包含室内、室外和混合机器人轨迹与真值数据。它是用于机器人和SLAM目的的最古老的公开基准测试工具之一。McCormac等人[52]的Scenenet RGB-D是场景理解问题的另一个受欢迎的数据集,例如语义分割和目标检测,包含500万个大规模渲染的RGB-D图像。最近在VSLAM和VO领域的许多工作已经在TUM RGB-D数据集上测试了它们的方法[53]。此外,Nguyen等人[54]的NTU VIRAL是由配备3D激光雷达、相机、IMU和多个超宽带(UWB)的无人机收集的数据集。该数据集包含室内和室外实例,旨在评估自动驾驶和空中操作性能。其他数据集如EuRoC MAV[55]、OpenLORIS Scene[56]、KITTI[57]、TartanAir[58]、ICL-NUIM[59]和基于事件相机的数据集[60]可以参考相关论文。
根据传感器设置、应用和目标环境,上述数据集用于多种VSLAM方法。这些数据集主要包含摄像机的内外参以及GT。表I和图3分别显示了数据集的总结特征和每个数据集的一些实例。

语义等级
机器人需要语义信息才能理解周围的场景并做出更优决策。在许多最近的VSLAM工作中,将语义级信息添加到基于几何的数据中优于纯几何的方法,使其能够提供环境的概念知识[61]。在这方面,预先训练的目标识别模块可以将语义信息添加到VSLAM模型[62]。最新的方法之一是在VSLAM应用中使用CNN。一般来说,语义VSLAM方法包含以下四个主要组成部分[43]:
-
跟踪模块:它使用从连续视频帧中提取的二维特征点来估计相机姿态并构建三维地图点。相机姿态的计算和3D地图点的构建分别建立了定位和建图过程的基线;
-
局部建图模块:通过处理两个连续视频帧,创建了一个新的3D地图点,该点与BA模块一起用于改进相机姿态;
-
回环模块:通过将关键帧与提取的视觉特征进行比较并评估它们之间的相似性,进一步调整相机姿态并优化构建的地图;
-
非刚性上下文消隐 (Non-Rigid Context Culling,NRCC):使用NRCC的主要目标是从视频帧中过滤时间目标,以减少它们对定位和建图阶段的不利影响。其主要包含一个分割过程,用于分离帧中的各种不稳定实例,例如人。由于NRCC可以减少待处理的特征点的数量,因此简化了计算部分并获得了更鲁棒的性能。
因此,在VSLAM方法中利用语义信息可以改善姿态估计和地图重建的不确定性。然而,当前的挑战是如何正确使用提取的语义信息,而不影响计算成本。
基于主要目标的VSLAM方法
目标一:多传感器处理
这一类别涵盖了使用各种传感器以更好地了解环境的VSLAM方法的范围。虽然一些技术仅依赖摄像机作为所使用的视觉传感器,但其他技术将各种传感器结合起来以提高算法的准确性。
1)使用多相机
一个相机重建运动物体的3D轨迹可能很困难,一些研究人员建议使用多相机。例如,CoSLAM是Zou和Tan[63]推出的一个VSLAM系统,它使用部署在不同平台上的单摄像机来重建鲁棒地图。CoSLAM结合了在动态环境中独立移动的多个摄像机,并根据它们重叠的视场重建地图。该过程通过混合相机内和相机间姿态估计和建图,使得在3D中重建动态点更容易。CoSLAM使用Kanade-Lucas-Tomasi(KLT)算法跟踪视觉特征,并在静态和动态环境中运行,包括室内和室外,其中相对位置和方向可能会随时间变化。这种方法的主要缺点是需要复杂的硬件来理解大量的摄像机输出,并通过增加更多的摄像机来增加计算成本。
对于具有挑战性的野外场景,Yang等人[64]开发了一种多摄像机协同全景视觉VSLAM方法。[64]赋予每个摄像机独立性,以提高VSLAM系统在挑战场景下的性能,例如遮挡和纹理稀疏。为了确定匹配范围,他们从摄像机的重叠视场中提取ORB特征。此外,[64]还使用了基于CNN的深度学习技术来识别回环检测的类似特征。在实验中,作者使用了由全景相机和集成导航系统生成的数据集。相关工作还有MultiCol-SLAM[65]。
2)使用多传感器
其他一些方法建议融合多传感器,并使用基于视觉和惯性的传感器输出以获得更好的性能。在这方面,Zhu等人[66]提出了一种称为CamVox的低成本间接激光雷达辅助VSLAM,并证明了其可靠的性能和准确性。他们的方法使用ORB-SLAM 2.0,将Livox激光雷达作为高级深度传感器提供的独特功能与RGB-D相机的输出相结合。作者使用IMU来同步和校正非重复扫描位置。CamVox贡献是提出了一种在不受控制的环境中运行的自主激光雷达-相机校准方法。在机器人平台上的实测表明,CamVox在能够实时运行。
[67]提出了一种名为VIRAL(视觉-惯性-测距-激光雷达)SLAM的多模态系统,该系统将相机、激光雷达、IMU和UWB耦合起来。并提出了一种基于激光雷达点云构建的局部地图的视觉特征地图匹配边缘化方案。使用BRIEF算法提取和跟踪视觉分量。该框架还包含用于所使用的传感器的同步方案和触发器。VIRAL在NTU VIRAL[54]数据集上测试了他们的方法,该数据集包含相机、激光雷达、IMU和UWB传感器捕获的数据。然而,由于处理同步、多线程和传感器冲突解决,他们的方法计算量很大。其他相关算法Ultimate SLAM[68]、[69]可以参考相关论文。
目标二:姿态估计
这类方法的重点是如何使用各种算法改进VSLAM方法的姿态估计。
1)使用线/点数据
在这方面,Zhou等人[70]建议使用建筑结构线段作为有用的特征来确定相机姿态。结构线与主导方向相关联,并编码全局方向信息,从而改善预测轨迹。方法名为StructSLAM,是一种6自由度(DoF)VSLAM技术,可在低特征和无特征条件下运行。
Point and Line SLAM(PL-SLAM)是一种基于ORB-SLAM的VSLAM系统,针对非动态低纹理场景进行了优化,由Pumarola等人提出[71]。该系统同时融合线和点特征以改进姿态估计,并帮助在特征点较少的情况下运行。作者在生成的数据集和TUM RGB-D上测试了PL-SLAM。其方法的缺点是计算成本和必须使用其他几何图元(例如平面),以获得更稳健的精度。
Gomez-Ojeda等人[72]介绍了PL-SLAM(不同于Pumarola等人[71]中同名的框架),这是一种间接VSLAM技术,使用立体视觉相机中的点和线来重建看不见的地图。他们将从所有VSLAM模块中的点和线获得的片段与从其方法中的连续帧获取的视觉信息合并。使用ORB和线段检测器(LSD)算法,在PL-SLAM中的后续立体帧中检索和跟踪点和线段。作者在EuRoC和KITTI数据集上测试了PL-SLAM,在性能方面可能优于ORB-SLAM 2.0的立体版本。PL-SLAM的主要缺点之一是特征跟踪模块所需的计算时间以及考虑所有结构线以提取关于环境的信息。其他相关算法[73]可以参考论文。
2)使用额外特征
[74]中提出了Dual Quaternion Visual SLAM(DQV-SLAM),一种用于立体视觉相机的框架,该框架使用广泛的贝叶斯框架进行6-DoF姿态估计。为了防止非线性空间变换组的线性化,他们的方法使用渐进贝叶斯更新。对于地图的点云和光流,DQV-SLAM使用ORB功能在动态环境中实现可靠的数据关联。在KITTI和EuRoC数据集上,该方法可以可靠地得到预测结果。然而,它缺乏姿态随机建模的概率解释,并且对基于采样近似的滤波的计算要求很高。其他相关算法SPM-SLAM[75]可以参考论文。
3)深度学习
Bruno和Colombini[76]提出了LIFT-SLAM,它将基于深度学习的特征描述子与传统的基于几何的系统相结合。并扩展了ORB-SLAM系统的流水线,使用CNN从图像中提取特征,基于学习得到的特征提供更密集和精确的匹配。为了检测、描述和方向估计,LIFT-SLAM微调学习不变特征变换(LIFT)深度神经网络。使用KITTI和EuRoC MAV数据集的室内和室外实例进行的研究表明,LIFT-SLAM在精度方面优于传统的基于特征和基于深度学习的VSLAM系统。然而,该方法的缺点是其计算密集的流水线和未优化的CNN设计。
Naveed等人[77]提出了一种基于深度学习的VSLAM解决方案,该解决方案具有可靠且一致的模块,即使在极端转弯的路线上也是如此。他们的方法优于几种VSLAM,并使用了在真实模拟器上训练的深度强化学习网络。此外,它们还为主动VSLAM评估提供了基线,并可在实际室内和室外环境中适当推广。网络的路径规划器开发了理想的路径数据,由其基础系统ORB-SLAM接收。[77]制作了一个数据集,包含了挑战性和无纹理环境中的实际导航事件,以供评估。其他方法RWT-SLAM[78]可参考相关论文。
目标三:现实世界可行性
这类方法的主要目标是在各种环境中使用,并在多种场景下工作。论文注意到,本节中的引用与从环境中提取的语义信息高度集成,并展示了端到端的VSLAM应用。
1)动态环境
在这方面,Yu等人[61]引入了一个名为DS-SLAM的VSLAM系统,该系统可用于动态上下文,并为地图构建提供语义级信息。该系统基于ORB-SLAM 2.0,包含五个线程:跟踪、语义分割、局部建图、回环和密集语义图构建。为了在姿态估计过程之前排除动态目标并提高定位精度,DS-SLAM使用了实时语义分割网络SegNet的光流算法[80]。DS-SLAM已经在现实世界环境中、RGB-D相机以及TUM RGB-D数据集上进行了测试。然而,尽管它的定位精度很高,但它仍面临语义分割限制和计算密集型特征的问题。
Semantic Optical Flow SLAM(SOF-SLAM)是基于ORB-SLAM 2.0的RGB-D模式构建的间接VSLAM系统[45]。他们的方法使用语义光流动态特征检测模块,该模块提取并跳过ORB特征提取提供的语义和几何信息中隐藏的变化特征。为了提供准确的相机姿态和环境信息,SOF-SLAM使用了SegNet的像素级语义分割模块。在极端动态的情况下,TUM RGB-D数据集和现实环境中的实验结果表明,SOF-SLAM的性能优于ORB-SLAM 2.0。然而,非静态特征识别的无效方法和仅依赖于两个连续帧是SOF-SLAM的缺点。其他相关算法[81]、[82]可以参考相关论文。
2)基于深度学习的解决方案
在Li等人[83]的另一个名为DXSLAM的工作中,深度学习用于找到类似于SuperPoints的关键点,并生成通用描述子和图像的关键点。他们训练先进的CNN HF-NET,通过从每个帧中提取局部和全局信息,生成基于帧和关键点的描述子。此外还使用离线Bag of Words(BoW)方法训练局部特征的视觉词汇表,以实现精确的回环识别。DXSLAM在不使用GPU的情况下实时运行,并且与当代CPU兼容。即使这些品质没有得到特别的处理,它也有很强的抵抗动态环境中动态变化的能力。DXSLAM已经在TUM RGB-D和OpenLORIS场景数据集以及室内和室外图像上进行了测试,可以获得比ORB-SLAM 2.0和DS-SLAM更准确的结果。然而,这种方法的主要缺点是复杂的特征提取架构和将深层特征合并到旧的SLAM框架中。
在另一种方法中,Li等人[84]开发了一种实时VSLAM技术,用于在复杂情况下基于深度学习提取特征点。该方法可以在GPU上运行,支持创建3D密集地图,是一个具有自监督功能的多任务特征提取CNN。CNN输出是固定长度为256的二进制代码串,这使得它可以被更传统的特征点检测器(如ORB)所取代。系统包括三个线程,用于在动态场景中实现可靠和及时的性能:跟踪、局部建图和回环。支持使用ORB-SLAM 2.0作为基线的单目和RGB-D相机的系统。其他相关算法[85]可以参考相关论文。
3)使用人工地标
Medina Carnicer等人提出的一种称为UcoSLAM[86]的技术,通过结合自然和人造地标,并使用基准标记自动计算周围环境的比例,从而优于传统的VSLAM系统。UcoSLAM的主要驱动力是对抗自然地标的不稳定性、重复性和较差的跟踪质量。它可以在没有标签或特征的环境中运行,因为它只能在关键点、地标和混合模式下运行。为了定位地图对应关系,优化重投影误差,并在跟踪失败时重新定位,UcoSLAM具有跟踪模式。此外,它有一个基于地标的回环检测系统,可以使用任何描述子描述特征,包括ORB和FAST。尽管UcoSLAM有很多优点,但系统在多线程中执行,这使得它成为一种耗时的方法。
4)广泛的设置
用于动态室内和室外环境的另一种VSLAM策略是DMS-SLAM[87],它支持单目、立体和RGB-D视觉传感器。该系统采用滑动窗口和基于网格的运动统计(GMS)[88]特征匹配方法来找到静态特征位置。DMS-SLAM以ORB-SLAM 2.0系统为基础,跟踪ORB算法识别的静态特征。作者在TUM RGB-D和KITTI数据集上测试了他们建议的方法,并优于先进的的VSLAM算法。此外,由于在跟踪步骤中删除了动态目标上的特征点,DMS-SLAM比原始的ORB-SLAM 2.0执行得更快。尽管有上述优点,但DMS-SLAM在纹理少、运动快和高度动态环境的情况下会遇到困难。
目标四:资源限制
在另一类中,与其他标准设备相比,一些VSLAM方法是为计算资源有限的设备构建的。例如,为移动设备和具有嵌入式系统的机器人设计的VSLAM系统就属于这一类别。
1)处理能力有限的设备
在这方面,edgeSLAM是Xu等人提出的用于移动和资源受限设备的实时、边缘辅助语义VSLAM系统[89]。它采用了一系列细粒度模块,由边缘服务器和相关移动设备使用,而不需要多线程。edgeSLAM中还包括基于Mask-RCNN技术的语义分割模块,以改进分割和目标跟踪。作者在一个边缘服务器上安装了一些商用移动设备,如手机和开发板。通过重用目标分割的结果,他们通过使系统参数适应不同的网络带宽和延迟情况来避免重复处理。EdgeSLAM已在TUM RGB-D、KITTI的单目视觉实例和为实验设置创建的数据集上进行了评估。
对于立体相机设置,Grisetti等人[90]提出了一种轻量级的基于特征的VSLAM框架,名为ProSLAM,其结果与先进技术不相上下。四个模块组成了他们的方法:triangulation模块,它创建3D点和相关的特征描述子;增量运动估计模块,其处理两个帧以确定当前位置;创建局部地图的地图管理模块;以及基于局部地图的相似性更新世界地图的重新定位模块。ProSLAM使用单个线程检索点的3D位置,并利用少量已知库来创建简单的系统。根据KITTI和EuRoC数据集的实验,他们的方法可以获得稳健的结果。然而,它在旋转估计方面表现出不足,并且不包含任何光束法平差模块。其他相关算法VPS-SLAM[91]、[94]可以参考相关论文。
2)计算迁移
Ben Ali等人[96]建议使用边缘计算将资源密集型操作迁移到云上,并减少机器人的计算负担。他们在其间接框架Edge-SLAM中修改了ORB-SLAM 2.0的架构,在机器人上维护了跟踪模块,并将剩余部分委派给边缘。通过在机器人和边缘设备之间拆分VSLAM流水线,系统可以维护局部和全局地图。在可用资源较少的情况下,它们仍然可以在不牺牲准确性的情况下正确运行。[96]使用TUM RGB-D数据集和两个不同的移动设备,基于RGB-D相机生成定制的室内环境数据集进行评估。然而,该方法的缺点之一是由于各种SLAM模块的解耦而导致架构的复杂性。另一个问题是,系统仅在短期设置下工作,在长期场景(例如,多天)中使用Edge SLAM将面临性能下降。
目标五:弹性化(Versatility)
VSLAM在这一类中的工作侧重于直接的开发、利用、适应和扩展。
在这方面,Sumikura等人[95]引入了OpenVSLAM,这是一个高度适应性的开源VSLAM框架,旨在快速开发并被其他第三方程序调用。他们基于特征的方法与多种相机类型兼容,包括单目、立体和RGB-D,并且可以存储或重用重建的地图以供以后使用。由于其强大的ORB特征提取模块,OpenVSLAM在跟踪精度和效率方面优于ORB-SLAM和ORB-SLAM2.0。然而,由于担心代码相似性侵犯了ORB-SLAM 2.0的权利,该系统的开源代码已经停止。
为了弥合实时能力、准确性和弹性之间的差距,Ferrera等人[97]开发了OV2SLAM,可用于单目和立体视觉相机。通过将特征提取限制在关键帧中,并通过消除测光误差在后续帧中对其进行监控,他们的方法减少了计算量。从这个意义上讲,OV2SLAM是一种混合策略,它结合了VSLAM直接和间接方法的优点。在室内和室外实验中,使用包括EuRoC、KITTI和TartanAir在内的著名基准数据集,证明OV2SLAM在性能和准确性方面优于几种流行技术。其他相关算法DROID-SLAM[98]、iRotate[99]可以参考相关论文。
目标六:视觉里程计(Visual Odometry)
此类方法旨在以尽可能高的精度确定机器人的位置和方向。
1)深度神经网络
在这方面,[100]中提出了Dynamic-SLAM框架,该框架利用深度学习进行准确的姿态预测和适当的环境理解。作为优化VO的语义级模块的一部分,作者使用CNN来识别环境中的运动目标,这有助于他们降低由不正确的特征匹配带来的姿态估计误差。此外,Dynamic-SLAM使用选择性跟踪模块来忽略场景中的动态位置,并使用缺失特征校正算法来实现相邻帧中的速度不变性。尽管结果很好,但由于定义的语义类数量有限,该系统需要巨大的计算成本,并面临动态/静态目标误分类的风险。
Bloesch等人[101]提出了Code-SLAM,它提供了场景几何体的浓缩和密集表示。他们的VSLAM系统是PTAM的增强版[14],该系统仅与单目摄像机一起工作。其将强度图像划分为卷积特征,并使用根据SceneNet RGB-D数据集的强度图像训练的CNN将其馈送到深度自编码器。EuRoC数据集的实验结果表明,其结果在准确性和性能方面很有希望。其他相关算法DeepVO[102]、[103]、DeepFactors[104]可以参考相关论文。
2)深度相邻帧处理
在另一项工作中,[106]的作者通过减少用于摄像机运动检测的两幅图像之间的光度和几何误差,为RGB-D摄像机开发了一种实时密集SLAM方法,改进了他们先前的方法[107]。他们基于关键帧的解决方案扩展了Pose SLAM[108],它只保留非冗余姿态,以生成紧凑的地图,增加了密集的视觉里程计特征,并有效地利用来自相机帧的信息进行可靠的相机运动估计。作者还采用了一种基于熵的技术来度量关键帧的相似性,用于回环检测和漂移避免。然而,他们的方法仍然需要在回环检测和关键帧选择质量方面进行工作。
在Li等人[109]介绍的另一项工作中,使用称为DP-SLAM的基于特征的VSLAM方法实现实时动态目标移除。该方法使用基于从运动目标导出的关键点的似然性的贝叶斯概率传播模型。使用移动概率传播算法和迭代概率更新,DP-SLAM可以克服几何约束和语义数据的变化。它与ORB-SLAM 2.0集成,并在TUM RGB-D数据集上进行了测试。尽管结果准确,但由于迭代概率更新模块,该系统仅在稀疏VSLAM中工作,并且面临较高的计算成本。其他相关算法[110]可以参考相关论文。
3)各种特征处理
此类别中的另一种方法是Li等人[111]提出的基于文本的VSLAM系统,称为TextSLAM。它将使用FAST角点检测技术从场景中检索的文本项合并到SLAM管道中。文本包括各种纹理、图案和语义,这使得使用它们创建高质量3D文本地图的方法更加有效。TextSLAM使用文本作为可靠的视觉基准标记,在找到文本的第一帧之后对其进行参数化,然后将3D文本目标投影到目标图像上以再次定位。他们还提出了一种新的三变量参数化技术,用于初始化瞬时文本特征。使用单目相机和作者创建的数据集,在室内和室外环境中进行了实验,结果非常准确。在无文本环境中操作、解释短字母以及需要存储大量文本词典是TextSLAM的三大基本挑战。其他相关算法[43]、[112]可以参考相关论文。
确定当前趋势
统计数字
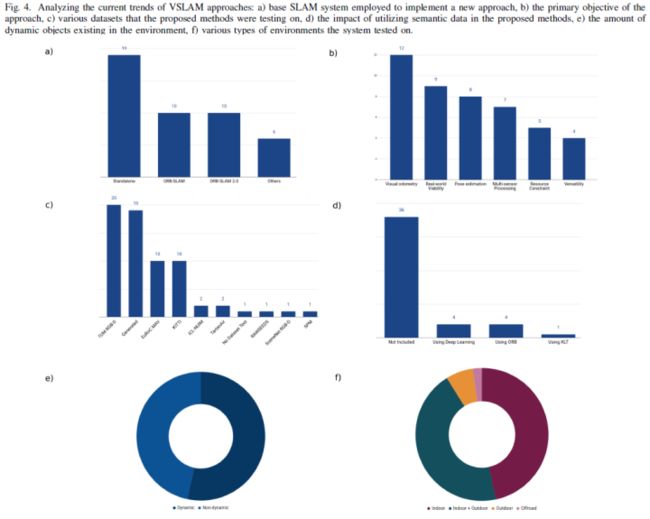
关于上述各方面调查论文的分类,论文将图4中的处理数据可视化,以找出VSLAM的当前趋势。在子图“a”中,可以看到,大多数拟议的VSLAM系统都是独立的应用程序,它们使用视觉传感器从头开始执行定位和建图的整个过程。虽然ORB-SLAM2.0和ORB-SLAM是用于构建新框架的其他基础平台,但只有很少的方法基于其他VSLAM系统,如PTAM和PoseSLAM。此外,就VSLAM应用程序的目标而言,子图“b”中最重要的是改进视觉里程计模块。因此,大多数最近的VSLAM都试图解决当前算法在确定机器人位置和方向方面的问题。姿态估计和真实世界生存能力是提出新的VSLAM论文的进一步基本目标。关于调查论文中用于评估的数据集,子图“c”说明了大多数工作都在TUM RGB-D数据集上进行了测试。此外,许多研究人员倾向于对他们生成的数据集进行实验。我们可以假设生成数据集的主要动机是展示VSLAM方法在真实场景中的工作方式,以及它是否可以作为端到端应用程序使用。EuRoC MAV和KITTI分别是VSLAM工作中下一个流行的评估数据集。从子图“d”中提取的另一个有趣信息涉及使用VSLAM系统时使用语义数据的影响。我们可以看到,大多数论文在处理环境时不包括语义数据。论文假设不使用语义数据的原因是:
-
在许多情况下,训练识别目标并将其用于语义分割的模型的计算成本相当大,这可能会增加处理时间;
-
大多数基于几何的VSLAM算法被设计在即插即用的设备上工作,因此它们可以用最少的努力使用相机数据进行定位和建图;
-
从场景中提取的不正确信息也会导致过程中增加更多的噪声。
当考虑环境时,我们可以在子图“e”中看到,一半以上的方法也可以在具有挑战性的动态环境中工作,而其余的系统只关注没有动态变化的环境。此外,在子图“f”中,大多数方法都适用于“室内环境”或“室内和室外环境”,而其余的论文仅在室外条件下进行了测试。应当指出的是,如果在其他情况下采用的方法只能在具有限制性假设的特定情况下工作,则可能不会产生相同的准确性。这是一些方法只集中于特定情况的主要原因之一。
分析当前趋势
本文回顾了最先进的视觉SLAM方法,这些方法吸引了大量关注,并展示了它们在该领域的主要贡献。尽管在过去几年中,VSLAM系统的各个模块都有了广泛的可靠解决方案和改进,但仍有许多高潜力领域和未解决的问题需要在这些领域进行研究,从而在SLAM的未来发展中采用更稳健的方法。鉴于视觉SLAM方法的广泛性,论文介绍以下开放的研究方向:
深度学习:深度神经网络在各种应用中显示出令人鼓舞的结果,包括VSLAM[15],使其成为多个研究领域的一个重要趋势。由于其学习能力,这些体系结构已显示出相当大的潜力,可以用作可靠的特征提取器,以解决VO和回环检测中的不同问题。CNN可以帮助VSLAM进行精确的目标检测和语义分割,并且在正确识别人工设计的特征方面可以优于传统的特征提取和匹配算法。必须指出的是,由于基于深度学习的方法是在具有大量多样数据和有限目标类的数据集上进行训练的,因此总是存在对动态点进行错误分类并导致错误分割的风险。因此,它可能导致较低的分割精度和姿态估计误差。
信息检索和计算成本权衡:通常情况下,处理成本和场景中的信息量应始终保持平衡。从这个角度来看,密集地图允许VSLAM应用程序记录高维完整场景信息,但实时这样做将需要计算量。另一方面,稀疏表示由于其较低的计算成本,将无法捕获所有需要的信息。还应注意的是,实时性能与摄像机的帧速率直接相关,峰值处理时间的帧丢失会对VSLAM系统的性能产生负面影响,而与算法性能无关。此外,VSLAM通常利用紧耦合的模块,修改一个模块可能会对其他模块产生不利影响,这使得平衡任务更具挑战性。
语义分割:在创建环境地图的同时提供语义信息可以为机器人带来非常有用的信息。识别摄像机视场中的目标(例如门、窗、人等)是当前和未来VSLAM工作中的一个热门话题,因为语义信息可用于姿态估计、轨迹规划和回环检测模块。随着目标检测和跟踪算法的广泛使用,语义VSLAM无疑将成为该领域未来的解决方案之一。回环算法:任何SLAM系统中的关键问题之一是漂移问题,以及由于累积的定位误差而导致的特征轨迹丢失。在VSLAM系统中,检测漂移和回环以识别先前访问过的位置会导致计算延迟和高成本[89]。主要原因是回环检测的复杂度随着重建地图的大小而增加。此外,组合从不同地点收集的地图数据并细化估计姿态是非常复杂的任务。因此,回环检测模块的优化和平衡具有巨大的改进空间。检测回环的常见方法之一是通过基于局部特征训练视觉词汇表,然后将其聚合来改进图像检索。
在具有挑战性的场景中工作:在没有纹理的环境中工作,很少有显著特征点,这通常会导致机器人的位置和方向出现漂移误差。作为VSLAM的主要挑战之一,此错误可能导致系统故障。因此,在基于特征的方法中考虑互补的场景理解方法,例如目标检测或线条特征,将是一个热门话题。
结论
本文介绍了一系列SLAM算法,其中从摄像机采集的视觉数据起着重要作用。论文根据VSLAM系统方法的各种特点,如实验环境、新颖领域、目标检测和跟踪算法、语义级生存能力、性能等,对其最近的工作进行了分类。论文还根据作者的主张、未来版本的改进以及其他相关方法中解决的问题,回顾了相关算法的关键贡献以及现有的缺陷和挑战。本文的另一个贡献是讨论了VSLAM系统的当前趋势以及研究人员将更多研究的现有开放问题。
参考
[1] Visual SLAM: What are the Current Trends and What to Expect?
往期回顾
激光雷达SLAM方法汇总 | 自动驾驶和移动机器人领域